【梳理】第一章 浅谈物体检测与PyTorch
1.1 深度学习与计算机视觉
1.1.1 发展历史
- 机器学习的思想是让机器自动地从大量的数据中学习出规律,并利用该规律对未知的数据做出预测。
- 在机器学习的算法中,深度学习是特指利用深度神经网络的结构完成训练和预测的算法。
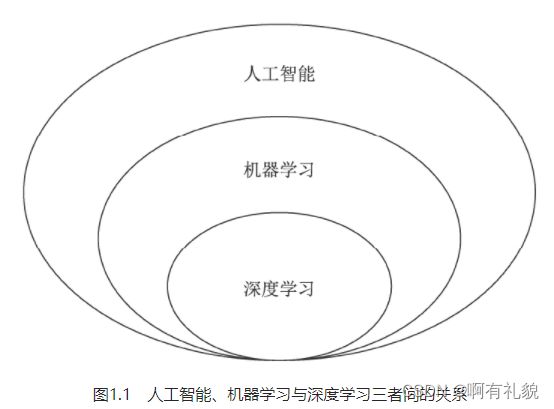
- 人工智能、机器学习、深度学习这三者的关系如图1.1所示。可以看出,机器学习是实现人工智能的途径之一,而深度学习则是机器学习的算法之一。
1) 人工智能
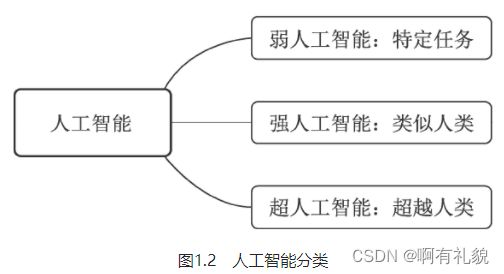
- 弱人工智能(Artificial Narrow Intelligence,ANI):擅长某个特定任务的智能。
- 强人工智能:在人工智能概念诞生之初,人们期望能够通过打造复杂的计算机,实现与人一样的复杂智能,这被称做强人工智能,也可以称之为通用人工智能(Artificial General Intelligence,AGI)。
- 超人工智能(Artificial Super Intelligence,ASI):在强人工智能之上,是超人工智能,其定义是在几乎所有领域都比人类大脑聪明的智能,包括创新、社交、思维等。
2) 机器学习
- 机器学习是实现人工智能的重要途径,也是最早发展起来的人工智能算法。
- 机器学习最早可见于1783年的贝叶斯定理中。贝叶斯定理是机器学习的一种,根据类似事件的历史数据得出发生的可能性。
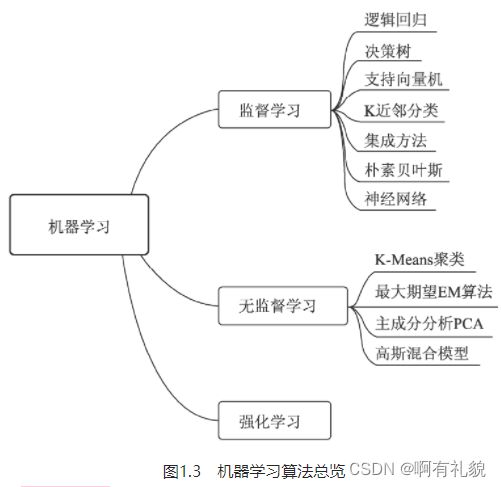
- 机器学习算法中最重要的就是数据,根据使用的数据形式,可以分为三大类:监督学习(Supervised Learning)、无监督学习(Unsupervised Learning)与强化学习(Reinforcement Learning)
- 监督学习:通常包括训练与预测阶段。在训练时利用带有人工标注标签的数据对模型进行训练,在预测时则根据训练好的模型对输入进行预测。监督学习是相对成熟的机器学习算法。监督学习通常分为分类与回归两个问题,常见算法有决策树(Decision Tree,DT)、支持向量机(Support Vector Machine,SVM)和神经网络等。
- 无监督学习:输入的数据没有标签信息,也就无法对模型进行明确的惩罚。无监督学习常见的思路是采用某种形式的回报来激励模型做出一定的决策,常见的算法有K-Means聚类与主成分分析(Principal Component Analysis,PCA)。
- 强化学习:让模型在一定的环境中学习,每次行动会有对应的奖励,目标是使奖励最大化,被认为是走向通用人工智能的学习方法。常见的强化学习有基于价值、策略与模型3种方法。
3) 深度学习
- 深度学习是机器学习的技术分支之一,主要是通过搭建深层的人工神经网络(Artificial Neural Network)来进行知识的学习,输入数据通常较为复杂、规模大、维度高。深度学习可以说是机器学习问世以来最大的突破之一。
发展
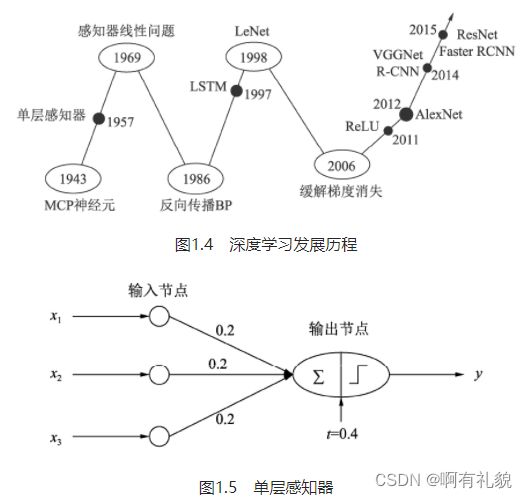
- 最早的神经网络可以追溯到1943年的MCP(McCulloch and Pitts)人工神经元网络,希望使用简单的加权求和与激活函数来模拟人类的神经元过程。
- 1958年的感知器(Perception)模型使用了梯度下降算法来学习多维的训练数据,成功地实现了二分类问题,也掀起了深度学习的第一次热潮。
- 1986年,深度学习领域“三驾马车”之一的Geoffrey Hinton创造性地将非线性的Sigmoid函数应用到了多层感知器中,并利用反向传播(Backpropagation)算法进行模型学习,使得模型能够有效地处理非线性问题。
- 1998年,“三驾马车”中的卷积神经网络之父Yann LeCun发明了卷积神经网络LeNet模型,可有效解决图像数字识别问题,被认为是卷积神经网络的鼻祖。
深度学习元年
- 神经网络存在两个致命问题:一是Sigmoid在函数两端具有饱和效应,会带来梯度消失问题;另一个是随着神经网络的加深,训练时参数容易陷入局部最优解。
- 2006年,Hinton提出了利用无监督的初始化与有监督的微调缓解了局部最优解问题,再次挽救了深度学习,这一年也被称为深度学习元年。
- 2012年的AlexNet网络,其在ImageNet图像分类任务中以“碾压”第二名算法的姿态取得了冠军。
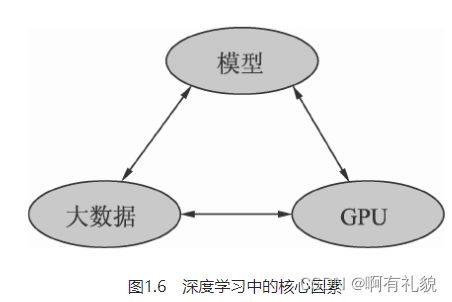
- 深度学习的发展离不开大数据、GPU及模型这3个因素
分类
根据网络结构的不同,深度学习模型可以分为
- 卷积神经网络(Convolutional Neural Network,CNN)
- 循环神经网络(Recurrent Neural Network,RNN)
- 生成式对抗网络(Generative Adviserial Network,GAN)
1.1.2 计算机视觉
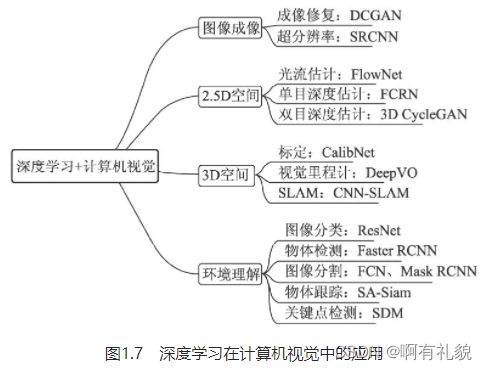
- 图像成像:成像是计算机视觉较为底层的技术,深度学习在此发挥的空间更多的是成像后的应用,如修复图像的DCGAN网络,图像风格迁移的CycleGAN,这些任务中GAN有着广阔的发挥空间。此外,在医学成像、卫星成像等领域中,超分辨率也至关重要,例如SRCNN(Super-Resolution CNN)。
- 2.5D空间:我们通常将涉及2D运动或者视差的任务定义为2.5D空间问题,因为其任务跳出了单纯的2D图像,但又缺乏3D空间的信息。这里包含的任务有光流的估计、单目的深度估计及双目的深度估计。
- 3D空间:3D空间的任务通常应用于机器人或者自动驾驶领域,将2D图像检测与3D空间进行结合。这其中,主要任务有相机标定(Camera Calibration)、视觉里程计(Visual Odometry,VO)及SLAM(Simultaneous Localization and Mapping)等。
- 环境理解:环境的高语义理解是深度学习在计算机视觉中的主战场,相比传统算法其优势更为明显。主要任务有图像分类(Classification)、物体检测(Object Detection)、图像分割(Segmentation)、物体跟踪(Tracking)及关键点检测。其中,图像分割又可以细分为语义分割(Semantic Segmentation)与实例分割(Instance Segmentation)。
1.2 物体检测技术
- 物体检测是一项非常基础的任务,图像分割、物体追踪、关键点检测等通常都要依赖于物体检测。
- 物体检测技术,通常是指在一张图像中检测出物体出现的位置及对应的类别。对于图1.8中的人,我们要求检测器输出5个量:物体类别、xmin 、ymin 、xmax 与ymax 。当然,对于一个边框,检测器也可以输出中心点与宽高的形式,这两者是等价的。
- 在计算机视觉中,图像分类、物体检测与图像分割是最基础、也是目前发展最为迅速的3个领域。
- ·图像分类:输入图像往往仅包含一个物体,目的是判断每张图像是什么物体,是图像级别的任务,相对简单,发展也最快。
- 物体检测:输入图像中往往有很多物体,目的是判断出物体出现的位置与类别,是计算机视觉中非常核心的一个任务。
- 图像分割:输入与物体检测类似,但是要判断出每一个像素属于哪一个类别,属于像素级的分类。图像分割与物体检测任务之间有很多联系,模型也可以相互借鉴。

1.2.1 发展历程
1) 传统算法思路
在利用深度学习做物体检测之前,传统算法对于物体的检测通常分为区域选取、特征提取与特征分类这3个阶段
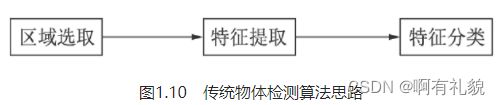
1. 区域选取:首先选取图像中可能出现物体的位置,由于物体位置、大小都不固定,因此传统算法通常使用滑动窗口(Sliding Windows)算法,但这种算法会存在大量的冗余框,并且计算复杂度高。
2. 特征提取:在得到物体位置后,通常使用人工精心设计的提取器进行特征提取,如SIFT和HOG等。由于提取器包含的参数较少,并且人工设计的鲁棒性较低,因此特征提取的质量并不高。
3. 特征分类:最后,对上一步得到的特征进行分类,通常使用如SVM、AdaBoost的分类器。
2) 发展过程
- 2014年的RCNN(Regions with CNN features)算是使用深度学习实现物体检测的经典之作,从此拉开了深度学习做物体检测的序幕。
- 2015年的Fast RCNN实现了端到端的检测与卷积共享,Faster RCNN提出了锚框(Anchor)这一划时代的思想,将物体检测推向了第一个高峰。
Anchor是一个划时代的思想,最早出现在Faster RCNN中,其本质上是一系列大小宽高不等的先验框,均匀地分布在特征图上,利用特征去预测这些Anchors的类别,以及与真实物体边框存在的偏移。Anchor相当于给物体检测提供了一个梯子,使得检测器不至于直接从无到有地预测物体,精度往往较高,常见算法有Faster RCNN和SSD等。
- 2016年,YOLO v1实现了无锚框(Anchor-Free)的一阶检测,SSD实现了多特征图的一阶检测。
- 2017年,FPN利用特征金字塔实现了更优秀的特征提取网络,Mask RCNN则在实现了实例分割的同时,也提升了物体检测的性能。
- 2018年后,物体检测的算法更为多样,如使用角点做检测的CornerNet、使用多个感受野分支的TridentNet、使用中心点做检测的CenterNet等。.
3) 检测算法
- 两阶:两阶的算法通常在第一阶段专注于找出物体出现的位置,得到建议框,保证足够的准召率,然后在第二个阶段专注于对建议框进行分类,寻找更精确的位置,典型算法如Faster RCNN。两阶的算法通常精度准更高,但速度较慢。
- 一阶:一阶的算法将二阶算法的两个阶段合二为一,在一个阶段里完成寻找物体出现位置与类别的预测,方法通常更为简单,依赖于特征融合、Focal Loss等优秀的网络经验,速度一般比两阶网络更快,但精度会有所损失,典型算法如SSD、YOLO系列等。
1.2.2 技术应用领域
安防、自动驾驶、机器人、搜索推荐、医疗诊断
1.2.3 评价指标
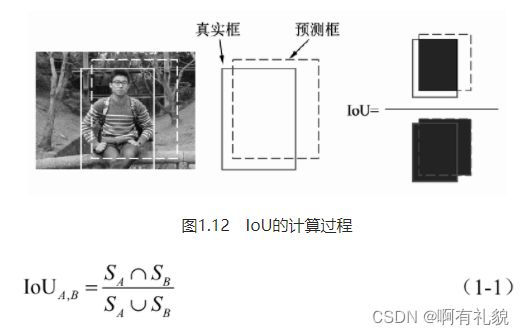
1) IoU(Intersection of Union)
- IoU的计算方式:使用两个边框的交集与并集的比值
- IoU的取值区间是[0,1],IoU值越大,表明两个框重合越好
- Python实现
def iou(boxA, boxB):
# 计算重合部分的上、下、左、右4个边的值,注意最大最小函数的使用
left_max = max(boxA[0], boxB[0])
top_max = max(boxA[1], boxB[1])
right_min = min(boxA[2], boxB[2])
bottom_min = min(boxA[3], boxB[3])
# 计算重合部分的面积
inter =max(0,(right_min-left_max))* max(0,(bottom_min-top_max)
Sa = (boxA[2]-boxA[0])*(boxA[3]-boxA[1])
Sb = (boxB[2]-boxB[0])*(boxB[3]-boxB[1])
# 计算所有区域的面积并计算iou,如果是Python 2,则要增加浮点化操作
union = Sa+Sb-inter
iou = inter/union
return iou
- 选取一个阈值(如0.5)来确定预测框是正确的还是错误的。当两个框的IoU大于该阈值时,我们认为是一个有效的检测,否则属于无效的匹配。

- 正确检测框TP(True Positive):预测框正确地与标签框匹配了,两者间的IoU大于0.5,如图1.13中右下方的检测框。
- 误检框FP(False Positive):将背景预测成了物体,如图1.13中左下方的检测框,通常这种框与图中所有标签的IoU都不会超过0.5。
漏检框FN(False Negative):本来需要模型检测出的物体,模型没有检测出,如图1.13中左上方的杯子。
正确背景(True Negative):本身是背景,模型也没有检测出来,这种情况在物体检测中通常不需要考虑。
2) mAP(mean Average Precision)
- AP指的是一个类别的检测精度,mAP则是多个类别的平均精度。
- 评测需要每张图片的预测值与标签值:
- 预测值(Dets):物体类别、边框位置的4个预测值、该物体的得分。
- 标签值(GTs):物体类别、边框位置的4个真值。
- AP的具体计算过程:
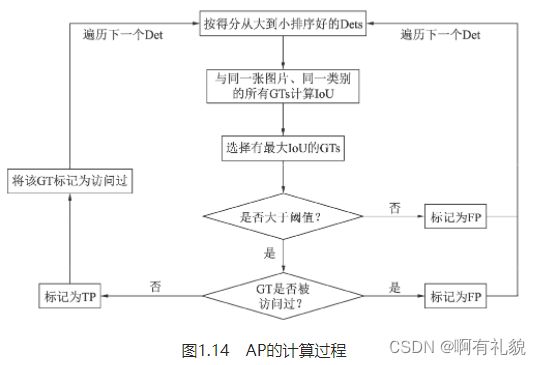
- 首先将所有的预测框按照得分从高到低进行排序(因为得分越高的边框其对于真实物体的概率往往越大),然后从高到低遍历预测框。
- 对于遍历中的某一个预测框,计算其与该图中同一类别的所有标签框GTs的IoU,并选取拥有最大IoU的GT作为当前预测框的匹配对象。如果该IoU小于阈值,则将当前的预测框标记为误检框FP。
- 如果该IoU大于阈值,还要看对应的标签框GT是否被访问过。如果前面已经有得分更高的预测框与该标签框对应了,即使现在的IoU大于阈值,也会被标记为FP。如果没有被访问过,则将当前预测框Det标记为正确检测框TP,并将该GT标记为访问过,以防止后面还有预测框与其对应。
- 在遍历完所有的预测框后,我们会得到每一个预测框的属性,即TP或FP。在遍历的过程中,我们可以通过当前TP的数量来计算模型的召回率
3) 召回率(Recall,R)
当前一共检测出的标签框与所有标签框的比值。

4) 准确率(Precision,P)
当前遍历过的预测框中,属于正确预测边框的比值

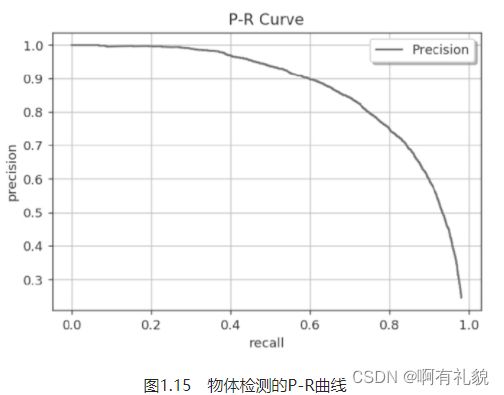
5) P-R曲线
遍历到每一个预测框时,都可以生成一个对应的P与R,这两个值可以组成一个点(R,P),将所有的点绘制成曲线,即形成了P-R曲线
6) AP
- 即使有了P-R曲线,评价模型仍然不直观,如果直接取曲线上的点,在哪里选取都不合适,因为召回率高的时候准确率会很低,准确率高的时候往往召回率很低。
- AP代表了曲线的面积,综合考量了不同召回率下的准确率,不会对P与R有任何偏好。每个类别的AP是相互独立的,将每个类别的AP进行平均,即可得到mAP。
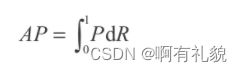
- 严格意义上讲,还需要对曲线进行一定的修正,再进行AP计算。除了求面积的方式,还可以使用11个不同召回率对应的准确率求平均的方式求AP。
- 求解AP:假设当前经过标签数据与预测数据的加载,我们得到了下面两个变量:
- det_boxes:包含全部图像中所有类别的预测框,其中一个边框包含了[left,top,right,bottom,score,NameofImage]。
- gt_boxes:包含了全部图像中所有类别的标签,其中一个标签的内容为[left,top,right,bottom,0]。最后一位0代表该标签有没有被匹配过,如果匹配过则会置为1,其他预测框再去匹配则为误检框。
# 所有类别的评测过程
for c in classes:
# 通过类别作为关键字,得到每个类别的预测、标签及总标签数
dects = det_boxes[c]
gt_class = gt_boxes[c]
npos = num_pos[c]
# 利用得分作为关键字,对预测框按照得分从高到低排序
dects = sorted(dects, key=lambda conf: conf[5], reverse=True)
# 设置两个与预测边框长度相同的列表,标记是True Positive还是False Positive
TP = np.zeros(len(dects))
FP = np.zeros(len(dects))
# 对某一个类别的预测框进行遍历
for d in range(len(dects)):
# 将IoU默认置为最低
iouMax = sys.float_info.min
# 遍历与预测框同一图像中的同一类别的标签,计算IoU
if dects[d][-1] in gt_class:
for j in range(len(gt_class[dects[d][-1]])):
iou = Evaluator.iou(dects[d][:4], gt_class[dects[d][-1]][j][:4])
if iou > iouMax:
iouMax = iou
jmax = j # 记录与预测有最大IoU的标签
# 如果最大IoU大于阈值,并且没有被匹配过,则赋予TP
if iouMax >= cfg['iouThreshold']:
if gt_class[dects[d][-1]][jmax][4] == 0:
TP[d] = 1
gt_class[dects[d][-1]][jmax][4] = 1 # 标记为匹配过
# 如果被匹配过,赋予FP
else:
FP[d] = 1
# 如果最大IoU没有超过阈值,赋予FP
else:
FP[d] = 1
# 如果对应图像中没有该类别的标签,赋予FP
else:
FP[d] = 1
# 利用NumPy的cumsum()函数,计算累计的FP与TP
acc_FP = np.cumsum(FP)
acc_TP = np.cumsum(TP)
rec = acc_TP / npos # 得到每个点的Recall
prec = np.divide(acc_TP, (acc_FP + acc_TP)) # 得到每个点的Precision
# 利用Recall与Precision进一步计算得到AP
[ap, mpre, mrec, ii] = Evaluator.CalculateAveragePrecision(rec, prec)
1.3 PyTorch简介
1.3.1 诞生与特点
PyTorch的前身是诞生于2002年的Torch框架。2017年Facebook的团队对Torch张量之上的所有模块进行了重构,并增加了自动求导这一先进的理念,实现了一个高效的动态图框架PyTorch。
1.3.2 各大深度学习框架对比
1) TensorFlow
- 2015年,谷歌大脑(Google Brain)团队推出了深度学习开源框架TensorFlow,其前身是谷歌的DistBelief框架。
- TensorFlow使用数据流图进行网络计算,图中的节点代表具体的数学运算,边则代表了节点之间流动的多维张量Tensor。
- 优点:功能完全,对于多GPU的支持更好,有强大且活跃的社区,并且拥有强大的可视化工具TensorBoard。
- 缺点:系统设计较为复杂,接口变动较快,兼容性较差,并且由于其构造的图是静态的,导致图必须先编译再执行,不利于算法的预研等。
2) MXNet
- MXNet由DMLC(Distributed Machine Learning Community)组织创建,该组织成员以陈天奇、李沐为代表,大部分都为中国人。
- MXNet项目于2015年在GitHub上正式开源,于2016年被亚马逊AWS正式选择为其云计算的官方深度学习平台,并在2017年进入Apache软件基金会,正式成为了Apache的孵化器项目。
- 优点:将命令式编程(提供了张量计算)与声明式编程(支持符号表达式)进行结合,提供了多种语言接口,有超强的分布式支持,对于内存和显存做了大量优化,尤其适用于分布式环境中。
- 缺点:推广不够有力,文档的更新没有跟上框架的迭代速度,导致新手上手MXNet较难。
3) Keras
- Keras是建立在TensorFlow、Theano及CNTK等多个框架之上的神经网络API,对深度学习的底层框架作了进一步封装,提供了更为简洁、易上手的API。
- 优点:使用Python语言,并且可以在CPU与GPU间无缝切换。使用相对简单,入门快。
- 缺点:构建于第三方框架之上,导致其灵活性不足,调试不方便,很难学习到神经网络真正的内容,且性能较慢。
4) Caffe与Caffe 2
- Caffe(Convolutional Architecture for Fast Feature Embedding)作者是贾扬清博士,核心语言是C++,支持CPU与GPU两种模式的计算。优点:设计清晰、实现高效,尤其是对于C++的支持,使工程师可以方便地在各种工程应用中部署Caffe模型。缺点:灵活性不足,总体上更偏底层。
- Caffe 2是一个轻量化与跨平台的深度学习框架,核心库是C++,但也提供了Python的API。优点是高性能与跨平台部署。
1.3.3 为什么选择PyTorch
简洁优雅、易上手、速度快、发展趋势
1.3.4 安装方法
- cmd查看GPU信息:nvidia-smi
- cuda:可以参考 https://blog.csdn.net/fu6543210/article/details/90020330
- 具体安装可以参考https://blog.csdn.net/love_respect/article/details/124681233 ,个人建议安装anaconda mini版,没有图形化界面
1.4 基础知识准备
1.4.1 Linux基础
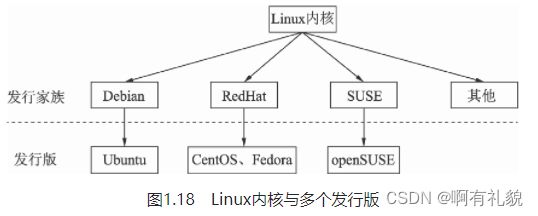
1) 基本目录结构
- boot:Linux系统启动时用到的文件,建议单独分区,大小512MB即可。
- lib:系统使用到的函数库目录,协助系统中程序的执行,比较重要的有lib/modules目录,存放着内存文件。
- bin:可执行的文件目录,包含了如ls、mv和cat等常用的命令。
- home:默认的用户目录,包含了所有用户的目录与数据,建议设置较大的磁盘空间。
- usr:应用程序存放的目录,其中,usr/local目录下存放一些软件升级包,如Python、CUDA等,usr/lib目录下存放一些不能直接运行但却是其他程序不可或缺的库文件,usr/share目录下存放一些共享的数据。
- opt:额外安装的软件所在的目录,例如常用的ROS可执行文件,一般就存放在opt/ros目录下。
2) 环境变量
系统级环境变量
- /etc/environment:用于为所有进程设置环境变量,是系统登录时读取的第一个文件,与登录用户无关,一般要重启系统才会生效。
- /etc/profile:用于设置针对系统所有用户的环境变量,是系统登录时读取的第二个文件,与登录用户有关。
用户级环境变量
- ~/.profile:对应当前用户的profile文件,用于设置当前用户的工作环境,默认执行一次。
- ~/.bashrc:对应当前用户的bash初始化文件,每打开一个终端,就会被执行一次。
1.4.2 Python基础
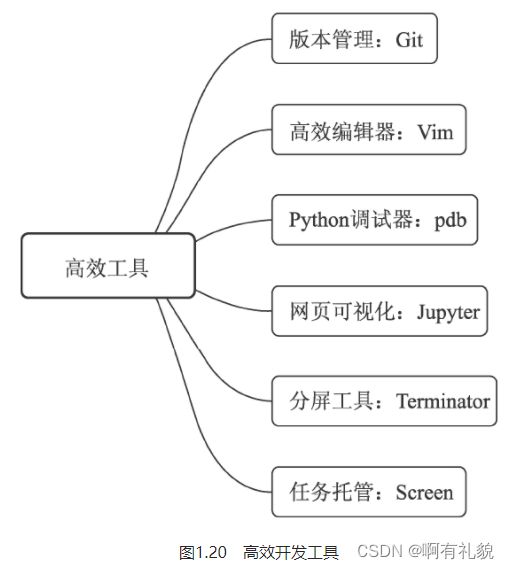
1.4.3 高效开发工具
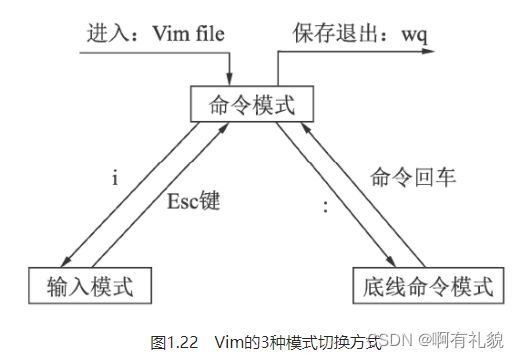
2) VIM
三种基本模式
- 命令模式:刚打开Vim时就进入了命令模式,此时敲入任何字母都代表了命令,而不是直接插入到光标处。命令模式下有一些常用的基本命令,可以有效提升开发者的效率。
- 输入模式:在命令模式中输入i字符就进入了输入模式,在该模式下可以进行代码的增、删等操作。
- 底线命令模式:在命令模式下输入“:”(英文冒号)即进入底线命令模式,这里有更为丰富的命令,如保存、退出和跳转等。
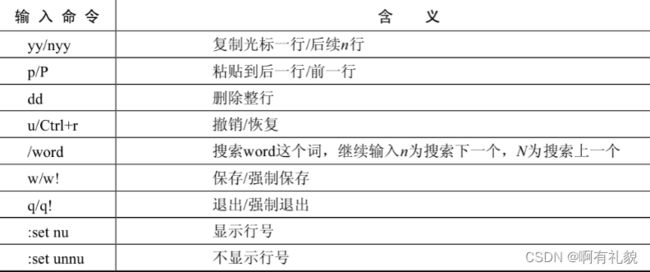
Vim命令
- Vim常用的插入方式

- Vim常用的光标移动方式

- Vim其他常见的功能