MobileViT:挑战MobileNet端侧霸主
论文:《MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer》
轻量级的 CNN 在移动视觉任务中非常有用,通过卷积层的局部感知功能,可以让 CNN 网络模型在不同的视觉任务中以较少的参数学习表征。不过值得注意的是,CNN 类型结构的网络模型在空间上是局部建模的,也就是主要对局部特征进行感知提取。如果想要学习全局表征,可以采用基于自注意的视觉Transformer(ViT)。但是与 CNN 不同,ViT 的参数量一般来说都比较大。
那现在!是否有可能结合 CNN 和 ViT 的优势,为移动视觉任务构建一个轻量级、低延迟的网络? 为此,作者提出了 MobileViT,一种用于移动设备的轻量级通用视觉Transformer。
实验结果表明,MobileViT 在不同的任务和数据集上显著优于基于 CNN 和 ViT 的网络。在 ImageNet-1k 数据集上,MobileViT 实现了 78.4% 的 Top-1 精度,拥有约 600 万个参数,对于类似数量的参数,其精度分别比 MobileNetv3(基于CNN)和 DeIT(基于ViT)高3.2%和6.2%。在 MS-COCO 目标检测任务中,对于相同数量的参数,MobileViT 比 MobileNetv3 的准确度高 5.7%!

MobileNet V2
因为 MobileViT 借鉴了 MobileNet V2 的结构体,所以在这里简单的讲讲 MobileNet V2 的经典内容。
MobileNet V2 是在 V1 基础之上的改进,V1主要思想就是深度可分离卷积(depthwise separable convolution),V2的新想法包括 Linear Bottleneck 和 Inverted Residuals。
Linear Bottleneck
深度神经网络是由 n 个 L_i 层构成,每层经过激活输出的张量为 [d_i,w_i,h_i]。作者认为一连串的卷积和激活层形成一个 manifold of interest,在神经网络中 manifold 可以嵌入到低维子空间,通俗点说,我们查看的卷积层中所有单个 d 通道像素时,这些值中存在多种编码信息,manifold 位于其中的。通过变换,进一步嵌入到下一个低维子空间中,例如通过 1x1 卷积变换维数,转换 manifold 所在空间维度。
这样的想法比较容易验证,可通过减少层维度从而降低激活空间的维度。MobileNet v1 通过宽度因子(width factor)在计算量和精度之间取折中。用上面的理论来说,宽度因子控制激活空间的维度,直到 manifold 横跨整个空间。
然而,由于深度卷积神经网络的层是具有非线性激活函数的。以ReLU变换为例,会存在以下特点:
- 如果当前激活空间内 manifold 完整度较高,经过ReLU层可能会让激活空间坍塌,不可避免的会丢失信息。
- 如果输入对应的输出是非零的,那么输入和输出之间其实对应的就是一个线性映射关系。

在设计网络结构的时候,想要减少运算量,就需要尽可能将网络维度设计的低一些,但是维度如果低的话,激活变换 ReLU 函数可能会滤除很多有用信息。然后作者就想到了,反正 ReLU 0以上的计算其实就是一个线性映射。那么如果全用线性分类器,会不会就不会丢失一些维度信息,同时可以设计出维度较低的层呢?
作者针对这个问题使用 linear bottleneck(即不使用ReLU激活,做了线性变换)的来代替原本的非线性激活变换。到此,优化网络架构的思路也出来了:
通过在卷积模块中插入linear bottleneck来捕获 manifold。实验证明,使用linear bottleneck 可以防止非线性数据被破坏太多。
从linear bottleneck到深度卷积之间的的维度比,称为Expansion factor(扩展系数),该系数控制了整个block的通道数。下一部分介绍就要用到这个Expansion了。
在 Depthwise Separable Convolution 引入 bottlenck layer 后,结构如图所示,其中浅色代表的是下一个 block 的开始,并且注意方块代表的是特征图,而红色映射才是卷积或者 ReLU 操作。
图(a)是常规的卷积,而图(b)是 Depthwise Separable Convolution,在MobileNetv1 中大量使用。当在 Depthwise Separable Convolution 后面加入 bottlenck layer 就变成了图(c),但是考虑到block是互相堆积的,调整一下视角,如果将 bottlenck layer 看成 block 的输入,那么这种结构也等价于图(d)。
对于图(d),block 中开始的 1x1 卷积层称为 expansion layer,它的通道大小(inner size)和输入 bottleneck 层的通道大小之比,称为扩展比(expansion ratio)。扩展层之后是 depthwise 卷积,然后采用 1x1 卷积得到 block 的输出特征,这个卷积后面没有非线性激活。对于图(d)这种结构,block 的输入和输出特征是bottleneck 特征,所以这个 block 称为 bottleneck block。

Inverted Residuals
MobileNetV1 网络主要思路就是深度可分离卷积的堆叠。在 V2 的网络设计中,除了继续使用深度可分离结构之外,还使用了 Expansion layer 和 Projection layer。这个projection layer 使用 1x1 的卷积,目的是希望把高维特征映射到低维空间去。Expansion layer 的功能正相反,使用 1x1 的卷积,目的是将低维空间映射到高维空间。
bottleneck residual block(ResNet)是中间窄两头胖,在 MobileNetV2 中正好反了过来,所以,在 MobileNetV2 的中称这样的网络结构为 Inverted residuals。
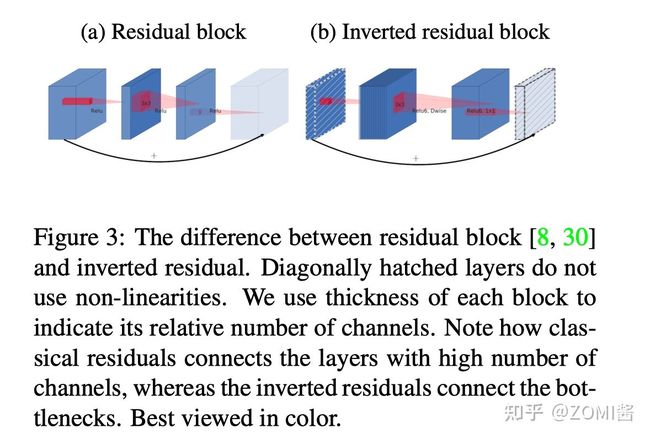
需要注意的是 residual connection 是在输入和输出的部分进行连接。刚才我们知道,Linear Bottleneck 因为从高维向低维转换,使用 ReLU 激活函数可能会造成信息丢失或破坏。所以在 projection convolution 这一部分,不再使用 ReLU 激活函数而是使用线性激活函数。
下面谈谈为什么要构造一个这样的网络结构:如果 tensor 维度越低,卷积层的乘法计算量就越小。如果整个网络都是低维的 tensor,整体计算速度就会很快。
然而,如果只是使用低维的 tensor 效果并不会好。如果卷积层的过滤器都是使用低维的 tensor 来提取特征的话,那么就没有办法提取到整体的足够多的信息。所以,如果提取特征数据的话,我们可能更希望有高维的 tensor 来做这个事情。V2就设计这样一个结构来达到平衡。
先通过 Expansion layer 来扩展维度,之后在用深度可分离卷积来提取特征,之后使用Projection layer来压缩数据,让网络从新变小。因为 Expansion layer 和 Projection layer 都是有可以学习的参数,所以整个网络结构可以学习到如何更好的扩展数据和从新压缩数据。

MobileViT
MobileViT 个人认为是基于 Mobilenet V2 模型架构之上,加入了新的 ViT 模块,那这个模块作者称为 MobileViT block。并带来了一些新的结果:
- 更好的性能:在相同的参数情况下,与现有的轻量级CNN相比,MobileViT 模型在不同的移动视觉任务中实现了更好的精度。
- 更好的泛化能力:泛化能力是指训练和评价指标之间的差距,对于具有相似的训练指标的两个模型,具有更好评价指标的模型更具有通用性,因为它可以更好地预测未见的数据集。
- 更好的鲁棒性:一个好的模型应该对超参数具有鲁棒性,因为调优这些超参数会消耗时间和资源。与大多数ViT的模型不同,MobileViT 模型使用基于增强训练,对L2正则化不太敏感。
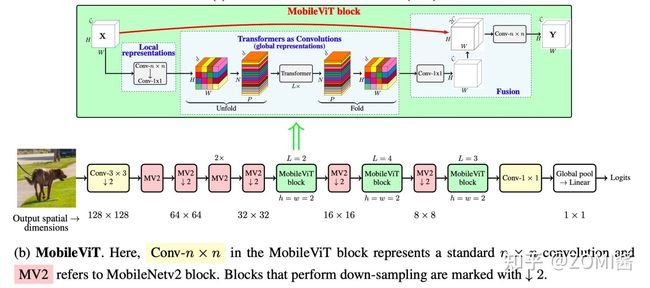
MobileViT 的初始层是一个 stride=3×3 的标准卷积,其次是 MobileNetv2(MV2) Block 和 MobileViT Block,使用 Swish 作为激活函数。跟随 CNN 模型,在MobileViT 块中使用 n=3。特征图的空间维数通常是2和h的倍数。因此,在所有空间层面设 h=w=2,MobileViT 网络中的 MV2 块主要负责降采样。
动机和方法
一个标准的 ViT 模型将输入 reshape 为 patches,将其投影到固定的 D 维空间,然后使用 L 个 transformer block 学习 patches 之间的表征。
vision transformer 由于这些模型忽略了 CNN 模型固定的局部空间特征,所以它们需要更多的参数来学习图像中的表征。例如,与 CNN 网络 deeplabv3 相比,基于 vit 的网络多学习了6倍的参数才可以提供相似的分割性能(DPT vs DeepLabv3:345 M vs. 59 M)。此外与 CNN 相比,这些模型的优化性能不佳。ViT 对 L2 正则化很敏感,需要大量的数据增强以防止过拟合。

MobileViT 引入了 MobileViT block,它可以有效地将局部和全局信息进行编码。与ViT 及其变体不同,MobileViT 从不同的角度学习全局表示。标准卷积涉及三个操作:展开(unfloading) 、局部处理(local processing) 和展开(folding)。MobileViT 块使用 Transformer 将卷积中的局部建模替换为全局建模。这使得MobileViT 块具有 CNN 和 ViT 的性质,有助于它用更少的参数和简单的训练方式学习更好的表示。一句话来说,就是:
作者提出了一种轻量级ViT模型 MobileViT,其核心思想是用 Transformer 作为卷积来学习全局表示。
MobileViT block
MobileViT 块的结构如图所示,可以用较少的参数在输入张量中建模局部和全局信息。对于输入的张量 X,MobileViT 块首先用 n×n 和 1×1 卷积对输入进行操作,得到 X_L。其中 n×n 卷积用于学习局部的空间信息,1×1 卷积用于将输入特征投影到高维空间。
为了获取更长距离的关系,有一种方法是利用空洞卷积(dilated convolution)进行建模。然而,这种方法需要仔细选择扩张率(dilation rate)。另一个解决方案是自注意力,具有多头自注意的视觉 Transformer(ViT)被证明对视觉识别任务是有效的。然而,ViT 的参数量很大,并且优化能力较弱。
为了使 MobileViT 能够学习具有空间归纳偏置的全局表示,作者首先将 X_L 展开为 N 个不重叠的patch X_U。其中,P=wh,N=WH/P 为patch的数量,w,h为 patch 的高和宽。跨 patch 中的每个像素 p 通过 Transformer 来进行建模,得到X_G:
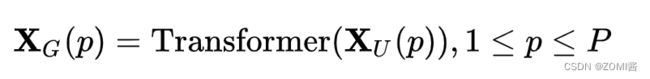
与丢失像素空间顺序的ViT不同,MobileViT 既不会丢失 patch 顺序,也不会丢失每个 patch 内像素的空间顺序。作者折叠了 X_G 来获得 X_F,然后 X_F 用 1x1 的卷积得到 C 维的特征。再使用 nxn 的卷积用于融合局部和全局特征。由于 X_U 使用卷积对 n×n 区域的局部信息进行编码,而 X_G 对 P 个 patch 中的第 p 个位置的全局信息进行编码,因此 X_G 可以对 X 中的全局信息进行感知。最终,MobileViT块的整体有效感受野为 H×W,也就是一个全局感知的操作。
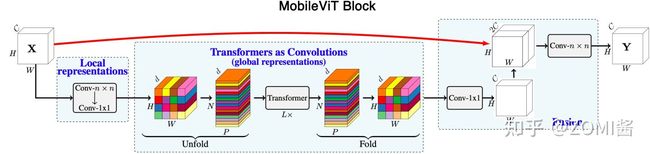
在MobileViT Block中,每个像素都可以感知到其他像素。图中,黑色和灰色网格中的每个单元分别表示一个patch和一个像素。红色像素通过transformer处理蓝色像素(其他patch中相应位置的像素)。因为蓝色像素已经使用卷积对邻近像素的信息进行了编码,这就允许红色像素对图像中所有像素的信息进行编码。

实验部分
- 与 CNN 结构模型进行对比
下图(a)示了本文方法和其他轻量级CNN网络的对比,可以看出 MobileViT 模型精度的优越性。(b)对比了本文方法和其他轻量级网络在相似参数量下的性能对比,MobileViT 具有更高的性能。(c)展示了本文方法和 heavy-weight CNN的对比,MobileViT 可以用更少的参数,达到更高的准确率。
MobileViT 在不同网络规模(MobileNetv1、MobileNetv2、ShuffleNetv2、ESPNetv2和MobileNetv3)上的性能优于轻量级CNN。例如,对于一个大约有250万个参数的模型,在ImageNet-1k验证集上,MobileViT 比 MobileNetv2、ShuffleNetv2和MobileNetv3 的性能分别高出 5.0%、5.4%和7.4%。
MobileViT 提供了比 Heavy-weight CNN(ResNet, DenseNet, ResNet-se和EfficientNet)更好的性能。例如,对于相同数量的参数,MobileVi T比 effentnet 的准确率高出 2.1%。

- 与 ViTs 结构模型进行对比
下面还对比了 MobileViT 和 ViT 结构的的参数量和性能,可以看出,MobileViT 可以用更少的参数、更简单的数据增强,达到更高的性能。图中比较了 MobileViT 和在ImageNet-1k 数据集上从头开始训练的ViT变体(DeIT、T2T、PVT、CAIT、DeepViT、CeiT、CrossViT、LocalViT、PiT、ConViT、ViL、BoTNet和Mobile-former)。
不像 ViT 变体,显著受益于高级的数据增强(PiT w/ basic vs. advanced: 72.4%(R4) vs. 78.1%(R17)), MobileViT 通过更少的参数和基本的增强实现了更好的性能。例如,MobileViT 比 DeiT 小2.5,好2.6%。
总的来说,这些结果表明,与CNN相似,MobileViTs易于优化和鲁棒性强。因此,MobileViT 可以很容易地应用于新的任务和数据集。

- 下游任务进行对比测试
下面展示了 MobileViT 在语义分割任务/分类任务/检测任务,基于不同主干网络的DeepLabv3 性能和参数对比,可以看出,本文的方法在各种轻量级网络中,能够达到更高的性能。并且推理性能还能够做到实时 33ms 以内啦。
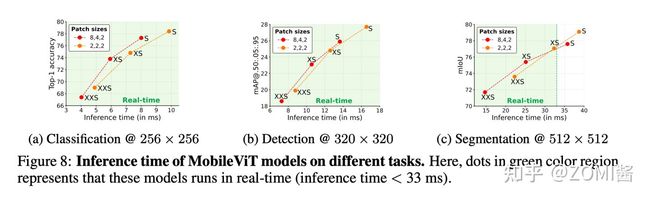
带有 MobileViT 的 DeepLabv3 更小更好。使用 MobileViT 代替 MobileNetv2 作为 Backbone 时,DeepLabv3 的性能提高了 1.4%,体积减少了1.6×。此外,MobileViT 提供了具有竞争力的性能与模型 renet-101 相比,所需参数减少了 9 倍。这一段数字就很有意思了,因为实验部分就看你用谁跟谁比较,毕竟田忌赛马嘛。
小结
MobileViT 是 Apple 公司发表的一种用于移动设备的轻量级通用视觉 Transformer。作者称,这是首个能比肩轻量级 CNN 网络性能的轻量级 ViT 工作。
MobileViT 结构上基本基于 MobileNet V2 而改进增加了 MobileViT block,但是同样能够实现一个不错的精度表现,文章实验部分大量的对比了 MobileViT 跟 CNN 和 ViT 模型的参数量和模型大小,不过值得一提的是在端侧除了模型大小以外,更加重视模型的性能,只能说这篇文章经典之处是开创了 CNN 融合 ViT 在端侧的研究。
引用
[1] https://blog.csdn.net/qq_42178122/article/details/121028215
[2] 《MobileViT》它来了!轻量、通用、适用于移动设备的Transformer!苹果公司提出了MobileViT - 知乎
[3] Sandler, Mark, et al. "Mobilenetv2: Inverted residuals and linear bottlenecks." Proceedings of the IEEE conference on computer vision and pattern recognition. 2018.
[4] Mehta, Sachin, and Mohammad Rastegari. "Mobilevit: light-weight, general-purpose, and mobile-friendly vision transformer." arXiv preprint arXiv:2110.02178 (2021).