全文链接:http://tecdat.cn/?p=28519
作者:Yiyi Hu
近年来,共享经济成为社会服务业内的一股重要力量。作为共享经济的一个代表性行业,共享单车快速发展,成为继地铁、公交之后的第三大公共出行方式。但与此同时,它也面临着市场需求不平衡、车辆乱停乱放、车辆检修调度等问题。本项目则着眼于如何不影响市民出行效率的同时,对共享单车进行合理的批量维修工作的问题,利用CART决策树、随机森林以及Xgboost算法对共享单车借用数量进行等级分类,试图通过模型探究其影响因素并分析在何种条件下对共享单车进行批量维修为最优方案。
解决方案
任务/目标
通过机器学习分类模型探究共享单车借用数量的影响因素,并分析在何种条件下对共享单车进行批量维修为最优方案。
数据源准备
该数据集有三个数据来源,分别为交通局,天气数据,以及法定假期。
数据预处理及可视化
(一)时间:首先从“timestamp”列中提取了“month”和“hour”两列,试图分别从整体、季度、月份、小时四个方面,对共享单车借用总数进行箱图分析。
解决方案
任务/目标
通过机器学习分类模型探究共享单车借用数量的影响因素,并分析在何种条件下对共享单车进行批量维修为最优方案。
数据预处理及可视化
(一)时间:首先从“timestamp”列中提取了“month”和“hour”两列,试图分别从整体、季度、月份、小时四个方面,对共享单车借用总数进行箱图分析。
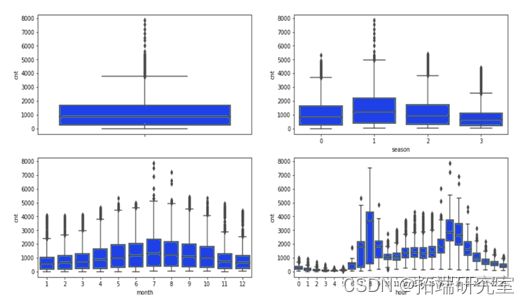
(二)天气:观察数据特征发现,其中“weather_code”列各类别分别为:1 =晴朗;大致清晰,但有一些值与雾霾/雾/雾斑/雾附近;2 =散云/一些云;3 =碎云/云层疏松;4 =多云;7 =雨/小雨阵雨/小雨;10 =雨与雷暴;26 =降雪;94 =冻雾。因此,本文对“weather_code”进行重新定义,将 1,2,3,4 类天气现象定义为宜骑车天气;7,10,26,94 类天气现象定义为不宜骑车天气。
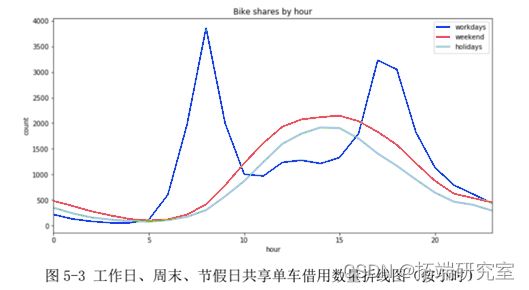
(三)共享单车借用数量:“节假日”与“双休日”中共享单车使用数量的分布较为相似,高峰期均在午后。对比发现,“工作日”中单车使用数量的高峰期在 7 点至 9 点,16 点到 19 点这两个时间段呈现为两个明显的波峰,这两个时间段往往是上班下班时间,人流量比较大,因而数据的呈现比较符合实际的规律。因此,绝对将“is_holiday”列与“is_weekend”列联合进行分组,合并为“is\_non\_workday”,分为工作组与非工作日组。
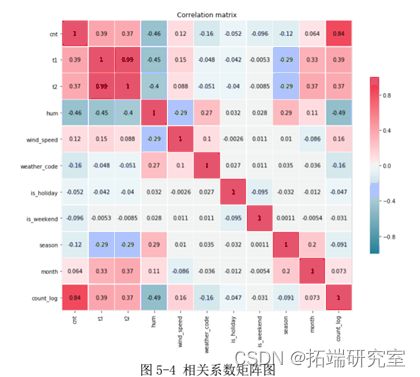
(四)温度:图 5-4 为各变量之间的相关系数矩阵,发现温度“t1”列与体感温度“t2”列之间存在较高的相关性,且天气温度数据更加客观,因此选择仅保留“t1”列。各个变量之间的均呈现中弱相关性。此外,各变量与因变量“count_log”列均存在一定的相关性,但相关强度不一。
(五)经观察“count_log”箱图发现,该数据仍存在着少量异常值。因此,为了提高结果的准确性,选择删去 16 个过低的数值,剩余 17398 组数据。
在进行预处理后,本文已经对共享单车中的变量进行了筛选与调整,保留了 hour,t1,is\_non\_workday,weather_code,wind_speed,hum,season 等 7 个特征变量。在正 式建立模型之前,对于因变量“count_log”进行等频分箱,将其分成了五类,命名为 category。当保证类别平衡,即每类数据的样本量接近,算法会有更好的效果。对于温度、湿度等连续性变量,为使得最后结果的准确性,并未对其进行分箱。
接下来,本文对所有的特征变量进行了归一化处理,为了归纳统一样本的统计分布性, 本文选取 75%的数据划分为训练集,25%的数据作为测试集。
建模
CART决策树:
CART 算法易于理解和实现,人们在通过解释后都有能力去理解决策树所表达的意义。 并且能够同时处理分类型与数值型属性且对缺失值不敏感。
随机森林:
使用随机森林模型在进行分类时,需要现在经过训练的决策树中输入测试样本,这棵决策树的分类便可以由各叶子节点的输出结果而确定;再根据所有决策树的分类结果,从而求得随机森林对测试样本的最终评价结果。
使用自助法随机地抽样得到决策树的输入样本和选取最佳的分割标准在决策树的节点上随机地选取特征进行分割是随机森林的两大优点,正是这些优势使得随机森林具备了良好的容忍噪声的能力,且使得决策树之间的相关性有所降低。随机森林中的决策树还具备了任意生长但不被修剪的特点,因此这些决策树的偏差较低,有利于提高评价的准确度。
Xgboost:
Xgboost 作为一种新型的集成学习方法,优点颇多。首先,他在代价函数里加入了正则化项,用于控制模型的复杂度,有效防止了过拟合。其次,Xgboost 支持并行处理,众所周知,决策树的学习最耗时的一个步骤是对特征的值进行排序,Xgboost 在训练之前预先对数据进行了排序,然后保存为 block 结构,后面的迭代中重复使用这个结构,大大减小了计算量。再次,Xgboost 算法灵活性高,它支持用户自定义目标函数和评估函数,只要保证目标函数二阶可导即可,并且对于特征值有缺失的样本,可以自动学习出它的分裂方向。最后,Xgboost 先从顶到底建立所有可以建立的子树,再从底到顶反向进行剪枝,这样不容易陷入局部最优解。
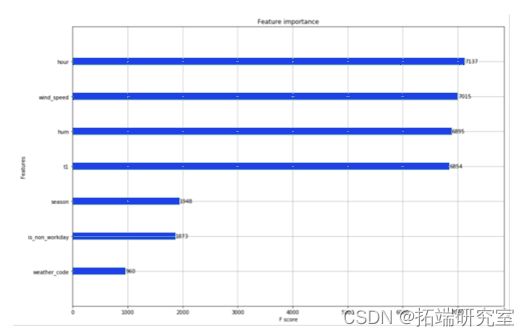
本文分别利用 CART 决策树、随机森林以及 Xgboost 算法对共享单车借用数量进行等级分类,并对三个方法进行精度测试,发现通过 Xgboost 算法分类效果最好,经过调参后,训练集模型精确度高达 0.92,测试集精确度为 0.83。分析分类结果以及各因素的重要性发现,时间、风速、湿度、温度四个因素对共享单车使用量存在较高的影响,因此维修部门可以选在凌晨阶段,或者风速较大、温度过低或过高的时期对共享单车进行合理的批量维修,避开市民用车高峰,保证市民出行效率以及用车安全。
关于作者

在此对Yiyi Hu对本文所作的贡献表示诚挚感谢,她毕业于上海财经大学,专长时间序列预测、回归分析、多元统计、数据清洗、处理及可视化、基础机器学习模型以及集成模型。

最受欢迎的见解
1.PYTHON用户流失数据挖掘:建立逻辑回归、XGBOOST、随机森林、决策树、支持向量机、朴素贝叶斯模型和KMEANS聚类用户画像
3.python中使用scikit-learn和pandas决策树
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用