机器学习-决策树之回归树python实战(预测泰坦尼克号幸存情况)(三)
本文用通俗易懂的方式来讲解分类树中的回归树,并以“一维回归的图像绘制”和“泰坦尼克号幸存者预测”两个例子来说明该算法原理。
以下是本文大纲:
1 DecisionTreeRegressor
首先,我们来看看在sklearn中,这个库长什么样子吧:
如果你读过本博客的前两篇关于决策树的文章,你会发现
1.1 重要参数,属性及接口 criterion
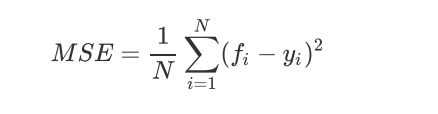
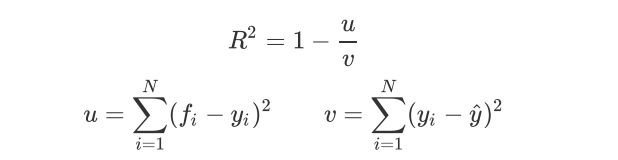
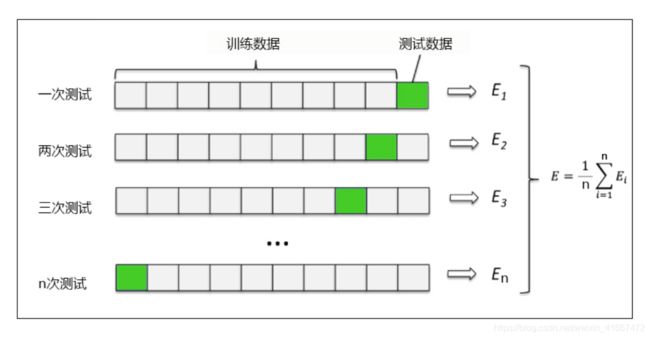
1.2 交叉验证
from sklearn.datasets import load_boston #我们导入波士顿的放假数据
from sklearn.model_selection import cross_val_score #导入交叉验证模块
from sklearn.tree import DecisionTreeRegressor #导入回归树模块接着我们来看看数据长什么样:
boston = load_boston()boston.data
boston.target
regressor = DecisionTreeRegressor(random_state=0)#实例化
cross_val_score(regressor, boston.data, boston.target, cv=10,scoring = "neg_mean_squared_error") #交叉验证cross_val_score的用法,这里将数据集分为十个部分。
2 实例:一维回归的图像绘制
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt然后我们开始造一个数据集:
rng = np.random.RandomState(1) #随机数种子
X = np.sort(5 * rng.rand(80,1), axis=0) #生成0~5之间随机的x取值,数据为80行1列(二维的),因为训练时候不允许有一维特征。sort是排序。
y = np.sin(X).ravel()#生成正弦曲线。ravel函数是将数据降成一维的。
y[::5] += 3 * (0.5 - rng.rand(16))#在正弦曲线上加噪声,每5个步长取一个数 ,共16个数,结果噪声就在3*(-0.5,0.5)=(-1.5,1.5)之间。这四行代码已经做了比较详细的注释,若不清楚,请百度一下每个函数的作用,做做实验就会懂的。
然后我们将造好的数据画出来看看:
plt.figure()
plt.scatter(X,y,s=20,edgecolor="black",c="darkorange",label="data")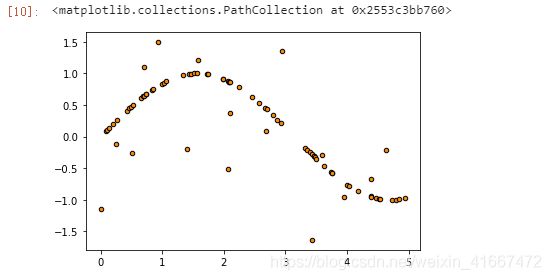
这里我们建立两个模型,目的是为了看不同拟合效果(max_depth不一样)能得到什么结果。
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor(max_depth=5)
regr_1.fit(X, y)
regr_2.fit(X, y)好了,现在模型已经训练好,现在我们得找一个数据来训练一下,看看模型的效果:
X_test = np.arange(0.0, 5.0, 0.01)[:, np.newaxis]#这里是生成0~5,步长为0.01的数列,后面[]的功能是增维
y_1 = regr_1.predict(X_test)#得到模型1的结果
y_2 = regr_2.predict(X_test)#得到模型2的结果我们将数据图、模型1的结果、模型2的结果画在一张图上:
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()
plt.show()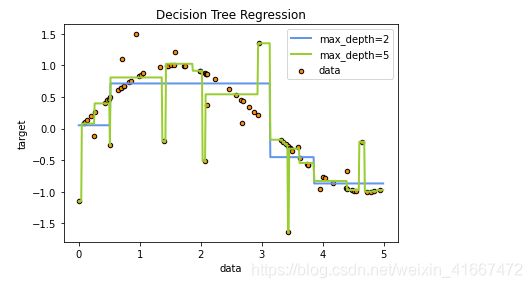
解释一下:我们可以很清晰的看到,当max_depth为2的时候,效果还算好,当max_depth为5的时候,模型会对数据有更强的拟合,但是结果却不如人意,结果画出来的图很夸张有没有。那就说明受噪声影响比较大。
3 实例:泰坦尼克号幸存者的预测
首先我们导入所需要的库:
import pandas as pd
from sklearn import tree
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt然后我们导入数据集,并看看数据集长什么样吧:
data = pd.read_csv(r"D:\学习笔记\毛维杨\data.csv",index_col= 0)
data
可以看到这是一个891行11列的数据集。
接着,我们看看数据信息。
data.info() 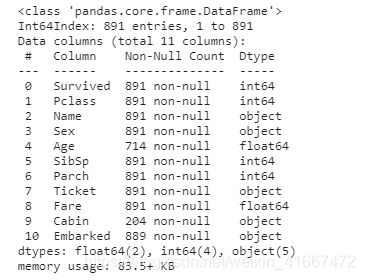
以上把数据集的详细信息都展示了出来。
有一个问题,要是这个数据集有100亿条呢,我们还要全部拿出来看看吗?
当然不用!
data.head(10)#默认为5,这里我们来看看前10行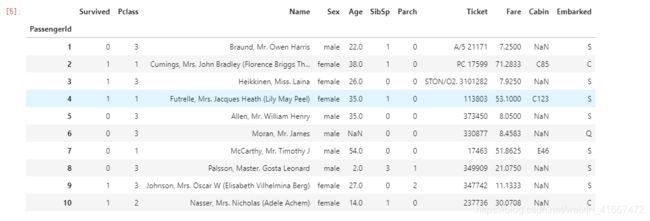
上面这个函数就能取出数据集中的前n行展示出来,默认为5.
拿到数据集了,首先当然是处理一下,取其精华去其糟粕!
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1) #删除缺失值过多的列,和观察判断来说和预测的y没有关系的列
data["Age"] = data["Age"].fillna(data["Age"].mean())#处理缺失值,对缺失值较多的列进行填补,有一些特征只确实一两个值,可以采取直接删除记录的方法
data = data.dropna()#将有缺失值的行删掉
#将分类变量转换为数值型变量
#astype能够将一个pandas对象转换为某种类型,和apply(int(x))不同,astype可以将文本类转换为数字,用这个方式可以很便捷地将二分类特征转换为0~1
data["Sex"] = (data["Sex"]== "male").astype("int") #将二分类变量转换为数值型变量0和1
#将三分类变量转换为数值型变量
labels = data["Embarked"].unique().tolist()#将Embarked属性的三个标签取出来(是一个数组),再用tolist函数将数组转化为列表。
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))#属性标签列表的索引替换掉文本
#查看处理后的数据集
data.head()(1)我们要做的是预测幸运者,那么有些属性和我们要得到的结果根本没啥关系,比如说票号,姓名,几等仓,这些和是否在灾难中能幸存关系不大,可以不要,第一行代码就是做这个事情的。inplace的意思是说删除完这些列后,覆盖原来没删除的表,默认为false。axis=1是说对列进行删除,为0的时候是对行进行删除。
(2)处理缺失值,有些特征它缺少一些数据,但不是缺失严重,且比较重要,我们可以进行填补,比如说本数据集的age属性,缺失200+个,但是在灾难中老人和孩子一般优先上救生艇,所以它对我们的实验很重要,我们不能直接删除,要进行填补。第二行就是用均值对age属性进行填补。当然填补还有很多方法。
(3)将有缺失值的行进行删除,第三行就是实现了这个功能
(4)文本数据我们不好处理,所以我们要将属性中的文本型数据转化为数值型数据,以上代码的后几行实现了这个功能,已经写了详细的注释。
我们来看看处理后的数据:
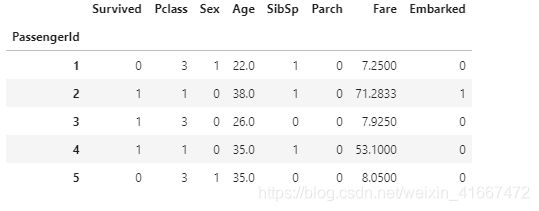
是不是更“漂亮”了!
下面开始建模:
X = data.iloc[:,data.columns != "Survived"] #取出所有的行,其中去掉属性“Survived”
y = data.iloc[:,data.columns == "Survived"] #取出所有的行,仅包含属性“Survived”
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3) #划分训练集和测试集
for i in [Xtrain, Xtest, Ytrain, Ytest]:#修正训练集和测试集的索引
i.index = range(i.shape[0])
#查看分好的训练集和测试集
Xtrain.head()
分完训练集和测试集后,我们的训练集和测试集的索引会变乱,所以我们要对其进行修正。
下面我们来进行建模:
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25,max_depth=i+1,criterion="entropy")
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
#这里为什么使用“entropy”?因为我们注意到,在最大深度=3的时候,模型拟合不足,在训练集和测试集上的表现接近,但却都不是非常理想,只能够达到83%左右,所以我们要使用entropy。
本文首先以max_depth为例来构建学习曲线,我们以max_depth取值为横轴,以得分score为纵轴画图,图中包含训练集和测试集两条曲线。
可以看到,当max_depth越来越大的时候,模型的过拟合程度越来约严重,其中最好的点是在3附近,通过实验可以知道,最大的得分是0.81778,这个分数依然不是那么理想。
那么我们要找出最合适的剪枝方案(也就是每个参数设置成什么最好),难道要我们像max_depth一样一个一个去画图观察?那样工作量巨大!
当然不是!
因为在剪纸这一步有很多可以调节的参数,如何寻找到一个最优的参数组合就成了一个问题,网格搜索方法(GridSearchCV)就解决了这个问题。
GridSearchCV,它存在的意义就是自动调参,只要把参数输进去,就能给出最优化的结果和参数。但是这个方法适合于小数据集,一旦数据的量级上去了,很难得出结果。
这个时候就是需要动脑筋了。数据量比较大的时候可以使用一个快速调优的方法——坐标下降。它其实是一种贪心算法:拿当前对模型影响最大的参数调优,直到最优化;
再拿下一个影响最大的参数调优,如此下去,直到所有的参数调整完毕。
这个方法的缺点就是可能会调到局部最优而不是全局最优,但是省时间省力,巨大的优势面前,还是试一试吧,后续可以再拿bagging再优化。
本文利用该方法对模型进行处理,其中cv值设为10,即做10次交叉验证:
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
parameters = {'splitter':('best','random'),'criterion':("gini","entropy"),"max_depth":[*range(1,10)],'min_samples_leaf':[*range(1,50,5)],'min_impurity_decrease':[*np.linspace(0,0.5,20)]}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
我们来看看最好的剪枝方案
GS.best_params_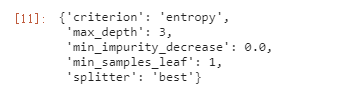
再根据最好的剪枝方案得到最好的得分情况
GS.best_score_![]()
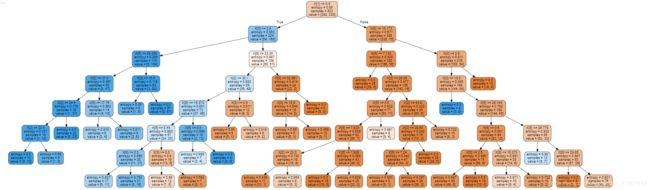
最后我们来画出决策树的图:
4 决策树的优缺点
5 附录
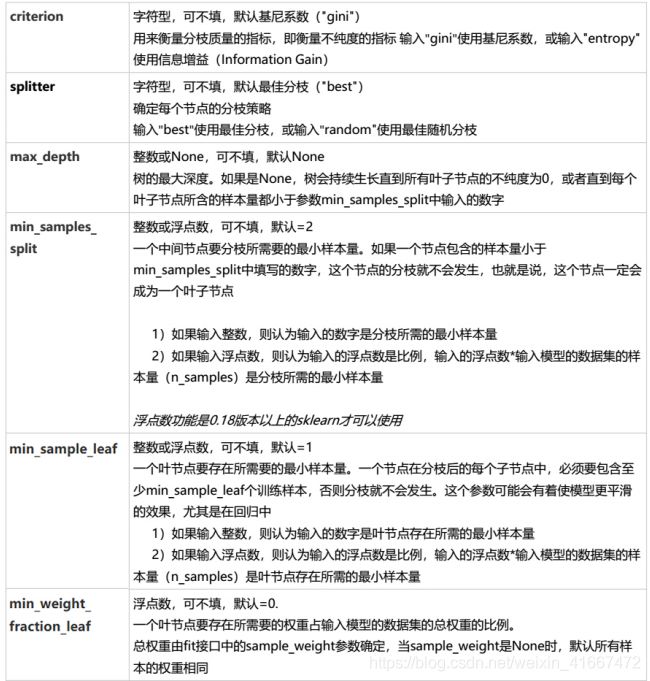
5.1 分类树参数列表



5.2 分类树属性列表
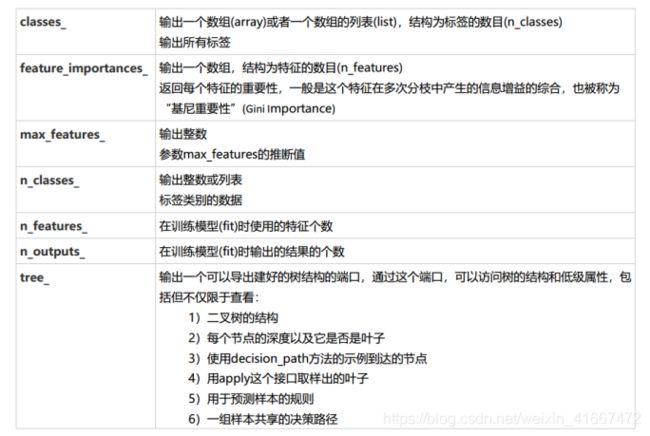
5.3 分类树接口列表

至此,关于决策树的全部内容整理完毕,接下来开始新的算法整理。
本文参考教程:菜菜的sk-learn课程
如有写的不合适,亦或是不精确的地方,望读者多包涵
如果大家对上述内容有任何不理解的地方,可以留言,和毛同学共同讨论,一起进步!
qq:1518887260
相关文章链接:
机器学习-万字长文介绍决策树之原理(一)
机器学习-决策树之分类树python实战(以红酒数据集为例)(二)
整理于2020年12月15日