论文阅读:(二)Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping
我们常用的SLAM库有ORB-SLAM、VINSMono、OKVIS、ROVIO等。
这篇论文要介绍的是另一个开源库Kimera,它提供了3D网格重建功能和语义标注功能。
(因为还没有什么基础,不能够判别总结,差不多就是整篇翻译)
论文:Kimera: an Open-Source Library for Real-Time Metric-Semantic Localization and Mapping——2020IEEE
源码:https://github.com/MIT-SPARK/Kimera
为实时度量语义视觉惯性SLAM提供了一个开源的C++库,该库支持3D网格重建和语义标注。度量语义理解是一种同时估计场景的3D几何图形并将语义标签附加到对象的能力。
它由四个模块组成:
(1)VIO:用于快速和准确状态估计的视觉惯导测距模块。
(2)RPGO:全局轨迹估计的姿态图优化器
(3)Mesher:快速网格重建的轻型3D网格划分器模块
(4)Semantics:密集的3D度量语义重建模块
这些模块可以单独或组合运行。
相关工作:
SLAM++开创性工作引发了对实时度量语义建图的兴趣激增,这些作品大多数
(1)依赖RGB-D相机
(2)使用GPU处理
(3)使用tracking and mapping架构
(4)使用基于体素、表面或对象表示
比如:SemanticFusion、Fusion++、Mask-fusion。
最近也有基于CPU的处理方法像Voxblox++,但它也依赖于RGB-D相机。
还有一些其他感测模式,像单目相机的CNNSLAM、VSO、VITAMIN-E、XIVO,像激光雷达的SemantiKitti、SegMap。
其中XIVO和Voxblox++最接近最篇论文的提议。XIVO是基于EKF的视觉惯性方法,并产生基于对象的地图。Voxblox++依靠RGB-D传感器和轮式里程计,使用maplab的预建地图来获得视觉惯性姿态估计。
与这些工作不同的是,Kimera
(1)提供了高精度的基于实时优化的VIO
(2)使用了更鲁棒和通用的姿态图优化器
(3)提供了轻量级的优化器
贡献:Kimera是一个开源的C++库,它使用视觉惯性感知来估计机器人的状态,并构建一个轻量级的环境度量语义网格模型。它统一了跨领域的最新成果(nb!),包括VIO、姿态图优化、网格重建和3D语义分割。共包含4个部分:
(1)Kimera-VIO:用于快速和精确的惯性测量单元速率状态估计的VIO模块。它的核心采用了基于GTSAM的VIO方法,使用了IMU预整合和无结构的视觉因子,在EuRoC数据集上实现最高性能。
(2)Kimera-RPGO:是一种稳健的姿态图优化方法,利用现代技术剔除异常值。它增加了鲁棒性层,避免了感知混叠导致的SLAM失败,减轻了用户耗时的参数调整。
(3)Kimera-Mesher:计算快速每帧和多帧正则化3D网格以支持避障的模块。网格建立在作者和其他小组以前的算法基础上。
(4)Kimera-Semantics:使用体积方法构建一个更慢但更精确的全局3D网格,并使用2D像素语义分割对3D网格进行语义标注。
(又讲了一遍 在摘要的基础上细讲了一下)
Kimera可以使用机器人操作系统(ROS)离线或在线处理数据集。它在中央处理器上实时运行,并提供有用的调试和可视化工具。此外,它是模块化的,允许替换每个模块或单独执行它们。例如,如果语义标签不可用,它可以退回到VIO解决方案,或者可以简单地估计几何网格。
框架流程:
将立体帧和高速的惯性测量作为输入,进入
(1)以IMU的速率进行高精度的状态估计。
(2)全局一致的轨迹估计。
(3)环境的多个网格,包括快速局部网络和全局语义注释网络。
它是高度并行化的,使用四个线程来适应不同速率的输入和输出(IMU、帧、关键帧)。
(1)第一个线程包括Kimera-VIO的前端,它获取立体图像和惯性测量单元的数据,输出特征轨迹和预集成惯性测量单元的测量值,还发布惯性测量单元的速率状态估计。
(2)第二个线程包括Kimera-VIO的后端形式,它输出优化的状态估计以及Kimera-Mesher,它计算低延迟全帧和多帧3D网格。
这两个线程可以创建每帧网络b(也可带语义标签变成c)和多帧网格d,这两个线程运行速度慢,旨在支持低频功能,如路径规划。
(3)第三个线程包括kimera-RPGO,它检测闭环,挑除异常值,并估计全局一致性轨迹a。
(4)最后一个线程包括Kimera-Semantics,它使用稠密的立体和2D语义标签来获得一个精确的度量-语义网格,使用Kimera-VIO的姿态估计。

各模块的具体算法:
(1)Kimera-VIO:视觉惯性里程计模块
实现了基于关键帧的最大的后验视觉惯性估计器。根据指定的时间范围,估计器可以执行完全平滑或固定滞后平滑;我们通常使用后者来限制估计时间。它包括一个(视觉和惯性)前端,负责处理原始传感器数据,以及一个后端,用于融合处理后的测量结果,以获得传感器状态的估计值(即姿态、速度和传感器偏差)。
前端:惯性测量单元前端执行一次预集成,从原始惯性测量单元数据中获得两个连续关键帧之间相对状态的紧凑预集成测量。视觉前端检测Shi-Tomasi角点,使用Lukas-Kanade跟踪器跨帧跟踪它们,找到左右立体匹配,并执行几何验证。我们使用5点RANSAC进行单验证,使用3点RANSAC进行立体验证;该代码还提供了使用惯性测量单元旋转的选项,并分别使用2点和1点RANSAC执行单和立体声验证。特征检测、立体匹配和几何验证在每个关键帧执行,而我们只跟踪中间帧的特征。
后端:在每个关键帧,预集成的惯性测量单元和视觉测量被添加到固定滞后平滑器(因子图),构成我们的VIO后端。我们使用预集成惯性测量单元模型和无结构视觉模型。因子图用GTSAM 中的iSAM2求解。在每次iSAM2迭代中,无结构视觉模型使用DLT估计观察到的特征的3D位置,并从VIO状态分析性地消除相应的3D点。在消除之前,退化点(即,相机后面的点或没有足够的视差用于三角测量的点)和离群点(即,具有大的重投影误差的点)被去除,从而提供额外的鲁棒性层。最后,超出平滑范围的点使用GTSAM被边缘化。
(2)Kimera-RPGO:鲁棒的位姿图优化模块
负责(I)检测当前和过去关键帧之间的循环闭合,以及(ii)使用鲁棒的PGO计算全局一致的关键帧姿态。
闭环检测:闭环检测依赖于DBoW2库,并使用一包单词表示来快速检测假定的闭环。对于每个假定的闭环,我们使用单和立体几何验证来拒绝异常闭环,并将剩余的闭环传递给鲁棒的PGO求解器。请注意,由于感知混叠,最终的闭环仍然可能包含异常值(例如,一个建筑物的不同楼层上的两个相同的房间)。
鲁棒的PGO:该模块在GTSAM中实现,包括一种现代离群点剔除方法,增量一致测量集最大化(PCM) ,我们根据单个机器人和在线设置进行了定制。我们分别存储里程计边缘和闭环;每次执行PGO时,我们首先使用修改后的PCM选择最大的一组一致闭环,然后在姿态图上执行GTSAM,包括里程计和一致闭环。
(3)Kimera-Mesher:三维网格重建
可以快速生成两种类型的3D网格:(1)每帧3D网格,(2)在VIO固定滞后平滑器中跨越关键帧的多帧3D网格。
每帧3D网格:首先在当前关键帧中成功跟踪的2D特征(由VIO前端生成)上执行2D-Delaunary三角测量。然后,我们使用来自VIO后端的3D点估计,反投影2D Delaunary三角测量来生成3D网格b。虽然每帧网格被设计为提供低延迟障碍检测,但是我们还提供了通过用2D标签纹理化网格来对结果网格进行语义标记的选项c。
多帧3D网格:多帧网格将在VIO减弱的范围上收集的每帧网格融合成单个网格d。每帧和多帧3D网格都被编码为顶点位置列表,以及描述三角形面的顶点标识三元组列表。假设我们在时间t1已经有一个多帧网格,对于我们生成的每个新的每帧3D网格(在时间t),我们在它的顶点和三元组上循环,并添加在每帧网格中但在多帧网格中缺失的顶点和三元组。然后我们在多帧网格顶点上循环,并根据最新的VIO后端估计更新它们的3D位置。最后,我们移除对应于在VIO时间范围之外观察到的旧特征的顶点和三元组。结果是一个最新的三维网格,跨越当前VIO时间范围内的关键帧。如果在网格中检测到平面,则正则因子被添加到VIO后端,这导致VIO正则化和网格正则化之间的紧密耦合。
(4)Kimera-Semantics:度量语义分割
采用了中介绍的捆绑光线投射技术,以(I)构建精确的全局3D网格(覆盖整个轨迹),以及(ii)对网格进行语义注释。
全局网格:建立在V oxblox的基础上,使用基于体素的(TSDF)模型来滤除噪声并提取全局网格。在每个关键帧,我们使用密集立体(半全局匹配)从当前立体对获得3D点云。然后我们使用Voxblox应用捆绑的光线投射。这个过程在每个关键帧重复,并产生一个TSFD,从中使用行进立方体提取网格
语义标注:Kimera-Semantics使用2D语义标注的图像(在每个关键帧产生)对全局网格进行语义标注;2D语义标签可以使用用于像素级2D语义分割的现成工具来获得,例如,深度神经网络或基于经典MRF的方法。为此,在捆绑的光线投射过程中,我们还传播语义标签。使用2D语义分割,我们将标签附加到由密集立体生成的每个3D点。然后,对于束射线投射中的每束射线,我们从束中观察到的标记的频率构建标记概率向量。然后,我们仅在TSDF截断距离内(即表面附近)沿射线传播该信息,以节省计算。换句话说,我们省去了更新“空”标签概率的计算工作。当沿着射线遍历体素时,我们使用贝叶斯更新来更新每个体素的标签概率,类似于。在捆绑语义光线投射之后,每个体素都有一个标签概率向量,我们从中提取最可能的标签。最终使用行进立方体提取度量语义网格。生成的网格比第二节-第三节的多帧网格精确得多,但计算速度较慢。
实验评估:
A:(1)Kimera实现了一流的状态估计性能 (2)鲁棒的PGO减轻用户耗时的参数调整

从表中得出,在EuRoC数据集上,Kimera拥有最先进的VIO通道。
比较的是均方根误差,根据它们是否使用固定滞后平滑、完全平滑和闭环来对技术进行分组。Kimera各个领域都取得了优异的表现。
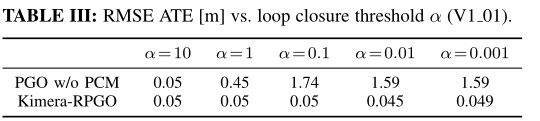
此外,Kimera-RPGO确保了稳健的性能,并且对闭环参数调整不太敏感。表三显示了DBoW2中使用的不同环路闭合阈值α值的带和不带异常值剔除(PCM)的PGO精度。α值越小,检测到的闭环越多,但保守性越低(离群值越多)。表三显示,通过使用PCM,Kimera-RPGO对α的选择相当不敏感。
B:展示了Kimera在EuRoC上的3D网格重建,使用场景子集提供了一个基本的点云。
(a)显示出了估计的云(对应于V1 01上的Kimera-Semantics的全局网格),通过到地面真实云中最近点的距离进行颜色编码(准确性);(b)显示了地面真实云,用到估计云中最近点的距离(完整性)进行了颜色编码。

C:使用照片真实感模拟器检查了Kimera的3D十进制语义重建,该模拟器提供了真实的3D语义。
使用了麻省理工学院林肯实验室提供的基于照片真实感的模拟器,该模拟器为场景的几何和语义提供传感器流(ROS)和地面真实。Kimera-Semantics根据VIO的姿势估计构建了一个3D网格,并使用了密集立体和捆绑光线投射的组合。我们通过运行三个不同的实验来评估每个组件的影响。
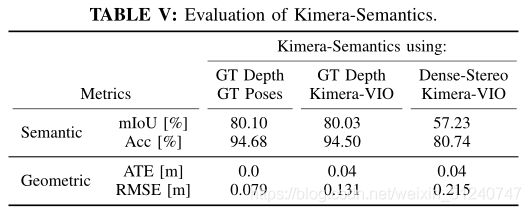
首先,我们使用Kimera-Semantics结合地面真实(GT)姿态和地面真实深度图(在模拟中可用)来评估捆绑光线投射造成的初始性能损失。其次,我们使用Kimera-VIO的姿势估计。最后,我们使用完整的Kimera语义管道,包括密集的立体声。为了分析语义性能,我们计算了联合上的平均交集(mIoU) ,以及正确标记点的整体部分(Acc) 。最后,我们评估了度量重建,将估计的网格与地面真实情况配准,并计算点的RMSE。
表总结了我们的发现,并表明捆绑的射线投射在几何上(< 3D网格上的8厘米误差)和语义上(准确性> 94%)都导致了性能的小幅下降。
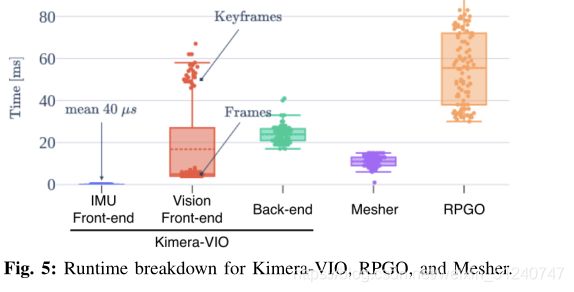
D:突出了Kimera的实时性能,并分析了每个模块的运行时间。