Yolov5-5.0源码分享以及环境配置——Yolov5训练及测试教程(超详细含数据集制作,格式转换,数据集划分)
yolov5-5.0百度网盘连接
链接: https://pan.baidu.com/s/1Hd2KKBixuEWRv3jcH6Bcsw 提取码: g6xf 复制这段内容后打开百度网盘手机App,操作更方便哦
环境配置
测试环境:ubuntu18.04,显卡GTX1060台式机
1、进入Yolov5目录

2、使用conda创建一个虚拟环境
conda create -n yolov5 python=3.7

3、激活虚拟环境
conda activate yolov5
![]()
4、安装相关库环境(requirements.txt)

pip install -r requirements.txt
上面那个指令下载会比较慢,建议加上清华镜像,指令如下:
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple -r requirements.txt
这样速度就快很多

成功安装
5、数据集制作及格式转换格式划分
制作工具:labelimg。工具使用简单,不做介绍
百度网盘链接:https://pan.baidu.com/s/1kD4N4Ki-vuuzPCMm_-_GOg
提取码:xlky
制作生成的是xml格式的数据,将xml格式转换成yolov5使用的txt格式,代码如下:
import xml.etree.ElementTree as ET
import pickle
import os
from os import listdir, getcwd
from os.path import join
# 数据标签
classes = ['protect_wire','negative_feeder_insulator','wrist_brace','negative_feeder']
def convert(size, box):
dw = 1./(size[0])
dh = 1./(size[1])
x = (box[0] + box[1])/2.0 - 1
y = (box[2] + box[3])/2.0 - 1
w = box[1] - box[0]
h = box[3] - box[2]
x = x*dw
w = w*dw
y = y*dh
h = h*dh
if w>=1:
w=0.99
if h>=1:
h=0.99
return (x,y,w,h)
def convert_annotation(rootpath,xmlname):
xmlpath = rootpath + '/xml'
xmlfile = os.path.join(xmlpath,xmlname)
with open(xmlfile, "r", encoding='UTF-8') as in_file:
txtname = xmlname[:-4]+'.txt'
print(txtname)
txtpath = rootpath + '/labels'
if not os.path.exists(txtpath):
os.makedirs(txtpath)
txtfile = os.path.join(txtpath,txtname)
with open(txtfile, "w+" ,encoding='UTF-8') as out_file:
tree=ET.parse(in_file)
root = tree.getroot()
size = root.find('size')
w = int(size.find('width').text)
h = int(size.find('height').text)
out_file.truncate()
for obj in root.iter('object'):
difficult = obj.find('Difficult').text
cls = obj.find('name').text
if cls not in classes or int(difficult)==1:
continue
cls_id = classes.index(cls)
xmlbox = obj.find('bndbox')
b = (float(xmlbox.find('xmin').text), float(xmlbox.find('xmax').text), float(xmlbox.find('ymin').text), float(xmlbox.find('ymax').text))
bb = convert((w,h), b)
out_file.write(str(cls_id) + " " + " ".join([str(a) for a in bb]) + '\n')
if __name__ == "__main__":
rootpath='D:/desktop/merge'
xmlpath=rootpath+'/xml/'
list=os.listdir(xmlpath)
for i in range(0,len(list)) :
path = os.path.join(xmlpath,list[i])
if ('.xml' in path)or('.XML' in path):
convert_annotation(rootpath,list[i])
print('done', i)
else:
print('not xml file',i)
然后进行划分:训练集、验证集、测试集,比例为8:1:1。比例可改,参考代码:
import os
import shutil
root_path = "D:/desktop/merge/dataset/"
img_path = "D:/desktop/merge/protect_wire/images/"
txt_path = "D:/desktop/merge/labels/"
def train_test_move(txt_path,root_path,img_path):
files = os.listdir(txt_path)
l = len(files)
sets = ['train', 'valid', 'test']
k = 0
p = 0.8
for i in sets:
if not os.path.exists(root_path+i):
print(root_path+i)
os.mkdir(root_path+i)
os.mkdir(root_path+i+"/images")
os.mkdir(root_path+i+"/labels")
for file in files[round(l*k):round(l*p)]:
shutil.copy(txt_path+file,root_path+i+"/labels")
shutil.copy(img_path+file[:-3]+"jpg",root_path+i+"/images")
k = p
p += 0.1
train_test_move(txt_path,root_path,img_path)
6、Yolov5使用的数据集格式如下
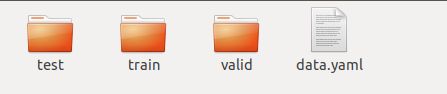 以train文件夹为例子,test、valid同train一样。
以train文件夹为例子,test、valid同train一样。
 images文件夹存放的是原图,labels文件夹存放的是标签文件。
images文件夹存放的是原图,labels文件夹存放的是标签文件。


7、训练
(1)数据集文件夹创建一个data.yaml,内容为:
 百度网盘链接:
百度网盘链接:
链接: https://pan.baidu.com/s/1Yxa2q8EXwUu8sjZuItDM2g 提取码: ivmg 复制这段内容后打开百度网盘手机App,操作更方便哦
前面两行指定数据集的绝对路径;…/是返回上级目录的意思
nc:代表类的个数
names:类名,以列表的形式存放
(2)修改训练参数yolov5/models/yolov5s.yaml
nc:与数据集nc保持一致

(3)训练代码
python train.py --img 640 --batch 16 --epochs 300 --data ../VOC/data.yaml --cfg models/yolov5s.yaml --weights ''
***常见错误:内存不足***RuntimeError: CUDA out of memory.
![]()
调小batch ,依据个人电脑配置。我调成8之后问题就解决了

至此训练环节结束。码字不易,动动发财的小手,一键三连如何??
8、测试代码及结果展示:此处未用自己的模型,因为在写的时候还没训练好,借用别的模型介绍。
python detect.py --weight weights/yolov5s.pt --source ../VOC/test/images
yolov5s.pt网盘连接:链接: https://pan.baidu.com/s/1rusS9hwEyLacbIBKRNCZfA 提取码: 3acn 复制这段内容后打开百度网盘手机App,操作更方便哦

