基于感知机的手写体识别
对于手写体的识别,我采用的是keras来实现的,首先搭建一个单层感知机的模型来训练,来观察其模型的预测效果。
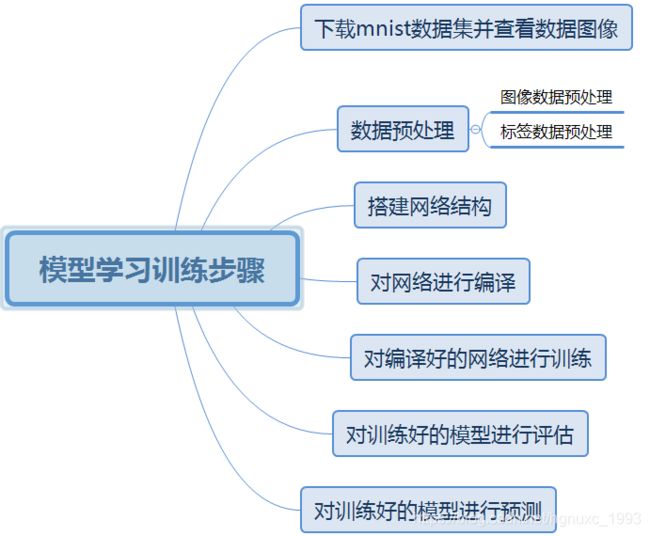
学习步骤如下:
源码:
from keras.datasets import mnist
import matplotlib.pyplot as plt
import numpy as np
from keras.utils import np_utils
from keras.layers.core import Dense,Activation,Dropout #从keras中导入layers模块,为搭建全连接层做好准备
from keras.models import Sequential #从keras中导入sequential模块
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
print(X_train.shape)
print(Y_train.shape)
print(X_test.shape)
print(Y_test.shape)
def plot_image(image): #输入参数为image
fig=plt.gcf() #获取当前图像
fig.set_size_inches(2, 2) #设置图片大小
plt.imshow(image,cmap="binary") #使用plt_imshow显示图片
plt.show()#开始绘图
#plot_image(X_train[0])
X_test1=X_test #备注未经处理的测试数据
Y_test1=Y_test #备注未经处理的测试标签
X_train=X_train.reshape(60000,784)#将28*28的二维数据转化成784的一维向量
X_test=X_test.reshape(10000,784) #将28*28的二维数据转化为784的一维向量
##转化成浮点型,该一维向量由784个0——255的浮点数组成,大部分为0,少部分有数字,数字大小代表图形每个点灰度深浅、
#接下来对一维向量的数字进行归一化,使每个数值范围都在0-1内
X_train=X_train.astype("float")
X_test=X_test.astype("float")
#print(X_train[0])
X_train=X_train/255
X_test=X_test/255
#print(X_train[0])
#①接下来一步搞定图形数据的预处理
#X_train=X_train.reshape(60000,784).astype("float")/255
#X_test=X_test.reshape(10000,784).astype("float")/255
#②标签数据的预处理
print(Y_train[:3])
#对数据进行一位有效编码
#编码位数为十位,对应分类的类别数目
N_classses=10
Y_train=np_utils.to_categorical(Y_train,N_classses)
Y_test=np_utils.to_categorical(Y_test,N_classses)
#print(Y_train[:3])
#③搭建单层感知机网络
model=Sequential()
model.add(Dense(N_classses,input_dim=784))
model.add(Activation("softmax"))
model.summary()
#④编译和训练,选择损失函数,优化算法,设置评估模型标准
model.compile(
loss="categorical_crossentropy",#损失函数选择交叉熵函数
optimizer ="adam", #优化选择器adam或者sgd
metrics=["accuracy"] #以准确率(accura)评估模型训练结果
)
#⑤训练网络
N_epoch=20
Batch_size=128
Validation_split=0.2
training=model.fit(X_train,Y_train, #输入训练集和标签
batch_size=Batch_size, #设置每次处理数据集的个数
epochs=N_epoch, #设置迭代次数
validation_split=Validation_split, #设置验证集的比率0.2
verbose=2 #日志显示,0代表不在标准输入输出日志信息,1代表输出进度记录,2代表每次迭代输出一行记录且无进度条记录
)
#⑥训练好的网络进行测试集评估
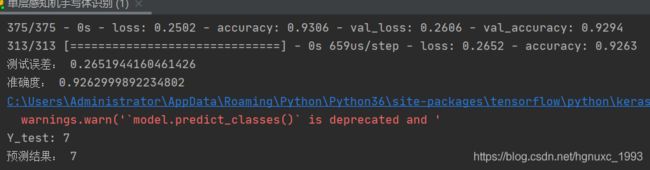
Test =model.evaluate(X_test,Y_test,verbose=1)
print("测试误差:",Test[0])
print("准确度:",Test[1])
#⑦预测
prediction=model.predict_classes(X_test) #X_test已经进行编码处理了
def pre_result(i):
plot_image(X_test1[i])
print("Y_test:",Y_test1[i])
print("预测结果:",prediction[i])
pre_result(0)
运行结果:
下面是多层感知机的手写体识别
该模型有一个输入层有784个神经元,两个隐藏层都有1000个神经元,一个输出层有10个神经元,使用了dropout()函数减少过拟合现象。
学习过程如上一样。
源码如下:
from keras.models import Sequential
from keras.datasets import mnist
from keras.layers.core import Dense,Dropout,Activation
import numpy as np
from keras.utils import np_utils
import matplotlib.pyplot as plt
(X_train,Y_train),(X_test,Y_test)=mnist.load_data()
def plot_image(image):
fig=plt.gcf()
fig.set_size_inches(2,2)
plt.imshow(image,cmap="binary")
plt.show()
N_classses=10
X_test1=X_test
Y_test1=Y_test
X_train=X_train.reshape(60000,784).astype("float32")/255
X_test=X_test.reshape(10000,784).astype("float32")/255
Y_test=np_utils.to_categorical(Y_test,N_classses)
Y_train=np_utils.to_categorical(Y_train,N_classses)
#print(Y_train[0])
model=Sequential()
model.add(Dense(1000,input_dim=784)) #输入层为784个神经元,输入层所连接的第一个隐藏层有1000个神经元
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(1000)) #第二个隐藏层
model.add(Activation("relu"))
model.add(Dropout(0.5))
model.add(Dense(10)) #输出层有10个神经元,激活函数softmax
model.add(Activation("softmax"))
model.summary()
#网络编译
model.compile(loss="categorical_crossentropy", #损失函数
optimizer="adam", #优化器选择adam
metrics=["accuracy"] #以准确率评估模型训练结果
)
#网络训练
N_epochs=20
Batch_size = 128
Validation = 0.2
training =model.fit(
X_test,Y_train,
batch_size=Batch_size,
epochs=N_epochs,
validation_split=Validation,
verbose=2
)
#评估
Test =model.evaluate(X_test,Y_test,verbose=1)
print("误差:",Test[0])
print("准确率:",Test[1])
#预测
prediction=model.predict_classes(X_test) #预测所有的数据
def pre_result(i):
plot_image(X_test1[i])
print("Y_test:",Y_test1[i])
print("预测值:",prediction[i]) #预测值
pre_result(0)
pre_result(1)
综上多层感知机的对于手写体识别预测不是很好,单层感知机对于手写体识别的预测较好。