2020-05-06
深度学习,框架是王道,调参也是关键,分享一篇调参的优秀文章。
http://www.360doc.cn/article/99071_844393697.html?luicode=10000011&lfid=2304131064414853_-_WEIBO_SECOND_PROFILE_WEIBO&u=http%3A%2F%2Fwww.360doc.cn%2Farticle%2F99071_844393697.html
作者:藏云阁主
一、简介
模型的调整是一项很细致的任务,仅仅通过输出结果来调整,并不能够了解到模型的内部缺陷。我将通过这篇文章来介绍一下我的一次调试过程,解决dead relu节点的问题,最终修复了模型的缺陷。
一些名词解释:
Dead Relu:在训练过程中,由于一次梯度更新的幅度过大,导致某些Relu节点的权重调整的太大,使得后续的训练对该节点不再起作用,这个节点相当于永久dead了。
激活函数:将神经元的输入映射到输出端的非线性函数,常见的有Relu、Leaky-Relu、Sigmoid、Tanh等等。
正则化算法:将神经元的输出规范到一定的分布,使训练加快,增加训练的稳定性。常见的有:Batch Normalization、Group Normalization、L2 Normalization。
二、模型缺陷的研究
起初,在我的模型调参的过程中,发现了一些难以理解的有趣现象:对于同样的一层feature,我用maxpool和avgpool来提取特征,训练出的模型效果居然会差了10个点以上!要知道,这层feature已经是在backbone网络的最后一层了,按理来说即使有差异,也不应该大到这种程度,这种反常的现象引起了我的注意。
为了寻找原因,我把这一层feature的值输出,发现采用avgpool的模型,feature中的零值大概只占10%,而采用maxpool的模型,feature中的零值占到了40%以上,这显然不合理。为了排除个别样本造成的feature差异,我用两个模型都跑了一遍测试集,统计feature中的零值的平均数量,avgpool大约占12%,maxpool大约占43%,看来不是由于样本造成的差异。
我仔细地查看训练的过程,发现maxpool的模型在训练初期的loss震荡的比较厉害,中期偶尔会出现loss骤然增高的情况,虽然训练到后期loss会收敛,但是这个不稳定的loss曲线显然是有一些设计不合理的地方在里面。
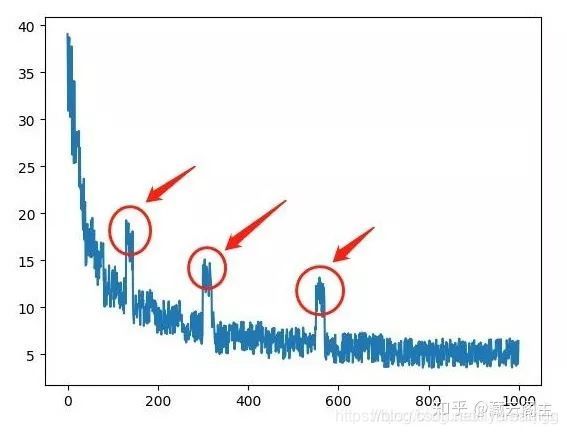
如图所示,在训练中偶然会出现这样的震荡点,甚至有时问题更严重,在某些batch更新完之后,loss突然就升到了NAN,导致训练失败。针对这个现象,我首先想到的是数据问题。训练的数据集非常大,不可避免会有一些脏数据,这些脏数据可能会在某些batch中主导了梯度,导致loss过大。
猜测一:脏数据导致梯度过大
为了确认这一点,我首先是在代码中加了一段监测loss变化的代码,当某个batch的loss显著高于之前的loss,超出了很大的比例,我就把这个batch的数据和标签打印出来。这样一来,我就可以定位到具体是哪些样本造成了loss过大。经过一段时间的Debug,发现造成loss过大的那些样本,绝大多数都很正常,极个别的样本属于比较难的样本或者说是脏数据。我把那些脏数据清理了一遍之后再训练,发现还是会出现loss震荡的问题,这说明问题不在数据上。
既然数据没有问题,那么问题有可能出在训练参数的设置上。loss震荡的现象绝大多数发生在训练的前500个batch,这个阶段模型还很不稳定,由于样本间的差异性较大,在较大的训练学习率下有可能造成梯度震荡。
猜测二:训练超参数设置不当
为了缓解训练初期的模型学习难度,我首先是调低了学习率的数值,发现在模型的前500个batch确实没有发生震荡的情况,但是到了1800个batch左右的时候又出现了,看来单纯地调低学习率并不能解决,我又加上了warmup的策略,也就是在训练的前1000个batch里,学习率逐渐上升,我分别测试了线性增长和指数增长两种方式,公式如下:
learning_rate = base_learning_rate * batch * (1/1000) # 线性增长
learning_rate = base_learning_rate * (batch * (1/1000)) ** 2 # 指数增长
可是这两种方式都不能避免loss的震荡,看来调整学习率只是延缓了震荡现象到来的时间,并不能解决掉这个问题。我继续分析,把loss震荡前和loss震荡后的feature输出,看看差异。结果是,震荡之后,原先feature里有响应的部分变成了零值,而原先是零值的依然是零值,也就是说,震荡之后零值的数量增加了,几乎每次震荡都会多出来一些新的零值节点。这么看来,每次震荡,都相当于把网络砍掉了一部分,那么,保留下来的部分,应当要能表达整个数据集的信息,但是事实并不是这样,零值过多的那些模型明显效果要差很多。
我又花了一段时间搜索这个问题,无意中在Quora上发现一些关于dead relu的讨论。
神经网络中的Dying Relu是怎么回事?
https://www.quora.com/What-is-the-dying-ReLU-problem-in-neural-networks
看看他们有什么解决方法:减小学习率、增加warmup策略、规范ground truth的取值范围、将Relu改为PRelu或者Leaky-Relu等等。前几种方法我都试过了,就差这个改变激活函数还没试过,于是我猜测可能是激活函数的不当导致了这个问题。
猜测三:激活函数选择不当
于是我把激活函数换成了PRelu,训练中发现,震荡的现象依然存在,且训练后的模型效果依然不佳。虽然feature中不存在零值了,但是存在很多几乎接近于零值的响应节点,所占比例与之前用Relu时,产生的零值点几乎一致。看来这也不起作用,只是把零值变成了一个负数,这个负数还是1e-7这种数量级的,跟零值没什么区别,这一猜测又宣告失败。
我又回到了刚开始的那个问题开始思考,为什么maxpool和avgpool的效果会有如此大的差别?我把经过maxpool之后和经过avgpool之后的响应值输出,发现了一些之前忽略的情况:avgpool输出的值通常在0到1之间,而maxpool输出的值有时可以达到6甚至到两位数!看到这一现象,我似乎有些明白了loss震荡的原因,应该是在经过一段时间的训练后,maxpool输出的值过大,导致接下来的卷积响应值也过大,这样累积到后面,最终输出的值就有可能变成NAN了。
猜测四:maxpool输出的值范围不当
既然认为maxpool输出的值范围不当,就需要一个函数来规范它。我首先想到用batch normalization,实验了一下发现不行,因为pytorch中的bn层附带了scale层,训练之后仍然会存在很大的激活值。我的目标是把它规范到0到1的范围内,所以我又选择了softmax,这样确保它能在0到1的范围内了。训练之后发现,震荡的现象消失了,看来猜测四是正确的。但是,尽管没有震荡,模型的效果也没有多大提升,这应该是因为softmax函数降低了响应值之间的差异性,还需要换个norm函数,既需要规范到0到1之间,又不能破坏响应值之间的差异性,我想到了L2Norm。终于,在maxpool后加上L2Norm后再训练,feature中响应值为零的节点数大幅下降,模型的效果也提升了很多,甚至超过了之前用avgpool时的效果。
结论:猜测四正确,解决方法是加上合适的norm层
三、正则化方法
经过了这一段经历和分析,我对norm层的重要性有了更加清晰的认识。在一个深度网络的设计过程中,norm层的存在是不可或缺的,缺少norm层会有很大的可能造成梯度震荡(梯度消失或梯度爆炸),而如何选择norm层,需要考虑到norm层本身的特点和前一层输出的响应值的分布。在我的模型里,选择L2Norm就比较合适,但是如果遇到其他的不同情况,可能就要换一换思路了。接下来我将介绍一些Norm算法的原理和特点。
Batch Normalization
batch normalization可以说是近几年来深度学习领域最重要的研究成果之一,它有效地加快了模型的收敛速度,在一定程度缓解了深层网络中“梯度弥散”的问题,从而使得训练深层网络模型更加容易和稳定。batch normalization的算法过程如下:
1.求当前batch的数据的均值u和方差sigma
2.将当前的所有数据减去均值u
3.将当前的所有数据除以方差的平方根sqrt(sigma)
4.将经过前三步之后得到的数据乘以gamma,再加上betta,这里的gamma和betta是可学习的参数
前三步很好理解,将数据减去均值,再除以方差,可以将数据归一到正态分布。那第四步该如何理解呢,又有什么作用呢?从公式上看,第四步相当于把已处于正态分布的数据乘以了一个尺度因子gamma,再加上了一个平移因子betta,这不是又逆向回原来的分布了吗?当然不是,第四步的gamma和betta是可学习的参数,网络会通过权重更新自己去调节这两个参数,使得它拟合现有的模型参数。如果取消了第四步,那相当于经过了bn层之后的数据都变成了正态分布,这样不利于网络去表达数据的差异性,会降低网络的性能,加上了第四步之后,网络会根据模型的特点自动地去调整数据的分布,更有利于模型的表达能力。
Group Normalization
Batch Normalization的效果虽好,但是它也有一些缺陷,当batch_size较小的时候,bn算法的效果就会下降,这是因为在较小的batch_size中,bn层难以学习到正确的样本分布,导致gamma和betta参数学习的不好。为了解决这一问题,Facebook AI Research提出了Group Normalization。
从上图可以看出,随着batch_size的减小,batch norm的error率逐渐上升,而group norm的error率几乎不变。在一些目标检测方面的模型中,例如faster-rcnn或mask-rcnn,当你只拥有一个GPU时,要求的batch_size通常为1或2张图片,这种情况下batch norm的效果就会大打折扣。那么group norm是如何改进这一点的呢?下面来看下group norm的算法流程:
1.将当前层的数据在通道的维度上划分为多个group
2.求出每个group中的数据的均值和方差
3.将每个group中的数据减去它们相应的均值再除以方差的平方根
4.将经过前三步之后得到的数据乘以gamma,再加上betta
可以看出,group normalization和batch normalization的算法过程极为相似,仅仅通过划分group这样的简单操作就改善了batch norm所面临的问题,在实际应用中取得了非常好的效果。
L2 Normalization
L2 norm其实是一个比较朴素的应用比较广泛的正则化算法,从过去的传统算法到现在的深度学习,从数据预处理到模型优化,都或多或少的会用到这个思想。其算法的过程也比较简单:
1.求出当前层数据的平方
2.求出当前层数据的平方和
3.将第一步得到的数据除以第二步得到的数据
这样一个简单的过程,会有什么作用呢?首先,经过L2 norm的数据都处于0到1之间。其次,经过L2 norm的数据之间的差异性会被放大。这两个特点能够在某些情况下发挥重要的作用,而在实际应用中,往往就是这样的小trick的累积最终形成了质变。
我所了解的L2 norm在深度学习中的应用,比较著名的有SSD目标检测器。作者在SSD中的conv4_3层后面加上了L2 norm,他的理由是该层的数据尺度与其他层不同,所以需要加上一个norm操作,具体的分析可看作者在github中的回复。
为什么ssd中的conv4_3层后面需要加上归一化?
https://github.com/weiliu89/caffe/issues/241
这里我做一些自己的思考和猜想,为什么仅仅是conv4_3层中的数据分布与其他层不同呢?我想原因应该与我遇到的问题相似,在网络的前面层中存在一些操作,使得卷积对样本的差异性敏感度增加,扩大了输出值的分布范围,经过了多层卷积之后,这样的敏感性被逐渐累积放大,直到conv4_3引起了质变。当然,这个想法的合理性还有待验证。
四、总结
在模型的迭代和优化中,很多时候就是一些微不住道的细节影响了整体的效果,着眼于大方面的结构和框架的同时,也要关注小方面的trick,这些trick的累积也能达到质变的效果。大的结构和框架虽然影响大,但是要想研究出一个合理的有效的结果是不容易的,而小trick虽然看起来影响小,但也确实会对整体的模型起着一定的作用。总之,训练模型时遇到不合理的现象时,可以按照下面的步骤去排查:
检查数据和标签,这是刚开始调试模型时最可能出错的方向。
检查训练参数和模型参数的设置,看看是否有不合理的地方。
检查网络框架中的具体操作的使用是否有错误。
检查不同的细节操作对网络的输出的影响。
希望这篇文章能给各位读者一定的启发,欢迎大家来讨论文章的细节和不足之处!