PP-ShiTu: A Practical Lightweight Image Recognition System
最近看了一个新的分享,关于图像识别的,对于大规模图像搜索以及新物品频繁情况下表现良好。
- 论文: https://arxiv.org/abs/2111.00775
- 项目: https://github.com/PaddlePaddle/PaddleClas
Abstract
近年来,图像识别的应用发展迅速。在人脸识别、行人和车辆再识别、地标检索和产品识别等不同的领域,已经出现了大量的研究和技术。在本文中,提出了一种实用的轻量级图像识别系统PP-ShiTu,由以下3个模块、主体检测、特征提取和向量搜索等模块组成。引入了流行的策略,包括度量学习、深度散列、知识蒸馏和模型量化,以提高精度和推理速度。通过上述策略,PP-ShiTu在不同的场景下工作得很好,使用一组在混合数据集上训练的模型。在不同数据集和基准上的实验表明,该系统在图像识别领域具有广泛的有效性。上面所有提到的模型都是开源的,代码可以在GitHub存储库中找到。

1 Introduction
图像识别是计算机视觉中的一般任务。由于深度学习的快速改进和巨大的市场需求,图像识别已经迅速发展,并发展成几个子领域。许多应用程序使用类似的pipeline,如人脸识别、行人和车辆重新识别、地标识别、产品识别等。此外,在一个应用程序中工作的策略通常被证明对其他应用程序是有效的。例如,ArcMargin loss(Deng, 2019)。和triple loss(Wenetal 2016年)被提议用于人脸识别,这被证明有助于许多其他任务,如行人重新识别(Hermans, Beyer, Leibe 2017)和地标识别(Yokoo 2020)。
然而,研究人员总是关注一个或几个应用程序,因此,作为开源项目。当将策略迁移到另一个应用程序时,需要花费很多代价。有鉴于此,本文提出了PP-ShiTu图像识别系统来解决一个管道中的类似问题。图2展示了PP-ShiTu的框架。PP-ShiTu包含主体检测,即特征提取、向量搜索三个模块。pp-shitu的管道非常简单。当获取一个图像时,我们首先检测到一个或几个主体区域来找到图像的主要区域。然后,使用CNN模型从这些区域中提取特征。**特征是一个浮点向量或一个二进制向量。根据度量学习理论,特征意味着两个物体的相似性。两个特征之间的距离越短,原始的两个对象就越相似。**最后,使用向量搜索算法找到图库中最接近从图像中提取的特征的特征,并使用相应的标签作为识别结果。
除了构建一个通用的管道外,还在系统中引入了一些有效的策略。使用PP-Picodet和PP-LCNet的主干(Cui),PPLCNet采用度量学习策略,如ArcMargin 作为特征提取模型。知识蒸馏策略在该系统中得到了广泛的应用。使用经过SSLD蒸馏策略训练的骨干(Cui), 还使用SSLD来训练特征提取模型。模型量化(Choi),帮助我们减少模型的存储大小。 deepHash(Wu 2019)策略压缩特征,加速向量搜索。消融实验表明了上述策略的有效性。
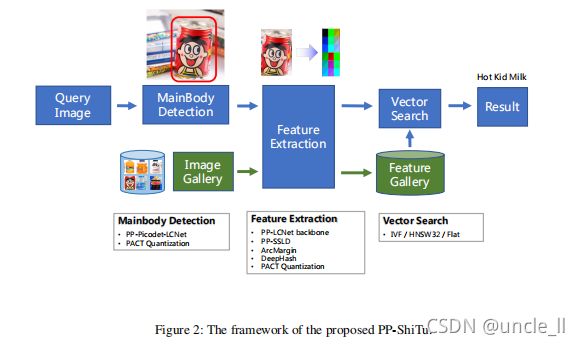
更重要的是,我们训练了主体检测模型和通过混合多个数据集在一起,建立了具有混合数据集的特征提取模型。PP-ShiTu在不同的场景下工作良好,并在许多数据集和基准测试上获得了有竞争力的结果。
论文组织如下:
- 在第2节中,将详细介绍PP-ShiTu的模块和策略的细节
- 在第3节中,提出并讨论了消融实验的结果
- 在第4节中总结这些结论
2 Modules and Strategies
2.1 主体检测
主体检测技术是一种应用广泛的检测技术,它是指对图像中的所有前景对象进行检测。主体检测是整个识别任务的第一步,可以有效地提高识别精度。
目标检测方法有多种多样的,如常用的两阶段检测器(FasterRCNN系列等),单阶段探测器(YOLO、SSD等),无锚探测器(PP-PicoDet、FCOS等)等等。Paddle Detection为服务器端场景开发了PP-YOLOv2模型和移动端场景(CPU和移动)的PP-PicoDet模型,这两种模型在各自的场景中都是SOTA。通过结合许多优化技巧,如下降块(Ghiasi、Lin,Le2018),MatrixNMS(Wang 2020年),IoU损失(雷扎托菲吉等)。以此类推,PP-YOLOv2在准确性和效率上都超过了YOLOv5。PP-PicoDet以PP-LCNet为其骨干,并结合了许多其他的检测器训练技巧,如PAN FPN(Liu 2018),csp-net(Wang 2020),SimOTA(Ge 2021),最终成为第一个在coco数据集上mAP(0.5:0.95)超过0.30+以上的目标检测器,模型参数为1m,输入图像大小为416.
一个轻量级的图像识别系统需要一个轻量级的主主体检测模型。因此,PP-ShiTu中的主体检测使用的是PP-PicoDet。
**Lightweight CPU Network (PP-LCNet)。**在CPU时,通过比较不同的网络推理获得了一个BaseNet,并添加了不同的方法来进一步提高该网络的准确性,得到了PP-LCNet,它提供了一种支持mkldnn的更快、更准确的识别算法。整个网络的结构如图3所示。下面,简要介绍了该网络的改进情况。有关更多细节和消融实验,请参考原论文(Cui 2021a)
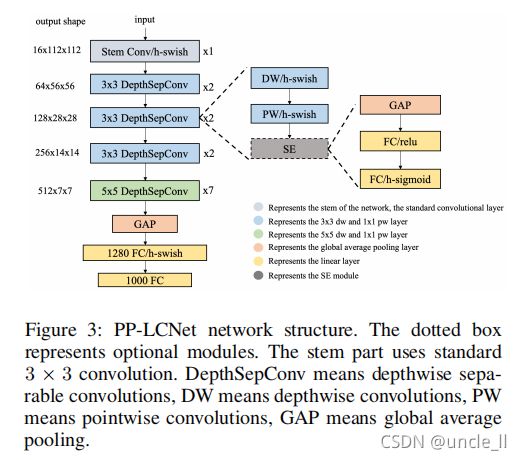
Better activation function。为了提高BaseNet的拟合能力,将网络中的激活函数替换为原ReLU中的H-Swish函数,可以显著提高精度,但仅略微提高推理时间。
SE modules at appropriate positions。SE(Hu、Shen,Sun2018)模块自被提出以来已被大量网络使用。这是一个很好的方式来加权网络通道,以获得更好的功能,并被用于许多轻量级网络,如MobileNetV3(Howard 2019)。但是,在Intelcpu上,SE模块增加了推理时间,因此不能将其用于整个网络。事实上,通过大量的实验,发现SE模块越靠近网络的尾部,效果就越有效。所以只将SE模块添加到网络尾部的块中,从而得到更好的精度-速度平衡。SE模块中两层的激活函数为ReLU和H-Sigmoid。
Larger convolution kernels。卷积核的大小往往会影响网络的最终性能。在mixnet(Tan,Le2019)中,作者分析了不同大小的卷积核对网络性能的影响,最终在网络的同一层中混合了不同大小的卷积核。然而,这种混合物减慢了模型的推理速度,因此试图增加卷积核的大小,但最小化推理时间的增加。最后,将网络尾部的卷积核的大小设为5×5。
Larger dimensional 1 × 1 conv layer after GAP。在PPLCNet中,GAP后的网络输出维度较小,直接连接最终的分类层将失去特征的组合。为了使网络具有更强的拟合能力,在GAP层和最终分类层之间插入了一个1280维尺寸的1x1conv,这为模型提供了更多的存储空间,而不会增加推理时间。
通过这四个变化,本文提出的模型在ImageNet上表现良好,表5列出了与Intelcpu上的其他轻量级模型相比的指标。
PP-PicoDet是由paddleDetection开发的一系列新的目标检测模型。
具体来说,对于骨干模型,利用了上述的PPLCNet,这有助于提高检测器的推理速度和mAP。对于颈部,结合了CSP-Net(Wang 2020a)与PANFPN(Liu 2018)开发一种新的CSP-PANFPN结构,有助于提高特征图提取能力。**SimOTA(Ge 采用了2021年),并改进了GFocal损失(Li)。**在网络训练过程中使用了该损失函数。更重要的是,一些经验上的改进也用于PP-PicoDet。例如,在FPN中使用了具有5x5内核的深度卷积,而不是3x3,因为其可以提高mAP0.5%,并且几乎对推理速度没有伤害。更多的细节可以在PaddleDection上看到。
对于主体检测任务,所有对象都被视为前景,因此在标签列表中只有一个类被命名为前景。
2.2 Feature Extraction
图像识别的主要问题是如何从模型中提取更好的特征。因此,特征提取的能力直接影响了图像识别的性能。在特征提取的训练阶段,使用度量学习方法来学习图像的特征。下面将简要描述度量学习。
Additive Angular Margin Loss (ArcMargin loss)。度量学习试图将数据映射到嵌入空间,在那里相似的数据紧密在一起,不同的数据相距很远。**在度量学习中,特征的质量取决于损失、骨干网络、数据的质量和数量以及训练策略。**损失是度量性学习中最重要的组成部分。度量学习的损失分为基于损失分类和基于损失对两种类型。近年来,由于基于分类的损失的改进版本更加稳健,这种类型的损失越来越多地被使用。在PPShiTu中,使用ArcMargin Loss(Deng 2019年),这是基于Softmax的改进。公式中显示了弧度的损失,该损失使角空间中的分类限度最大化,从而更好地提取和组织特征。

其中, θ j θ_j θj是权重和特征之间的夹角。批处理大小和类别数量分别为N和n。M是目标角 θ y i θ_{yi} θyi上的角边距惩罚,s是特征标度。
Unified-Deep Mutual Learning (U-DML)。深度相互学习(Zhang 2017)是一种两个学生网络相互学习的方法,且其知识蒸馏不需要一个更大的具有预先训练过的权重的教师网络。在DML中,对于图像分类任务,损失函数包含两部分:
- 学生网络的输出与真值之间的损失函数
- 学生网络输出软标签之间的kullback-leibler散度(KL-Div)损失
在OverHaul的工作中(Heo 2019),其中使用学生网络和教师网络之间的特征图距离进行蒸馏过程。对学生网络特征图进行变换,以保持特征图的对齐性。
为了避免过于耗时的教师模型训练过程,本文在DML的基础上提出了U-DML,即在蒸馏过程中也对特征图进行监督。图4显示了U-DML的框架。
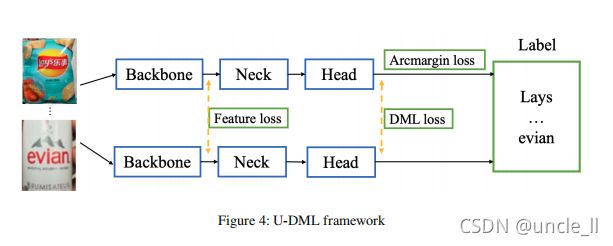
蒸馏过程有两个网络:学生网络和教师网络。它们具有完全相同的网络结构,具有不同的初始化权重。目标是对于相同的输入图像,两个网络可以得到相同的输出,不仅对预测结果,而且也对于特征图。
总损失函数包括三部分:
- 加性角度间隔损失函数(Arcmargin loss) 由于这两个网络的颈部和头部都是从头开始训练的,因此弧度损失可用于网络的收敛;
- DML损失。预计两个网络的最终输出分布相同,因此需要DML损失来确保两个网络之间分布的一致性;
- 特性损失。两个网络的结构相同,因此它们的特征图应该相同,可以利用特征损失来约束两个网络的中间特征图距离。
加性角度间隔损失函数:
L o s s a r c = A r c m a r g i n ( S h o u t , g t ) + A r c m a r g i n ( T h o u t , g t ) Lossarc = Arcmargin(S_{hout}, gt) + Arcmargin(T_{hout}, gt) Lossarc=Arcmargin(Shout,gt)+Arcmargin(Thout,gt)
其中 s h o u t s_{hout} shout表示学生网络的头部输出, T h o u t T_{hout} Thout表示教师网络的头部输出。 g t gt gt提供输入图像的组真值标签。
DML损失。在DML中,每个子网的参数分别进行更新。在这里,为了简化训练过程,计算了两个子网之间的KL散度损失,并同时更新了所有参数。DML损失如下:
L o s s d m l = K L ( S p o u t ∣ ∣ T p o u t ) + K L ( T p o u t ∣ ∣ S p o u t ) 2 Lossdml=\frac{KL(S_{pout}||T_{pout})+KL(T_{pout}||S_{pout})}2 Lossdml=2KL(Spout∣∣Tpout)+KL(Tpout∣∣Spout)
其中 K L ( p ∣ ∣ q ) KL(p||q) KL(p∣∣q)表示p和q的KL散度。 S p o u t S_{pout} Spout和 T p o u t T_{pout} Tpout的计算方法如下:
S p o u t = S o f t m a x ( S h o u t ) S_{pout}=Softmax(S_{hout}) Spout=Softmax(Shout)
T p o u t = S o f t m a x ( T h o u t ) T_{pout}=Softmax(T_{hout}) Tpout=Softmax(Thout)
特征损失。在训练过程中,希望学生网络的骨干输出与教师网络的骨干输出相同。因此,与Overhual类似,在蒸馏过程中采用了特征损失。该损失的计算方法如下:
L o s s f e a t = L 2 ( S b o u t , T b o u t ) Lossfeat = L2(S_{bout}, T_{bout}) Lossfeat=L2(Sbout,Tbout)
其中 S b o u t S_{bout} Sbout为学生网络骨干输出, T b o u t T_{bout} Tbout为教师网络骨干输出。这里使用了均方误差损失。需要注意的是,对于特征损失,不需要进行特征图转换,因为用于计算损失的两个特征图完全相同。
最后,U-DML训练过程的总损失如下所示:
L o s s t o t a l = L o s s a r c + L o s s d m l + L o s s f e a t Loss_{total}=Loss_{arc}+Loss_{dml}+Loss_{feat} Losstotal=Lossarc+Lossdml+Lossfeat
DeepHash。在实际应用中,大规模的检索图像和视频特征数据库不仅会消耗巨大的存储空间,而且会导致检索时间长,这在某些应用场景中是不可接受的。此外,移动设备上的存储空间非常有限,这给海量功能存储带来了进一步的挑战。考虑到这一点,我们在度量学习的基础上整合了 DeepHash (Luo 2020)功能。可以帮助PP-Shitu减少存储和加快检索。
**DeepHash研究使用深度神经网络如何获得代表性二元特征,使用比特存储二进制特征,并采用汉明距离测量两个特征向量之间的距离。**具体来说,有三种最常见的DeepHash算法:
- DLBHC(Lin 2015)
- LCDSH(Cao 2017)
- DSHSD(Wu 2019b)。
在PP-ShiTu中,采用了优化后的DSHSD(Wu 2019b)算法得到实用的二进制特征。与实值模型相比,检索精度可能略有下降,但图库特征的存储空间可以减少32倍。并且,当搜索库的大小大于10万时,检索速度可提高5倍以上。
2.3 Vector Search
为了在多个操作系统上运行,包括Linux、Windows和MacOS,我们使用Faiss作为向量搜索模块,这是一个用于高效相似性搜索的库,并支持在任何大小的向量集中搜索的算法,最多不超过RAM的向量。
在PP-ShiTu中,选择了三种算法:
- HNSW32(Malkov,ashunin 2018)
- IVF(Babenko, Lempisky 2012)
- FLAT
以满足不同场景的需求。值得注意的是,在向量搜索之前,需要建立一个特性库。特征库由从标记图像中提取的特征组成。在PP-ShiTu管道中,通过相似性搜索,从特征库中获得查询的标签。
3 Experiments
3.1 Experimental Setup
数据集。为不同的场景使用了大量的公共数据集来训练模型,具体介绍如下。
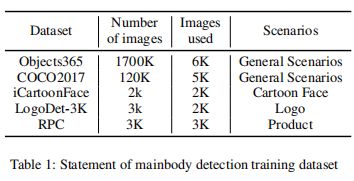
主体检测。在主体检测训练过程中,使用了5个公共数据集:
- Object365(Shao 2019)
- COCO2017(Lin 2014)
- iCartoonFace(Zheng 2020)
- LogoDet-3k(Wang 2020b)
- RPC(Wei 2019)
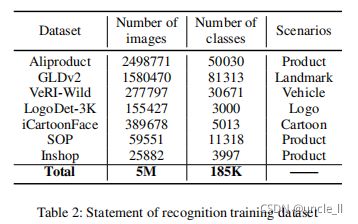
识别模型。使用7个公共数据集,包括 - Aliproduct(Cheng 2020)
- GLDv2(Weyand 2020)
- veri-wild(Lou 2019)
- LogoDet-3K(Wang 2020b)
- iCartoonFace(Zheng 2020)
- SOP(Song 2016)
- Inshop(Liu 2016)。
这些数据集也用于一般训练、模型蒸馏和深度散列。
测试集。为了评估PP-ShiTu的速度,发布了一个由查询图像集和特征库组成的测试集。从互联网上收集了200张图像作为查询集。查询数据集可以在GitHub存储库中找到。对于图库,使用了10k的商品(Bai 2020)和从互联网上下载的一些常见产品,并建立带有图片库的特征库。查询集中的每个图像都包含至少一个图库中的对象。图5显示了测试集中的图像示例。

实现细节。下面简要描述实现细节,这对最终系统的结果至关重要。
- 主体检测:对于主体检测模型,使用PP-PicoDet架构作为主体检测架构。为了提高主干的特征提取能力,使用PP-LCNet-2.5x作为检测器骨干,使用SSLD蒸馏法对PP-LCNet-2.5x的预训练权重进行训练(Cui)。主体检测的Epoch设置为100,由于GPU内存的限制,批量大小和学习率减少到
PaddleDetection检测中提供的标准配置的一半。 - 通用识别:对于通用识别,使用上面提到的所有7个数据集来训练PP-LCNet-2.5x 100个Epoch。对数据进行数据增强,随机裁剪到224×224像素和随机水平翻转。优化器是使用的SGD,动量设置为0.9,minBatch设置为2048。权重衰减被设置为1e-5,初始学习率设置为0.1。在Arcmargin Loss中,将比例设置为30,边际设置为0.2。为了进一步改进小数据集中的指标,将LogoDet、Inshop和VeRI-Wild的采样率提高了4倍。U-DML蒸馏训练的超参数除损失函数外,与通用识别训练的超参数相同。在评估阶段,使用每个单一的数据集进行评估,我们使用的度量是recall@1。在DSHSD损失中,对冲损失的权重设置为0.05,边距设置为1024(是特征嵌入大小的两倍)。
3.2 Mainbody Detection Result
表3显示了5个公共数据集的mAP结果。PPYOLO是我们在上一个版本中提供的主体检测模型,建议在服务器端使用。PPPicoDet在CPU延迟上的速度是PP-YOLO的14倍,而mAP仅略有降低(-2.4%),为了进一步减小模型尺寸,使用PACT对PP-PicoDet模型进行量化,最终模型尺寸减少到6.9M,适合于移动部署。

3.3 General Recognition Result
表4显示了ResNet50vd和PP-LCNet-2.5x在不同数据集上的召回率。其中,ResNet50vd是在各自的数据集上进行训练的。PP-LCNet-2.5x在整个合并后的数据集上进行训练。从表中可以看出,**我们的训练策略允许轻量级模型接近甚至超过ResNet50vd的精度。**此外,因为识别模型是在大量不同类型的数据,可以应用于不同的场景。

3.4 Ablation study
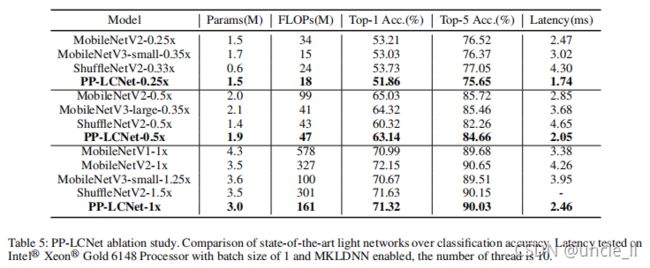
Ablation study for PP-LCNet 为了测试模型的泛化能力,在整个模型设计过程中使用了ImageNet-1k等具有挑战性的数据集。表5显示了PPLCNet与其他有竞争的轻量级模型的精度-速度比较。可以看出,PP-LCNet在速度和准确性方面都具有显著的优势,即使与MobileNetV3等非常具有竞争力的网络相比也是如此。
Ablation study for U-DML。 基于一般的PPLCNet-2.5x识别模型,进行了一些实验。训练策略与基本PP-LCNet-2.5x识别模型训练过程基本相同,只是采用了精馏损失。表7给出了不同方法的一些结果。6个DML数据集的模型召回率平均提高了0.5%,使用U-DML后,模型召回率平均提高了0.7%。由于该模型是使用知识蒸馏训练过程生成的,因此在推理过程中不需要任何额外的时间成本。
值得注意的是,没有微调模型训练过程的任何超参数,如loss rate。更重要的是,与标准训练过程(最终训练损失为2.64)相比,蒸馏模型泛化更好,需要更长的时间收敛(学生的最终训练损失为2.75),这与Beyeretal的结论一致 )。我们相信,随着Epoch的增加,蒸馏模型可以表现得更好。

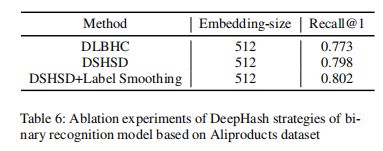
Ablation study for DeepHash,在DSHSD算法的基础上,结合其他DeepHash方法进行了一些实验。表6显示了基于MobileNetv3的不同策略的一些结果。可以看出,通过标签平滑,可以进一步提高二进制特征的表示能力。
3.5 Inference time latency on test set
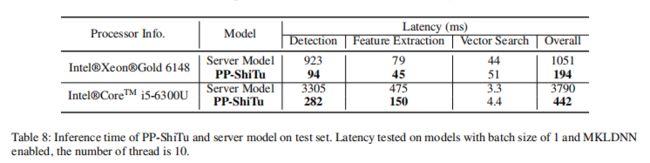
在测试集上比较了PP-ShiTu和服务器模型的推理速度,该模型之前在PaddleClas上发布,并使用ResNet50骨干进行检测和特征提取。两种模型的f1分数均为0.3306。表8显示了在CPU和GPU服务器上测试的两种模型的延迟时间。
4 Conclusions
本文提出了一种实用的轻量级图像识别系统PP-ShiTu。介绍了一个通用的管道和实际的策略,包括PP-PicoDet,UDML,Arcmargin Loss 和DeepHash。实验表明,PP-ShiTu在不同的任务和数据集上效果很好。并提供了相应的消融实验结果。
参考文献
- Babenko, A.; and Lempitsky, V. 2012. The inverted multiindex. In 2012 IEEE Conference on Computer Vision and Pattern Recognition, 3069–3076. doi:10.1109/CVPR.2012. 6248038
- Bai, Y.; Chen, Y.; Yu, W.; Wang, L.; and Zhang, W. 2020. Products-10k: A large-scale product recognition dataset. arXiv preprint arXiv:2008.10545 .
- Beyer, L.; Zhai, X.; Royer, A.; Markeeva, L.; Anil, R.; and Kolesnikov, A. 2021. Knowledge distillation: A good teacher is patient and consistent. arXiv preprint arXiv:2106.05237
- Cao, Z.; Long, M.; Wang, J.; and Yu, P. S. 2017. HashNet: Deep Learning to Hash by Continuation. IEEE Computer Society
- Cheng, L.; Zhou, X.; Zhao, L.; Li, D.; Shang, H.; Zheng, Y.; Pan, P.; and Xu, Y. 2020. Weakly Supervised Learning with Side Information for Noisy Labeled Images.
- Choi, J.; Wang, Z.; Venkataramani, S.; Chuang, P. I.-J.; Srinivasan, V.; and Gopalakrishnan, K. 2018. Pact: Parameterized clipping activation for quantized neural networks. arXiv preprint arXiv:1805.06085
- Cui, C.; Gao, T.; Wei, S.; Du, Y.; Guo, R.; Dong, S.; Lu, B.; Zhou, Y.; Lv, X.; Liu, Q.; Hu, X.; Yu, D.; and Ma, Y. 2021a. PP-LCNet: A Lightweight CPU Convolutional Neural Network.
- Cui, C.; Guo, R.; Du, Y.; He, D.; Li, F.; Wu, Z.; Liu, Q.; Wen, S.; Huang, J.; Hu, X.; Yu, D.; Ding, E.; and Ma, Y. 2021b. Beyond Self-Supervision: A Simple Yet Effective Network Distillation Alternative to Improve Backbones.
- Deng, J.; Guo, J.; Xue, N.; and Zafeiriou, S. 2019. Arcface: Additive angular margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 4690–4699.
- Ge, Z.; Liu, S.; Wang, F.; Li, Z.; and Sun, J. 2021. Yolox: Exceeding yolo series in 2021. arXiv preprint arXiv:2107.08430
- Ghiasi, G.; Lin, T.-Y.; and Le, Q. V. 2018. Dropblock: A regularization method for convolutional networks. arXiv preprint arXiv:1810.12890
- Heo, B.; Kim, J.; Yun, S.; Park, H.; Kwak, N.; and Choi, J. Y. 2019. A Comprehensive Overhaul of Feature Distillation. CoRR abs/1904.01866. URL http://arxiv.org/abs/1904. 01866.
- Hermans, A.; Beyer, L.; and Leibe, B. 2017. In defense of the triplet loss for person re-identification. arXiv preprint arXiv:1703.07737
- Howard, A.; Sandler, M.; Chu, G.; Chen, L.-C.; Chen, B.; Tan, M.; Wang, W.; Zhu, Y.; Pang, R.; Vasudevan, V.; Le, Q. V.; and Adam, H. 2019. Searching for MobileNetV3. In Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV).
- Hu, J.; Shen, L.; and Sun, G. 2018. Squeeze-and-Excitation Networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Li, X.; Wang, W.; Wu, L.; Chen, S.; Hu, X.; Li, J.; Tang, J.; and Yang, J. 2020. Generalized focal loss: Learning qualified and distributed bounding boxes for dense object detection. arXiv preprint arXiv:2006.04388
- Lin, K.; Yang, H. F.; Hsiao, J. H.; and Chen, C. S. 2015. Deep learning of binary hash codes for fast image retrieval. In IEEE Conference on Computer Vision and Pattern Recognition Workshops
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll´ar, P.; and Zitnick, C. L. 2014. Microsoft coco: Common objects in context. In European conference on computer vision, 740–755. Springer.
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; and Jia, J. 2018. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on computer vision and pattern recognition, 8759–8768
- Liu, Z.; Luo, P.; Qiu, S.; Wang, X.; and Tang, X. 2016. DeepFashion: Powering Robust Clothes Recognition and Retrieval with Rich Annotations. In Proceedings of IEEE Conference on Computer Vision and Pattern Recognition (CVPR).
- Lou, Y.; Bai, Y.; Liu, J.; Wang, S.; and Duan, L.-Y. 2019. VERI-Wild: A Large Dataset and a New Method for Vehicle Re-Identification in the Wild. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, 3235–3243.
- Luo, X.; Chen, C.; Zhong, H.; Zhang, H.; and Hua, X. 2020. A Survey on Deep Hashing Methods
- Malkov, Y. A.; and Yashunin, D. A. 2018. Efficient and robust approximate nearest neighbor search using Hierarchical Navigable Small World graphs.
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; and Savarese, S. 2019. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 658–666
- Shao, S.; Li, Z.; Zhang, T.; Peng, C.; Yu, G.; Zhang, X.; Li, J.; and Sun, J. 2019. Objects365: A large-scale, highquality dataset for object detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, 8430–8439.
- Song, H. O.; Xiang, Y.; Jegelka, S.; and Savarese, S. 2016. Deep Metric Learning via Lifted Structured Feature Embedding. In Computer Vision and Pattern Recognition (CVPR).
- Tan, M.; and Le, Q. V. 2019. MixConv: Mixed Depthwise Convolutional Kernels
- Wang, C.-Y.; Liao, H.-Y. M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; and Yeh, I.-H. 2020a. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition workshops, 390–391.
- Wang, J.; Min, W.; Hou, S.; Ma, S.; Zheng, Y.; and Jiang, S. 2020b. LogoDet-3K: A Large-Scale Image Dataset for Logo Detection.
- Wang, X.; Zhang, R.; Kong, T.; Li, L.; and Shen, C. 2020c. Solov2: Dynamic, faster and stronger. arXiv e-prints arXiv–2003.
- Wei, X.-S.; Cui, Q.; Yang, L.; Wang, P.; and Liu, L. 2019. RPC: A large-scale retail product checkout dataset. arXiv preprint arXiv:1901.07249 .
- Wen, Y.; Zhang, K.; Li, Z.; and Qiao, Y. 2016. A discriminative feature learning approach for deep face recognition. In European conference on computer vision, 499–515. Springer
- Weyand, T.; Araujo, A.; Cao, B.; and Sim, J. 2020. Google Landmarks Dataset v2 – A Large-Scale Benchmark for Instance-Level Recognition and Retrieval.
- Wu, L.; Ling, H.; Li, P.; Chen, J.; Fang, Y.; and Zhou, F. 2019a. Deep supervised hashing based on stable distribution. IEEE Access 7: 36489–36499.
- Wu, L.; Ling, H.; Li, P.; Chen, J.; and Zou, F. 2019b. Deep Supervised Hashing Based on Stable Distribution. IEEE Access 7(1): 36489–36499.
- Yokoo, S.; Ozaki, K.; Simo-Serra, E.; and Iizuka, S. 2020. Two-stage discriminative re-ranking for large-scale landmark retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, 1012–1013.
- Zhang, Y.; Xiang, T.; Hospedales, T. M.; and Lu, H. 2017. Deep Mutual Learning. CoRR abs/1706.00384. URL http: //arxiv.org/abs/1706.00384. 2.2
- Zheng, Y.; Zhao, Y.; Ren, M.; Yan, H.; Lu, X.; Liu, J.; and Li, J. 2020. Cartoon Face Recognition: A Benchmark Dataset. In Proceedings of the 28th ACM International Conference on Multimedia, 2264–2272.
附加资源
- Deep Mutual Learning
- https://zhuanlan.zhihu.com/p/76541084