机器学习四大基本模型:回归、分类、聚类、降维
在本文中,我对现代机器学习算法进行了简要梳理,我通过查阅转载众多博客和资料,基于实践中的经验,讨论每个算法的优缺点,并以机器学习入门者的角色来看待各个模型。
主要内容来自《机器之心》:回归、分类与聚类:三大方向剖解机器学习算法的优缺点
通俗理解:
1.给定一个样本特征 , 我们希望预测其对应的属性值 , 如果是离散的, 那么这就是一个分类问题,反之,如果是连续的实数, 这就是一个回归问题。
2.如果给定一组样本特征 , 我们没有对应的属性值 , 而是想发掘这组样本在二维空间的分布, 比如分析哪些样本靠的更近,哪些样本之间离得很远, 这就是属于聚类问题。
3.如果我们想用维数更低的子空间来表示原来高维的特征空间, 那么这就是降维问题。
1、回归(regression)
回归方法是一种对数值型连续随机变量进行预测和建模的监督学习算法。使用案例一般包括房价预测、股票走势或测试成绩等连续变化的案例。回归任务的特点是标注的数据集具有数值型的目标变量。也就是说,每一个观察样本都有一个数值型的标注真值以监督算法。
目的:为了找到最优拟合,通过回归算法得到是一个最优拟合线,这个线条可以最好的接近数据集中的各个点。
输出:定量的值、连续的
应用:归问题通常是用来预测一个值。另外,回归分析用在神经网络上,其最上层是不需要加上softmax函数的,而是直接对前一层累加即可。一个比较常见的回归算法是线性回归算法(LR)如预测房价、股票的成交额、未来的天气情况等等。
1.1 线性回归(正则化)
线性回归是处理回归任务最常用的算法之一。该算法的形式十分简单,它期望使用一个超平面拟合数据集(只有两个变量的时候就是一条直线)。如果数据集中的变量存在线性关系,那么其就能拟合地非常好。

在实践中,简单的线性回归通常被使用正则化的回归方法(LASSO、Ridge 和 Elastic-Net)所代替。正则化其实就是一种对过多回归系数采取惩罚以减少过拟合风险的技术。当然,我们还得确定惩罚强度以让模型在欠拟合和过拟合之间达到平衡。
优点:线性回归的理解与解释都十分直观,并且还能通过正则化来降低过拟合的风险。另外,线性模型很容易使用随机梯度下降和新数据更新模型权重。
缺点:线性回归在变量是非线性关系的时候表现很差。并且其也不够灵活以捕捉更复杂的模式,添加正确的交互项或使用多项式很困难并需要大量时间。
线性回归实例代码:
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets, linear_model#sklearn机器学习
from sklearn.metrics import mean_squared_error, r2_score
# 利用 diabetes数据集来学习线性回归
# diabetes 是一个关于糖尿病的数据集, 该数据集包括442个病人的生理数据及一年以后的病情发展情况。
# 数据集中的特征值总共10项, 如下:
# 年龄
# 性别
#体质指数
#血压
#s1,s2,s3,s4,s4,s6 (六种血清的化验数据)
# Load the diabetes(糖尿病) dataset
diabetes_X, diabetes_y = datasets.load_diabetes(return_X_y=True)
#shape=(422,10)取一个特征(422,1)
# Use only one feature(特征)
diabetes_X = diabetes_X[:, np.newaxis, 2]
# Split(拆分) the data into training/testing sets
diabetes_X_train = diabetes_X[:-20]#422,1
diabetes_X_test = diabetes_X[-20:]#20,1
#Split the targets(目标) into training/testing sets
diabetes_y_train = diabetes_y[:-20]#422
diabetes_y_test = diabetes_y[-20:]#20
print(diabetes_y_train.shape,diabetes_y_test.shape)
# Create linear regression(线性回归) object
regr = linear_model.LinearRegression()
# Train the model using the training sets
regr.fit(diabetes_X_train, diabetes_y_train)#训练
# Make predictions using the testing set
diabetes_y_pred = regr.predict(diabetes_X_test)#试预测
# The coefficients(系数)
#调用预测模型的coef_属性,求出生理数据的回归系数b
print("Coefficients: \n", regr.coef_)
# The mean squared error
print("Mean squared error: %.2f" % mean_squared_error(diabetes_y_test, diabetes_y_pred))#均方误差
# The coefficient of determination: 1 is perfect prediction(决定系数:1为完美预测)
print("Coefficient of determination: %.2f" % r2_score(diabetes_y_test, diabetes_y_pred))#决定系数
# Plot outputs
plt.scatter(diabetes_X_test, diabetes_y_test, color="black")
plt.plot(diabetes_X_test, diabetes_y_pred, color="blue", linewidth=3)
plt.xticks(())
plt.yticks(())
plt.show()
1.2 回归树(集成方法)
回归树(决策树的一种)通过将数据集重复分割为不同的分支而实现分层学习,分割的标准是最大化每一次分离的信息增益。这种分支结构让回归树很自然地学习到非线性关系。

集成方法,如随机森林(RF)或梯度提升树(GBM)则组合了许多独立训练的树。这种算法的主要思想就是组合多个弱学习算法而成为一种强学习算法,不过这里并不会具体地展开。在实践中 RF 通常很容易有出色的表现,而 GBM 则更难调参,不过通常梯度提升树具有更高的性能上限。
优点:决策树能学习非线性关系,对异常值也具有很强的鲁棒性(健壮性)。集成学习在实践中表现非常好,其经常赢得许多经典的(非深度学习)机器学习竞赛。
缺点:无约束的,单棵树很容易过拟合,因为单棵树可以保留分支(不剪枝),并直到其记住了训练数据。集成方法可以削弱这一缺点的影响。
随机树实例代码:
#之后我再学习,这里大家参考:python实现随机树
1.3 深度学习
深度学习是指能学习极其复杂模式的多层神经网络。该算法使用在输入层和输出层之间的隐藏层对数据的中间表征建模,这也是其他算法很难学到的部分。
深度学习还有其他几个重要的机制,如卷积和 drop-out 等,这些机制令该算法能有效地学习到高维数据。然而深度学习相对于其他算法需要更多的数据,因为其有更大数量级的参数需要估计。
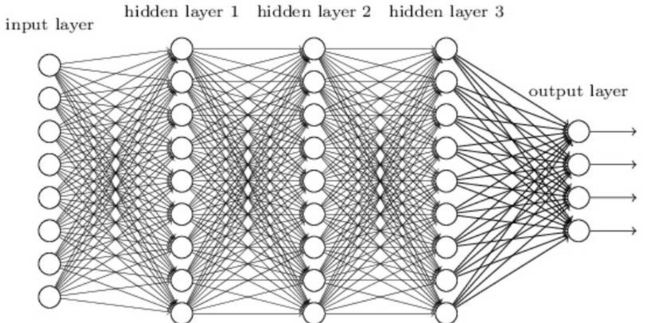
优点:深度学习是目前某些领域最先进的技术,如计算机视觉和语音识别等。深度神经网络在图像、音频和文本等数据上表现优异,并且该算法也很容易对新数据使用反向传播算法更新模型参数。它们的架构(即层级的数量和结构)能够适应于多种问题,并且隐藏层也减少了算法对特征工程的依赖。
缺点:深度学习算法通常不适合作为通用目的的算法,因为其需要大量的数据。实际上,深度学习通常在经典机器学习问题上并没有集成方法表现得好。另外,其在训练上是计算密集型的,所以这就需要更富经验的人进行调参(即设置架构和超参数)以减少训练时间。
深度神经网络实例代码:可以参考我之前的文章
1.4 最近邻算法
最近邻算法是「基于实例的」,这就意味着其需要保留每一个训练样本观察值。最近邻算法通过搜寻最相似的训练样本来预测新观察样本的值。而这种算法是内存密集型,对高维数据的处理效果并不是很好,并且还需要高效的距离函数来度量和计算相似度。在实践中,基本上使用正则化的回归或树型集成方法是最好的选择。
2、分类(classification )
分类方法是一种对离散型随机变量建模或预测的监督学习算法。使用案例包括邮件过滤、金融欺诈和预测雇员异动等输出为类别的任务。许多回归算法都有与其相对应的分类算法,分类算法通常适用于预测一个类别(或类别的概率)而不是连续的数值。
目的:分类的目的是为了寻找决策边界,即分类算法得到是一个决策面,用于对数据集中的数据进行分类。
输出:定性的值、离散的
应用:分类问题应用非常广泛。通常是建立在回归之上,分类的最后一层通常要使用softmax函数进行判断其所属类别。分类并没有逼近的概念,最终正确结果只有一个,错误的就是错误的,不会有相近的概念。例如判断一幅图片上的动物是一只猫还是一只狗,判断明天天气的阴晴,判断零件的合格与不合格等等。
2.1 Logistic 回归(正则化)
(逻辑回归)Logistic 回归是与线性回归相对应的一种分类方法,且该算法的基本概念由线性回归推导而出。Logistic 回归通过 Logistic 函数(即 Sigmoid 函数)将预测映射到 0 到 1 中间,因此预测值就可以看成某个类别的概率(线性回归输出加一个sigmoid函数就是逻辑回归)。
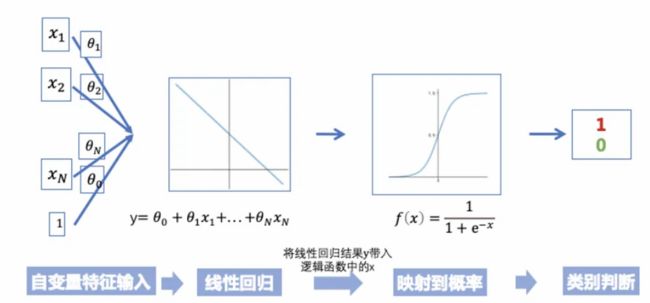 该模型仍然还是「线性」的,所以只有在数据是线性可分(即数据可被一个超平面完全分离)时,算法才能有优秀的表现。同样 Logistic 模型能惩罚模型系数而进行正则化。
该模型仍然还是「线性」的,所以只有在数据是线性可分(即数据可被一个超平面完全分离)时,算法才能有优秀的表现。同样 Logistic 模型能惩罚模型系数而进行正则化。
优点:输出有很好的概率解释,并且算法也能正则化而避免过拟合。Logistic 模型很容易使用随机梯度下降和新数据更新模型权重。
缺点:Logistic 回归在多条或非线性决策边界时性能比较差。
Logistic回归实例代码:
from sklearn.datasets import load_breast_cancer
from sklearn.linear_model import LogisticRegression
import numpy as np
# ----数据加载------
#sk-learn中的breast_cancer数据,只选4个特征
#模型预测乳腺癌是良性还是恶性
data = load_breast_cancer()
X = data.data[:, 4:8]#(569,4)569个人的特征,每个人都有4个特征
y = data.target#569个人的标签(0 or 1)
# ----数据归一化------
xmin = X.min(axis=0)
xmax = X.max(axis=0)
X_norm = (X - xmin) / (xmax - xmin)
# -----训练模型--------------------
clf = LogisticRegression(random_state=0)#逻辑回归
clf.fit(X_norm, y)#训练
# ------模型预测-------------------------------
pred_y = clf.predict(X_norm) # 预测类别
pred_prob_y = clf.predict_proba(X_norm)[:, 1] # 预测属于1类的概率
print("模型系数(对应归一化数据):", clf.coef_[0])
print("模型阈值(对应归一化数据):", clf.intercept_)
print("模型准确率:", (pred_y == y).sum() / len(y))2.2 分类树(集成方法)
与回归树相对应的分类算法是分类树。它们通常都是指决策树,或更严谨一点地称之为「分类回归树(CART)」,这也就是非常著名的 CART 的算法。#这里与前面的回归树区分开,这里输出的是(0,1)类,并非是连续的值。
优点:同回归方法一样,分类树的集成方法在实践中同样表现十分优良。它们通常对异常数据具有相当的鲁棒性(健壮性)和可扩展性。因为它的层级结构,分类树的集成方法能很自然地对非线性决策边界建模。
缺点:不可约束,单棵树趋向于过拟合,使用集成方法可以削弱这一方面的影响。
分类树实例代码:
#之后我再学习,这里大家参考:sklearn实现决策树(分类树)
2.3 深度学习
深度学习同样很容易适应于分类问题。实际上,深度学习应用地更多的是分类任务,如图像分类等。
优点:深度学习非常适用于分类音频、文本和图像数据。
缺点:和回归问题一样,深度神经网络需要大量的数据进行训练,所以其也不是一个通用目的的算法。
分类深度学习实例代码:#参考我之前的文章
2.4 支持向量机
支持向量机(SVM)可以使用一个称之为核函数的技巧扩展到非线性分类问题,而该算法本质上就是计算两个称之为支持向量的观测数据之间的距离。SVM 算法寻找的决策边界即最大化其与样本间隔的边界,因此支持向量机又称为大间距分类器。
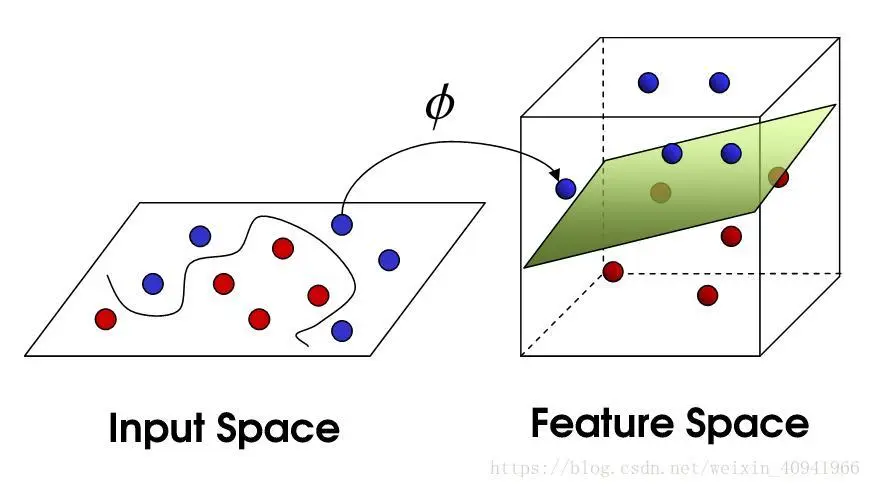
支持向量机中的核函数采用非线性变换,将非线性问题变换为线性问题。例如,SVM 使用线性核函数就能得到类似于 logistic 回归的结果,只不过支持向量机因为最大化了间隔而更具鲁棒性。因此,在实践中,SVM 最大的优点就是可以使用非线性核函数对非线性决策边界建模。
优点:SVM 能对非线性决策边界建模,并且有许多可选的核函数形式。SVM 同样面对过拟合有相当大的鲁棒性,这一点在高维空间中尤其突出。
缺点:然而,SVM 是内存密集型算法,由于选择正确的核函数是很重要的,所以其很难调参,也不能扩展到较大的数据集中。目前在工业界中,随机森林通常优于支持向量机算法。
SVM实例代码:
后面学习,参考:SVM-python
2.5 朴素贝叶斯
朴素贝叶斯(NB)是一种基于贝叶斯定理和特征条件独立假设的分类方法。本质上朴素贝叶斯模型就是一个概率表,其通过训练数据更新这张表中的概率。为了预测一个新的观察值,朴素贝叶斯算法就是根据样本的特征值在概率表中寻找最大概率的那个类别。之所以称之为「朴素」,是因为该算法的核心就是特征条件独立性假设(每一个特征之间相互独立),而这一假设在现实世界中基本是不现实的。
优点:即使条件独立性假设很难成立,但朴素贝叶斯算法在实践中表现出乎意料地好。该算法很容易实现并能随数据集的更新而扩展。
缺点:因为朴素贝叶斯算法太简单了,所以其也经常被以上列出的分类算法所替代。
3、聚类(clustering)
聚类是一种无监督学习任务,该算法基于数据的内部结构寻找观察样本的自然族群(即集群)。因为聚类是一种无监督学习(即数据没有标注),并且通常使用数据可视化评价结果。如果存在「正确的回答」(即在训练集中存在预标注的集群),那么分类算法可能更加合适。
目的:聚类就是将相似的事物放在一起
输出:C个聚类中心点向量和C*N的一个模糊划分矩阵
应用:使用案例包括细分客户、新闻聚类、文章推荐等
3.1 K 均值聚类
K 均值聚类(K-Means)是一种通用目的的算法,聚类的度量基于样本点之间的几何距离(即在坐标平面中的距离)。集群是围绕在聚类中心的族群,而集群呈现出类球状并具有相似的大小。聚类算法是我们推荐给初学者的算法,因为该算法不仅十分简单,而且还足够灵活以面对大多数问题都能给出合理的结果。
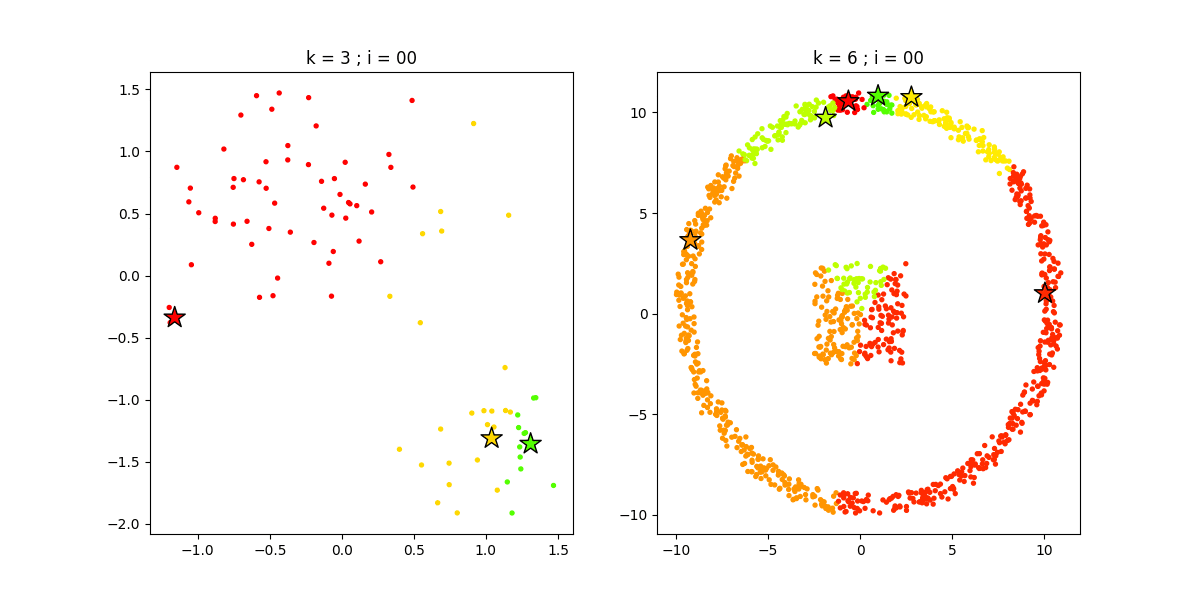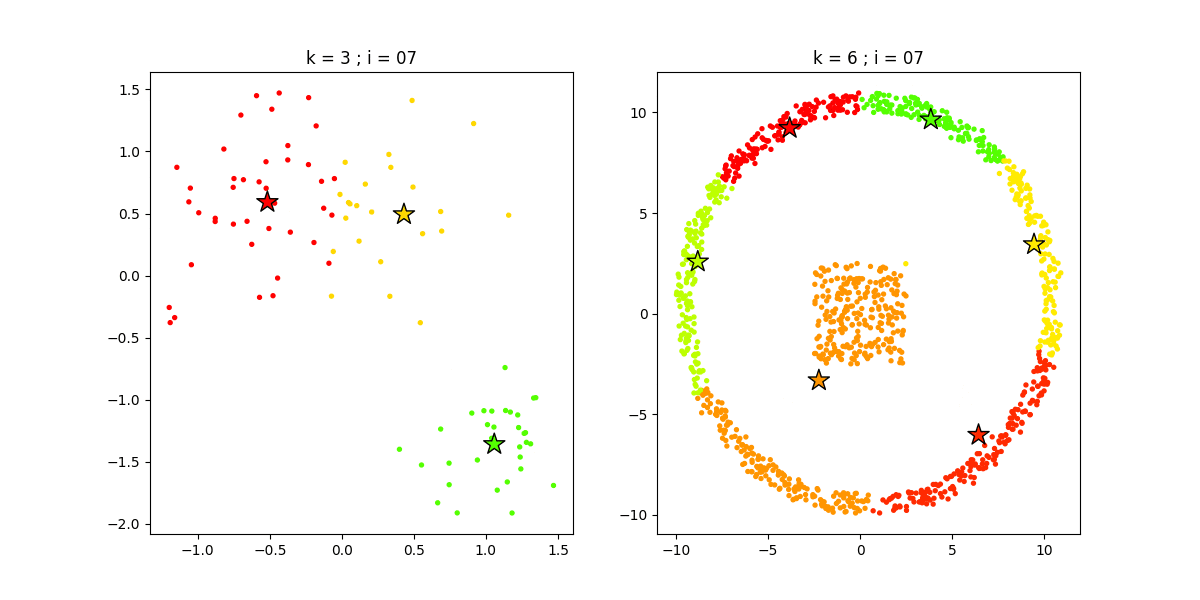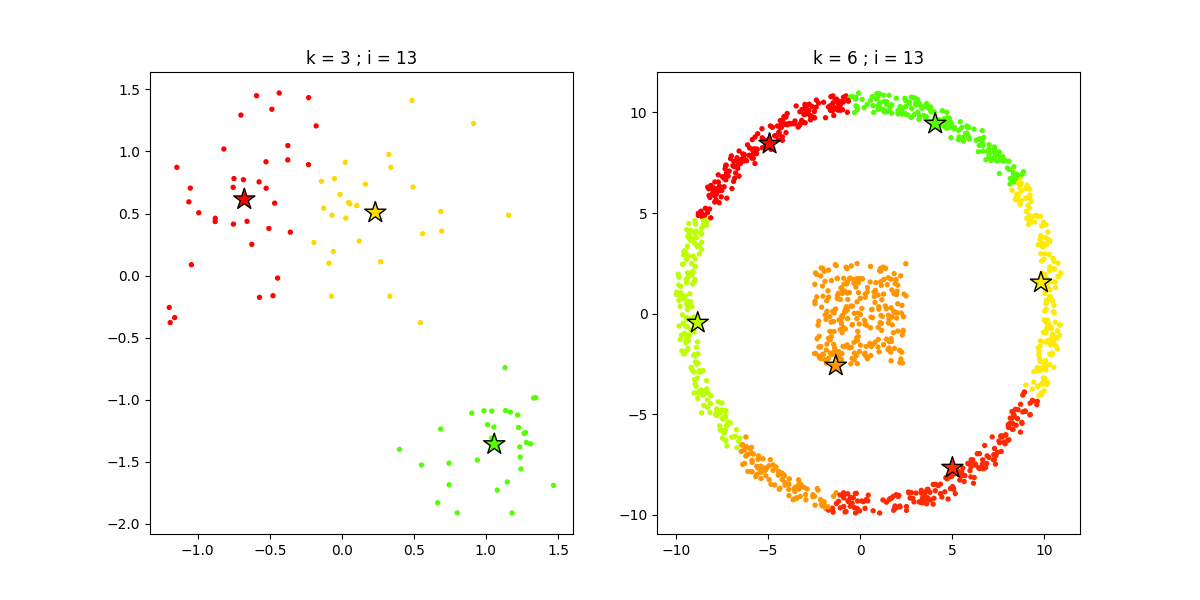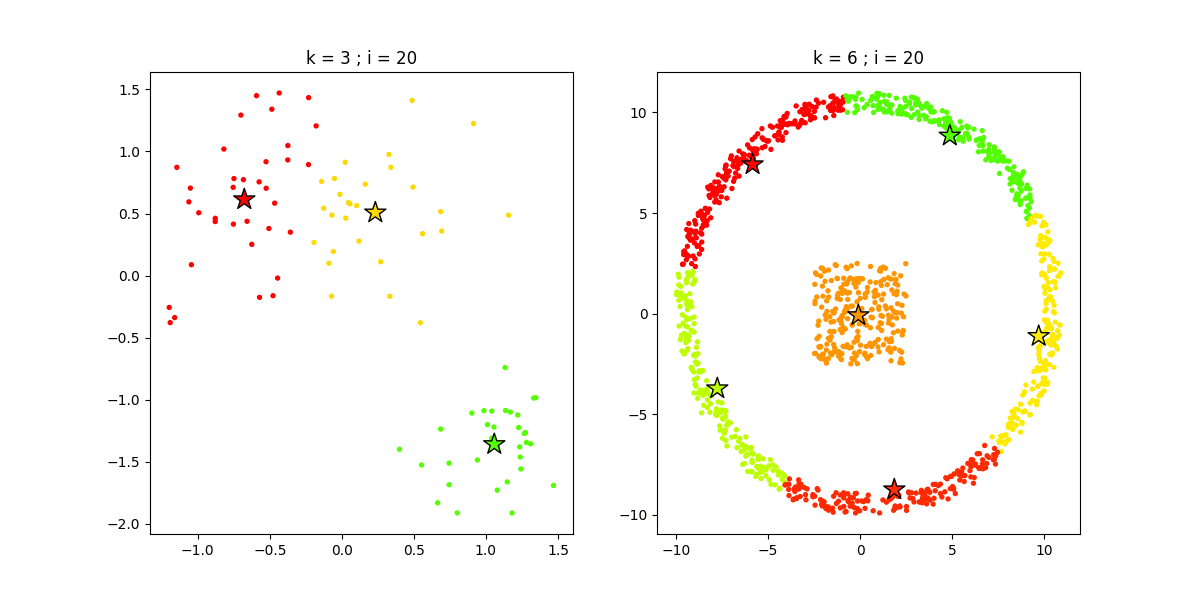
优点:K 均值聚类是最流行的聚类算法,因为该算法足够快速、简单,并且如果你的预处理数据和特征工程十分有效,那么该聚类算法将拥有令人惊叹的灵活性。
缺点:该算法需要指定集群的数量,而 K 值的选择通常都不是那么容易确定的。另外,如果训练数据中的真实集群并不是类球状的,那么 K 均值聚类会得出一些比较差的集群。
K-means实例代码:
后面我学习了再补充,大家现在可以参考这篇文章进行学习:K-Means
3.2 Affinity Propagation 聚类
AP 聚类算法是一种相对较新的聚类算法,该聚类算法基于两个样本点之间的图形距离(graph distances)确定集群。采用该聚类方法的集群拥有更小和不相等的大小。
优点:该算法不需要指出明确的集群数量(但是需要指定「sample preference」和「damping」等超参数)。
缺点:AP 聚类算法主要的缺点就是训练速度比较慢,并需要大量内存,因此也就很难扩展到大数据集中。另外,该算法同样假定潜在的集群是类球状的。
3.3 层次聚类(Hierarchical / Agglomerative)
层次聚类是一系列基于以下概念的聚类算法:最开始由一个数据点作为一个集群,对于每个集群,基于相同的标准合并集群,重复这一过程直到只留下一个集群,因此就得到了集群的层次结构。
#关于聚类算法,大家可以参考:机器理解大数据的秘密:聚类算法深度详解
4.dimensionality reduction (降维)
降维是机器学习另一个重要的领域, 降维有很多重要的应用, 特征的维数过高, 会增加训练的负担与存储空间, 降维就是希望去除特征的冗余, 用更加少的维数来表示特征.降维算法最基础的就是PCA了, 后面的很多算法都是以PCA为基础演化而来。
降维的途径:特征选择(Feature Selection)、特征提取(Feature Extraction)
目的:是一个去掉冗余的不重要的变量,而只留下主要的可以保持信息的变量的过程
输出:一组描述原数据的,低维度的隐式特征(或称主要特征)
应用: 用于消除噪声、对抗数据稀疏问题 ,进行数据压缩
4.1主成分分析PCA(Principal Component Analysis)
主成分分析(PCA)是十分常用的一种降维方法,从字面意思看是通过找到数据中主要的特征然后删去其余的作用小的特征来实现降维,寻找一个低纬度的平面对数据进行投影,以便最小化每个点与投影后的对应点之间的距离的平方值。
在高维图像中,让数据集映射在一个低维超平面上可以从两个方面看:
最小重构性:即样本点到超平面的距离足够近。
最大可分性:样本点映射到投影平面尽可能分散。
通过对以上两个方面分析,可以得到主成分分析的两个等价推导,首先看最小重构性。
4.2等距映射(Isometric Mapping)
4.3局部线性嵌入(Locally Linear Embedding)
结语
机器学习的这四个基本模型,几乎涵盖了所有的问题,在工业场景中,我们不可能只用一种途径就可以解决所有的问题,有时候我们需要几者结合,有时候需要恰当的选择,所以,我们学习这章的目的就在于了解机器学习的基本框架方法,有助于我们深入的进行研究。