DeepLabv3:Rethinking Atrous Convolution for Semantic Image Segmentation论文解读
Introduction
这篇文章是DeepLab系列文章的第三篇,也可以说是DeepLabv3. 这篇文章主要是对DeepLab系列的不断改进,在介绍这篇文章之前,我们先来看一下DeepLab系列论文的大致内容。
Dilated Convolution
Dilated Convolution,也可以叫做空洞卷积,最早在文章
Multi-Scale Context Aggregation by Dilated Convolutions
中被应用到分割领域。我们都知道,CNN的一大特点就是具有一定的平移不变性,这种性质对于分类来说大有裨益,但对于分割这种需要找到每个像素标签的dense classification任务来说,这种特性反而会导致我们很难以得到精确的分割结果,因为特征图的某个激活点代表的特征可能实际分布在激活点靠左,也可能分布在靠右。如果我们再往深一点考虑,这种平移不变性是怎么引入的呢?是池化,因为池化的存在,某个局部最大的激活点便会同时出现在池化后的多个位置,在Bengio等人写的DeepLearning一书中对此也有介绍。如果想要解决这个问题,那只需要把池化取消掉,或者把卷积层的步进(stride)全部设为1就好了。但是这样子又会带来两个新的问题:
感受野(Receptive Field)过小
计算量巨大
对于CNN,每一层的感受野都可以通过公式 RFi=RFi−1+(Kernelsize−1)∗Stride R F i = R F i − 1 + ( K e r n e l s i z e − 1 ) ∗ S t r i d e 得到,考虑像VGG一样全部由3*3组成的网络,输入为224*224,在没有步进的情况下需要100+卷积层才能使感受野达到原图的大小,更何况实际感受野的面积要远小于理论感受野,这部分可以参考我的上一篇ParseNet的博客。而且,特征图过大,需要的计算时间也是以往的几倍几十倍。
反过来想,我们减少stride的数量,又想增大感受野,那就只有增大kernel覆盖的面积,但是这又会增加参数量和计算量,于是空洞卷积就应运而生了。
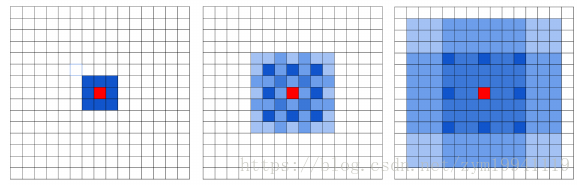
如上所示1,通过空洞卷积把卷积核膨胀起来,可以以极高的速率(合适的rate可以指数级)扩大网络的感受野,即使不做stride也可以聚合全局信息。
CRF(Conditional Random Field)
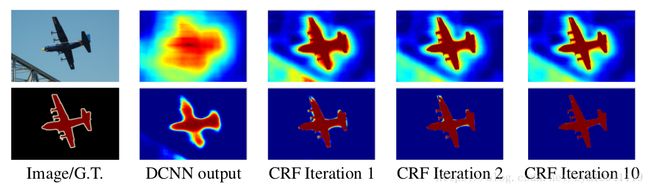
条件随机场是一种概率图模型,以往用来对加噪声的图像进行refine,由于FCN中间的feature map得到的都是非常粗糙的分割图,DeepLab通过CRF作为后处理过程,将得到的分割图在条件随机场中根据能量函数迭代,最终得到精确的分割结果。
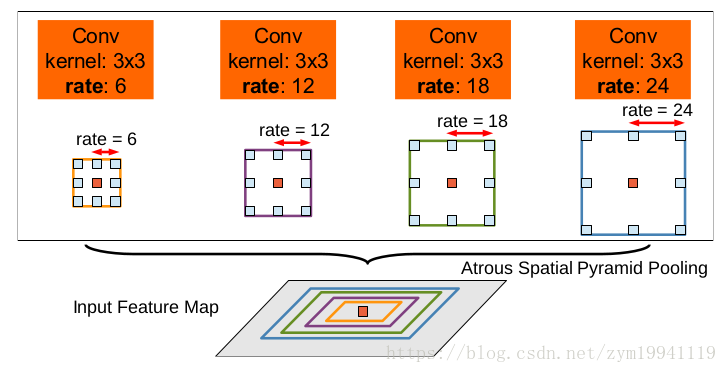
ASPP(Atrous Spatial Pyramid Pooling)
金字塔池化(Spatial Pyramid Pooling)是一项很早就使用的技术,就是把一张图片池化成不同尺度再进行处理,这样可以利用多尺度特征。而在深度学习中的应用最早来自大佬Kaiming He的SPPNet文章,这篇文章使用SPP作为最后的Pooling层,使目标检测可以应用于不同尺度的图片,对任意大小图片都可以检测而不需要再resize成固定大小。随后SPP的思想被利用在分割领域,用来提取多尺度的特征再进行融合,以提升分割的精确度。
而ASPP顾名思义,就是利用不同尺度的空洞卷积进行池化,再把结果融合起来。
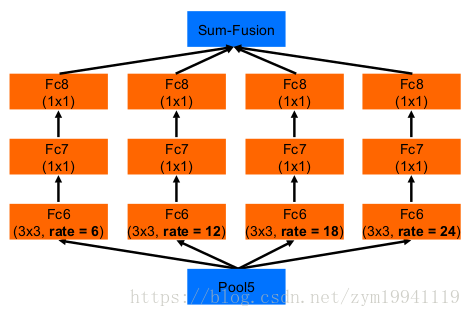
在网络中完整的框架如下:
DeepLab v3
Atrous Concolution
首先文章介绍了空洞卷积的使用,通常情况下CNN输出的特征图是原图的1/32大小,如果想要double输出的分辨率,可以在CNN的最后一个步进为2的池化或卷积处把步进设为1,然后把后续的卷积全部改为rate=2的空洞卷积。
在分割中,正如前面所说,stride的存在对于卷积核捕获大尺度甚至全局信息非常重要,然而作者发现,如果不断地缩小特征图的尺寸,反而会因为失去了细节信息,对分割的性能有很大的影响。

上述实验的网络结构是这样的:

主干是ResNet,block5、block6、block7都是对block4的复制。
因此,使用连续的空洞卷积来捕捉全局信息是一种非常好的方式,在这里作者对级联的不同block定义了不同的扩张系数, MultiGrid=(r1,r2,r3) M u l t i G r i d = ( r 1 , r 2 , r 3 ) 对应于block5-7的基础扩张系数(unit rate),而扩张系数是由网络的output_stride决定的。例如网络的output_stride=16,基础级联系数为 (1,2,4) ( 1 , 2 , 4 ) ,那么block5-7的扩张系数为 32/16∗(1,2,4)=2,4,8 32 / 16 ∗ ( 1 , 2 , 4 ) = 2 , 4 , 8
ASPP
与DeepLabv2中使用的ASPP不同,文章中对ASPP的改进主要体现为加入了Batch Norm。
相比而言,这部分更重要的部分在于发现了空洞卷积的rate并不是越大越好。
通常在ASPP中的rate都会非常大,把大尺度信息聚合起来,但作者通过实验发现随着rate的增加,卷积核中的有效权重会越来越少,不仅没有起到捕捉全局信息的作用,反而会坍缩为一个1*1的卷积,只有最中心的卷积核有个不等于0的值,其他的权重都会变为0。
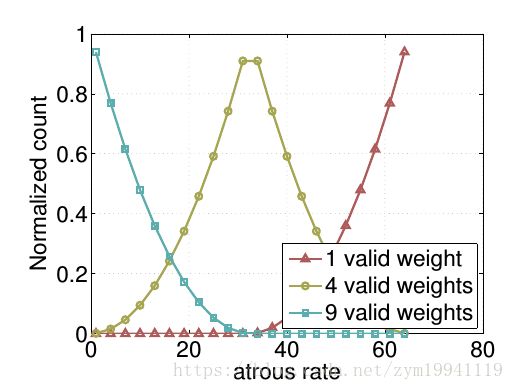
这意味着想要获取全局信息,使用大的rate并不是一个合适的办法,因此,作者在ASPP层又加入了一个全局平均池化(Global Average Pooling),让空洞卷积只负责较大尺度的信息聚合,全局信息交给GAP来收集,GAP位于模型的最后一层,得到的全局特征还会再经过一个1*1的卷积,输出256通道的特征图,最后经过双线性插值插值到原来的大小,与其他的特征图拼接(Concatenate)起来,如下所示:
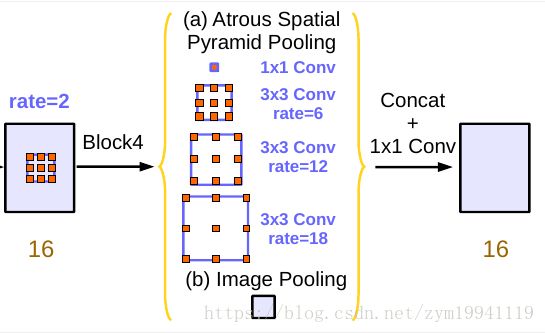
在对比试验中,加入Image Pooling前后的mIoU分别为76.58与77.21,而在ASPP中把Image Pooling替换成rate=24的空洞卷积,性能反而下降了0.12,只有76.46
正说明了GAP对全局信息的聚合能力与空洞卷积大rate下的退化现象。
- 图片来源:Understanding Convolution for Semantic Segmentation ↩