MagicData-RAMC数据集测评 | 西北工业大学冠军队分享
作为2021年第十六届全国人机语音通讯学术会议 (NCMMSC 2021) 特殊议题,由Magic Data (北京爱数智慧科技有限公司) 和江苏师范大学主办,MagicHub开源社区、上海白玉兰开源开放研究院、华为MindSpore社区和英特尔Open VINO中文社区协办的“对话式AI语音识别及说话人识别 (ASR&SD) 挑战赛” 收到了四十多个来自国内各大高校和企业参赛队伍注册报名。
其中,西工大音频语音与处理研究组 (ASLP@NPU) 同学们组建的 “要锅好鱼” 队在本挑战赛 “对话场景下的语音识别 (ASR)”赛道中,以测试集字准确率 87.3% 的优异成绩,荣获第一名。

数 据 集 开 源 ✦ Open Source: MagicData-RAMC
为了进一步丰富开源语音语料库,促进语音语言处理技术的发展,Magic Data 于4月15日在 Magichub 开源社区正式开源用于本次比赛的180小时中文对话式语音数据集 MagicData-RAMC。作为高质量且标注丰富的训练数据,可以很好地支持开发者完成语音识别和说话人日志相关的研究。

数据集下载地址 https://magichub.com/datasets/magicdata-ramc/
论文地址 https://arxiv.org/abs/2203.16844
基线地址 https://github.com/MagicHub-io/MagicData-RAMC-Challenge
MagicData-RAMC 包括351组多轮普通话对话,时长共计180小时。每组对话的标注信息包括转录文本、语音活动时间戳、说话人信息、录制信息和话题信息。说话人信息包括了性别、年龄和地域,录制信息包括了环境和设备。
同时,Magic Data 联合中科院声学研究所、上海交通大学和西北工业大学基于 MagicData-RAMC 完成了语音识别、说话人日志和关键词检索的相关研究,该工作已投稿语音领域顶级会议 Interspeech 2022。
查找更多开源数据集:www.magichub.com
冠 军 队 分 享 ✦ 西工大音频语音与处理研究组
在本次比赛中,西工大音频语音与处理研究组(ASLP@NPU)团队参加的实验室成员包括郭鹏程、梁宇颢、魏坤、姚卓远、王智超、俞帆。以下将对实验室提交的系统进行详细介绍。
对话语音识别的挑战
对话语音识别(Conversational ASR)是语音识别领域的一个挑战性研究课题。自然口语对话不同于朗读式语音,其重要特点和难点主要在于:
・对话语音通常在一段时间内围绕固定主题开展
・口语化语音包含结巴、吞字、不规范语法等情况
・由于录音设备或录音环境导致的噪声和房间混响
此次竞赛语音识别赛道属于受限数据条件。训练集为 Magic Data 开源的 755 小时 ASR 中文朗读数据与为竞赛提供的 160 小时中文对话数据。比赛阶段的测试集为两个 10 小时数据集,分别是朗读风格(以下记为 755h_test)与对话风格(以下记为 160h_test)。竞赛队伍提交的系统只能基于以上这些数据的音频和抄本进行构建,不允许使用集外数据。
多种模型和工具探索
实验室团队分别使用了 ESPnet [1] 和 WeNet [2] 两个语音识别工具包,模型采用 Conformer Encoder [3] + Transformer Decoder 的结构。关于WeNet端到端语音识别工具包,敬请关注「WeNet步行街」公众号。
Conformer Encoder 由多个 Conformer Block 堆叠而成。它的核心想法是将 Multiheaded Self-attention 网络和 Convolution 网络进行结合。Multiheaded Self-attention 网络主要用于建模语音信号的全局依赖信息,同时 Convolution 网络用于学习局部信息。Conformer Encoder 的具体结构如图 1 所示。

图1 : Conformer Block 结构
实验室团队在两个工具包的模型上分别探究了仅使用 160 小时对话语音数据、引入部分或全部 755 小时朗读语音数据、基于 Speed Perturbation 和 SpecAugment 的数据增广技术、增加注意力头数等多个不同配置对识别结果的影响。主要实验结果总结于表 1 和 2,评估准则为字错误率 (Character Error Rate, CER)。

表1 : WeNet 实验结果 (CER%)

表2 : ESPnet 实验结果(CER%)
基于语音转换的数据增广
语音转换(Voice Conversion, VC)是语音合成领域的一个重要研究方向,旨在不改变语音内容的前提下,改变语音中说话人音色的一项技术。鉴于本次竞赛无法使用集外数据,实验室团队用语音转换技术有效地扩充了对话风格的数据。具体来说,随机抽取 755 小时朗读数据中 100 个说话人,每人 400 句话,来提取目标说话人音色。使用多对多语音转换技术,建立这 100 人的音色模型。之后,针对每个目标说话人,从 160 小时对话数据中选取 4000 句生成转换音频。通过在上面效果最好的WeNet模型 (E4) 上加入转换后的 VC 数据进行模型微调,WeNet系统的识别率取得了进一步提升,具体结果如表3所示。关于语音转换技术的方案详见实验室公众号推介文章——论文推介:语音转换中的源风格到目标的迁移
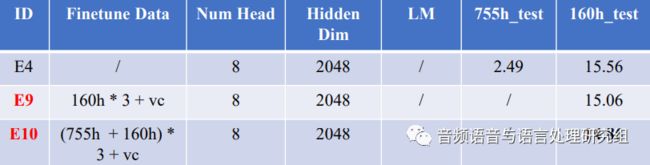
表3 : WeNet VC Finetune 结果(CER%)
基于长上下文建模的语言模型
考虑到语言模型在对话语音识别中的重要作用,实验室团队采用了基于 Transformer 的语言模型重打分(Rescore)方案。对话语音通常会在一段时间内维持一个主题,即上文出现过的信息,当前句中可能会再次出现。因此语言模型如果能建模更长的上下文历史信息,将训练时的语料扩展成为更长的输入,就有可能提高识别准确率[5][6] 。借鉴实验室先前发表论文[6]中的方案,实验室团队随机将处理后的相同话题中的 n (n<4) 句话顺序拼接,加入分隔符并送入语言模型中进行训练,获得长上下文建模的 Transformer 语言模型(LongCtx Transformer LM),如图2所示。通过该语言模型进行模型重打分,在测试集上获得了非常明显的识别性能提升,具体实验结果见表4。
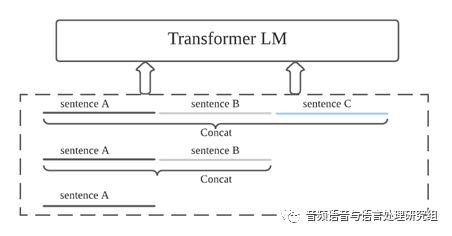
图2 : 基于长上下文建模的语言模型框架

表4 : 基于长上下文建模的语言模型Rescore结果 (CER%)
基于ROVER的多系统融合
Recognizer Output Voting Error Reduction (ROVER) [7] 技术是常用的系统融合技术,其核心思想是根据多个系统得到的结果的出现频率和置信度进行最后判决。考虑到加入长上下文建模的语言模型可能会存在对已有测试集合过拟合的情况,本次竞赛中,我们挑选上述较好的多个模型,使用 ROVER 技术进行多系统融合见表5,在最终的测试集合上取得了 12.7% CER 的好成绩,获得语音识别赛道冠军。

表5 : 基于 ROVER 技术的多系统融合结果 (CER%)
总结
通过本次竞赛,实验室团队探究了对话语音识别任务中存在的难点,分别从数据扩充、声学模型结构、语言模型重打分等多个方面尝试提升识别效果。验结果表明,针对对话语音数据量较少的情况下,基于语音转换技术的数据扩充技术,能够有效地提升性能。如何更为有效的利用语音合成和转换数据进行数据增广是值得进一步研究的问题。此外,长上下文建模的语言模型通过学习跨句子级别的依赖信息,显著提升对话语音识别结果。为此,如何更为有效的利用对话语音的特点进行显式建模是未来的重要研究工作。
参考文献
[1] S. Watanabe, T. Hori, S. Karita, T. Hayashi, J. Nishtoba, Y. Unno, N. E. Y. Soplin, J. Hyemann, M. Wiesner, N. Chen, A. Renduchintala, T. Ochiai, “ESPnet: End-to-end speech processing toolkit,” Interspeech, 2018
[2] Z. Yao, Di. Wu, X. Wang, B. Zhang, F. Yu, C. Yang, Z. Peng, X. Chen, L. Xie, X. Lei, “WeNet: Production oriented streaming and non-streaming end-to-end speech recognition toolkit,” Interspeech, 2021
[3] A. Gulati, J. Qin, C.-C. Chiu, N. Parmer, Y. Zhang, J. Yu, W. Han, S. Wang, Z. Zhang, Y. Wu, R. Pang, “Conformer: Convolution-augmented Transformer for speech recognition,” Interspeech, 2020
[4] Z. Wang, X. Zhou, F. Yang, T. Li, H. Du, L. Xie, W. Gan, H. Chen, H. Li, “Enriching source style transfer in recognition-synthesis based non-parallel voice conversion,” Interspeech, 2021
[5] K. Irie, A. Zeyer, R. Schluter, H. Ney, “Training language models for long-span cross-sentence evaluation,” ASRU, 2019
[6] K. Wei, P. Guo, H. Lv, Z. Tu, L. Xie, “Context-aware RNNLM rescoring for conversational speech recognition,” ISCSLP, 2020
[7] J. G. Fiscus, et al., “A post-processing system to yield reduced word error rate: Recognizer output voting error reduction (ROVER),” ASRU, 1997


点击了解更多数据集
训练数据集'-Magic Data'