Python数据分析——基础数据结构
四种基础数据结构
List

1. 包含一组相似的数据,类似于数组
2. 允许添加、删除、修改元素
3. 允许重复的元素
4. 逗号隔开,中括号包含。
创建List
可以通过直接赋值的方式创建List,也可以创建一个空的List
regions = ['Asia', 'America', 'Europe']
# 空list
regions = []
追加元素
myList = []
myList.append("one")
myList.append("two")
可以通过append方法追加新的元素到list的末尾,元素的顺序与添加的顺序一致。
元素的获取
print(myList[0])
元素是从0开始排序的,我们可以通过索引的方式获取指定位置上的元素
元素的位置
myList.index("one")
通过index方法可以获取指定元素所在的位置
元素的个数
myList.count("one")
通过count方法可以统计指定元素的个数,例如上述语句意在获取"one"在myList中出现了几次。
插入元素
myList.insert(0, "zero")
通过insert(index, value)在指定的位置插入元素
List的切片

切片是指,取list的一个范围的数据

例如myList[1:3],意指取index等于1,2的元素。取到的元素个数为b-a个,但取到的最后一个索引是b-1而不是b

省略前面的范围指的是从第一个元素开始取,一直取到b-1

省略后面的范围,表示从a开始取,一直取完所有元素

两侧都省略,意味着取全部元素。
不使用append追加元素
myList [ len(myList) : ] = ["four", "five"]
通过指定范围的方式进行赋值
删除部分元素
del myList[5 : ]
删除index >= 5的元素
队列
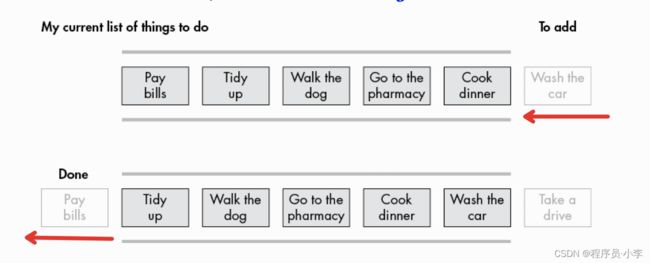
采用FIFO的方式实现,引入deque来实现双端操作
# 引入deque
from collections import deque
# list转deque
queue = deque(my_list)# 使用append追加元素
queue.append('Wash the car')
# 使用popleft()弹出左侧元素
print(queue.popleft(), ' - Done!')
# 转回list
my_list_upd = list(queue)
append可以在末尾追加新的元素,使用popleft可以弹出最左侧的元素
栈
通过两个list实现栈

先将my_list的元素依次追加到stack数组。然后依次弹出最后一个元素。
Tuple
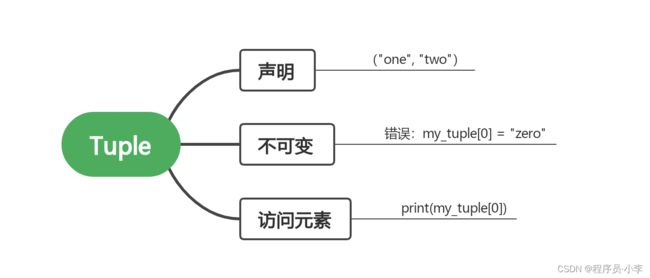

使用小括号包含,逗号分隔,无法修改。
元组的List

顾名思义,外层是list,内层是Tuple
可以通过两个list来构建这个list

sched_list = [(time, task) for time, task in zip(tm_list, task_list) ]
可以获取元组中的元素,但是不可修改
# that is alright
sched_list[0][0]
# that is illegal
sched_list[0][0] = "aaa"
Dictionary

字典存储的是键值对:
1. 大括号包裹
2. 键值对形式存储
3. 可以修改
4. 可组合其他数据结构使用
字典的集合:

内层是字典,外层是list
可以通过键获取值:
print (dict_list [0] ['time'])
setdefault追加新的键值对
如果键已经存在,则不做处理,否则追加进字典。
car = {
"brand": "Volkswagen",
"style": "Sedan",
"model": "Jetta"
}# 追加元素,由于已经存在,不处理
car.setdefault("model", "Passat")
# 由于不存在,则追加成功
car.setdefault("year", 2022)
JSON数据文件的读写
通过dump可以写入JSON文件
import json
# w表示写入
with open("po.json", "w") as outfile:
json.dump(d, outfile)
通过load可以读取JSON数据
with open("po.json",) as fp:
d = json.load(fp)
Set

无重复元素,使用大括号包裹,注意区分字典(字典是键值对)
list去重
lst = ['John Silver', 'Tim Jemison', 'John Silver', 'Maya Smith']
lst = list(set(lst))
这个做法有个缺点,无法保证list元素的相对顺序,因此可以使用下面的方式解决:
lst = list (sorted(set(lst), key = lst.index))
这样可以保证原List元素的相对顺序
取交集
photo1_tags = {'coffee', 'breakfast', 'drink', 'table', 'tableware', 'cup', 'food'}
photo2_tags = {'food', 'dish', 'meat', 'meal', 'tableware', 'dinner', 'vegetable'}
intersection = photo1_tags.intersection(photo2_tags)
if len(intersection) >= 2:
print("The photos contain similar objects.")
intersection可以用于生成一个新的set,存储两个集合的公共部分。