贝叶斯神经网络毫无意义吗?Twitter、Reddit双战场辩论,火药味十足!
| 2020-01-19 15:49 |
导语:道理,不辨析不明朗;学问,不争论不清晰
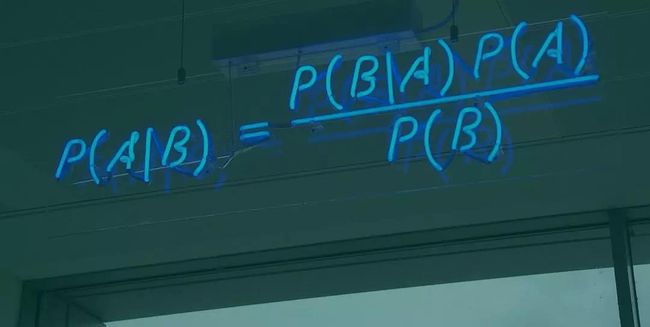
作者 | 雷锋网 AI 科技评论
编辑 | 雷锋网 Camel
最近Twitter、Reddit上有一股争论的热潮涌动,先是有 François Chollet 、Yann LeCun 等人隔空辨析「到底什么是深度学习」,后是有一大批研究者争论「贝叶斯神经网络到底有没有意义」。新的一年,火药味十足,这是否也意味着深度学习的研究正进入一个混乱的时期?道理,不辨析不明朗;学问,不争论不清晰。
所谓贝叶斯神经网络,简单来说便是将一般神经网络中的权重和偏置由确定的数值变为一个分布。

按照一般理解,这种将参数以概率分布的形式表示,可以为网络推理提供不确定性估计;此外,通过使用先验概率分布的形式来表示参数,训练期间在许多模型上计算平均值,可以给网络提供正则化效果,从而防止过度拟合。然后,在大约一个月前,OpenAI 研究员Carles Gelada发布了一个系列Twitter:
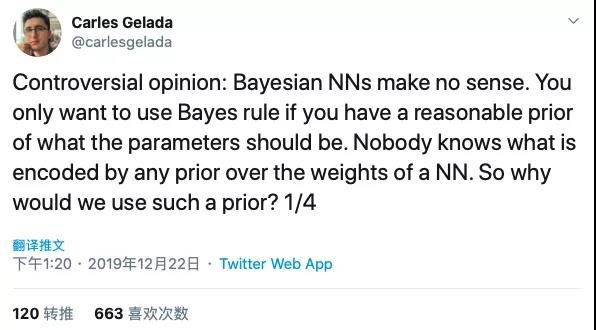
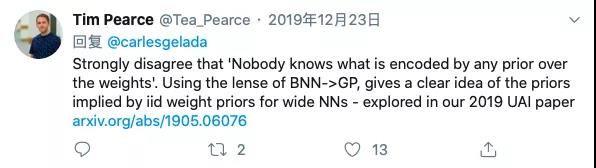
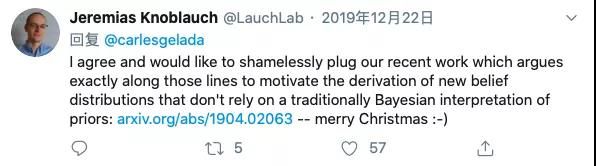
他指出,或许贝叶斯神经网络并没有多大用处。大致观点为:1)只有当具有合理的参数先验时,我们才会去使用贝叶斯规则,但没有人知道先验对神经网络权重的编码会是什么,那么为什么我们还要使用这种先验呢?2)许多正则化都可以用贝叶斯解释,但事实上每个人都能够对正则化给出一个解释。那么我们用贝叶斯理论来解释正则化,有什么意义呢?3)或许有人会说BNNs可以让我们直接用经验来找到正则化。但谁来保证BNNs找到的这种正则化空间就是最优的呢?4)BNNs可以用在贝叶斯元学习框架当中。但没有理由相信这种应用会比其他元学习框架更好。针对Carles提出的这些反对意见,在Twitter上迅速吸引了大批的研究人员加入讨论。多数引经据典,从历史发展、当前研究、实践经验等各种角度进行辩论,或赞同,或反对,不一而足。
一、贝叶斯神经网络有用吗?
为了更加明晰“贝叶斯网络没啥用”的立场,近期Carles Gelada 和 Jacob Buckman重新梳理了他们的思路,专门写了一篇博客,从贝叶斯网络的原理入手,详细阐述了“BNNs需要先验信息丰富的先验知识才能处理不确定性”的观点,并指出泛化的代价不容忽视。
1、贝叶斯神经网络具有不确定性的原因:泛化不可知先验
为了说明先验在贝叶斯网络中的重要意义,Buckman在博客中引入了泛化不可知先验(generalization-agnostic priors),用这种“不可知的先验”进行贝叶斯推理并不能减少模型的不确定性。Carles和Buckman认为,要想在深度学习中使用贝叶斯框架,只有让先验与神经网络的泛化特性相联系,才能达到好的效果,方法是给泛化能力良好的函数以更高的概率。但是目前学术界还没有足够的能力(作者猜测)来证明哪种先验的情况能够满足条件。另外,Buckman在博客中作者举了一个具体的例子:当一个数据集C
里面包含两种数据对:一种是给定输入,输出正确;另一种是给定输入,输出错误。训练神经网络所得到的参数 ![]() 必须让神经网络既能够表达正确输出,也能够表达错误的输出。即使模型在数据集上训练后,能够得到条件概率p(f|c)=1,但在测试集上模型也可能表现很差。另外,定义一种先验概率Q,可以让 Q(f*)=Q(fθ)这意味着如果泛化良好的函数与泛化不好的函数得到的分配概率是相同的。但这种先验是有问题的:由于f*和fθ的数据的可能性为1,并且由于先验概率相似,这意味着后验概率也是相似的(如下公式)。
必须让神经网络既能够表达正确输出,也能够表达错误的输出。即使模型在数据集上训练后,能够得到条件概率p(f|c)=1,但在测试集上模型也可能表现很差。另外,定义一种先验概率Q,可以让 Q(f*)=Q(fθ)这意味着如果泛化良好的函数与泛化不好的函数得到的分配概率是相同的。但这种先验是有问题的:由于f*和fθ的数据的可能性为1,并且由于先验概率相似,这意味着后验概率也是相似的(如下公式)。

注:实际上对于某些数据,fθ可以产生错误的输出,即Q(f*)不等于Q(fθ)
综上,Carles和Buckman认为在泛化不可知的先验条件下,无论数据集如何,都无法降低模型的不确定性。即贝叶斯神经网络起作用的关键因素是:先验能够区分泛化良好的函数和泛化不好的函数。
2、当前贝叶斯网络的泛化能力不可知
在构建贝叶斯神经网络时,大家的共识是用比较简单的概率先验,即假设参数服从独立的高斯分布。但是高斯先验显然会导致结构先验,而这些先验并无泛化能力,原因有两点:1.高斯先验平滑分配概率。2.在训练神经网络的时候,无论数据集如何,最合理的策略似乎是给不同的泛化函数以相同的权重。还有一点是计算问题也不容忽视,实际上如何对贝叶斯推理q(F|D)进行计算可能是贝叶斯神经网络(具有先验泛化不可知)能够有合理效果的关键因素。
3、理性批判BNNs
Carles和Buckman也在博客中表示上面的理由有猜测的成分,因为无法得知何种因素决定神经网络泛化能力,所以定义执行贝叶斯推理的先验具有不确定性。贝叶斯神经网络只是一个神经网络,先验只是里面的一个超参数。Carles和Buckman认为当前在网络中加入贝叶斯不会带来任何好处,只有当能够找到一个好的先验,并且能够验证推理的准确性才能有所帮助。另外,他们还提到:作为一个领域,先验在贝叶斯框架里扮演着重要的角色,这一点毋容置疑,所以对于贝叶斯网络需要理性的批判,不能让“不具信息性的先验在不确定性下表现良好”(uninformative priors are good under uncertainty)这种无脑观点所左右。
二、反驳与批评:Twitter、Reddit双战场
这篇博客同步发在了推特和 Reddit 上,自然也就在两个平台上都引来了反驳的声音。
1、Twitter 战场:存在技术错误
在Twitter上,纽约大学数学和数据科学教授Andrew Gordon Wilson就表示他们的观点存在错误:这篇博客中存在错误。
1,如果数据是来自我们想要拟合的分布的,那么随着我们使用的数据的规模增大,似然性会收缩到那个“好的函数”上,因为不好的函数会越来越少出现,这也和我们的观测值一致。
2,能拟合噪声的模型并没有什么出奇之处,而且也和“存在归纳偏倚,更倾向于选择有噪声的解”是两码事。在函数上简单增加一个标准的GP-RBF先验就可以支持噪声了,但它仍然更善于建模有结构的解。
3,对于通常会使用神经网络来解决的问题,好的解的数量通常都会比不好的解的数量更多。神经网络的结构中就含有帮助带来更好的泛化性的归纳偏倚。神经网络函数“与泛化性无关”的说法有点不负责任。
4,实际上,想要在函数空间创造许多不同的“泛化性无关”的先验是很简单的事,而它们的行为会和神经网络非常不同。它们可以由平凡的结构组成,而且也肯定不会具有任何泛化能力。
5,缺少理想的后验收缩会在这么几种情况下发生:
-
假想空间中并不包含好的解;
-
先验对某个坏的解太过自信(比如给任意的 x 都分配同一个标签 p)。
但神经网络有很强的表达能力,这里的b情况根本就和“有模糊的权重先验”完全相反!除了技术讨论之外,我建议两位可以多提问、多学习,以及对贝叶斯深度学习抱有开放的心态。
也许是你们的“贝叶斯神经网络不合理”的先验太强了才觉得理解不了(微笑)。
Carles Gelada 对这份质疑的回应是:
如果情况是像你说的这样,那么证明这件事是贝叶斯支持的责任(而不是我们质疑者的),尤其是当他们声称模型可以提供好的不确定性的时候。实际上我们提出质疑的理由就是,每个初始值附近都同时有好的和坏的泛化函数,那么他们声称的东西也就值得怀疑了。
另外,关于“拟合损坏的样本”的讨论不应该和“拟合噪声”混为一谈。我们在讨论中假设了分类任务中不存在噪声,但即便是有噪声的分类任务,我们的观点也是成立的。用简单的测试就可以说明目前使用的先验不是泛化无关的:训练一个好的函数、训练一个坏的函数,然后看看先验是否会给好的函数更高的概率。我怀疑状况不是这样的,但这里需要贝叶斯的支持者向我证明他们的先验是好的。
2、Reddit 回帖:水平不足+双重标准
Reddit上网友们的回应更激烈、更情绪性一些,甚至得到最多赞同意见的帖子就含有辛辣的批评和嘲讽。
adversary_argument:
由于博客作者们对贝叶斯推理中的真正的先验缺乏了解,所以我觉得这个讨论很没意思,甚至有一股双重标准的味道。
全体深度学习研究人员(以及作者们自己)都已经接受了神经网络的大规模使用,即便我们还没有找到明确的泛化边界,也对神经网络的理论理解甚少。但是既然神经网络运行起来令人满意,这些问题就一股脑地被视而不见 —— 神经网络就是好的、正义的。然而,现在作者们要求贝叶斯神经网络必须在先验方面提供很强的理论保证,虽然他们同时也承认贝叶斯神经网络是有效的…… emmm,你们觉得这像不像贼喊捉贼?
做深度学习的人挺能散布负面言论的啊……尤其是,我觉得他们的讨论方式,针对某个任意的、损坏的测试集 C 的讨论,只不过是在攻击他们自己造出来的一个靶子而已。
我解释给你们看看:他们没有给出被损坏的数据的数量,但是他们就声称 f_theta 肯定在 D_test 上会有糟糕的表现?他们的依据是什么?那比如 D 是一百万个好的数据点组成的数据集,C 是 D 加上一个损坏的数据点,所以按照他们的理论,D_test 上的测试误差肯定会特别糟糕?
他们洋洋洒洒了一大堆,最后只证明了损坏训练数据会降低贝叶斯神经网络的测试准确率而已…… 呃…… 所以这有什么好奇怪的吗……
博客作者回应:
可能我们在博客里写得不够清楚。我们考虑含有损坏数据的数据集,不是为了说明只要有损坏数据就会有糟糕的预测表现(尤其对于一百万比一这种情况),而是想说明有损坏数据的、神经网络拟合之后会有糟糕的泛化表现的数据集是存在的。我们是为了说明存在性。如果先验对这样的网络分配很高的概率,那么贝叶斯推理就没有什么好处。我们的博客也不是为了表达贝叶斯神经网络没用,而是想表示“如果没有好的先验,贝叶斯神经网络就无法带来好的不确定性估计”,“关于非信息性的先验的标准讨论方式是有问题的”,以及“想要有好的不确定性估计,我们需要先理解神经网络的泛化性”。除此之外,其它多篇Reddit 的网友回帖也认为原博客两人的讨论态度有问题,立场很难称得上是“冷静看待”,有些简单的实验也完全可以自己先尝试。