【深度学习】损失函数详解
损失函数篇
- 什么是损失函数?
- 损失函数的分类
- 回归损失
-
- L1 Loss
- L2 Loss
- Smooth L1 Loss
- IoU Loss
-
- IoU Loss vs Lx Loss
- GIoU Loss
- DIoU Loss
- CIoU Loss
- 分类损失
-
- Entropy
- Cross Entropy
- K-L Divergence
- Dice Loss
-
- Dice Loss vs CE
- Focal Loss
- Reference
什么是损失函数?
在机器学习中,损失函数是代价函数的一部分,而代价函数则是目标函数的一种类型。
- 损失函数(Loss Function): 用于定义单个训练样本与真实值之间的误差;
- 代价函数(Cost Function): 用于定义单个批次/整个训练集样本与真实值之间的误差;
- 目标函数(Objective Function): 泛指任意可以被优化的函数。
损失函数用来评估模型预测值与真实值的偏离程度。通常情况下,损失函数选取的越好,模型的性能越好。不同模型间采用的损失函数一般也不一样。最常用的最小化损失函数的算法便是“梯度下降”(Gradient Descent)。
损失函数的分类
损失函数的分类方式有多种,按照是否添加正则项可分为经验风险损失函数和结构风险损失函数。按照任务类型分类,可分为两种:回归损失(针对连续型变量)和分类损失(针对离散型变量)。
回归损失
L1 Loss
也称Mean Absolute Error,即平均绝对误差(MAE),计算预测值与真实值的差的绝对值,衡量预测值与真实值之间距离的平均误差幅度,范围为0到正无穷。

优点:
- L1损失函数对离群点(Outliers)或者异常值更具有鲁棒性。
缺点:
- 在零处不可导,求解效率低,收敛速度慢;
- 梯度始终相同,即使很小的损失值,梯度也很大,这样不利于模型的收敛。针对它的收敛问题,一般的解决办法是在优化算法中使用变化的学习率,在损失接近最小值时降低学习率。
L2 Loss
也称为Mean Squred Error,即均方差(MSE),计算的是预测值与真实值之间距离的平方和,范围同为0到正无穷。
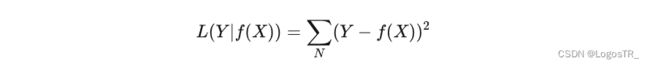
优点:
- 收敛速度快,能够对梯度给予合适的惩罚权重,而不是“一视同仁”,使梯度更新的方向可以更加精确。
缺点:
- 对异常值十分敏感,梯度更新的方向很容易受离群点所主导,不具备鲁棒性。
Smooth L1 Loss
平滑的L1损失(SLL),出自Fast RCNN。SLL通过综合L1和L2损失的优点,在0点处附近采用了L2损失中的平方函数,解决了L1损失在0点处梯度不可导的问题,使其更加平滑易于收敛。此外,在|x|>1的区间上,它又采用了L1损失中的线性函数,使得梯度能够快速下降。
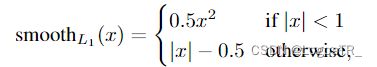

Smooth L1在训练初期输入数值较大时能够较为稳定在某一个数值,而在后期趋向于收敛时也能够加速梯度的回传,很好的解决了L1、L2损失所存在的问题。
IoU Loss
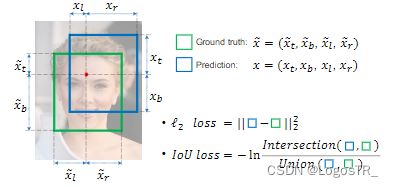
交并比损失,出自UnitBox,由旷视科技于ACM2016首次提出。是目标检测中常见的评价标准,主要是衡量模型生成的Predict bounding box和Ground-truth bounding box之间的重叠程度。

上图存在2个边框(bounding box), Ground-truth bouding box(绿色边框)和Predict bouding box(红色边框)。Ground-truth是人为标注的正确结果,Predict表示算法预测的结果。简单来说,IOU标准用于测量真实和预测之间的相关度,相关度越高,该值越高。

图形化展示:

IoU Loss:

IoU Loss vs Lx Loss
常规的Lx损失中,都是基于目标边界中的4个坐标点信息之间分别进行回归损失计算的。因此,这些边框信息之间是相互独立的。然而,直观上来看,这些边框信息之间必然是存在某种相关性的。如下图(a)-(b)分别所示,绿色框代表Ground Truth,黑色框代表Prediction,可以看出,同一个Lx分数,预测框与真实框之间的重叠程度并不相同,显然重叠度越高的预测框是越合理的。IoU损失将候选框的四个边界信息作为一个整体进行回归,从而实现准确、高效的定位,具有很好的尺度不变性。为了解决IoU度量不可导的现象,引入了负Ln范数来间接计算IoU损失。

GIoU Loss
泛化IoU损失,全称为Generalized Intersection over Union,由斯坦福学者于CVPR2019年发表的这篇论文中首次提出。上面我们提到了IoU损失可以解决边界框坐标之间相互独立的问题,考虑这样一种情况,当预测框与真实框之间没有任何重叠时,两个边框的交集(分子)为0,此时IoU损失为0,因此IoU无法j计算两者之间的距离(重叠度)。另一方面,由于IoU损失为零,意味着梯度无法有效地反向传播和更新,即出现梯度消失的现象,致使网络无法给出一个优化的方向。此外,如下图所示,IoU对不同方向的边框对齐也是一脸懵逼,所计算出来的值都一样。

解决方法: 如下图公式所示,GIoU通过计算任意两个形状(这里以矩形框为例)A和B的一个最小闭合凸面C,然后再计算C中排除掉A和B后的面积占C原始面积的比值,最后再用原始的IoU减去这个比值得到泛化后的IoU值。

DIoU Loss
距离IoU损失,全称为Distance-IoU loss,由天津大学数学学院研究人员于AAAI2020所发表的这篇论文中首次提出。上面我们谈到GIoU通过引入最小闭合凸面来解决IoU无法对不重叠边框的优化问题。但是,其仍然存在两大局限性:边框回归还不够精确与收敛速度慢。考虑下图这种情况,当目标框完全包含预测框时,此时GIoU退化为IoU。显然,我们希望的预测是最右边这种情况。因此,作者通过计算两个边框之间的中心点归一化距离,从而更好的优化这种情况。

下图表示的是GIoU损失(第一行)和DIoU损失(第二行)的一个训练过程收敛情况。其中绿色框为目标边框,黑色框为锚框,蓝色框和红色框则分别表示使用GIoU损失和DIoU损失所得到的预测框。可以发现,GIoU损失一般会增加预测框的大小使其能和目标框重叠,而DIoU损失则直接使目标框和预测框之间的中心点归一化距离最小,即让预测框的中心快速的向目标中心收敛。

图左给出这三个IoU损失所对应的计算公式。对于DIoU来说,如图右所示,其惩罚项由两部分构成:分子为目标框和预测框中心点之间的欧式距离;分母为两个框最小外接矩形框的两个对角线距离。因此, 直接优化两个点之间的距离会使得模型收敛得更快,同时又能够在两个边框不重叠的情况下给出一个优化的方向。

CIoU Loss
完整IoU损失,全称为Complete IoU loss,与DIoU出自同一篇论文。上面我们提到GIoU存在两个缺陷,DIoU的提出解决了其实一个缺陷,即收敛速度的问题。而一个好的边框回归损失应该同时考虑三个重要的几何因素,即重叠面积(Overlap area)、中心点距离(Central point distance)和高宽比(Aspect ratio)。GIoU考虑到了重叠面积的问题,DIoU考虑到了重叠面积和中心点距离的问题,CIoU则在此基础上进一步的考虑到了高宽比的问题。
CIoU的计算公式如下所示,可以看出,其在DIoU的基础上加多了一个惩罚项αv。其中α为权重为正数的重叠面积平衡因子,在回归中被赋与更高的优先级,特别是在两个边框不重叠的情况下;而v则用于测量宽高比的一致性。
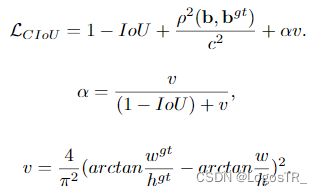
分类损失
Entropy
熵, 最早起源于物理学,用于度量一个热力学系统的混乱程度。但更常见的,在信息论里面, 熵是用于描述对不确定性的度量。所以,这个概念可以延伸到深度神经网络中,比如我们的模型在做分类时,也是希望尽可能的减小不确定性,其中使用了交叉熵,与信息论中的信息熵还有所不同。因此,在正式介绍分类损失函数时,我们必须先了解熵的概念。
计算机网络中,各种类型数据的传输其底层都是0-1bit流在传输介质中传输,其中有些位是有用信息,有些位则是冗余信息,有些位甚至是错误信息,等等。当我们传达信息时,我们希望尽可能多地向接收者传递有用的信息。
下面以一个天气预报的例子为例,解释熵到底为何物?假设一个地方的天气是随机的,每天有50%的机会是晴天或雨天。

现在,如果气象站告诉您明天要下雨,那么他们将不确定性降低了2倍。起初,有两种同样可能的可能性,但是在收到气象站的更新信息后,我们只有一种 。在这里,气象站向我们发送了一点有用的信息,无论他们如何编码这些信息,这都是事实。即使发送的消息是雨天,每个汉字占两个字节,消息的总大小为32位,但它们仍然只通信1位的有用信息。现在,我们假设天气有8种可能状态,且都是等可能的。

那么,当气象站为您提供第二天的天气时,会将不确定性降低了8倍。由于每个事件的发生几率为1/8,因此降低因子为8。但如果这些可能性不是等概率的呢?比如,75%的机会是晴天,25%的机会是雨天。
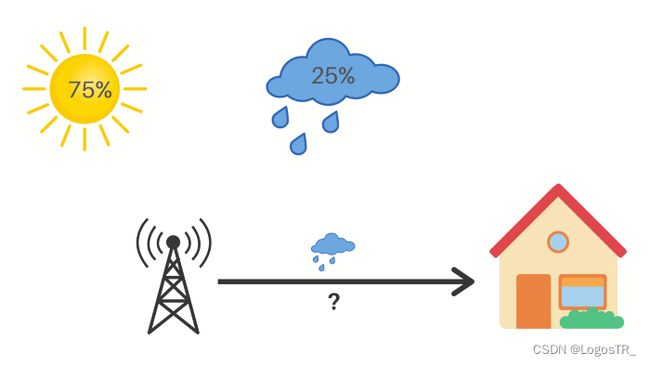
现在,如果气象台说第二天会下雨,那么你的不确定性就降低了4倍,也就是2比特的信息。不确定性的减少就是事件概率的倒数。在这种情况下,25%的倒数是4,log(4)以2为底得到2。因此,我们得到了2位有用的信息。
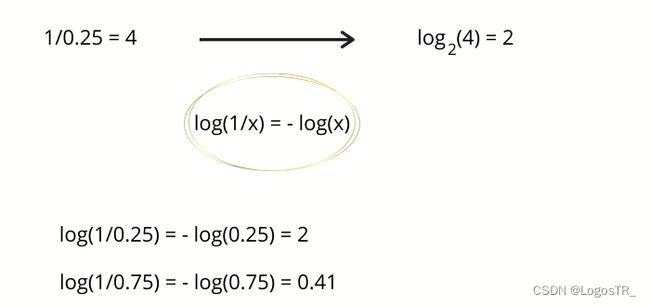
如果气象站说第二天是晴天,那么我们得到0.41比特的有用信息。那么,我们平均能从气象站得到多少信息呢?明天是晴天的概率是75%这就给了你0.41比特的信息而明天是雨天的概率是25%这就给了你2比特的信息,这就对应我们平均每天从气象站得到0.81比特的信息。
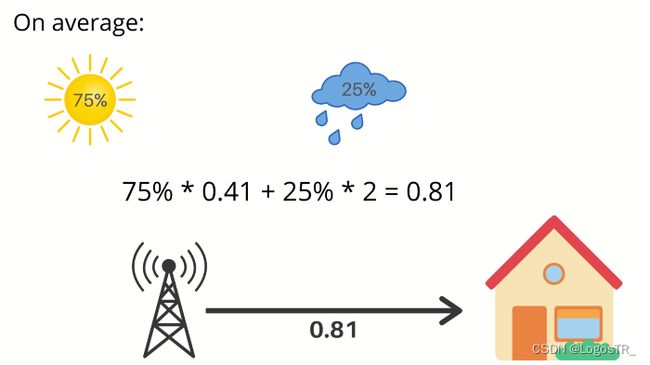
我们刚刚所计算出来的就叫做熵,它可以很好地描述事件的不确定性。它是由以下公式给出:
![]()
它衡量的是你每天了解天气情况时所得到的信息量的期望。同时也反映了在给定概率分布p中样本值的平均信息量的前提下,它的概率分布有多不可预测。如果我们住在沙漠中央,那里每天都是阳光灿烂的,平均来说,我们不会每天从气象站得到很多信息,熵会接近于零。另一方面,如果天气变化很大,熵就会大得多。简单地说:一个事件的不确定性就越大,其信息量越大,它的信息熵就越高。
Cross Entropy
下面来研究一下交叉熵,它代表发送平均信息长度。考虑同样的例子,8种可能的天气条件,所有都是等可能的,每一种都可以用3位编码 (2^3=8)。

此时平均信息长度为3,也就是交叉熵为3。但是现在,假设你住在一个阳光充足的地区,那里的天气概率分布是这样的:
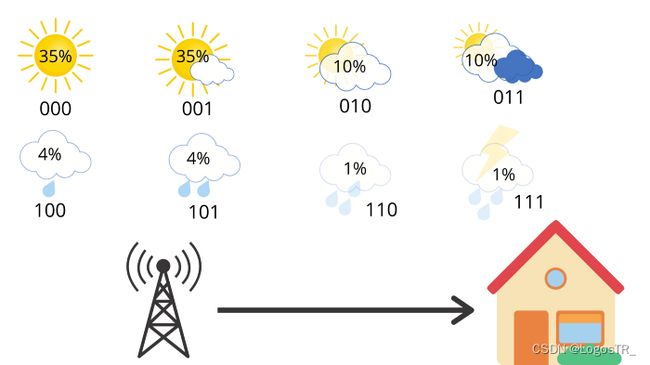
按照公式计算,得到其信息量,信息熵为2.23bit:

平均来说,气象站发送了3个比特,但接收者只得到2.23个比特有用的信息。但是,我们可以做得更好。比如,更改编码方式:
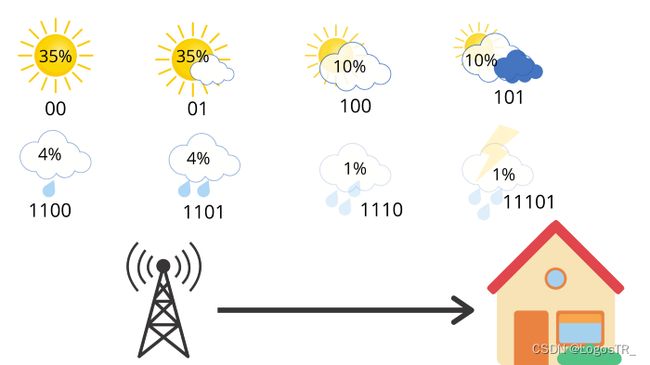
天气的编码方式是明确的,并且如果你链接多条消息,则只有一种方法可以解释位的顺序。例如,01100只能表示部分晴天(01),然后是小雨(100)。因此,如果我们计算该站每天发送的平均比特数,则可以得出:

这是我们新的改进的交叉熵比之前的3比特(即全部用3位表示的形式)更好。现在,我们在换一种情况。
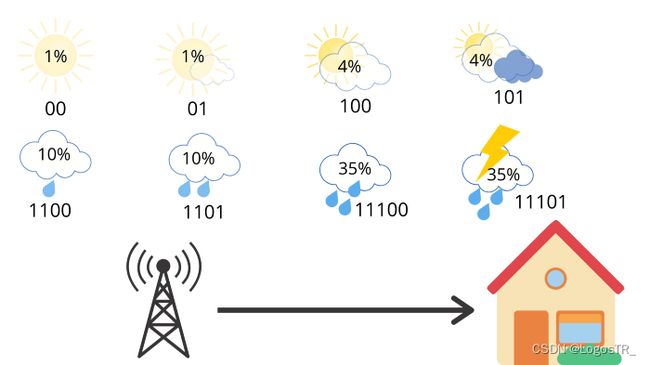
此时,如果我们计算它的交叉熵:
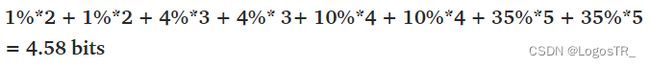
我们将得到4.58位。大约是熵的两倍。平均而言,该站发送4.58位,但只有2.23位对接收者有用。每条消息发送的信息量是必要信息的两倍。这是因为我们使用的编码对天气分布做出了一些隐含的假设。例如,当我们在晴天使用2位消息时,我们隐式地预测晴天的概率为25%。以同样的方式,我们计算所有天气情况。
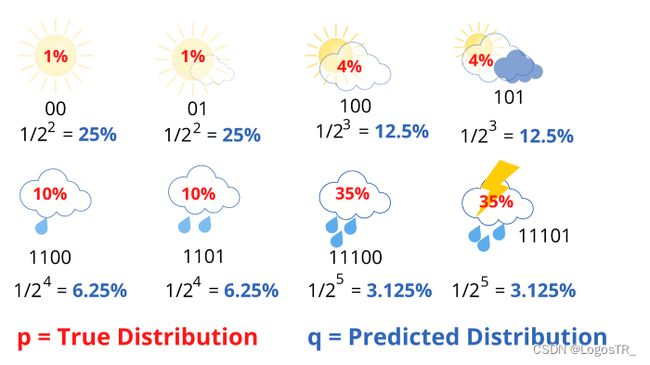
分母中2的幂对应于用于传输消息的比特数。很明显,此时的预测分布q和真实分布p有很大不同。现在我们可以把交叉熵表示成真实概率分布p的函数和预测概率分布q的函数:
![]()
K-L Divergence
KL散度。对于交叉熵损失,除了我们在这里使用预测概率的对数(log(q(i)))外,它看起来与上面熵的方程非常相似。 如果我们的预测是完美的,那就是预测分布等于真实分布,此时交叉熵就等于熵。 但是,如果分布不同,则交叉熵将比熵大一些位数。交叉熵超过熵的量称为相对熵,或更普遍地称为库尔贝克-莱布里埃发散度(KL Divergence)。总结如下:

接上面的例子,我们便可以顺便算出:KL散度 = 交叉熵 - 熵 = 4.58 - 2.23 = 2.35(Bits)。
Dice Loss
Dice Loss 最先是在VNet 这篇文章中被提出,后来被广泛的应用在了医学影像分割之中。

Dice系数是一种集合相似度度量函数,通常用于计算两个样本的相似度,取值范围为0~1,值越大表示两个值的相似度越小,其基本定义(二分类)如下:

其中 |X∩Y| 是X和Y之间的交集,|X|和|Y|分表表示X和Y的元素的个数。从上述公式也可以看出,其实Dice系数是等价于F1分数的,优化Dice等价于优化F1值。此外,为了防止分母项为0,一般我们会在分子和分母处同时加入一个很小的数作为平滑系数,也称为拉普拉斯平滑项。
Dice Loss vs CE
语义分割中一般用交叉熵来做损失函数,而评价的时候却使用IOU来作为评价指标,为什么不直接拿类似IOU的损失函数来进行优化呢?
- 相较于 dice-coefficient 和类似 IoU 度量的损失函数,交叉熵的梯度形式更优;
- 分割的真实目标就是最大化 dice-coefficient 和 IoU 度量. 而交叉熵仅是一种代理形式,利用其在 BP 中易于优化的特点。
Focal Loss
焦点损失,出自何凯明的《Focal Loss for Dense Object Detection》,出发点是解决目标检测领域中one-stage算法如YOLO系列算法准确率不高的问题。作者认为样本的类别不均衡(比如前景和背景)是导致这个问题的主要原因。比如在很多输入图片中,我们利用网格去划分小窗口,大多数的窗口是不包含目标的。如此一来,如果我们直接运用原始的交叉熵损失,那么负样本所占比例会非常大,主导梯度的优化方向,即网络会偏向于将前景预测为背景。即使我们可以使用OHEM(在线困难样本挖掘)算法来处理不均衡的问题,虽然其增加了误分类样本的权重,但也容易忽略掉易分类样本。而Focal loss则是聚焦于训练一个困难样本的稀疏集,通过直接在标准的交叉熵损失基础上做改进,引进了两个惩罚因子,来减少易分类样本的权重,使得模型在训练过程中更专注于困难样本。其基本定义如下:

其中:
- 参数α和(1-α)分别用于控制正/负样本的比例,其取值范围为[0, 1]。α的取值一般可通过交叉验证来选择合适的值;
- 参数γ称为聚焦参数,其取值范围为[0, +∞),目的是通过减少易分类样本的权重,从而使模型在训练时更专注于困难样本。 当 γ = 0 时,Focal Loss就退化为交叉熵损失,γ 越大,对易分类样本的惩罚力度就越大。
Reference
- 一文看尽深度学习中的各种损失函数
- 医学影像分割—Dice Loss
- 常见的损失函数(loss function)总结