机器学习笔记 - 用于语义图像分割的空洞卷积DeepLabv3
一、什么是DeepLabv3?
DeepLabv3 是用于语义分割任务的深度神经网络 (DNN) 架构。虽然不是比较新的网络模型,但是也是分割模型里的杰出代表之一,所以还是值得深入了解。
它使用Atrous(Dilated)卷积来控制感受野和特征图分辨率,而不增加参数总数。另一个主要属性是所谓的“Atrous Spatial Pyramid Pooling”,它可以有效地提取包含有用分割信息的多尺度特征。一般来说,网络能够捕获具有丰富远程信息的密集特征图,可用于准确分割图像。
深度和全卷积神经网络已被证明对于分割任务是有效的。通常,编码器用于将输入图像编码为压缩表示,而解码器用于将这些特征上采样到所需的分辨率。编码器和解码器之间通常存在跳过连接,以在整个网络中传递具有表达能力的高级信息。请参见下图的示例。
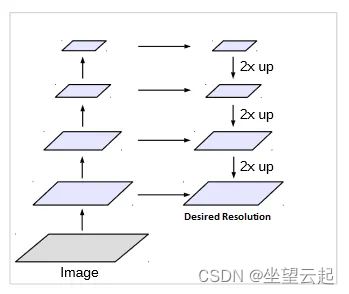
编码器通常使用重复的最大池化和跨步操作来以显着降低的分辨率获得压缩表示。DeepLab 架构提出了一种不同的方法,其中使用空洞卷积块来获得更高分辨率的特征图,并使用双线性上采样来获得所需的分辨率。
二、空洞卷积
Atrous Convolution(与 Dilated Convolution 相同)是 DeepLab 架构的基石。在空洞卷积中,我们只是将零插入到卷积核中以增加内核的大小,而不增加可学习参数的数量(因为我们不关心零)。
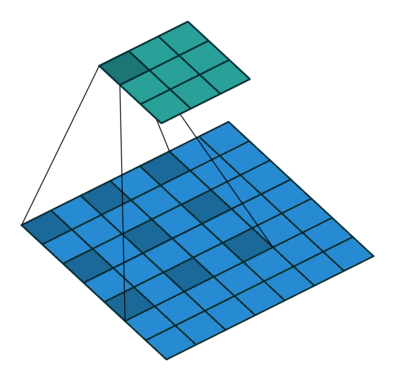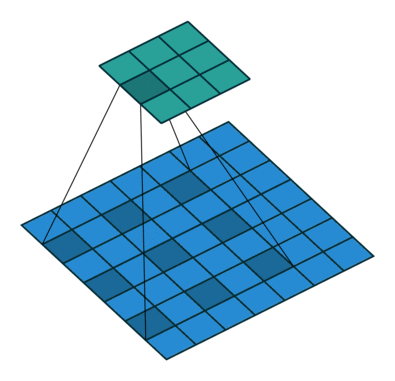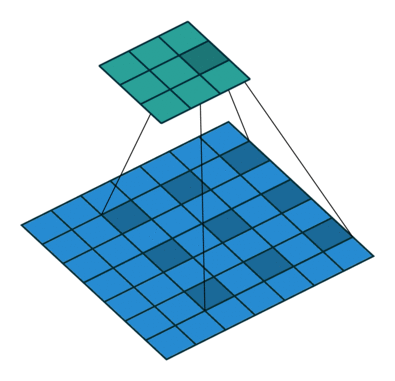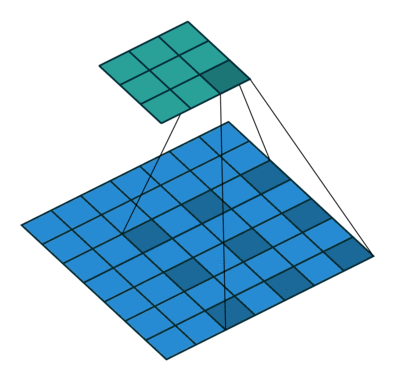
在上图中,我们可以看到 3x3 的空洞核具有 5x5 的感受野。如果我们堆叠空洞卷积层,我们不仅会有一个大的感受野,而且会比常规卷积有更密集的特征图。参见下图。
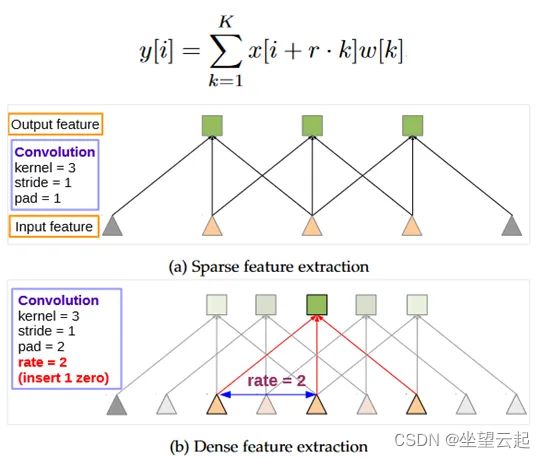
在上图的顶部,我们可以认识到 Atrous 卷积是常规卷积的推广,其中速率r决定了要插入的零的数量。在常规卷积中r = 1。
空洞卷积具有以下优点:
1、能够在更深层次上提取更密集的特征
2、允许通过速率控制感受野
3、保留与常规卷积相同数量的可学习参数
空洞卷积构建更深层次的网络,在不增加参数数量的情况下以更精细的分辨率保留更多高级信息。请参见下图,其中输出步幅定义为输入和输出图像之间的比率。具有更高输出步幅的网络将能够提取更好、更高分辨率的特征。
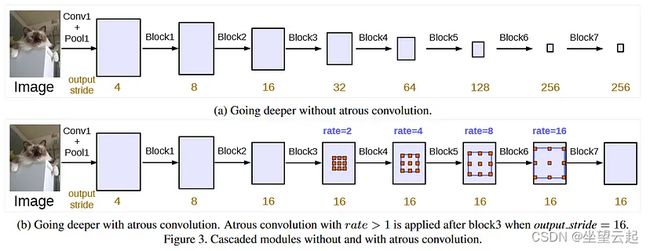 DeepLab 采用了一种称为多重网格方法的方法,其中不同的空洞卷积率应用于网络的不同块。请参见图底部,其中随着信息深入网络,速率会增加。
DeepLab 采用了一种称为多重网格方法的方法,其中不同的空洞卷积率应用于网络的不同块。请参见图底部,其中随着信息深入网络,速率会增加。
在 Atrous 架构中,解码器不需要从极度精简的特征图中进行上采样。通过使用空洞卷积,我们正在构建一个可以提取高分辨率特征图的主干网。
空洞卷积的缺点:空洞卷积可以在网络深处提取大型特征图,但代价是增加内存、显存消耗。另外推理时间也会更长,不过花费这样的代价是我们获得了一个强大的模型。
三、空洞空间金字塔池
如果说空洞卷积是基石,那么空洞空间金字塔池化 (ASPP) 就是基础。
空间金字塔池化(SPP)在多个尺度上对特征进行重新采样,然后将它们池化在一起(通常使用平均池化层)。
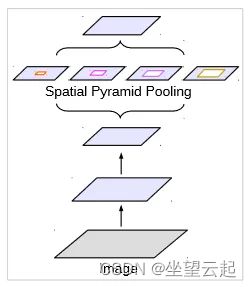
在 ASPP 的情况下,特征尺度通过空洞卷积率来改变。需要注意的一件事是,当速率太大时,空洞卷积本质上会变成 1x1 卷积。在这种情况下,速率接近特征图的大小,并且无法捕获整个图像的上下文。为了克服这个问题,应用了 1x1 卷积,它保留了原始特征图形状,从而从整个特征图中获取信息。将输出连接起来,然后应用全局平均池。
四、整体架构
现在组合在一起形成 DeepLabv3 架构的底层块。下图显示了 DeepLabv3 网络的基本架构,其中主要块只是主干和头部。每个主块都由子块组成。
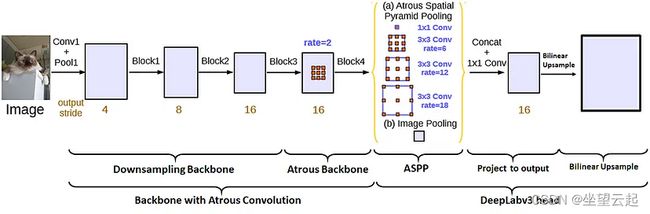 虽然主干和头部是神经网络架构的常用术语,但子块名称不一定是通用的。重要的部分是理解底层概念,以便您可以将它们应用到任何深层架构中。
虽然主干和头部是神经网络架构的常用术语,但子块名称不一定是通用的。重要的部分是理解底层概念,以便您可以将它们应用到任何深层架构中。
整体主干将图像特征编码为丰富的高分辨率特征图。下采样主干网获取输入图像并提取浅层特征,而Atrous主干网以高分辨率编码深层特征而不增加参数总数。
在网络的第二部分中,DeepLabv3 头应用于主干网的末端以产生输出。该头首先由一个 ASPP 块组成,该块对不同尺度的特征进行重新采样,并将它们汇集在一起,提供高质量的多尺度信息。在 ASPP 块之后,我们有一个附加块,它本质上将特征映射投影到所需数量的分割类。最后,使用双线性上采样来获得与输入图像相同分辨率的特征图。
四、网络实现
主干网(有时称为编码器)通常是 ImageNet 模型的修改版本,例如 ResNet 或 MobileNet,但我们实际上可以使用任何类型的网络,只要我们将空洞卷积应用于最终层以获得精细分辨率特征地图。尽管我们通过扩大一些卷积来改变架构,但我们没有改变任何权重,因此我们仍然可以毫无问题地使用预先训练的权重。以与骨干网训练相同的方式准备输入也很重要。
我们可以自己为 DeepLabv3 头编写代码,但如果你不想自己写,torchvision既有预先训练的主干,也有预先训练的头部,这里是文档的链接。
DeepLabV3 — Torchvision main documentation https://pytorch.org/vision/master/models/deeplabv3.html 让我们看一个例子。
https://pytorch.org/vision/master/models/deeplabv3.html 让我们看一个例子。
from torchvision.models.segmentation import deeplabv3_resnet50
deeplabv3 = deeplabv3_resnet50(
weights='COCO_WITH_VOC_LABELS_V1',
weights_backbone='IMAGENET1K_V1'
)
# change outputs to desired number of classes
deeplabv3.classifier[4] = torch.nn.Conv2d(256, num_classes, kernel_size=(1, 1), stride=(1, 1))我们还可以使用分割模型 Pytorch,它支持各种预训练的主干/编码器,但分割头似乎没有经过预训练。
import segmentation_models_pytorch as smp
deeplabv3 = smp.DeepLabV3(
encoder_name='timm-mobilenetv3_small_100',
encoder_weights='imagenet',
classes=num_classes
)五、小结
DeepLabv3 架构由两个主要模块组成:一个能够通过 Atrous Convolution 提供精细分辨率特征图的主干,以及一个能够以精细分辨率提取多尺度特征、将其投影到所需特征数量的DeepLabv3 Head。映射(分割类的数量),并将它们上采样到输入图像分辨率。
由于 DeepLabv3 具有模块化架构,我们可以混合搭配不同的模块以获得所需的性能。例如,我们可以使用预先训练的 ResNet101 主干来获得高性能,或者我们可以为了速度而放弃一些准确性,而使用 MobileNet 主干。我们甚至可以添加多个头来执行多任务学习,例如同时执行分割和深度估计。