数据运营平台-数据采集
目录
行为数据采集
业务数据采集与转换
第三方系统API对接
用户数据关联
人工数据采集
数据输出
行为数据采集
1.埋点采集
①跨平台打通
确定性方法识别
利用用户帐号体系中,可以是系统生成的 UserID,可以是手机号,也可以是邮箱,不同的产品情况略有差异,总之就是用户唯一的标识。 如果应用在 Android、iOS、Web、微信公众号四个平台上运营,各个平台用统一的帐号体系。假如小明有Android、iOS、PC三台设备,早上在Android 的微信公众号上看了一个推荐的,中午登录了网页查看了详细信息,晚上回家在iOS 手机上下了单,那么完全可以通过UserID将用户行为连贯起来。
概率论方法匹配
使用设备相关的间接数据来匹配,Cookie、IDFA、上网时间、Wifi、IP 等等,通过机器学习或者其他复杂的规则来分析。但是严重依赖于数据的多样性和算法,相对确定性的方法来说,准确性差距很大,不推荐。
②埋点方案设计
用户行为是由用户一系列的事件组成,包含5个基本要素:何人,何时,何地,通过何种方式,发生了何种行为,一份完整的埋点方案由事件、事件属性和用户属性三部分组成:
事件:记录用户在使用网站、APP 或小程序的过程中触发的行为。
用户的行为有一部分会在他们使用的过程中自动被采集上来,常见的如:与访问有关的“页面浏览”,“停留时长”;另外一部分包含具体业务含义的,则需要通过埋点才能得到,例如:“注册”、“登录”、“支付”等等。
事件属性:通过属性为事件补充相关的信息,例如:位置,方式和内容。
用户产生行为时就会上报具体的属性值,比如对“购买事件”定义了“支付方式”的属性值,则根据不同的行为可能上报的是微信支付,支付宝支付。
例如:在采购平台上花十万元购买一辆汽车。这个动作就产生一个名为“购买”的事件; 而“购买”事件,同时也可以包含:“品牌”,“价格”这两个属性,而“东风”和“十万元”就是属性的具体值了。
| Event要素 |
要素说明 |
采集的数据 |
示例 |
| Who |
参与事件的用户 |
用户唯一ID |
H522a3bd525a2af |
| When |
事件发生的时间 |
自动获取事件当时时间 |
11月11日00:02:03 |
| Where |
事件发生的地理位置 |
自动获取 IP、GPS信息 |
114.242.249.113 |
| How |
事件发生的方式 |
使用的环境 |
设备品牌:Apple 设备型号:iPhone 6s 操作系统:iOS 屏幕分辨率:1920*1680 运营商:中国联通 网络类型:Wifi …… |
| What |
事件的内容 |
自定义采集的事件:EventID 事件属性:Key-Value |
add_to_cart product_name:耳麦 product_price:666 |
用户、时间、地理位置、事件发生的环境等可以自动采集,采集哪些事件、事件更丰富的属性需要用户自己来上报。
事件模板:
| 事件ID |
事件名称 |
事件说明 |
属性ID |
属性名称 |
属性说明 |
属性值类型 |
| PayOrder |
支付订单 |
点击支付按钮时触发 |
paymentMethod |
支付方式 |
|
字符型 |
| ViewDetailPage |
浏览页详情 |
点击详情页时触发 |
PageID |
页面ID |
|
字符型 |
模板例子:
| 平台 |
事件ID |
事件显示名称 |
事件说明 |
属性ID |
属性显示名称 |
属性说明 |
属性值数据类型 |
| Android,iOS |
$signup |
注册 |
注册成功时触发 |
username |
用户名 |
用户输入的用户名 |
字符串 |
|
|
|
|
|
company |
所在公司 |
所在公司信息 |
字符串 |
|
|
|
|
|
age |
年龄 |
用户年龄 |
字符串 |
| Android,iOS |
login |
登录 |
点击登录成功时触发 |
|
|
|
|
分析应用当前所处的阶段,设置合理的目标,拉新、促活等等;
分析实现目标需要采集哪些数据;
按照模板梳理需要埋点的事件、事件属性
平台:输入需要埋点的平台,仅支持输入 Android、iOS、Web/H5、小程序、其他、未知这6个选项,多个平台时,英文逗号分隔
事件ID:用于工程师埋点,唯一标识事件,仅支持$、字母、数字和下划线,不能以数字或下划线开头,上限125个半角字符,$仅用于预置事件
事件显示名称:用于在产品中显示事件名称,不支持特殊字符,上限50个半角字符
事件说明:用于说明事件的触发条件、埋点位置等帮助工程师理解埋点需求,不支持特殊字符,上限100个半角字符
属性ID:更丰富的描述事件,属性ID用于唯一标识事件属性,命名规则同事件ID,当有多个属性时,自行增加行
属性显示名称:用于显示属性名称,不支持特殊字符,上限50个半角字符
属性说明:用于说明事件的属性,不支持特殊字符,上限100个半角字符
属性值类型:选择不同的属性值类型,不同的类型在分析时会有不同的处理方式,仅支持定义为 字符串、数值、布尔、日期或集合类型
用户属性:分析过程中,需要引入注册用户的更多维度,比如注册用户ID、姓名、用户等级等等,也需要进行梳理,方法同事件属性。
| 用户属性ID |
用户属性名称 |
属性说明 |
属性值类型 |
||||
| UserLevel |
用户等级 |
上传用户的等级信息 |
字符型 |
||||
| 用户属性ID |
属性显示名称 |
属性说明 |
属性值数据类型 |
||||
| username |
用户名 |
用户名 |
字符串 |
||||
| company |
所在公司 |
所在公司名称 |
字符串 |
||||
| age |
年龄 |
用户年龄 |
字符串 |
||||
确定要分析的用户维度;
按照模板格式梳理需要埋点上传的用户属性:
用户属性ID:唯一标识描述的用户维度,仅支持$、字母、数字和下划线,不能以数字或下划线开头,上限125个半角字符,$仅用于预置属性,当有多个属性时,自行增加行;
属性显示名称:用于显示属性名称,不支持特殊字符,上限50个半角字符;
属性说明:用于说明用户属性的含义、上报时机等,不支持特殊字符,上限100个半角字符;
属性值类型:选择不同的属性值类型,不同的类型在分析时会有不同的处理方式,仅支持定义为 字符串、数值、布尔、日期 或 集合 类型;
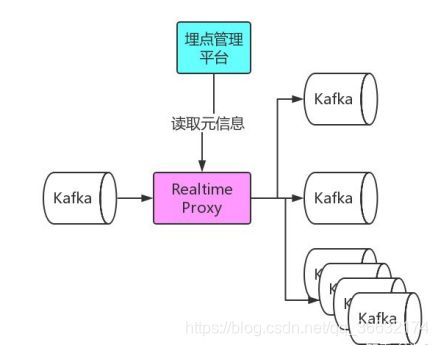
对采集到的埋点写入到 Kafka 中,对于各个业务的实时数据消费需求,我们为每个业务提供了单独的 Kafka,流量分发模块会定期读取埋点管理平台提供的元信息,将流量实时分发的各业务 Kafka 中。
③客户端埋点数据验证
对埋点后的执行进行验证,最佳办法是根据实际验证需求做出可视化埋点验证工具,或对接第三方埋点验证服务。但是如果不想花费此成本,也可以做以下的方案处理:
客户端有操作时,验证是否会正确触发上报;
查看上报事件的属性(名称、属性名称及类型)是否符合预期;
了解到客户端操作的行为序列;
网站埋点(JS)
调试模式开启时:
debugMode: 1 或 2;SDK 会向浏览器的控制台中输出日志。日志中会包含一些告警、错误,也会包含上报事件的内容。
以 Chrome 为例,步骤如下:
· 启动 Chrome,并访问已经埋好点的网站
· 按 F12 或 Ctl/Cmd + Alt/Opt + I 打开 “开发者工具”
· 点击 “Console” 页签进入控制台
· 正常浏览页面,接可以看到控制台有大量的日志

接下来,为了方便查看事件报文的内容,我们可以在过滤器中设定关键字“analysys”筛选出报文。
· SDK初始化相关日志
· Send message to server: **实际上报地址**
· 上报数据相关日志
如日志发送成功,控制台会输出:Send message success
调试模式未开启时:
debugMode: 0,生产环境通常会关闭调试模式,在调试模式未开启时SDK不会向浏览器的控制台发送任何日志,这对调试造成了一些不利。但通过浏览器自带的开发者工具也查看到上报的事件内容。下面以 Chrome 为例,介绍相应的测试方法。

步骤如下:
· 启动 Chrome,并访问已经埋好点的网站
· 按 F12 或 Ctl/Cmd + Alt/Opt + I 打开 “开发者工具”
· 如上图,点击“Network”页签
· 正常浏览页面,就能在浏览器中看到上报的埋点日志

· 如上图,在左上方红框位置的过滤器中输入“up?”
· 点击每条记录,就能在右侧红框“Request Payload”中看到上报报文的内容了。
APP埋点(iOS/Android)
移动端 SDK 也会输出日志,开发者可以按照下面的说明开启调试模式,通过 SDK 的日志调试。同时我们也提供一种面向非开发者的,通过抓包工具来查看上报日志的方式。
开发者,先在代码中设置调试状态开启:
Andorid环境
AnalysysAgent.setDebugMode(this, 2);
0:关闭 Debug 模式
1:打开 Debug 模式,但该模式下发送的数据仅用于调试,不计入平台数据统计
2:打开 Debug 模式,该模式下发送的数据可计入平台数据统计
iOS环境
AnalysysAgent setDebugMode:AnalysysDebugButTrack
AnalysysDebugOff:关闭 Debug 模式
AnalysysDebugOnly:打开 Debug 模式,但该模式下发送的数据仅用于调试,不计入平台数据统计
AnalysysDebugButTrack:打开 Debug 模式,该模式下发送的数据可计入平台数据统计
使用 Eclipse、AndroidStudio 或 Xcode 工具等,请在 Console 中搜索 tag 为“Analysys”
初始化成功后,控制台会输出:
· SDK初始化相关日志
· Send message to server: **实际上报地址**
· 上报数据相关日志
日志发送成功,控制台会输出:Send message success
非开发者,往往 App 已经安装在手机上,若想调试需要将 App 的流量发送到流量分析工具中进行调试。以下有几个知名度比较高的工具可供参考:
mitmproxy
https://mitmproxy.org/#mitmweb
Charles
https://www.charlesproxy.com/download/
Fiddler
https://www.telerik.com/fiddler
步骤如下:
从上述流量监控工具中选择适合您的,安装并按提示将您 app 的流量转发到工具里
· 在工具中的过滤器中输入“up?”
· 正常使用 app,就能在工具中看到上报的埋点日志
· 点击每条记录,就能查看上报报文的内容了
④Matomo采集
- Matomo统计添加方法
A.在Matomo上创建网站
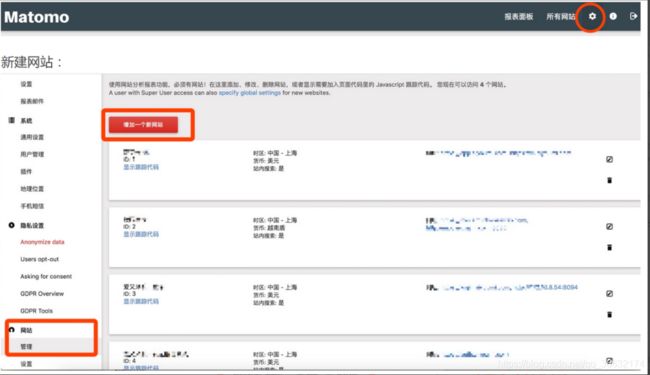
编辑内容

项目网址就是要统计的目标网址,统计代码添加后凡以此开头的都会被记录到Matomo,添加后就会产生如下网站记录,注意那个ID后面的统计代码里面都要用到
B.添加统计代码
Vue的方式
import Vue from 'vue'import VueMatomo from 'vue-matomo'// matomo用户统计--类似于友盟
Vue.use(VueMatomo, {
// 这里配置你自己的piwik服务器地址和网站ID
host: 'https://bayes.test.com/piwik',
siteId: 412,
// 根据router自动注册
router: router,
// 是否需要在发送追踪信息之前请求许可
// 默认false
requireConsent: false,
// 是否追踪初始页面
// 默认true
trackInitialView: true,
// 最终的追踪js文件名
// 默认 'piwik'
trackerFileName: 'piwik'
})
纯Js的方式
- vue+vue-matomo实现埋点
在安装好vue脚手架后,首先引入vue-matomo:npm i vue-matomo
在 main.js中配置:
import VueMatomo from 'vue-matomo'
Vue.use(VueMatomo, {
host: `你自己的matomo地址`,
siteId: '这个值页需要去matomo上去申请', // siteId值
// 根据router自动注册,需要注意的是如果有路由传值值太长的话会matomo会监听不到并报414,就不能使用此方法了
router: router,
// 是否需要在发送追踪信息之前请求许可
// 默认false
requireConsent: false,
enableLinkTracking: true,
// 是否追踪初始页面
// 默认true
trackInitialView: false,
// 最终的追踪js文件名,因为我这边的matomo版本比较老,所以使用的是piwik,现在版本新的话此值应该为matomo
trackerFileName: 'piwik',
debug: true,
userId:'当前用户登录Id,可根据需求来设置,非必传,也可以在用户登录成功之后设置'})
到此,就已经可以监听到页面访问、加载时间、访问次数、访问时间、实时访客等等数据。如图:
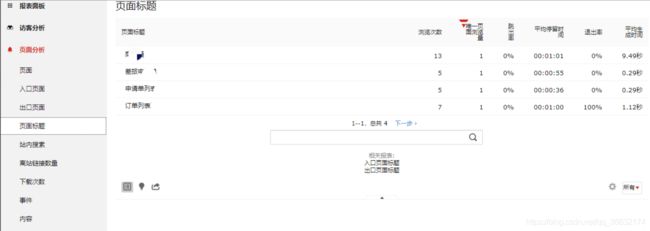
- matomo数据收集案例
内容收集-例:
事件收集-例:
_paq.push(['trackPageView']);
_paq.push(['trackEvent', 'Img', 'Clicked', 'handle']);
_paq.push(['trackAllContentImpressions']);
2、日志采集
方式一、通过采集架构的日志数据,从而形成基于日志的用户行为分析机制,其执行流程如下:
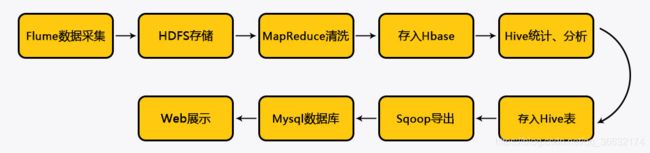
日志分析的总体架构就是使用Flume从nginx所在服务器上采集日志文件,并存储在HDFS文件系统上,使用mapreduce清洗日志文件,最后使用HIVE构建数据仓库做离线分析。任务的调度使用Shell脚本完成,当然大家也可以尝试一些自动化的任务调度工具,比如说AZKABAN或者OOZIE等。分析所使用的点击流日志文件主要来自Nginx的access.log日志文件,需要注意的是在这里并不是用Flume直接去生产环境上拉取nginx的日志文件,而是多设置了一层FTP服务器来缓存所有的日志文件,然后再用Flume监听FTP服务器上指定的目录拉取目录里的日志文件到HDFS服务器上。从生产环境推送日志文件到FTP服务器的操作可以通过Shell脚本配合Crontab定时器来实现。一般在WEB系统中,用户对站点的页面的访问浏览,点击行为等一系列的数据都会记录在日志中,每一条日志记录就代表着上图中的一个数据点;而点击流数据关注的就是所有这些点连起来后的一个完整的网站浏览行为记录,可以认为是一个用户对网站的浏览session。比如说用户从哪一个外站进入到当前的网站,用户接下来浏览了当前网站的哪些页面,点击了哪些图片链接按钮等一系列的行为记录,这一个整体的信息就称为是该用户的点击流记录。本次设计的离线分析系统就是收集WEB系统中产生的这些数据日志,并清洗日志内容存储分布式的HDFS文件存储系统上,接着使用HIVE去统计所有用户的点击流信息。
PageViews建模例子
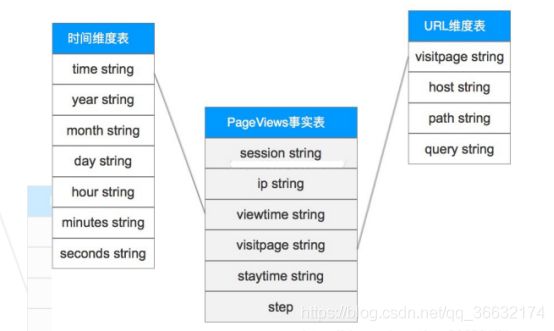
Visits建模例子

方式二、ELK日志分析系统
ELK是一组开源软件的简称,其包括Elasticsearch、Logstash 和 Kibana,目前最流行的集中式日志解决方案。
Elasticsearch: 能对大容量的数据进行接近实时的存储,搜索和分析操作。 主要通过Elasticsearch存储所有获取的日志。
Logstash: 数据收集引擎,支持动态的的从各种数据源获取数据,并对数据进行过滤,分析,丰富,统一格式等操作,然后存储到用户指定的位置。
Kibana: 数据分析与可视化平台,对Elasticsearch存储的数据进行可视化分析,通过表格的形式展现出来。
Filebeat: 轻量级的开源日志文件数据搜集器。通常在需要采集数据的客户端安装Filebeat,并指定目录与日志格式,Filebeat就能快速收集数据,并发送给logstash进行解析,或是直接发给Elasticsearch存储。
Redis:NoSQL数据库(key-value),也数据轻型消息队列,不仅可以对高并发日志进行削峰还可以对整个架构进行解耦


Logstash主要组成如下:
inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
Filebeats作为一种轻量级的日志搜集器,其不占用系统资源,自出现之后,迅速更新了原有的elk架构。Filebeats将收集到的数据发送给Logstash解析过滤,在Filebeats与Logstash传输数据的过程中,为了安全性,可以通过ssl认证来加强安全性。之后将其发送到Elasticsearch存储,并由kibana可视化分析。
业务数据采集与转换
大数据平台的数据来源广泛,根据来源,大致分为两类:
1)内部
a)手工填报
b)流+实时数据采集
c)批量
2)外部
a)文件导入
b)网络爬虫
c)对外接口服务
根据以上分类提供以下方案:
1、实时数据采集转换
实时采集选用Flume技术、消息队列选Kafka技术,在线实时处理选用Storm技术、关系型数据库可以选MySQL、Oracle多种类型,实时内存数据库选用Redis、历史大数据存储可选用MongoDB。数据采集系统体系结构如下图所示:
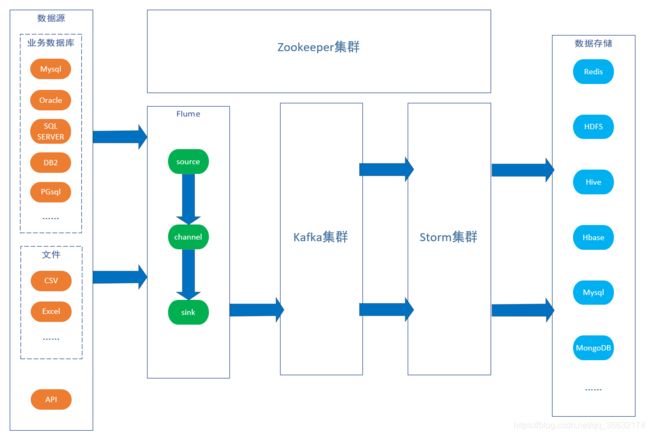
Flume是一个分布式、高可靠和高可用的数据采集采集系统。可针对不同数据源、不同结构的海量数据进行高效收集、聚合和传输,具备良好的扩展性、伸缩性和容错性。Flume由一系列的称为Agent的组件构成,每一个Agent内部包含三个组件,分别是Source、Channel、Sink。Flume的每个组件是可插拔、可定制的,其本质上是一个中间件,有效屏蔽了数据源与目标源之间的异构性,便于系统的扩展和升级。Source可定制开发从外部系统或Agent接收数据,并写入一个或多个Channel;Channel是一个缓冲区,缓冲Source写入的数据,知道Sink发送出去;Sink负责从Channel中读取数据,并发送给消息队列或存储系统,甚至于是另一个Agent。
针对不同通讯协议或者不同数据量级的数据源,定制开发一个Agent,在Agent内部采用Memory Channel缓存,以提升性能,采用Kafka Sink将Channel中的数据写入Kafka。
在实际应用中,不同数据源(数据生产者)产生的实时数据,需要经过不同的系统进行逻辑和业务处理,同时被写入历史数据库和Storm集群(数据消费者)进行离线大数据分析和在线实时分析。采用Kafka作为消息缓冲区,Kafka提供了高容错性和可扩展性,允许可靠地缓存更多的实时数据,以便于多个消费者重复读取。
Storm是为在线实时处理提供便利,实时采集数据,在Storm中实现模型化处理、简单的统计分析、数据存储等功能。Storm会根据实际业务应用的要求,将数据存储在实时内存数据库Redis、关系型数据库MySQL、历史大数据库MongoDB、HDFS等系统。
Kafka和Storm由Zookeeper集群化管理,这样即使Kafka宕机重启后也能找到上次的消费记录,接着从上次宕机点继续从Kafka的Broker中进行消费。但是由于存在先消费后记录日志或者先记录后消费的非原子操作,如果出现刚好消费完一条消息并还没将信息记录到Zookeeper的时候就宕机的类似问题,或多或少都会存在少量数据丢失或重复消费的问题,可选择Kafka的Broker和Zookeeper都部署在同一台机子上。接下来就是使用用户定义好的Storm Topology去进行数据的分析并输出到Redis缓存数据库中(也可以进行持久化)。
在Flume和Storm中间加入一层Kafka消息系统,就是因为在高并发的条件下, 数据会井喷式增长,如果Storm的消费速度(Storm的实时计算能力那是最快之一,但是也有例外, 而且据说现在Twitter的开源实时计算框架Heron比Storm还要快)慢于数据的产生速度,加上Flume自身的局限性,必然会导致大量数据滞后并丢失,所以加了Kafka消息系统作为数据缓冲区,而且Kafka是基于log File的消息系统,也就是说消息能够持久化在硬盘中,再加上其充分利用Linux的I/O特性,提供了可观的吞吐量。架构中使用Redis作为数据库也是因为在实时的环境下,Redis具有很高的读写速度。
2、批量数据采集转换
批量数据采集有多种方案,比如通过开源组件sqoop、kettle等,或者通过阿里的DataX离线同步服务完成。批量数据的执行周期可自写定时任务,也可利用工具自带定时机制完成。
1)Sqoop
主要用于在Hadoop(HDFS、Hive、HBase)与数据库(mysql、postgresql、MongoDB…)间进行数据的传递,可以将一个数据库中的数据导进到Hadoop的HDFS中,也可以将HDFS的数据导进到关系型数据库中。

Sqoop Client 通过 shell 命令来使用 Sqoop,Sqoop 中的 Task Translater 将命令转换成 Hadoop 中的 MapReduce 任务进行具体的数据操作。例如 Mysql 中某个表数据同步到 Hadoop 这个场景,Sqoop 会将表记录分成多份,每份分到各自 Mapper 中去进行落地 Hadoop(保证同步效率),这里的 MapReduce没有 reduce,只有 map。
2)Kettle
Kettle作为开源的ETL工具,具有比较完备的功能,同样支持多种数据源的采集转换功能,同时自带任务机制,无需自行手动编写定时任务;kettle提供Spoon可视化组件,可以视图形式完成转换任务及作业的创建,提高工作效率。
3)DataX
DataX 是阿里巴巴集团内被广泛使用的离线数据同步工具/平台,实现包括 MySQL、Oracle、SqlServer、Postgre、HDFS、Hive、ADS、HBase、TableStore(OTS)、MaxCompute(ODPS)、DRDS 等各种异构数据源之间高效的数据同步功能。

所支持的数据源如下,也可自行开发插件:

3、API接口
通过 Restful API 可以将历史数据通过网络上报到大数据平台,这种方式一般适用于数据量不太大的情况。
调用该接口,把符合特定格式的数据以POST的方式上报至服务器。接收服务器对上报的数据进行校验,不符合格式的返回相应的错误提示。上报后的数据会先暂存在 Kafka 中,流处理引擎大约会以3000条/秒的速度将数据落库并可用于查询,该过程性能受服务器影响,但偏差一般不会太大。
接口协议:HTTP(S),POST方式
请求地址:http(s)://host:port/up
请求数据:请求的 Body 体里面存放具体要上报的数据,数据明文为 JsonArray 的形式。上报的数据明文示例如下:
[{
"appid": "demo",
"xwho": "8c0eebf0-2383-44bc-b8ba-a5c719fc6194",
"xwhat": "confirmOrder",
"xwhen": 1532514947857,
"xcontext": {
"$channel": "豌豆荚",
"$app_version": "4.0.4.001",
"$model": "MI 6X",
"$os": "Android",
"$os_version": "8.1.0",
"$lib": "Android",
"$platform": "Android",
"$is_login": false,
"$lib_version": "4.0.4",
"$debug": 2,
"$importFlag": 1 //说明:$importFlag字段是专门用作导数
}
}]
数据编码:使用 UTF-8 编码。上报数据可以使用明文上报,也可以对数据进行压缩/编码处理后进行上报。压缩/编码过程具体为:先进行Gzip压缩,然后进行Base64编码,最后把编码后的数据直接放到Body体里面上报即可。
应答格式
上报成功:{"code":200}
上报失败:{"code":500}
上报数据格式错误:{"code":xxx, "msg":"xxxxx"},返回的应答消息中包含"msg"字段,内容为具体的异常信息。
4、网络爬虫
网络爬虫作为侵入式采集,特殊的存在,涉及诸多安全问题,需慎用。
第三方系统API对接
1、对接概要
从第三方平台获取数据最合理方式就是通过开放的接口获取所需数据,获取到所需接口后,首先需要做的有以下几点:
1)需要账号的要先申请账号。
2)申请完账号,严格对照接口文档开发。
3)注意文档的每个字段。都有它的特殊含义。
4)拼接第三方的参数接口最好写在配置文件中,方便修改
5)如第三方(微信,qq)登录授权,微信,银联支付等 需要拼接参数的,发送请求。成功后返回所需要的信息进行业务处理。
2、对接方案
1)对接方式
平台与外部系统对接方式多以web service方式。
系统接口标准:
以SOA体系架构为基础,服务总线技术实现数据交换以及实现各业务子系统间、外部业务系统之间的信息共享和集成,因此SOA体系标准就是我们采用的接口核心标准。主要包括:
服务目录标准:服务目录API接口格式参考国家以及关于服务目录的元数据指导规范,对于W3C UDDI v2 API结构规范,采取UDDI v2的API的模型,定义UDDI的查询和发布服务接口,定制基于Java和SOAP的访问接口。除了基于SOAP1.2的Web Service接口方式,对于基于消息的接口采用JMS或者MQ的方式。
交换标准:基于服务的交换,采用HTTP/HTTPS作为传输协议,而其消息体存放基于SOAP1.2协议的SOAP消息格式。SOAP的消息体包括服务数据以及服务操作,服务数据和服务操作采用WSDL进行描述。
Web服务标准:用WSDL描述业务服务,将WSDL发布到UDDI用以设计/创建服务,SOAP/HTTP服务遵循WS-I Basic Profile 1.0,利用J2EE Session EJBs实现新的业务服务,根据需求提供SOAP/HTTP or JMS and RMI/IIOP接口。
业务流程标准:使用没有扩展的标准的BPEL4WS,对于业务流程以SOAP服务形式进行访问,业务流程之间的调用通过SOAP。
数据交换安全:与外部系统对接需考虑外部访问的安全性,通过IP白名单、SSL认证等方式保证集成互访的合法性与安全性。
数据交换标准:制定适合双方系统统一的数据交换数据标准,支持对增量的数据自动进行数据同步,避免人工重复录入的工作。
2)接口规范性设计
系统平台中的接口众多,依赖关系复杂,通过接口交换的数据与接口调用必须遵循统一的接口模型进行设计。接口模型除了遵循工程统一的数据标准和接口规范标准,实现接口规范定义的功能外,需要从数据管理、完整性管理、接口安全、接口的访问效率、性能以及可扩展性多个方面设计接口规格。
接口定义约定
客户端与系统平台以及系统平台间的接口消息协议采用基于HTTP协议的REST风格接口实现,协议栈如图所示。
 接口消息协议栈示意图
接口消息协议栈示意图
系统在http协议中传输的应用数据采用具有自解释、自包含特征的JSON数据格式,通过配置数据对象的序列化和反序列化的实现组件来实现通信数据包的编码和解码。
在接口协议中,包含接口的版本信息,通过协议版本约束服务功能规范,支持服务平台间接口协作的升级和扩展。一个服务提供者可通过版本区别同时支持多个版本的客户端,从而使得组件服务的提供者和使用者根据实际的需要,独立演进,降低系统升级的复杂度,保证系统具备灵活的扩展和持续演进的能力。
业务消息约定
请求消息URI中的参数采用UTF-8编码并经过URLEncode编码。
请求接口URL格式:{http|https}://{host}:{port}/
{app name}/{business component name}/{action};其中:
协议:HTTP REST形式接口
host:应用支撑平台交互通信服务的IP地址或域名
port:应用支撑平台交互通信服务的端口
app name:应用支撑平台交互通信服务部署的应用名称
business component name:业务组件名称
action:业务操作请求的接口名称,接口名字可配置
应答的消息体采用JSON数据格式编码,字符编码采用UTF-8。
应答消息根节点为“response”,每个响应包含固定的两个属性节点:“status”和“message”。它们分别表示操作的返回值和返回消息描述,其他的同级子节点为业务返回对象属性,根据业务类型的不同,有不同的属性名称。
当客户端支持数据压缩传输时,需要在请求的消息头的“Accept-Encoding”字段中指定压缩方式(gzip),如消息可以被压缩传输则平台将应答的数据报文进行压缩作为应答数据返回,Content-Length为压缩后的数据长度。详细参见HTTP/1.1 RFC2616。
响应码规则约定
响应结果码在响应消息的“status”属性中,相应的解释信息在响应消息的“message”属性中。解释消息为终端用户可读的消息,终端应用不需要解析可直接呈现给最终用户。响应结果码为6位数字串。根据响应类型,包括以下几类响应码。如表4-1中的定义。
表4-1响应码对应表
| 响应码 |
描述 |
| 0 |
成功 |
| 1XXXXX |
系统错误 |
| 2XXXXX |
输入参数不合法错误 |
| 3XXXXX |
应用级返回码,定义应用级的异常返回。 |
| 4XXXXX |
正常的应用级返回码,定义特定场景的应用级返回说明。 |
数据管理
A.业务数据检查
接口应提供业务数据检查功能,即对接收的数据进行合法性检查,对非法数据和错误数据则拒绝接收,以防止外来数据非法入侵,减轻应用支撑平台系统主机处理负荷。
对于接口,其业务数据检查的主要内容有以下几个方面:
• 数据格式的合法性:如接收到非预期格式的数据。包括接收的数据长度,类型,开始结束标志等。
• 数据来源的合法性:如接收到非授权接口的数据。
• 业务类型的合法性:如接收到接口指定业务类型外的接入请求。
对于业务数据检查中解析出非法数据应提供以下几种处理方式:
• 事件报警:在出现异常情况时自动报警,以便系统管理员及时进行处理。
• 分析原因:在出现异常情况时,可自动分析其出错原因。如是数据来源非法和业务类型非法,本地记录并做后续管理,如是数据格式非法,分析网络传输原因或对端数据处理原因,并做相应处理。
• 统计分析:定期对所有的非法记录做统计分析,分析非法数据的各种来源是否具有恶意,并做相应处理。
B.数据压缩/解压
接口根据具体的需求应提供数据压缩/解压功能,以减轻网络传输压力,提高传输效率,从而使整个系统能够快速响应并发请求,高效率运行。
在使用数据压缩/解压功能时,应具体分析每一类业务的传输过程、处理过程、传输的网络介质、处理的主机系统和该类业务的并发量、峰值及对于所有业务的比例关系等,从而确定该类业务是否需要压缩/解压处理。对于传输文件的业务,必须压缩后传输,以减轻网络压力,提高传输速度。
在接口中所使用的压缩工具必须基于通用无损压缩技术,压缩算法的模型和编码必须符合标准且高效,压缩算法的工具函数必须是面向流的函数,并且提供校验检查功能。
完整性管理
根据业务处理和接口服务的特点,应用系统的业务主要为实时请求业务和批量传输业务。两类业务的特点分别如下:
1.实时请求业务:
(1) 采用基于事务处理机制实现
(2) 业务传输以数据包的方式进行
(3) 对传输和处理的实时性要求很高
(4) 对数据的一致性和完整性有很高的要求
(5) 应保证高效地处理大量并发的请求
2.批量传输业务:
(1) 业务传输主要是数据文件的形式
(2) 业务接收点可并发处理大量传输,可适应高峰期的传输和处理
(3) 要求传输的可靠性高
根据上述特点,完整性管理对于实时交易业务,要保证交易的完整性;对于批量传输业务,要保证数据传输的完整性。
3)接口双方责任
消息发送方
遵循本接口规范中规定的验证规则,对接口数据提供相关的验证功能,保证数据的完整性、准确性;
消息发起的平台支持超时重发机制,重发次数和重发间隔可配置。
提供接口元数据信息,包括接口数据结构、实体间依赖关系、计算关系、关联关系及接口数据传输过程中的各类管理规则等信息;
提供对敏感数据的加密功能;
及时解决接口数据提供过程中数据提供方一侧出现的问题;
消息响应方
遵循本接口规范中规定的验证规则,对接收的数据进行验证,保证数据的完整性、准确性。
及时按照消息发送方提供的变更说明进行本系统的相关改造。
及时响应并解决接口数据接收过程中出现的问题。
异常处理
对接口流程调用过程中发生的异常情况,如流程异常、数据异常、会话传输异常、重发异常等,进行相应的异常处理,包括:
对产生异常的记录生成异常记录文件。
针对可以回收处理的异常记录,进行自动或者人工的回收处理。
记录有关异常事件的日志,包含异常类别、发生时间、异常描述等信息。
当接口调用异常时,根据预先配置的规则进行相关异常处理,并进行自动告警。
4)接口的可扩展性规划与设计
各个系统间的通信接口版本信息限定了各个系统平台间交互的数据协议类型、特定版本发布的系统接口功能特征、特定功能的访问参数等接口规格。通过接口协议的版本划分,为客户端升级、其他被集成系统的升级、以及系统的部署提供了较高的自由度和灵活性。
系统可根据接口请求中包含的接口协议版本实现对接口的向下兼容。系统平台可根据系统的集群策略,按协议版本分别部署,也可多版本并存部署。由于系统平台可同时支持多版本的外部系统及客户端应用访问系统,特别是新版本客户端发布时,不要求用户强制升级,也可降低强制升级安装包发布的几率。从而支持系统的客户端与系统平台分离的持续演进。
5)接口安全性设计
为了保证系统平台的安全运行,各种集成的外部系统都应该保证其接入的安全性。
接口的安全是平台系统安全的一个重要组成部分。保证接口的自身安全,通过接口实现技术上的安全控制,做到对安全事件的“可知、可控、可预测”,是实现系统安全的一个重要基础。
根据接口连接特点与业务特色,制定专门的安全技术实施策略,保证接口的数据传输和数据处理的安全性。
系统应在接口的接入点的网络边界实施接口安全控制。
接口的安全控制在逻辑上包括:安全评估、访问控制、入侵检测、口令认证、安全审计、防(毒)恶意代码、加密等内容。
安全评估
安全管理人员利用网络扫描器定期(每周)/不定期(当发现新的安全漏洞时)地进行接口的漏洞扫描与风险评估。扫描对象包括接口通信服务器本身以及与之关联的交换机、防火墙等,要求通过扫描器的扫描和评估,发现能被入侵者利用的网络漏洞,并给出检测到漏洞的全面信息,包括位置、详细描述和建议改进方案,以便及时完善安全策略,降低安全风险。
安全管理人员利用系统扫描器对接口通信服务器操作系统定期(每周)/不定期(当发现新的安全漏洞时)地进行安全漏洞扫描和风险评估。在接口通信服务器操作系统上,通过依附于服务器上的扫描器代理侦测服务器内部的漏洞,包括缺少安全补丁、词典中可猜中的口令、不适当的用户权限、不正确的系统登录权限、操作系统内部是否有黑客程序驻留,安全服务配置等。系统扫描器的应用除了实现操作系统级的安全扫描和风险评估之外还需要实现文件基线控制。
接口的配置文件包括接口服务间相互协调作业的配置文件、系统平台与接口对端系统之间协调作业的配置文件,对接口服务应用的配置文件进行严格控制,并且配置文件中不应出现口令明文,对系统权限配置限制到能满足要求的最小权限,关键配置文件加密保存。为了防止对配置文件的非法修改或删除,要求对配置文件进行文件级的基线控制。
访问控制
访问控制主要通过防火墙控制接口对端系统与应用支撑平台之间的相互访问,避免系统间非正常访问,保证接口交互信息的可用性、完整性和保密性。访问控制除了保证接口本身的安全之外,还进一步保证应用支撑平台的安全。
为了有效抵御威胁,应采用异构的双防火墙结构,提高对防火墙安全访问控制机制的破坏难度。双防火墙在选型上采用异构方式,即采用不同生产厂家不同品牌的完全异构防火墙。同时,双防火墙中的至少一个应具有与实时入侵检测系统可进行互动的能力。当发生攻击事件或不正当访问时,实时入侵检测系统检测到相关信息,及时通知防火墙,防火墙能够自动进行动态配置,在定义的时间段内自动阻断源地址的正常访问。
系统对接口被集成系统只开放应用定义的特定端口。
采用防火墙的地址翻译功能,隐藏系统内部网络,向代理系统提供翻译后的接口通信服务器地址及端口,禁止接口对端系统对其它地址及端口的访问。
对通过/未通过防火墙的所有访问记录日志。
入侵检测
接口安全机制应具有入侵检测(IDS)功能,实时监控可疑连接和非法访问等安全事件。一旦发现对网络或主机的入侵行为,应报警并采取相应安全措施,包括自动阻断通信连接或者执行用户自定义的安全策略。
实施基于网络和主机的入侵检测。检测攻击行为和非法访问行为,自动中断其连接,并通知防火墙在指定时间段内阻断源地址的访问,记录日志并按不同级别报警,对重要系统文件实施自动恢复策略。
口令认证
对于需经接口安全控制系统对相关集成系统进行业务操作的请求,实行一次性口令认证。
为保证接口的自身安全,对接口通信服务器和其它设备的操作和管理要求采用强口令的认证机制,即采用动态的口令认证机制。
安全审计
为了保证接口的安全,要求对接口通信服务器的系统日志、接口应用服务器的应用日志进行实时收集、整理和统计分析,采用不同的介质存档。
防恶意代码或病毒
由于Internet为客户提WEB服务,因此,对于Internet接口要在网络分界点建立一个功能强大的防恶意代码系统,该系统能实时地进行基于网络的恶意代码过滤。建立集中的防恶意代码系统控制管理中心。
加密
为了提高接口通信信息的保密性,同时保证应用支撑平台的安全性,可以对系统平台与接口集成系统间的相关通信实施链路加密、网络加密或应用加密,保证无关人员以及无关应用不能通过网络链路监听获得关键业务信息,充分保证业务信息的安全。
3、具体实现
1)原生JDK构造HTTP请求客户端,调用API
手动去创建HTTP连接,并将数据写入流中,再将数据转换为JSON对象进行解析
2)在SpringBoot下使用RestTemplate,以及抽取配置的方式调用API
将一些配置抽取出来,不同的环境运行不同的配置文件是常见的做法。例如我们可以将上面的appKey放到application.yml配置文件中。
3)使用OpenFeign以及抽取配置的方式调用API
将API调用变得更加像调用普通接口一样方便。原版的OpenFeign不依赖Spring独立使用( https://github.com/OpenFeign/feign),SpringCloud整合了OpenFeign,在SpringCloud2.x,Feign成为SpringCloud的一级项目( https://cloud.spring.io/spring-cloud-openfeign/)。
OpenFeign为微服务架构下服务之间的调用提供了解决方案,同时它可以结合其它组件可以实现负载均衡的HTTP客户端。
用户数据关联
不同数据源采集的用户数据的关联可采用基于ID-Mapping技术实现id的数据关联。
当下数据关联实现主要选择第三方提供的服务和自行开发两种方式:
1、三方服务
三方服务选择上有很多,可以利用阿里、华为、神策等厂商提供的各种相关解决方案或服务,有原生开发支持,也有直接的SAAS支持方式。以阿里的ID-Mapping体系的方案OneData体系为例

2、自行开发
1)基于ID-Mapping用户数据关联实现可总结为以下三种:
①基于账号体系企业中最常用的是基于账号体系来做ID的打通,用户注册时,给到用户一个uid,以uid来强关联所有注册用户的信息。
②基于设备:那对于未注册用户可以通过终端设备ID精准识别,包含Android/iOS两类主流终端的识别;通过SDK将各种ID采集上报,后台利用的ID关系库和校准算法,实时生成/找回终端唯一ID并下发。
③基于账号&设备:结合各种账户、各种设备型号之间的关系对,以及设备使用规律等用户数据;采用规则规律、数据挖掘算法的方法,输出关系稳定的ID关系对,并生成一个UID作为唯一识别该对象的标识码。
2)技术实现ID-Mapping
①借助redis

a.从日志数据中抽取各种标识id
b.将提取出的标识id,去redis标识id库中查询是否存在
c.如果不存在,则新建一个"统一标识"+“id set”
d.如果已存在,则使用已存在的统一标识
②借助图计算
采用图计算手段,来找到各种id标识之间的关联关系,从而识别出哪些id标识属于同一个人;
图计算的核心思想:
将数据表达成“点”,点和点之间可以通过某种业务含义建立“边”;然后,可以从点、边上找出各种类型的数据关系:比如连通性、最短路径规划等;
整体实现流程:
A.将当日数据中的所有用户标识字段,及标志字段之间的关联,生成点集合 、边集合
B.将上一日的ids->guid的映射关系,也生成点集合、边集合
C.将上面两类点集合、边集合合并到一起生成一个图
D.再对上述的图执行“最大连通子图”算法,得到一个连通子图结果
E.在从结果图中取到哪些id属于同一组,并生成一个唯一标识
F.将上面步骤生成的唯一标识去比对前日的ids->guid映射表(如果一个人已经存在guid,则沿用原来的guid)
人工数据采集
主要通过实现数据导入工具,来实现对人工处理数据的采集;比如定制好数据模板,当人工填写数据模板后,在数据工具中导入上传,再进入大数据平台的文件自动处理机制流程中。
数据输出
数据导出方法包含API导出、文件导出、消费消息数据、数据库导出、工具导出集中方式。
1)API导出
定制开发数据输出API接口,实现对外数据查询或导出数据文件,接口做成详细参照《2.2.1.3第三方系统API对接-接口规范性设计》,输出API的调用大概分为以下几个步骤:
鉴权->获取链接->下载/数据
通过做成的对外API接口,为外部提供数据输出。
2)文件导出
可通可视化形式,提供页面级别操作,导出所需数据文件,前提也是需要获取到相应权限。
3)消费消息数据
以kafka为例,通过消费实时数据来满足更多使用场景。服务端接到一条 SDK 发来的数据后,会对数据做一些预处理并将数据写入到消息队列 Kafka 中供下游各类计算模块及对外使用。
注意点:
A.启动消费的服务器需与数据服务器实行鉴权,让消费服务器与数据服务器处于同一网段或者网络互通,且可解析数据服务器的host。
B.尽量选用兼容性的kafka版本,高版本服务端兼容低版本客户端,反之则容易出现兼容性问题
①消费参数
| 参数名称 |
参数值 |
| topic |
event{appid}/profile{appid}(其中{appid}表示项目的appid) |
| partition |
partitionid(从0开始,至少3个partition) |
| zookeeper |
ark1:2181,ark2:2181,ark3:2181 |
| broker |
ark1:9092,ark2:9092, ark3:9092 |
②消费数据
消费有shell、原生API等多种方式,可以选择一种适合使用场景的方式。
下面给出两种 Shell 方式启动消费的示例,使用 Shell 方式可以通过重定向标准输出将数据写入文件后处理或直接用管道作为其他进程的输入,可以对接各种编程语言实现的处理程序。
使用 Kafka Console Consumer
·可以使用 Kafka 自带的 Kafka Console Consumer 通过命令行方式消费,例如从最新数据开始消费:bin/kafka-console-consumer.sh --zookeeper ark1:2181 --topic event_topic
·可以将 stdout 输出到文件或作为其他数据处理进程的输入数据。
使用 Simple Consumer Shell
·使用 Simple Consumer Shell 可以实现更灵活的消费,例如:
bin/kafka-run-class.sh kafka.tools.SimpleConsumerShell \
--broker-list ark2:9092 \
--offset 1234 \
--partition 2 \
--topic event_topic \
--print-offsets
③数据格式
消费的数据的格式与导入时的数据格式基本一致。
4)数据库导出
即 JDBC、presto-cli、python 或 R 进行数据查询,达到更加高效、稳定的 SQL 查询方式,本次采用JDBC方式。
JDBC 信息
| 字段 |
信息 |
| jdbc url |
jdbc:presto://xxxx.xxxx.xxx:port/hive/default |
| driver |
com.facebook.presto.jdbc.PrestoDriver |
| user |
daxiang |
| SSL |
true |
| password |
编辑 /etc/presto/presto-auth.properties 文件查看 |
| SSLKeyStorePath |
presto.jks文件的路径,一般是/etc/presto/presto.jks |
| SSLKeyStorePassword |
值可以在单机环境的ark1,集群环境的/etc/presto/config.properties文件中找到,对应http-server.https.keystore.key的值 |
5) 工具导出
可通过自行开发导出工具或第三方导出工具为外部,可通过下载授权数据导出工具获取输出的数据。