DDC代码阅读笔记
论文:《Deep Domain Confusion: Maximizing for Domain Invariance》
https://arxiv.org/abs/1412.3474
[DDC]Deep Domain Confusion: Maximizing for Domain Invariance_HHzdh的博客-CSDN博客
源码:https://github.com/guoXuehong77/transferlearning/tree/master/code/deep/DDC_DeepCoral
前言(摘自README.md)
该源码主要是做了《Deep CORAL Correlation Alignment for Deep Domain Adaptation》的复现工作,但是只要把源码中的CORAL loss替换成MMD loss, 就可以复现DDC了。
网络部分
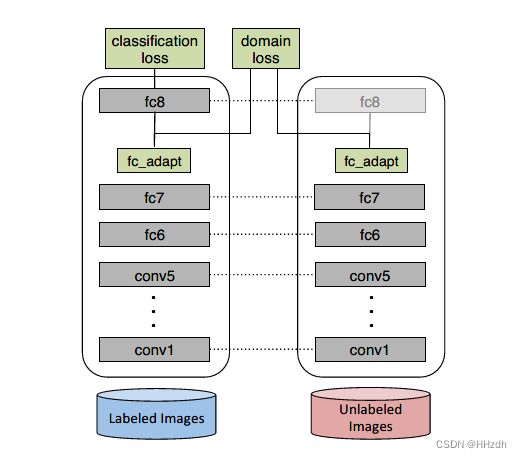
该架构使用了一个自适应层(adaptation layer)和一个基于最大平均偏差(MMD,maximum mean discrepancy)的domain confusion loss来自动学习一个联合训练的表示来优化分类和域不变性。论文是在AlexNet的fc7层后面加入fc_adapt层,源码中实际上实现了多种backbone,包括alexnet、resnet18-152。
代码部分
1、backbone.py
该文件定义了几种经典的CNN网络,包括alexnet、resnet18、resnet34、resnet50、resnet101、resnet152。初始化时加载预训练模型。
import numpy as np
import torch
import torch.nn as nn
import torchvision
from torchvision import models
from torch.autograd import Variable
# convnet without the last layer
class AlexNetFc(nn.Module):
def __init__(self):
super(AlexNetFc, self).__init__()
model_alexnet = models.alexnet(pretrained=True)
self.features = model_alexnet.features
self.classifier = nn.Sequential()
for i in range(6):
self.classifier.add_module(
"classifier"+str(i), model_alexnet.classifier[i])
self.__in_features = model_alexnet.classifier[6].in_features
def forward(self, x):
x = self.features(x)
x = x.view(x.size(0), 256*6*6)
x = self.classifier(x)
return x
def output_num(self):
return self.__in_features
class ResNet18Fc(nn.Module):
def __init__(self):
super(ResNet18Fc, self).__init__()
model_resnet18 = models.resnet18(pretrained=True)
self.conv1 = model_resnet18.conv1
self.bn1 = model_resnet18.bn1
self.relu = model_resnet18.relu
self.maxpool = model_resnet18.maxpool
self.layer1 = model_resnet18.layer1
self.layer2 = model_resnet18.layer2
self.layer3 = model_resnet18.layer3
self.layer4 = model_resnet18.layer4
self.avgpool = model_resnet18.avgpool
self.__in_features = model_resnet18.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet34Fc(nn.Module):
def __init__(self):
super(ResNet34Fc, self).__init__()
model_resnet34 = models.resnet34(pretrained=True)
self.conv1 = model_resnet34.conv1
self.bn1 = model_resnet34.bn1
self.relu = model_resnet34.relu
self.maxpool = model_resnet34.maxpool
self.layer1 = model_resnet34.layer1
self.layer2 = model_resnet34.layer2
self.layer3 = model_resnet34.layer3
self.layer4 = model_resnet34.layer4
self.avgpool = model_resnet34.avgpool
self.__in_features = model_resnet34.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet50Fc(nn.Module):
def __init__(self):
super(ResNet50Fc, self).__init__()
model_resnet50 = models.resnet50(pretrained=True)
self.conv1 = model_resnet50.conv1
self.bn1 = model_resnet50.bn1
self.relu = model_resnet50.relu
self.maxpool = model_resnet50.maxpool
self.layer1 = model_resnet50.layer1
self.layer2 = model_resnet50.layer2
self.layer3 = model_resnet50.layer3
self.layer4 = model_resnet50.layer4
self.avgpool = model_resnet50.avgpool
self.__in_features = model_resnet50.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet101Fc(nn.Module):
def __init__(self):
super(ResNet101Fc, self).__init__()
model_resnet101 = models.resnet101(pretrained=True)
self.conv1 = model_resnet101.conv1
self.bn1 = model_resnet101.bn1
self.relu = model_resnet101.relu
self.maxpool = model_resnet101.maxpool
self.layer1 = model_resnet101.layer1
self.layer2 = model_resnet101.layer2
self.layer3 = model_resnet101.layer3
self.layer4 = model_resnet101.layer4
self.avgpool = model_resnet101.avgpool
self.__in_features = model_resnet101.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
class ResNet152Fc(nn.Module):
def __init__(self):
super(ResNet152Fc, self).__init__()
model_resnet152 = models.resnet152(pretrained=True)
self.conv1 = model_resnet152.conv1
self.bn1 = model_resnet152.bn1
self.relu = model_resnet152.relu
self.maxpool = model_resnet152.maxpool
self.layer1 = model_resnet152.layer1
self.layer2 = model_resnet152.layer2
self.layer3 = model_resnet152.layer3
self.layer4 = model_resnet152.layer4
self.avgpool = model_resnet152.avgpool
self.__in_features = model_resnet152.fc.in_features
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
return x
def output_num(self):
return self.__in_features
network_dict = {"alexnet": AlexNetFc,
"resnet18": ResNet18Fc,
"resnet34": ResNet34Fc,
"resnet50": ResNet50Fc,
"resnet101": ResNet101Fc,
"resnet152": ResNet152Fc}
2、data_loader.py
数据加载部分,对于训练集数据Resize成[256,256]大小再进行[224,224]的随机裁剪,后续操作以此为随机水平翻转、转为tensor、标准化;而对于测试集数据则直接Resize为[224,224]大小,后进行tensor化和标准化。
from torchvision import datasets, transforms
import torch
def load_data(data_folder, batch_size, train, kwargs):
transform = {
'train': transforms.Compose(
[transforms.Resize([256, 256]),
transforms.RandomCrop(224),
transforms.RandomHorizontalFlip(),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])]),
'test': transforms.Compose(
[transforms.Resize([224, 224]),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
}
data = datasets.ImageFolder(root = data_folder, transform=transform['train' if train else 'test'])
data_loader = torch.utils.data.DataLoader(data, batch_size=batch_size, shuffle=True, **kwargs, drop_last = True if train else False)
return data_loader
3、mmd.py
即论文提出的MMD loss,MMD(最大均值差异)是迁移学习,尤其是Domain adaptation (域适应)中使用最广泛(目前)的一种损失函数,主要用来度量两个不同但相关的分布的距离。两个分布的距离定义为:可以参考以下这篇博客。【代码阅读】最大均值差异(Maximum Mean Discrepancy, MMD)损失函数代码解读(Pytroch版)_Vincent_gc的博客-CSDN博客_mmd损失

import torch
import torch.nn as nn
class MMD_loss(nn.Module):
def __init__(self, kernel_type='rbf', kernel_mul=2.0, kernel_num=5):
'''
source:源域数据(n * len(x))
target:目标域数据(m * len(y))
kernel_mul:核的倍数
kernel_num:多少个核
fix_sigma: 不同高斯核的sigma值
'''
super(MMD_loss, self).__init__()
self.kernel_num = kernel_num
self.kernel_mul = kernel_mul
self.fix_sigma = None
self.kernel_type = kernel_type
def guassian_kernel(self, source, target, kernel_mul=2.0, kernel_num=5, fix_sigma=None):
n_samples = int(source.size()[0]) + int(target.size()[0]) # 求矩阵的行数,一般source和target的尺度是一样的,这样便于计算
total = torch.cat([source, target], dim=0) # 将source,target按列方向合并
# 将total复制(n+m)份
total0 = total.unsqueeze(0).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
# 将total的每一行都复制成(n+m)行,即每个数据都扩展成(n+m)份
total1 = total.unsqueeze(1).expand(
int(total.size(0)), int(total.size(0)), int(total.size(1)))
# 求任意两个数据之间的和,得到的矩阵中坐标(i,j)代表total中第i行数据和第j行数据之间的l2 distance(i==j时为0)
L2_distance = ((total0-total1)**2).sum(2)
# 调整高斯核函数的sigma值
if fix_sigma:
bandwidth = fix_sigma
else:
bandwidth = torch.sum(L2_distance.data) / (n_samples**2-n_samples)
# 以fix_sigma为中值,以kernel_mul为倍数取kernel_num个bandwidth值(比如fix_sigma为1时,得到[0.25,0.5,1,2,4]
bandwidth /= kernel_mul ** (kernel_num // 2)
bandwidth_list = [bandwidth * (kernel_mul**i)
for i in range(kernel_num)]
# 高斯核函数的数学表达式
kernel_val = [torch.exp(-L2_distance / bandwidth_temp)
for bandwidth_temp in bandwidth_list]
# 得到最终的核矩阵
return sum(kernel_val)
def linear_mmd2(self, f_of_X, f_of_Y):
loss = 0.0
delta = f_of_X.float().mean(0) - f_of_Y.float().mean(0)
loss = delta.dot(delta.T)
return loss
def forward(self, source, target):
if self.kernel_type == 'linear':
return self.linear_mmd2(source, target)
elif self.kernel_type == 'rbf':
batch_size = int(source.size()[0]) # 一般默认为源域和目标域的batchsize相同
kernels = self.guassian_kernel(
source, target, kernel_mul=self.kernel_mul, kernel_num=self.kernel_num, fix_sigma=self.fix_sigma)
# 将核矩阵分成4部分
with torch.no_grad():
XX = torch.mean(kernels[:batch_size, :batch_size])
YY = torch.mean(kernels[batch_size:, batch_size:])
XY = torch.mean(kernels[:batch_size, batch_size:])
YX = torch.mean(kernels[batch_size:, :batch_size])
loss = torch.mean(XX + YY - XY - YX) # 因为一般都是n==m,所以L矩阵一般不加入计算
torch.cuda.empty_cache()
return loss
4、models.py
import torch.nn as nn
from Coral import CORAL
import mmd
import backbone
class Transfer_Net(nn.Module):
def __init__(self, num_class, base_net='resnet50', transfer_loss='mmd', use_bottleneck=True, bottleneck_width=256, width=1024):
super(Transfer_Net, self).__init__()
self.base_network = backbone.network_dict[base_net]()
self.use_bottleneck = use_bottleneck
self.transfer_loss = transfer_loss
bottleneck_list = [nn.Linear(self.base_network.output_num(
), bottleneck_width), nn.BatchNorm1d(bottleneck_width), nn.ReLU(), nn.Dropout(0.5)]
self.bottleneck_layer = nn.Sequential(*bottleneck_list)
classifier_layer_list = [nn.Linear(self.base_network.output_num(), width), nn.ReLU(), nn.Dropout(0.5),
nn.Linear(width, num_class)]
self.classifier_layer = nn.Sequential(*classifier_layer_list)
self.bottleneck_layer[0].weight.data.normal_(0, 0.005)
self.bottleneck_layer[0].bias.data.fill_(0.1)
for i in range(2):
self.classifier_layer[i * 3].weight.data.normal_(0, 0.01)
self.classifier_layer[i * 3].bias.data.fill_(0.0)
def forward(self, source, target):
source = self.base_network(source)
target = self.base_network(target)
source_clf = self.classifier_layer(source)
if self.use_bottleneck:
source = self.bottleneck_layer(source)
target = self.bottleneck_layer(target)
transfer_loss = self.adapt_loss(source, target, self.transfer_loss)
return source_clf, transfer_loss
def predict(self, x):
features = self.base_network(x)
clf = self.classifier_layer(features)
return clf
def adapt_loss(self, X, Y, adapt_loss):
"""Compute adaptation loss, currently we support mmd and coral
Arguments:
X {tensor} -- source matrix
Y {tensor} -- target matrix
adapt_loss {string} -- loss type, 'mmd' or 'coral'. You can add your own loss
Returns:
[tensor] -- adaptation loss tensor
"""
if adapt_loss == 'mmd':
mmd_loss = mmd.MMD_loss()
loss = mmd_loss(X, Y)
elif adapt_loss == 'coral':
loss = CORAL(X, Y)
else:
loss = 0
return loss
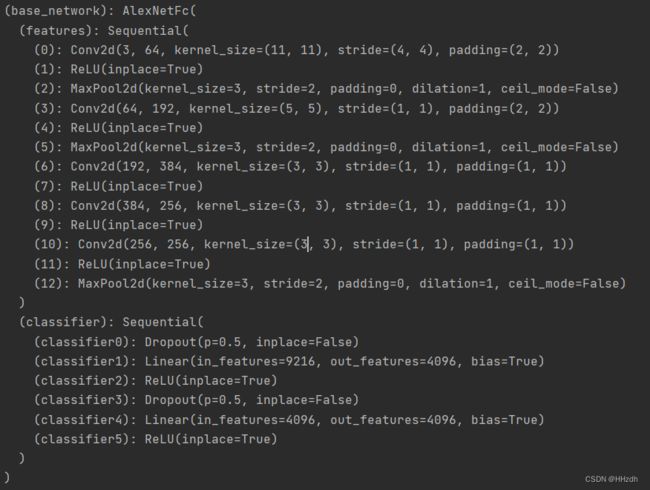
以AlexNet为例,model.py中定义的base_network即直接调用backbone.py中的alexnet,根据网络结构图,下图即conv1-5以及fc6-7的结构,因为这部分源域和目标域均使用且参数共享,故作为base_network。
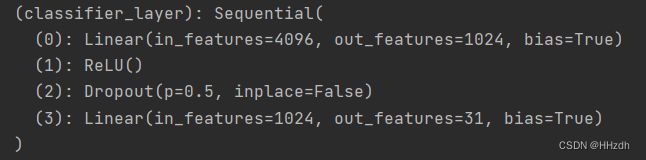
而bottleneck_layer 即论文中提到的fc_adapt层,结构如下所示。
5、main.py
(1)参数设置
- model:选择backbone中的base_net模型
- src:源域数据集;tar:目标域数据集;n_class:因为用的是office31数据集,共31类
- data:放office31数据集的路径,关注数据集的形式,参考深度学习:OFFICE31数据集训练精度每次都是100%_学好迁移Learning的博客-CSDN博客_office31
- trans_loss:选择是采用mmd loss还是coral loss,复现DDC使用的是MMD loss
# Command setting
parser = argparse.ArgumentParser(description='DDC_DCORAL')
parser.add_argument('--model', type=str, default='alexnet')
parser.add_argument('--batchsize', type=int, default=2)
parser.add_argument('--src', type=str, default='amazon')
parser.add_argument('--tar', type=str, default='webcam')
parser.add_argument('--n_class', type=int, default=31)
parser.add_argument('--lr', type=float, default=1e-3)
parser.add_argument('--n_epoch', type=int, default=100)
parser.add_argument('--momentum', type=float, default=0.9)
parser.add_argument('--decay', type=float, default=5e-4)
parser.add_argument('--data', type=str, default='E:\Myself\Office31\Original_images')
parser.add_argument('--early_stop', type=int, default=20)
parser.add_argument('--lamb', type=float, default=10)
parser.add_argument('--trans_loss', type=str, default='mmd')
args = parser.parse_args()(2)test函数
Pytorch:model.train()和model.eval()用法和区别,以及model.eval()和torch.no_grad()的区别_BEINTHEMEMENT的博客-CSDN博客_def train(model):
model.eval()的作用是不启用 Batch Normalization 和 Dropout。如果模型中有BN层(Batch Normalization)和Dropout。在测试时添加model.eval()。model.eval()是保证BN层能够用全部训练数据的均值和方差,即测试过程中要保证BN层的均值和方差不变。对于Dropout,model.eval()是利用到了所有网络连接,即不进行随机舍弃神经元。
def test(model, target_test_loader):
model.eval()
test_loss = utils.AverageMeter()
correct = 0
criterion = torch.nn.CrossEntropyLoss()
len_target_dataset = len(target_test_loader.dataset)
with torch.no_grad():
for data, target in target_test_loader:
data, target = data.to(DEVICE), target.to(DEVICE)
s_output = model.predict(data)
loss = criterion(s_output, target)
test_loss.update(loss.item())
pred = torch.max(s_output, 1)[1]
correct += torch.sum(pred == target)
acc = 100. * correct / len_target_dataset
return acc(3)train函数
model.train()的作用是启用 Batch Normalization 和 Dropout。如果模型中有BN层(Batch Normalization)和Dropout,需要在训练时添加model.train()。model.train()是保证BN层能够用到每一批数据的均值和方差。对于Dropout,model.train()是随机取一部分网络连接来训练更新参数。
def train(source_loader, target_train_loader, target_test_loader, model, optimizer):
len_source_loader = len(source_loader)
len_target_loader = len(target_train_loader)
best_acc = 0
stop = 0
for e in range(args.n_epoch):
stop += 1
train_loss_clf = utils.AverageMeter()
train_loss_transfer = utils.AverageMeter()
train_loss_total = utils.AverageMeter()
model.train()
iter_source, iter_target = iter(source_loader), iter(target_train_loader)
n_batch = min(len_source_loader, len_target_loader)
criterion = torch.nn.CrossEntropyLoss()
for _ in range(n_batch):
data_source, label_source = iter_source.next()
data_target, _ = iter_target.next()
data_source, label_source = data_source.to(
DEVICE), label_source.to(DEVICE)
data_target = data_target.to(DEVICE)
optimizer.zero_grad()
label_source_pred, transfer_loss = model(data_source, data_target)
clf_loss = criterion(label_source_pred, label_source)
loss = clf_loss + args.lamb * transfer_loss
loss.backward()
optimizer.step()
train_loss_clf.update(clf_loss.item())
train_loss_transfer.update(transfer_loss.item())
train_loss_total.update(loss.item())
# Test
acc = test(model, target_test_loader)
log.append([train_loss_clf.avg, train_loss_transfer.avg, train_loss_total.avg])
np_log = np.array(log, dtype=float)
np.savetxt('train_log.csv', np_log, delimiter=',', fmt='%.6f')
print('Epoch: [{:2d}/{}], cls_loss: {:.4f}, transfer_loss: {:.4f}, total_Loss: {:.4f}, acc: {:.4f}'.format(
e, args.n_epoch, train_loss_clf.avg, train_loss_transfer.avg, train_loss_total.avg, acc))
if best_acc < acc:
best_acc = acc
stop = 0
if stop >= args.early_stop:
break
print('Transfer result: {:.4f}'.format(best_acc))(4)数据加载和main
# 方便自己电脑运行,num_workers更改为1,原代码为4
def load_data(src, tar, root_dir):
folder_src = os.path.join(root_dir, src)
folder_tar = os.path.join(root_dir, tar)
source_loader = data_loader.load_data(
folder_src, args.batchsize, True, {'num_workers': 1})
target_train_loader = data_loader.load_data(
folder_tar, args.batchsize, True, {'num_workers': 1})
target_test_loader = data_loader.load_data(
folder_tar, args.batchsize, False, {'num_workers': 1})
return source_loader, target_train_loader, target_test_loader
if __name__ == '__main__':
torch.manual_seed(0)
source_name = "amazon"
target_name = "webcam"
print('Src: %s, Tar: %s' % (source_name, target_name))
print('Backbone: %s,Loss: %s' % (args.model, args.trans_loss))
source_loader, target_train_loader, target_test_loader = load_data(
source_name, target_name, args.data)
model = models.Transfer_Net(
args.n_class, transfer_loss=args.trans_loss, base_net=args.model).to(DEVICE)
print(model)
optimizer = torch.optim.SGD([
{'params': model.base_network.parameters()},
{'params': model.bottleneck_layer.parameters(), 'lr': 10 * args.lr},
{'params': model.classifier_layer.parameters(), 'lr': 10 * args.lr},
], lr=args.lr, momentum=args.momentum, weight_decay=args.decay)
train(source_loader, target_train_loader,
target_test_loader, model, optimizer)
实验部分
debugging~虽然跑通了但是跟论文和github给出的结果相差有点大??