全文链接:http://tecdat.cn/?p=26206**
结构方程建模 (SEM) 是一个非常广泛和灵活的数据分析框架,也许更好地被认为是一系列相关的方法,而不是单一的技术。它与营销研究有什么关系?
它的起源可以追溯到 20 世纪之交的心理学家查尔斯·斯皮尔曼和第一次世界大战后的遗传学家 Sewall Wright。许多其他人也参与了它的开发,尤其是 Karl Jöreskog 和 Peter Bentler。协方差结构分析和 LISREL(Jöreskog 共同开发的程序的名称)是偶尔与结构方程建模互换使用的其他术语。
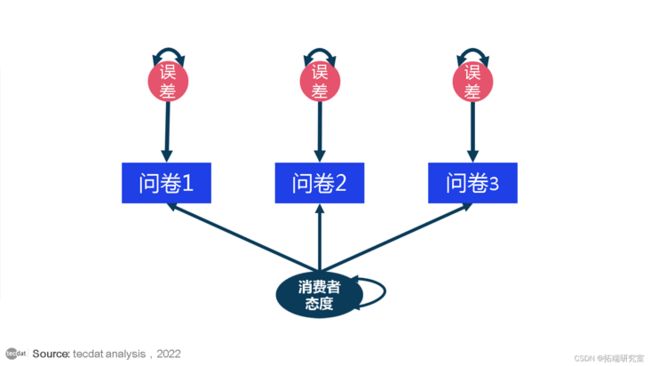
它与营销研究有什么关系?态度、观点和个性特征是消费者行为的重要驱动因素,但它们是潜在的结构,营销研究人员实际上无法观察或直接衡量它们。我们只能根据我们_可以_观察到的情况来推断它们,例如对问卷项目的回答。测量潜在结构具有挑战性,我们还必须将测量误差的估计纳入我们的模型中。SEM 擅长这两项任务。

简而言之,SEM 同时结合了因子分析和回归*,但为建模者提供了比这两种技术中的任何一种都大得多的灵活性。这_与_运行因子分析然后将因子分数输入多重回归不同。SEM 特别适用于因果分析。此外,当多重共线性*(高度相关的自变量)成为一个问题时,SEM 是许多研究人员的首选工具。
SEM 中类似于因子分析的部分称为_测量模型_,将测量模型的组成部分联系在一起或将它们与一个或多个因变量相关联的元素称为_结构模型_。然而,有时,在分析之前,变量会根据经验或理论基础进行组合(“打包”),而测量模型则不起作用。在其他时候,我们不关心测量误差,只使用原始变量——SEM 术语中的“观察变量”。当没有测量模型(只有结构模型)时,路径分析这个术语比 SEM 更合适,尽管有些人非常普遍地使用“SEM”。
虽然经常用于分析调查数据,但它不限于任何一种数据源,可以与社交媒体数据、客户交易数据、经济数据一起使用,甚至在神经科学中用于分析 fMRI 数据。在其现代形式中,它能够与任何数据类型一起使用——比率、区间、序数、名义和计数——并且可以对变量之间的曲线关系以及交互作用进行建模。
它不需要完整的数据……它可以容纳多个因变量,有时与联合分析混合。SEM 还可用于调整消费者调查和其他问卷数据中的个人响应风格。
我们什么时候使用它?
想象一下,如果您想更好地了解哪些消费者感知与您的产品或服务类别中的喜欢、购买兴趣或满意度最密切相关,并查看是否存在不同感知的潜在消费者细分(聚类)。虽然不是一个简单的建模任务,但 SEM 将适用于这些目标,并且品牌的图像也可以被映射,以帮助我们了解品牌感知背后的维度如何区分品牌。
SEM 可用于更简单的工作,例如下面关于男性个人护理类别的消费者调查示例。该插图是完整模型的简化和隐藏版本,其中包括更多属性以及年龄等外生变量。我应该注意,除了路径图之外,还有很多输出需要仔细检查!

在上面的路径图中,椭圆代表因素,在 SEM 术语中也称为潜变量、未观察变量或未测量变量。这些是可以推断但不能直接测量的理论概念。
矩形用于表示属性,也称为测量变量、观察变量或清单变量。在此示例中,传统因素由知名度、大品牌_和_可靠性 属性表示或衡量。
从一个潜在变量指向另一个潜在变量的单向箭头描绘了假设的因果关系,例如传统对品牌价值的影响,这是本分析中的因变量。这些可以比作回归系数。从潜在变量到属性的单向箭头等效于因子分析中的载荷。
在这个例子中,双头箭头是潜在外生(独立)变量之间的相关性。
与箭头相邻的数字是回归系数、相关系数和因子载荷。在 SEM 中,回归系数通常小于相关性和载荷,就像这里一样。
为了减少混乱,我省略了误差和残差项,它们类似于因子分析中的独特因素和回归中的残差项。
本次调查中评分的品牌也根据其在完整模型中的因子得分绘制在散点图中。出于保密和篇幅的原因,此处未显示。
几个常见问题解答
我需要多大的样本?多年来引用的两个指南是至少 200 个案例(例如,调查受访者)和每个测量变量至少 10 个案例(例如,如果模型中有 25 个属性评级,则 250 个受访者)。然而,这些指南只是经验法则,现在受到许多质疑。
大数据呢?在过去的 10-15 年里,SEM 才开始迁移到其发源地之外——主要是心理学、社会学和教育学。我记得在美国统计协会杂志上读过一篇文章,向其读者介绍了这种方法。如果我没记错的话,那是在 2006 年,在 SEM 用于社会和行为科学很久之后。在我看来,它在营销研究中仍未得到充分利用,高级分析通常也是如此。
数据科学家现在似乎才开始了解 SEM。这不是一个计算快速的过程,但在今天的硬件上,在具有许多变量的相当大的样本上运行良好。“大”是相对的!在某些情况下,使用标准机器学习工具(例如 LogitBoost 进行预测)和对相同数据样本使用 SEM 来尝试理解生成数据的机制是有意义的 -营销语言中的原因。
我需要做哪些统计假设?这是非常具体的,具体取决于您运行的 SEM 模型的类型。与大多数统计程序一样,SEM 对违反假设非常稳健,一般而言,标准误差比系数估计值更容易受到攻击。
我听说 SEM 只能用于检验假设。这是真的?这是对统计数据的普遍误解,而不仅仅是 SEM。理论不是凭空出现的,而且经常是在观察的基础上发展起来的。简而言之,我们看到事情正在发生,并试图找出它们发生的原因。也就是说,探索性分析——即使你只是使用交叉表——也会带来很高的发现风险,这些发现不会复制或推广到样本或非常狭窄的人群之外。我们总是需要小心并做好功课。
我怎么知道我的模型好不好?为此使用了多种拟合指数。比较拟合指数 (CFI) 和近似均方根误差 (RMSEA) 可能是最常见的。更熟悉的 R 平方有时也能提供丰富的信息。不过,我应该强调,该模型是否“足够好”最终将取决于常识、相关理论和对决策者的潜在效用。在很大程度上,这是一个判断电话。
延伸阅读
网上有大量关于 SEM 的材料,以及关于 SEM 的研讨会和大学课程,或者将其作为主要主题。Barbara M. Byrne 撰写了一些可读性极强的介绍性书籍,重点介绍广泛使用的商业 SEM 统计软件包(例如,_使用 EQS 进行结构方程建模_)。Rex B. Kline 的畅销书名为 _《结构方程建模的原理和实践》,_稍微高级一点但也非常易读。
_具有潜在变量的结构方程_(Bollen) 是揭示 SEM 数学基础的“经典”。_如前所述,Stan Mulaik 的结构方程线性因果建模与_Bollen 的相似,但更新且更集中于因果分析,这是 SEM 的主要应用。_结构方程建模手册 (Hoyle)_是一本密集而全面的书,涵盖了所有主要的 SEM 主题。
_A Primer on Partial Least Squares Structural Equation Modeling_ (Hair et al.) 和_Causality: Models, Reasoning and Inference_ (Pearl) 分别介绍了 PLS 和贝叶斯网络,这两种方法被一些研究人员视为 SEM 的替代方法。
良好的心理测量学背景将帮助您充分利用 SEM。_心理测量学:导论_(Furr 和 Bacharach)和_心理测量理论导论_(Raykov 和 Marcoulides)是这两本最新的教材,如果您是这门学科的新手,可以帮助您入门。其中第二个比第一个要先进得多。
总结
这是一个强大的工具,从统计学上讲,也是非常危险的。尽管 SEM 在技术上非常复杂,但使用当今用户友好的软件很容易将自己点击进入非常尴尬的情况。
许多模型可能提供与数据相似的拟合,但为决策者提供了截然不同的解释和行动方案。另外,我们需要注意不要过拟合,用SEM很容易做到。
营销研究的一个重要领域介于纯_定性_研究和艰苦的_定量_研究之间,而 SEM 在这个灰色空间中特别灵活。