Rethinking Atrous Convolution for Semantic Image Segmentation论文解
Rethinking Atrous Convolution for Semantic Image Segmentation
Abstract
在本文中,我们重温一下Atrous Convolution的妙用,Atrous Convolution能在调整滤波器的感受野的的同时,解决DCNNs造成的分辨率降低的问题。同时,为了解决图像语义分割的多尺度问题,设计了很多模型,包括并行或者串行的使用不同的rate的Atrous Convolution。更进一步的提出了ASPP。接下来会详细的说明实现的具体的细节和训练过程,我们的Deeplabv3在没有Dense crf的后期处理的条件下取得了非常不错的成绩,达到了state-of-art。
1. Introduction
对使用DCNNs进行图片语义分割的任务来说,我们认为主要有两大挑战,第一是由DCNNs中的下采样(如pooling,convolution stride等)造成的特征图分辨率降低,这种局部的不变性会对密集的预测任务造成干扰,因为丢失了很多空间信息。为了解决这一问题,提出了Atrous Convolution,也称为Dilated convolution,被证明对图片语义分割的任务很有效。通过使用Atrous Convolution,允许我们使用在ImageNet 上预训练好的模型来提取更加密集的特征图,也就是空间分辨率更高的特征图。
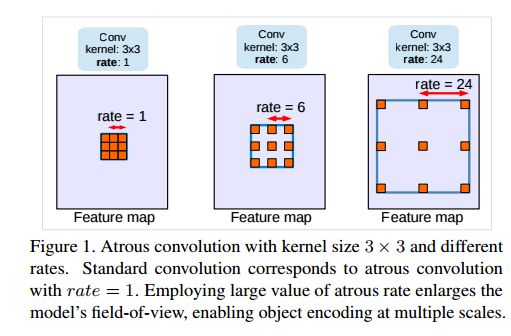
`Atrous Convolution`示意图
第二个则是物体存在的多尺度问题,主要有4种策略来解决这个问题。
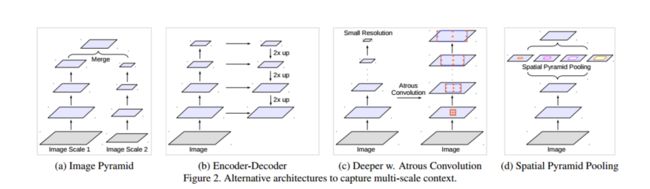
如上图所示,第一种办法是对不同的sacle的image进行并行的处理,再融合在一起。第二办法是使用编码和解码的对称结构,利用来自编码器部分的多尺度特征并从解码器部分恢复空间分辨率。第三种办法是在原始的网络上级联一些模块,用以捕获更多的信息。第四则是大名鼎鼎的SPP的使用了。
在级联模块和SPP的框架下,我们使用Atrous Convolution来增大滤波器的感受野去融合多尺度的语境信息。特别的是,我们提出的网络由不同rate的Atrous Convolution,BN层等组成。我们在并联或者串联的模块上做实验,发现一个重要的实际问题,就是当使用3×3的卷积核(Atrous Convolution的rate很大)时,由于图片边界的影响并不能捕获远程信息,有效简单地退化为1×1卷积,并提出将图像级特征纳入ASPP模块。此外,我们详细介绍实施细节,分享训练模型的经验,包括一个简单而有效的引导方法,用于处理稀有和精细注释的对象。最后再提出模型Deeplabv3,在PASCAL VOC 2012的test set上的mIOU取得了85.7%的成绩(没有Dense crf的后期处理的条件下)。
2. Related Work
Image pyramid
Encoder-decoder
Context module
Spatial pyramid pooling
具体的请看原paper吧
3. Methods
在本节中,我们将回顾如何应用Atrous Convolution来提取密集特征图用于语义分割。然后,我们讨论使用级联或并联的Atrous Convolution模块。
3.1. Atrous Convolution for Dense Feature Extraction
前面还一堆已经讲过的,就不赘述了。如下,一个二维的信号的Atrous Convolution的输出表达式
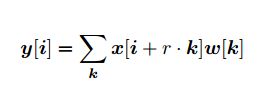
i是输出y中的位置,w是滤波器,x是输入,r是`Atrous Convolution`的rate
rate的具体含义可见上面的Atrous Convolution示意图。
再提出一个概念output_stride,个人认为可以简要的理解为输出的特征图是输入的多少分之一。如output_stride=32时,输入即为输出的32倍,而这也是一般的image classification任务常用的倍率(在全连接层或者全局最大/平均池化层之前的输出)。因此为了得到密集的特征图就应该减小output_stride,我们把下采样的Convolution全部换成了Atrous Convolution(rate=2),可参考这里。
3.2. Going Deeper with Atrous Convolution
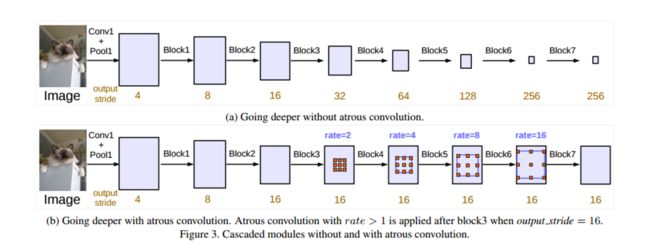
如上图,在级联模型中(类似于原始的ResNet),每个Block都是几个卷积层的叠加,使用了Atrous Convolution比没有的 能够获取更密集的特征图,这正是其优势所在之处。
3.2.1 Multigrid

这个比较有意思了,final atrous rate = Multi Grid * corresponding rate.(每个Block有三个卷积层)
3.3. Atrous Spatial Pyramid Pooling(ASPP)
这是deeplab中关于ASPP的描述,如下图
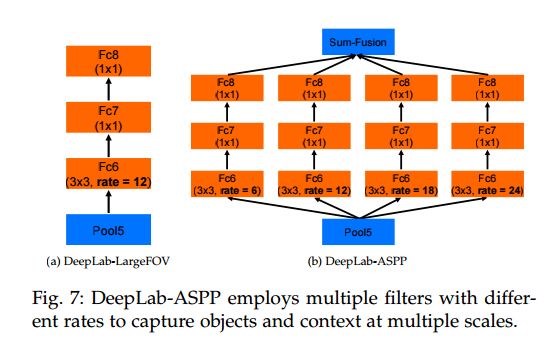
ASPP能捕获到多尺度的信息,但是随着rate的增大,出现了如下图的情况:

就是说,当atrous rate在极限的情况下(等于特征图的大小),3×3的卷积退化成为了1×1的卷积(只有一个权重(中心)是有效的)
为了解决这个问题,并且将全局的上下文信息合并到模型中,在模型最后得到的特征图中采用全局平均池化,再给256个1×1的卷积(BN),然后双线性地将特征图 上采样 到所需的空间维度。最后,改善的ASPP由一个1×1的卷积,三个3×3的卷积,且rate=(6,12,18)当output_stride=16时,如下图所示:
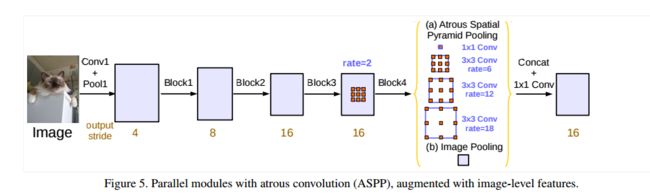
当output_stride=8时,rate=2×(6,12,18).并行处理后的特征图在集中通过256个1×1卷积(BN),最后就是输出了,依旧是1×1卷积。
4. Experimental Evaluation

VOC 2012 dataset
4.1. Training Protocol
分别介绍了:
Learning rate policy
Crop size
Batch normalization
Upsampling logits
Data augmentation
4.2. Going Deeper with Atrous Convolution

这是加了block7的ResNet-50在不同output_stride的条件下的试验结果。

这是层次变深的结果。
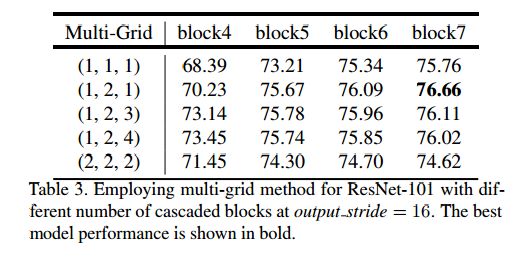
这是Multi-Grid的不同rate的结果。

不同的办法在VAL set上的结果。
4.3. Atrous Spatial Pyramid Pooling
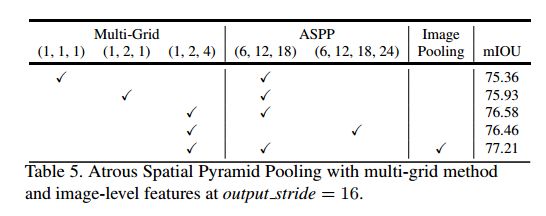
这是不同rate的ASPP的结果。

不同的办法在VAL set上的结果。
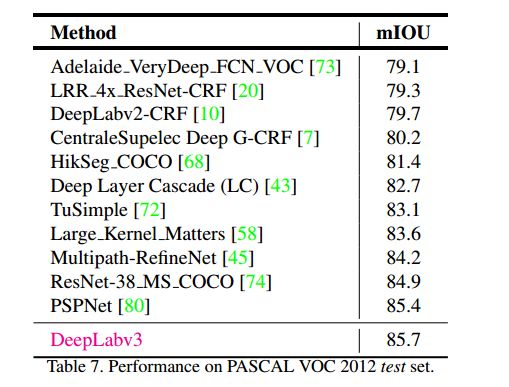
不同Net结果
5. Conclusions
