改进YOLOv5系列:10.最新HorNet结合YOLO应用首发! | ECCV2022出品,多种搭配,即插即用 | Backbone主干、递归门控卷积的高效高阶空间交互
YOLO Air:面向小白科研的YOLO检测项目-GitHub

- 统一使用 YOLOv5 代码框架,结合不同模块来构建不同的YOLO目标检测模型。
- 本项目包含大量的改进方式,降低改进难度,改进点包含
【Backbone特征主干】、【Neck特征融合】、【Head检测头】、【注意力机制】、【IoU损失函数】、【NMS】、【Loss计算方式】、【自注意力机制】、【数据增强部分】、【标签分配策略】、【激活函数】等各个部分,详情可以关注 YOLOAir 的说明文档。 - 可以排列组合上千种模块 不同的搭配 (推荐)
- 同时
附带各种改进点原理及对应的代码改进方式教程,用户可根据自身情况快速排列组合,在不同的数据集上实验, 应用组合写论文! - 项目地址:YOLOAir仓库:https://github.com/iscyy/yoloair
fork 和 star,持续同步更新完善
改进YOLO系列Trick QQ交流群: 569076270
本篇是《HorNet 递归门控卷积结构》的修改 演示
使用YOLOv5网络作为示范,可以无缝加入到 YOLOv7、YOLOX、YOLOR、YOLOv4、Scaled_YOLOv4、YOLOv3等一系列YOLO算法模块
更新
更新:新增YOLO中加入 C3HB 结构,参数量和计算量微涨

论文地址:https://arxiv.org/abs/2207.14284
文章目录
-
- YOLO Air:面向小白科研的YOLO检测项目-GitHub
-
- 更新
- 1、HorNet理论部分
- 2、如何使用HorNet,3种方式 将 HorNet 结合 YOLOv5 模型应用
-
- 3种使用方式演示:
- 1.在YOLOv5中 应用 gnconv 模块 代码示例
- 2、在YOLOv5中 应用 HorBlock 模块 代码示例
- 3、在YOLOv5中 应用 HorNet 作为主干网络 代码示例
- 4、在YOLOv5中 使用 新增C3HB结构 示例
- 5、训练yolov5s_HorNet.yaml模型(多种)
- 往期YOLO改进教程导航
1、HorNet理论部分
视觉Transformer的最新进展表明,在基于点积自注意力的新空间建模机制驱动的各种任务中取得了巨大成功。在本文中,作者证明了视觉Transformer背后的关键成分,即输入自适应、长程和高阶空间交互,也可以通过基于卷积的框架有效实现。作者提出了递归门卷积(g n Conv),它用门卷积和递归设计进行高阶空间交互。新操作具有高度灵活性和可定制性,与卷积的各种变体兼容,并将自注意力中的二阶交互扩展到任意阶,而不引入显著的额外计算。g nConv可以作为一个即插即用模块来改进各种视觉Transformer和基于卷积的模型。基于该操作,作者构建了一个新的通用视觉主干族,名为HorNet。在ImageNet分类、COCO对象检测和ADE20K语义分割方面的大量实验表明,HorNet在总体架构和训练配置相似的情况下,优于Swin Transformers和ConvNeXt。HorNet还显示出良好的可扩展性,以获得更多的训练数据和更大的模型尺寸。除了在视觉编码器中的有效性外,作者还表明g n Conv可以应用于任务特定的解码器,并以较少的计算量持续提高密集预测性能。本文的结果表明,g n Conv可以作为一个新的视觉建模基本模块,有效地结合了视觉Transformer和CNN的优点。
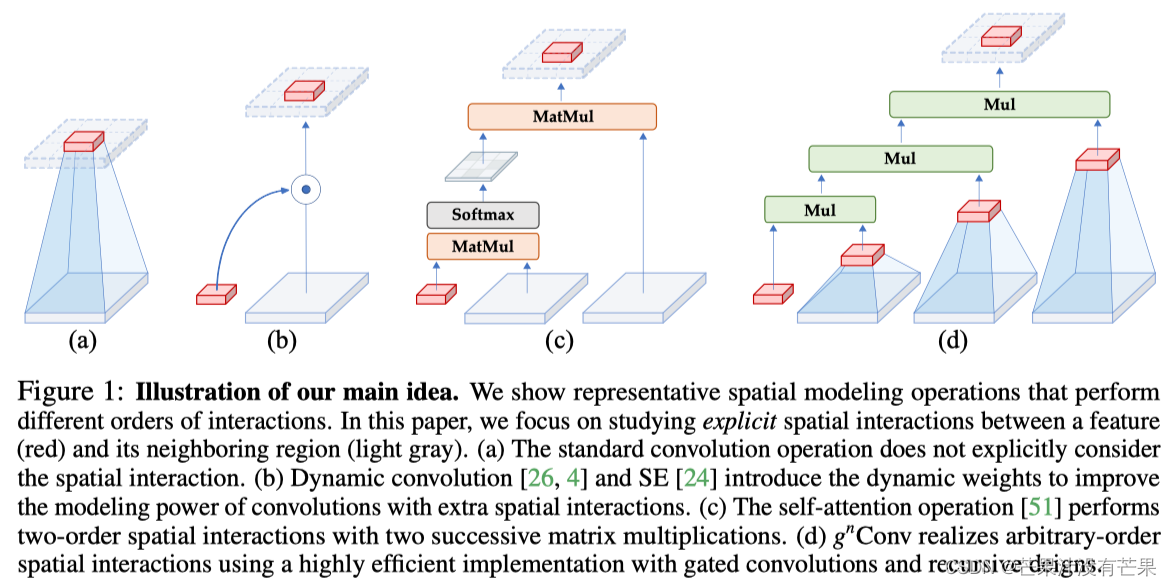
下图总结了g n Conv的细节实现:
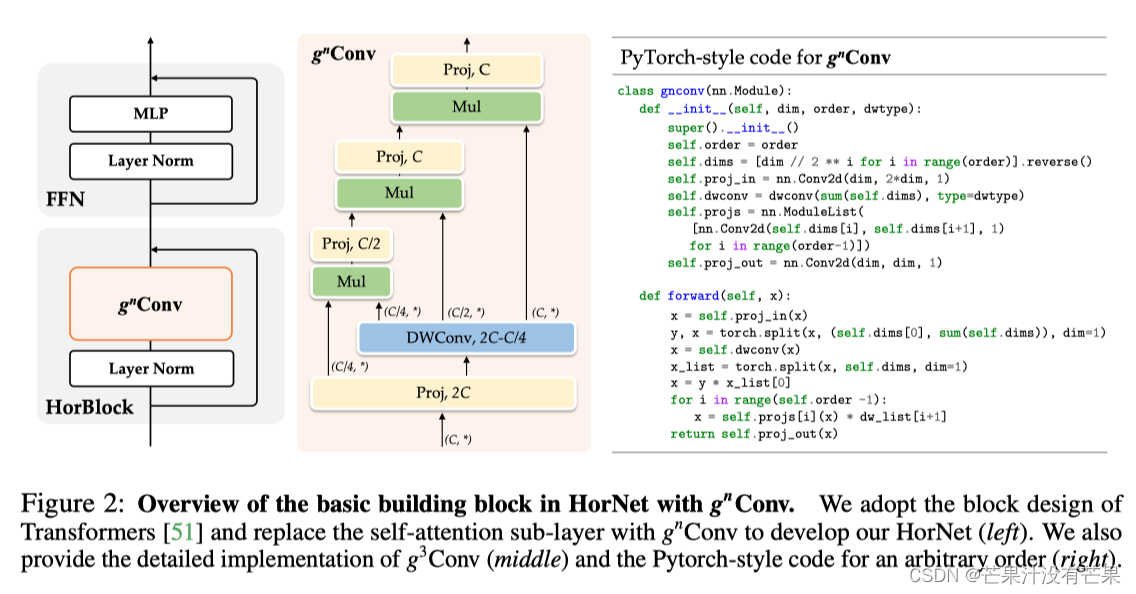
笔者 已经将 HorNet核心网络代码 整理在以下 Github 库中,地址为:
https://github.com/xmu-xiaoma666/External-Attention-pytorch
该库是一个 面向小白的顶会论文核心代码库。里面汇总诸多顶会论文核心代码,包括Attention、Self-Attention、Backbone、MLP、Conv等
2、如何使用HorNet,3种方式 将 HorNet 结合 YOLOv5 模型应用
代码在 YOLOAir仓库:https://github.com/iscyy/yoloair
3种使用方式演示:
1.在YOLOv5中 使用 gnconv模块 示例
2.在YOLOv5中 使用 HorBlock模块 示例
3.在YOLOv5中 使用 HorNet主干网络 示例
4.在YOLOv5中 使用 新增C3HB结构 示例
1.在YOLOv5中 应用 gnconv 模块 代码示例
第一步: 在 common.py 文件中添加如下代码
yolov5/models/common.py文件 新增代码
class gnconv(nn.Module): # gnconv模块
def __init__(self, dim, order=5, gflayer=None, h=14, w=8, s=1.0):
super().__init__()
self.order = order
self.dims = [dim // 2 ** i for i in range(order)]
self.dims.reverse()
self.proj_in = nn.Conv2d(dim, 2*dim, 1)
if gflayer is None:
self.dwconv = get_dwconv(sum(self.dims), 7, True)
else:
self.dwconv = gflayer(sum(self.dims), h=h, w=w)
self.proj_out = nn.Conv2d(dim, dim, 1)
self.pws = nn.ModuleList(
[nn.Conv2d(self.dims[i], self.dims[i+1], 1) for i in range(order-1)]
)
self.scale = s
def forward(self, x, mask=None, dummy=False):
fused_x = self.proj_in(x)
pwa, abc = torch.split(fused_x, (self.dims[0], sum(self.dims)), dim=1)
dw_abc = self.dwconv(abc) * self.scale
dw_list = torch.split(dw_abc, self.dims, dim=1)
x = pwa * dw_list[0]
for i in range(self.order -1):
x = self.pws[i](x) * dw_list[i+1]
x = self.proj_out(x)
return x
def get_dwconv(dim, kernel, bias):
return nn.Conv2d(dim, dim, kernel_size=kernel, padding=(kernel-1)//2 ,bias=bias, groups=dim)
第二步: 增加yolov5_gnconv.yaml配置文件(演示,可自行调整网络搭配)
# YOLOAir by iscyy, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 3, gnconv, [256]], # 修改示例
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第三步: 运行python train.py --cfg yolov5_gnconv.yaml
Model Summary: 275 layers, 7517693 parameters, 7517693 gradients, 17.6 GFLOPs
2、在YOLOv5中 应用 HorBlock 模块 代码示例
第一步: 在 common.py 文件中添加如下代码
同时将 gnconv 模块 加入到 common.py中
class HorBlock(nn.Module):# HorBlock模块
r""" HorNet block yoloair
"""
def __init__(self, dim, drop_path=0., layer_scale_init_value=1e-6, gnconv=gnconv):
super().__init__()
self.norm1 = HorLayerNorm(dim, eps=1e-6, data_format='channels_first')
self.gnconv = gnconv(dim)
self.norm2 = HorLayerNorm(dim, eps=1e-6)
self.pwconv1 = nn.Linear(dim, 4 * dim)
self.act = nn.GELU()
self.pwconv2 = nn.Linear(4 * dim, dim)
self.gamma1 = nn.Parameter(layer_scale_init_value * torch.ones(dim),
requires_grad=True) if layer_scale_init_value > 0 else None
self.gamma2 = nn.Parameter(layer_scale_init_value * torch.ones((dim)),
requires_grad=True) if layer_scale_init_value > 0 else None
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
def forward(self, x):
B, C, H, W = x.shape # [512]
if self.gamma1 is not None:
gamma1 = self.gamma1.view(C, 1, 1)
else:
gamma1 = 1
x = x + self.drop_path(gamma1 * self.gnconv(self.norm1(x)))
input = x
x = x.permute(0, 2, 3, 1) # (N, C, H, W) -> (N, H, W, C)
x = self.norm2(x)
x = self.pwconv1(x)
x = self.act(x)
x = self.pwconv2(x)
if self.gamma2 is not None:
x = self.gamma2 * x
x = x.permute(0, 3, 1, 2) # (N, H, W, C) -> (N, C, H, W)
x = input + self.drop_path(x)
return x
第二步: 增加yolov5_HorBlock.yaml配置文件(演示,可自行调整网络搭配)
# YOLOAir by iscyy, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, HorBlock, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, HorBlock, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, HorBlock, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, HorBlock, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第三步:在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m in HorBlock:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in HorBlock:
args.insert(2, n)
n = 1
第四步: 运行python train.py --cfg yolov5_HorBlock.yaml
Model Summary: 215 layers, 9462189 parameters, 9462189 gradients, 21.6 GFLOPs
3、在YOLOv5中 应用 HorNet 作为主干网络 代码示例
第一步: 在 common.py 文件中添加如下代码
同时将 gnconv模块 和 HorBlock模块 加入到 common.py中
class HorNet(nn.Module): # HorNet
# hornet by iscyy/yoloair
def __init__(self, index, in_chans, depths, dim_base, drop_path_rate=0.,layer_scale_init_value=1e-6,
gnconv=[
partial(gnconv, order=2, s=1.0/3.0),
partial(gnconv, order=3, s=1.0/3.0),
partial(gnconv, order=4, s=1.0/3.0),
partial(gnconv, order=5, s=1.0/3.0), # GlobalLocalFilter
],
):
super().__init__()
dims = [dim_base, dim_base * 2, dim_base * 4, dim_base * 8]
self.index = index
self.downsample_layers = nn.ModuleList() # stem and 3 intermediate downsampling conv layers hornet by iscyy/air
stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
HorLayerNorm(dims[0], eps=1e-6, data_format="channels_first")
)
self.downsample_layers.append(stem)
for i in range(3):
downsample_layer = nn.Sequential(
LayerNorm(dims[i], eps=1e-6, data_format="channels_first"),
nn.Conv2d(dims[i], dims[i+1], kernel_size=2, stride=2),
)
self.downsample_layers.append(downsample_layer)
self.stages = nn.ModuleList() # 4 feature resolution stages, each consisting of multiple residual blocks
dp_rates=[x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))]
if not isinstance(gnconv, list):
gnconv = [gnconv, gnconv, gnconv, gnconv]
else:
gnconv = gnconv
assert len(gnconv) == 4
cur = 0
for i in range(4):
stage = nn.Sequential(
*[HorBlock(dim=dims[i], drop_path=dp_rates[cur + j],
layer_scale_init_value=layer_scale_init_value, gnconv=gnconv[i]) for j in range(depths[i])]# hornet by iscyy/air
)
self.stages.append(stage)
cur += depths[i]
self.apply(self._init_weights)
def _init_weights(self, m):
if isinstance(m, (nn.Conv2d, nn.Linear)):
nn.init.trunc_normal_(m.weight, std=.02)
nn.init.constant_(m.bias, 0)
def forward(self, x):
x = self.downsample_layers[self.index](x)
x = self.stages[self.index](x)
return x
第二步: 增加yolov5_HorNet.yaml配置文件(演示,可自行调整网络搭配)
# YOLOAir by iscyy, GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLO backbone
backbone:
[[-1, 1, HorNet, [32, 0, 3, [2, 3, 18, 2], 32]],
[-1, 1, HorNet, [64, 1, 3, [2, 3, 18, 2], 32]],
[-1, 1, HorNet, [128, 2, 3, [2, 3, 18, 2], 32]],
[-1, 1, HorNet, [256, 3, 3, [2, 3, 18, 2], 32]],
]
# YOLOv5 head
head:
[[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 2], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[-1, 1, Conv, [128, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 1], 1, Concat, [1]],
[-1, 3, C3, [128, False]],
[-1, 1, Conv, [128, 3, 2]],
[[-1, 8], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[-1, 1, Conv, [256, 3, 2]],
[[-1, 4], 1, Concat, [1]],
[-1, 3, C3, [256, False]],
[[11, 14, 17], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第三步:在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m is HorNet:
c2 = args[0]
args = args[1:]
第四步: 运行python train.py --cfg yolov5_HorBlock.yaml
Model Summary: 1677 layers, 23159229 parameters, 23159229 gradients, 18.4 GFLOPs
4、在YOLOv5中 使用 新增C3HB结构 示例
第一步: 在 common.py 文件中添加如下代码
class C3HB(nn.Module):
# CSP HorBlock with 3 convolutions by iscyy/yoloair
def __init__(self, c1, c2, n=1, shortcut=True, g=1, e=0.5): # ch_in, ch_out, number, shortcut, groups, expansion
super().__init__()
c_ = int(c2 * e) # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.cv3 = Conv(2 * c_, c2, 1)
self.m = nn.Sequential(*(HorBlock(c_) for _ in range(n)))
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), dim=1))
第二步: 增加yolov5_C3HB.yaml配置文件(演示,可自行调整网络搭配)
# YOLOAir by , GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, C3, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3HB, [512]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3HB, [256]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3HB, [512]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3HB, [1024]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
# backbone
# YOLOAir by , GPL-3.0 license
# Parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
# YOLOv5 v6.0 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Conv, [64, 6, 2, 2]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, C3, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 6, C3, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 3, C3HB, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 3, C3HB, [1024]],
[-1, 1, SPPF, [1024, 5]], # 9
]
# YOLOv5 v6.0 head
head:
[[-1, 1, Conv, [512, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, C3, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, C3, [256, False]], # 17 (P3/8-small)
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, C3, [512, False]], # 20 (P4/16-medium)
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, C3, [1024, False]], # 23 (P5/32-large)
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
第三步:在 models/yolo.py文件夹下
- 定位到parse_model函数中
for i, (f, n, m, args) in enumerate(d['backbone'] + d['head']):内部- 对应位置 下方只需要新增以下代码
elif m in C3HB:
c1, c2 = ch[f], args[0]
if c2 != no:
c2 = make_divisible(c2 * gw, 8)
args = [c1, c2, *args[1:]]
if m in C3HB:
args.insert(2, n)
n = 1
第四步: 运行python train.py --cfg yolov5_C3HB.yaml
Model Summary: 298 layers, 7468429 parameters, 7468429 gradients, 17.1 GFLOPs
5、训练yolov5s_HorNet.yaml模型(多种)
python train.py --cfg yolov5s_HorNet.yaml
关于yolov5s_HorNet.yaml文件配置,可以针对不同数据集自行再进行模块修改,原理一致
往期YOLO改进教程导航
-
9.改进YOLOv5系列:9.BoTNet Transformer结构的修改
-
8.改进YOLOv5系列:8.增加ACmix结构的修改,自注意力和卷积集成
-
7.改进YOLOv5系列:7.修改DIoU-NMS,SIoU-NMS,EIoU-NMS,CIoU-NMS,GIoU-NMS
-
6.改进YOLOv5系列:6.修改Soft-NMS,Soft-CIoUNMS,Soft-SIoUNMS
-
5.改进YOLOv5系列:5.CotNet Transformer结构的修改
-
4.改进YOLOv5系列:4.YOLOv5_最新MobileOne结构换Backbone修改
-
3.改进YOLOv5系列:3.Swin Transformer结构的修改
-
2.改进YOLOv5系列:2.PicoDet结构的修改
-
1.改进YOLOv5系列:1.多种注意力机制修改