阿里云Hologres助力好未来网校实时数仓降本增效
客户介绍
好未来(NYSE:TAL)是一家以智慧教育和开放平台为主体,在全球范围内服务公办教育,助力民办教育,探索未来教育新模式的科技教育公司。好未来的前身学而思成立于 2003年,2010年在美国纽交所正式挂牌交易。好未来以“爱和科技让教育更美好”为使命,致力成为受尊敬的教育机构。当前,好未来已构建起从工具、平台到内容的多元化教育生态,满足从-1岁到 24岁各年龄段人群个性化学习需求。目前,好未来旗下拥有学而思素养、学而思网校、彼芯、美校、学而思国际、学而思文创出版中心、学而思大学生、妈妈帮等品牌,并战略投资了赫石少儿体能等多个品牌。集团业务覆盖素质教育、技术服务、海外教育服务、数字内容出版、教育硬件、托管服务等领域。
学而思网校,纽交所上市公司好未来旗下在线教育品牌,为6-14岁的孩子提供素质教育服务。2008年成立至今,积累了十余年教研经验和学习数据,陪伴千万孩子成长,在家长间口口相传。学而思网校首创“直播+辅导”的双师教学模式,大力投入AI和全真互联网等前沿技术,持续推动教育创新。2021年学而思网校全面升级素养体系,推出人文美育、科学创想、编程与机器人等热门素养课程。
网校实时数仓发展背景介绍
网校实时数仓1.0从2019年开始搭建,基于Kudu OLAP引擎构建,前期承载业务不多,任务量不大,运行稳定、性能也很高,比较适合前期的技术选型;自2020年后,网校进入业务快速发展期,实时开始承接更多的业务需求,包括营销域、交易域、教学域等数据域的建设以及实时大屏,随着需求增多,实时数仓任务量、数据量也不断攀升,Kudu开始遇见技术瓶颈,无法快速满足业务需求,运维难、成本贵等问题也开始凸显。

与此同时,2021年7月教育行业遭受“双减”,公司业务开始面临业务缩减以及转型等业务变化,大量学科类、无效任务空跑,造成资源的极大浪费,成本治理提升日程,开始着手调研建设成本更低的实时数仓OLAP引擎。经过市面上几款OLAP引擎的对比,最终选型Hologres,并于2022年1月开始实时数仓升级,经过半年多的成本治理以及数仓建设,网校实时数仓迈入2.0阶段,相比于1.0版数仓,更加稳定、可靠,建设成本也更低。此次升级主要是针对实时数仓的底层OLAP引擎的升级,使用阿里云Hologres替换Kudu,实现实时数仓降本增效,助力业务更加精细化增长。
实时数仓1.0:以Kudu为OLAP引擎,技术瓶颈凸显
1、网校实时数仓1.0全景图
实时数仓1.0支撑着网校大部分的线上数据,用于报表分析,精准营销等多个场景,其业务数据流程如下图:
- ODS层主要存储日志、业务库同步过来的原始数据,包括用户行为等埋点日志以及业务数据等。
- ODS层数据清洗后,写入DWD层,并在DWD层对根据业务需求数据做细分,分为教学、交易、营销等明细数据。
- DWS层将DWD数据与学员、课程、班级、讲次信息等维表进行关联,生成业务宽表或者业务模型汇总等数据。
- ADS层从DWS获取数据,面向应用层,主要是使用MSQL、Polardb作为查询引擎,根据业务场景对接实时看板、实时大屏、实时接口等,赋能实时销量、转化、续报、在线、出勤、完课等场景。

2、基于Kudu架构的场景方案
整个实时数仓1.0都是基于Kudu来建设的。其背后的技术架构如下图:
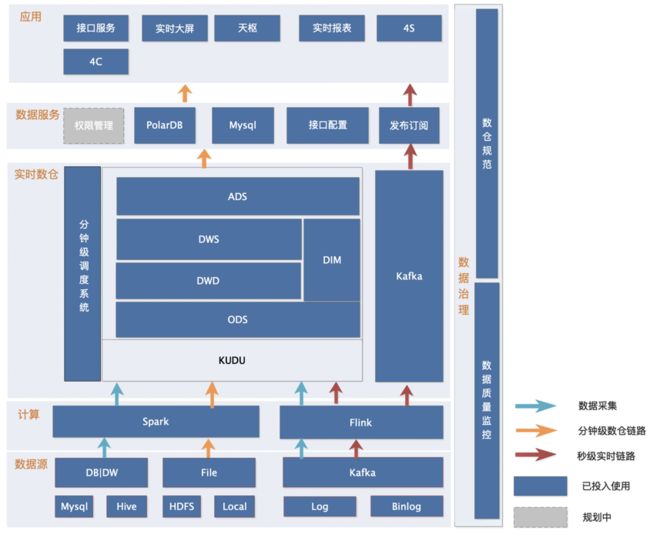
根据业务的时效性,将网校的场景分为分钟级场景和实时秒级场景。
1)准实时数仓模型(分钟级):
在分钟级实时数仓中,会通过Spark/Flink对数据进行预处理后写入Kudu,并在Kudu中根据ODS、DWD、DWS分层计算,然后将数据写入ADS层的PolarDB或者MySQL,最后对接实时大屏、报表等业务。

2)实时数仓模型(实时秒级):
在实时秒级的场景中,对数据的时效性要求非常高,采用Flink+Kafka架构,DWD明细数据同时会落地一份到Kudu,DWS层计算过程中 关联Kudu维表、以及历史DWD数据来完成汇总模型构建,输出结果数据到ADS层的PolarDB、MySQL、Kafka消息队列等,最后对接线上服务。

网校实时80%左右场景,使用分钟级实现;20%场景使用秒级实时链路实现。当然也有部分场景可能使用混合链路实现,比如实时在线、出勤,Flink程序实时接入心跳明细数据到数仓DWD层,然后在DWS层进行分钟级汇总班级出勤、在线等数据,在ADS层进行数据的输出。
3、业务挑战:Kudu技术瓶颈凸显,业务成本治理刻不容缓
实时数仓1.0中,Kudu作为底层OLAP引擎,使用Impala进行数据加载、运算,当业务上量时,Kudu的技术瓶颈开始凸显,主要表现在以下几个方面:
- 业务发展后期,Impala服务器内存压力较大,内存不足问题频发:网校80%的业务使用分钟级数仓实现且都是每隔5分钟计算一次,Impala承载Kudu数据的加载、计算,大量复杂计算的Sql任务在同一时间瞬时打到服务器,导致Impala节点内存压力较大,甚至出现部分批次任务执行失败情况。
- 运维困难:缺乏Kudu专业运维同学,当某个数据指标计算出现问题,或者集群不稳定时,有比较长的运维流程和修订流程,严重影响实时服务的稳定性,无法保证实时数据的SLA,使得用户体验非常不好。
- 故障恢复时间长,当出现节点故障的时候,为了快速恢复业务,短期靠扩容节点来暂时解决问题,导致运维和成本压力逐步增大。
- “双减”原因,急需对成本进行治理,迫切需要将Kudu切换到建设成本更低、更稳定、可靠的OLAP引擎。
综上,基于Kudu实时数仓,正逢“双减”,面临着业务快速变化、成本压力以及运维困难等一系列的内、外部挑战,我们迫切的希望能够找到一款OLAP产品将Kudu进行替换,解决当前遇见的各种问题,搭建一个更加简洁、易用、运维便捷、资源动态伸缩容的数仓底座。
实时数仓2.0:Hologres读写分离部署全面替换Kudu
基于实时数仓1.0的技术痛点,在对市面上的多种OLAP引擎进行调研以及对比后,我们最终选择了阿里云Hologres替换Kudu搭建网校实时数仓,即实时数仓2.0版本。
1、OLAP引擎技术选型需求:高吞吐、高可用
根据业务,我们梳理了对OLAP引擎的需求如下:
- 强大的OLAP能力
- 支持SQL,支持更新、删除、Upsert操作
- 高吞吐、高可用
- 运维方便,资源伸缩便捷
同时我们也对比了市面上常见的OLAP引擎,如下表所示,最终选择了Hologres为新的OLAP引擎

2、Hologres全面替换Kudu作为主OLAP引擎
选择了Hologres作为实时数仓的主OLAP引擎之后,通过Hologres替换了Kudu的所有数据处理链路,同时也通过Hologres读写分离部署的方式,以只读从实例(简称从库)替换了原PolarDB/MySQL等查询引擎,以此构成了实时数仓2.0。数据链路如下:
- 数据分为离线和实时两部分。离线部分数据源数据通过集团采集工具T-Collect接入Hologres ODS层,实时部分通过Flink实时接入MySQL Binlog、埋点日志等数据入仓。
- 在Hologres中对数仓分为ODS、DWD、DWS、ADS等4层,每一层的数据通过集团T-Data平台分钟级调度、清洗,并最后由Hologres从库提供线上服务出口。
- 实时和离线数据统一由Hologres存储,并由从库作为查询引擎统一提供线上数据出口,支撑的业务场景包括实时看板、实时大屏、实时接口服务、实时推送等场景。

3、查询引擎统一切换到Hologres从实例
实时数仓1.0计算在Kudu中,算完之后把结果同步到查询引擎PolarDB或者MySQL中,实时链路相对来说比较长,而且数据移动成本也很高,对实时数据的稳定性有一定的影响。
实时数仓2.0中,我们采用Hologres共享存储多实例的高可用部署方案,Hologres主实例承载数据的加载、计算,从库共享主库的所有表和数据承载数据查询,实现读写分离方案,并且从库作为实时数仓唯一的数据出口,统一数仓技术架构。这种方案的好处是减少了ADS层数据同步导出链路的维护,降低了开发成本。
Hologres的共享存储多实例的高可用部署方案如下图所示:

实时数仓2.0查询引擎统一升级切换到Hologres从库后的数据流转图前后对比如下:

同时,我们计划对外开放Hologres从库ADS层,分析师或者懂SQL的产品老师后期可通过集团T-Query平台查询工具对实时数据进行探索、分析,自满足部分临时需求,减少人工需求、释放实时数仓开发人力。
助力数仓业务升级,完成降本增效
实时数仓2.0经过半年多的建设,在成本治理上取得了非常好的效果,同时基于Hologres的实时数仓架构在集团推广应用上也有比较成功的案例:
1、百万级写入和毫秒级查询能力
- 实际业务中,Hologres的写入能力达到百万行+/秒,业务就能快速拿到数据并查询。同时在查询上不仅能支持秒级OLAP分析,还能支持在线服务毫秒级响应,使得业务探索数据的效率变得更快。
- 通过Hologres多子实例的部署方式,天然的就支持了网校实时数仓的多个查询场景,统一了数据的出口,简化了数仓的使用。并且写入和查询之间互不影响,非常有效的做到了读、写分离。
2、降低成本近百万/年
- 实时数仓底座升级Hologres后,无需维护多套系统,通过Hologres一套系统支持了实时数仓的全部场景,OLAP引擎成本相比Kudu节约了近百万/年的费用。
- 公司业务转型背景下,通过数据治理、任务治理等任务数下降80%,Yarn队列资源成本节约几十万/月,数据冗余存储减少90%,提升了数据的利用率。
3、减少运维压力
- 通过Hologres替换Kudu后,依托阿里强大的技术运维能力,很大程度减少了我们在运维层面上的压力,更加专注于业务开发,有更多精力去做好实时数据的稳定性、准确性、及时性,把用户体验做好。
- 周末、暑假等业务高峰资源不足时,可随时进行扩容;业务低峰时,可以对资源进行缩容处理,做到很好的一个资源伸缩和成本控制。
4、集团内Hologres实时数仓架构推广
- 网校实时数仓天然带有K9基因,希望学成功复制网校实时数仓2.0架构,并承载核心实时数据服务,比如实时续报、转化、企微等
未来规划和期望
未来规划:
- 网校实时数仓的持续建设
- 数据治理:元数据、数据质量、数据资产、数据安全等
- 流批一体技术探索
最后谈一谈,在Hologres使用过程中碰到一些问题以及对Hologres的期待
- Hologres暂时还不支持自定义函数,系统自带函数满足不了部分特殊需求,自定义函数这块可以同阿里的技术伙伴一起去共建、推动此功能的实现、上线。
- 其次是Hologres权限配置问题,目前支持简单权限模型、专家权限模型和Schema级别权限模型三种模式,专家模型功能最强大(支持细粒度表级别权限控制),但配置比较复杂,需要执行的命令细节多,从而运维不方便,线上使用的是简单权限模型,权限要控制到schema、表级别,需要在应用系统层面加一层库、表权限管理系统,增加了开发成本;开源Hadoop离线数仓有Range等权限控制框架,能做到精准库、表等权限控制,期望Hologres以后能把权限模型优化得更加简单易用,更多白屏化操作,方便上手。
- 同时,我们期待Hologres后面可以支持查询开源架构Hive表的数据,这样的话做流批一体可以有更加便捷、简单的实现方案。
相信Hologres未来会变得越来越好用,变成一款功能更全面、更加强大的OLAP引擎!我们也希望通过Hologres建设出更加优秀的实时数仓,赋能更多的业务。
作者:刘标新,好未来网校实时数仓开发工程师、负责人。王洋,好未来网校实时数仓开发工程师
参考文章:
学而思网校:https://touch.xueersi.com/
实时数仓Hologres核心技术揭秘:https://developer.aliyun.com/article/779118
实时数仓Hologres共享存储实例介绍:https://help.aliyun.com/document_detail/360394.html