Transformer代码解读(Pytorch)
Transformer代码解读(Pytorch)
本文是对transformer源代码的一点总结。原文在《Pytorch编写完整的Transformer》
本文涉及的jupter notebook在Pytorch编写完整的Transformer
在阅读完
文章目录
- Transformer代码解读(Pytorch)
-
- 0. 读完总结:(这一段是自己的总结笔记)
-
- 0.1 位置编码形状:
- 0.2 多头注意力
- 0.3 encoder层前向传播:
- 0.4 TransformerDecoder前向传播:
- 0.5 Transformer前向传播
- 1. 词嵌入
- 2. 位置编码
- 3. 多头注意力机制
-
- 3.1 初始化参数
- 3.2 前向传播
-
- 3.2.1 矩阵变换
- 3.2.2 遮挡机制
- 3.2.3 点积注意力
- 3.3完整多头注意力机制-MultiheadAttention
- 4.TransformerEncoder
-
- 4.1 Encoder Layer
- 4.2 Transformer layer组成Encoder
- 5. Decoder Layer:
-
- 5.1 TransformerDecoderLayer
- 5.2 Transformer layer组成Decoder
- 6. Transformer
- 致谢
0. 读完总结:(这一段是自己的总结笔记)
- 位置编码是最后加入的,输入输出形状不变。
- 每个attention层都有权重初始化(即输入映射成不同的QKV。而且每层权重不一样)
除了encoder-decoder-attention层q是来自前一层输出,kv是来自encoder层最后的输出memory会导致qkv维度不一致,其它层qkv维度都是一样的。并且只有第一维不一致,分别是L和S。 - 点积时会讲batch放到第一维,还有遮挡机制
- encoderlayer1:输入src加入位置编码,进入 Multi-self-attention层。self.norm1(src + self.dropout1(src2))。即dropout输出src2,然后残差连接+Norm
- encoderlayer2:全连接第一层3072神经元扩维4倍,之后激活并dropout,送入第二个全连接层降维回768维。之后同样的Add+Norm,即src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))、self.norm2(src + self.dropout2(src2))。
- out = transformer_encoder(src),两个线性层中间的激活函数,默认relu或gelu
- decoderlayer:和encoder比加入第二层,tgt=self.multihead_attn(tgt, memory, memory)。和之前一样,三层之后都是self.norm(src + self.dropout(src2))。
- out = decoder_layer(tgt, memory),memory = self.encoder(src)
- encoder和decoder参数除了各自的layer和num_layers,还有个norm参数,默认最后一层输出标准化。
- transformer:没有自定义时使用默认的encoder和decoder层
- out = transformer_model(src, tgt)。
0.1 位置编码形状:
- 输入: [batch_size, seq_length, num_features]
- 输出: [batch_size, seq_length, num_features]
- def positional_encoding(X, num_features, dropout_p=0.1, max_len=512)
0.2 多头注意力
0.2.1初始化:
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
- 如果qkv维度不一致(encoder-decoder-attention层,主要是第一维序列长度不一致),则各自初始化。也就是三个不同的proj_weight来将X映射成qkv。
- 如果qkv维度一致,则用一个3倍的权重矩阵转换之后分割成qkv
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
0.2.2 前向传播multi_head_attention_forward:
-
query, key, value通过_in_projection_packed变换得到q,k,v
-
遮挡机制 attn_mask的dtype为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;若为数值,则会直接加到attn_weights。
-
key_padding_mask是用来遮挡key里面的padding部分
-
点积注意力 多头拼接在一起,并且 q,k,v将Batch放在第一维以适合点积注意力(reshape)
输入:
- query:(L, N, E)点积时是(N, L, E)
- key:(S, N, E)点积时是(N, S, E)
- value:(S, N, E)点积时是(N, S, E)
- key_padding_mask:(N, S)
- attn_mask:(L, S)or(N * num_heads, L, S)N代表着batch_size,num_heads代表注意力头的数目
输出:
- attn_output:(L, N, E)
- attn_output_weights:(N, L, S)
上面N是batch_size,L和S分别代表着目标语言tgt和源语言src序列长度。E是:词嵌入的维度embed_dim
0.3 encoder层前向传播:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)#dropout对最里面的元素随机替换为0,正则手段防止过拟合
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout(src2)
src = self.norm2(src)
return src
torch.nn.dropout源码在这里。
decoderlayer前向传播中:
- tgt过masked-self-attention层后第一次Add+Norm,
- 进入encoder-decoder-self.multihead_attention层(此时输入是tgt、memory和memory),第二次Add+Norm
- 进入全连接层(两层),之后第三次Add+Norm
out = decoder_layer(tgt, memory)
'''参数:
tgt: 目标语言序列(必备)
memory: 从最后一个encoder_layer跑出的句子(必备)
'''
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
0.4 TransformerDecoder前向传播:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory)
0.5 Transformer前向传播
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
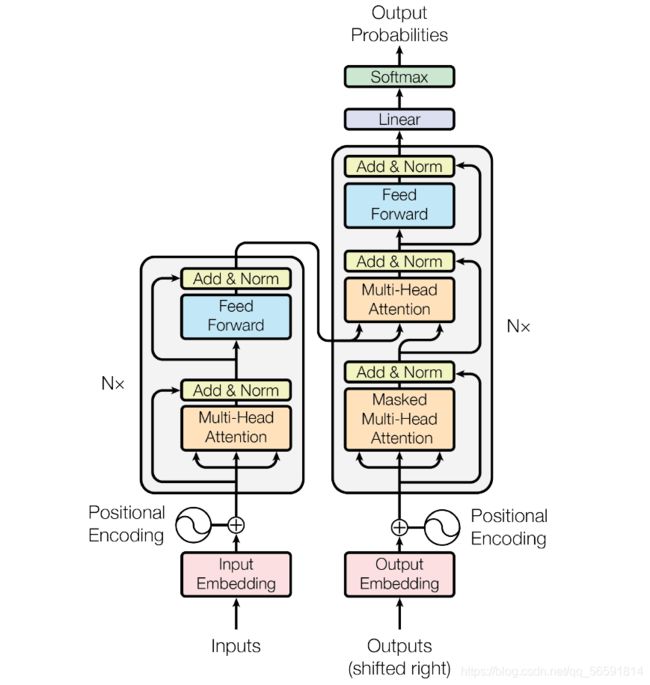
1. 词嵌入
如上图所示,Transformer图里左边的是Encoder,右边是Decoder部分。Encoder输入源语言序列,Decoder里面输入需要被翻译的语言文本(在训练时)。一个文本常有许多序列组成,常见操作为将序列进行一些预处理(如词切分等)变成列表,一个序列的列表的元素通常为词表中不可切分的最小词,整个文本就是一个大列表,元素为一个一个由序列组成的列表。如一个序列经过切分后变为[“am”, “##ro”, “##zi”, “meets”, “his”, “father”],接下来按照它们在词表中对应的索引进行转换,假设结果如[23, 94, 13, 41, 27, 96]。假如整个文本一共100个句子,那么就有100个列表为它的元素,因为每个序列的长度不一,需要设定最大长度,这里不妨设为128,那么将整个文本转换为数组之后,形状即为100 x 128,这就对应着batch_size和seq_length。
输入之后,紧接着进行词嵌入处理,词嵌入就是将每一个词用预先训练好的向量进行映射。
词嵌入在torch里基于torch.nn.Embedding实现,实例化时需要设置的参数为词表的大小和被映射的向量的维度比如embed = nn.Embedding(10,8)。向量的维度通俗来说就是向量里面有多少个数。注意,第一个参数是词表的大小,如果你目前最多有8个词,通常填写10(多一个位置留给unk和pad),你后面万一进入与这8个词不同的词就映射到unk上,序列padding的部分就映射到pad上。
假如我们打算映射到8维(num_features或者embed_dim),那么,整个文本的形状变为100 x 128 x 8。接下来举个小例子解释一下:假设我们词表一共有10个词(算上unk和pad),文本里有2个句子,每个句子有4个词,我们想要把每个词映射到8维的向量。于是2,4,8对应于batch_size, seq_length, embed_dim(如果batch在第一维的话)。
另外,一般深度学习任务只改变num_features,所以讲维度一般是针对最后特征所在的维度。
开始编程:
所有需要的包的导入:
import torch
import torch.nn as nn
from torch.nn.parameter import Parameter
from torch.nn.init import xavier_uniform_
from torch.nn.init import constant_
from torch.nn.init import xavier_normal_
import torch.nn.functional as F
from typing import Optional, Tuple, Any
from typing import List, Optional, Tuple
import math
import warnings
X = torch.zeros((2,4),dtype=torch.long)
embed = nn.Embedding(10,8)
print(embed(X).shape)
2. 位置编码
词嵌入之后紧接着就是位置编码,位置编码用以区分不同词以及同词不同特征之间的关系。代码中需要注意:X_只是初始化的矩阵,并不是输入进来的;完成位置编码之后会加一个dropout。另外,位置编码是最后加上去的,因此输入输出形状不变。
Tensor = torch.Tensor
def positional_encoding(X, num_features, dropout_p=0.1, max_len=512) -> Tensor:
r'''
给输入加入位置编码
参数:
- num_features: 输入进来的维度
- dropout_p: dropout的概率,当其为非零时执行dropout
- max_len: 句子的最大长度,默认512
形状:
- 输入: [batch_size, seq_length, num_features]
- 输出: [batch_size, seq_length, num_features]
例子:
>>> X = torch.randn((2,4,10))
>>> X = positional_encoding(X, 10)
>>> print(X.shape)
>>> torch.Size([2, 4, 10])
'''
dropout = nn.Dropout(dropout_p)
P = torch.zeros((1,max_len,num_features))
X_ = torch.arange(max_len,dtype=torch.float32).reshape(-1,1) / torch.pow(
10000,
torch.arange(0,num_features,2,dtype=torch.float32) /num_features)
P[:,:,0::2] = torch.sin(X_)
P[:,:,1::2] = torch.cos(X_)
X = X + P[:,:X.shape[1],:].to(X.device)
return dropout(X)
# 位置编码例子
X = torch.randn((2,4,10))
X = positional_encoding(X, 10)
print(X.shape)
3. 多头注意力机制
先拆开看多头注意力机制
完整版本可运行的多头注意里机制的class在后面,完整的多头注意力机制-MultiheadAttentionion 再回来依次看下面的解释。
多头注意力类主要成分是:参数初始化、multi_head_attention_forward
3.1 初始化参数
if self._qkv_same_embed_dim is False:
# 初始化前后形状维持不变
# (seq_length x embed_dim) x (embed_dim x embed_dim) ==> (seq_length x embed_dim)
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
# 后期会将所有头的注意力拼接在一起然后乘上权重矩阵输出
# out_proj是为了后期准备的
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
torch.empty是按照所给的形状形成对应的tensor,特点是填充的值还未初始化,类比torch.randn(标准正态分布),这就是一种初始化的方式。在PyTorch中,变量类型是tensor的话是无法修改值的,而Parameter()函数可以看作为一种类型转变函数,将不可改值的tensor转换为可训练可修改的模型参数,即与model.parameters绑定在一起,register_parameter的意思是是否将这个参数放到model.parameters,None的意思是没有这个参数。
这里有个if判断,用以判断q,k,v的最后一维是否一致,若一致,则一个大的权重矩阵全部乘然后分割出来,若不是,则各初始化各的,其实初始化是不会改变原来的形状的(如,见注释)。
可以发现最后有一个_reset_parameters()函数,这个是用来初始化参数数值的。xavier_uniform意思是从连续型均匀分布里面随机取样出值来作为初始化的值,xavier_normal_取样的分布是正态分布。正因为初始化值在训练神经网络的时候很重要,所以才需要这两个函数。
constant_意思是用所给值来填充输入的向量。
另外,在PyTorch的源码里,似乎projection代表是一种线性变换的意思,in_proj_bias的意思就是一开始的线性变换的偏置
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
3.2 前向传播
multi_head_attention_forward函数如下代码所示,主要分成3个部分:
- query, key, value通过_in_projection_packed变换得到q,k,v
- 遮挡机制
- 点积注意力
3.2.1 矩阵变换
import torch
Tensor = torch.Tensor
def multi_head_attention_forward(
query: Tensor,
key: Tensor,
value: Tensor,
num_heads: int,
in_proj_weight: Tensor,
in_proj_bias: Optional[Tensor],
dropout_p: float,
out_proj_weight: Tensor,
out_proj_bias: Optional[Tensor],
training: bool = True,
key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True,
attn_mask: Optional[Tensor] = None,
use_seperate_proj_weight = None,
q_proj_weight: Optional[Tensor] = None,
k_proj_weight: Optional[Tensor] = None,
v_proj_weight: Optional[Tensor] = None,
) -> Tuple[Tensor, Optional[Tensor]]:
r'''
形状:
输入:
- query:`(L, N, E)`
- key: `(S, N, E)`
- value: `(S, N, E)`
- key_padding_mask: `(N, S)`
- attn_mask: `(L, S)` or `(N * num_heads, L, S)`
输出:
- attn_output:`(L, N, E)`
- attn_output_weights:`(N, L, S)`
'''
tgt_len, bsz, embed_dim = query.shape
src_len, _, _ = key.shape
head_dim = embed_dim // num_heads
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
# reshape q,k,v将Batch放在第一维以适合点积注意力
# 同时为多头机制,将不同的头拼在一起组成一层
q = q.contiguous().view(tgt_len, bsz * num_heads, head_dim).transpose(0, 1)
k = k.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
v = v.contiguous().view(-1, bsz * num_heads, head_dim).transpose(0, 1)
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# 若attn_mask值是布尔值,则将mask转换为float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
# 若training为True时才应用dropout
if not training:
dropout_p = 0.0
attn_output, attn_output_weights = _scaled_dot_product_attention(q, k, v, attn_mask, dropout_p)
attn_output = attn_output.transpose(0, 1).contiguous().view(tgt_len, bsz, embed_dim)
attn_output = nn.functional.linear(attn_output, out_proj_weight, out_proj_bias)
if need_weights:
# average attention weights over heads
attn_output_weights = attn_output_weights.view(bsz, num_heads, tgt_len, src_len)
return attn_output, attn_output_weights.sum(dim=1) / num_heads
else:
return attn_output, None
query, key, value通过_in_projection_packed变换得到q,k,v
q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
对于nn.functional.linear函数,其实就是一个线性变换,与nn.Linear不同的是,前者可以提供权重矩阵和偏置,执行,而后者是可以自由决定输出的维度。
def _in_projection_packed(
q: Tensor,
k: Tensor,
v: Tensor,
w: Tensor,
b: Optional[Tensor] = None,
) -> List[Tensor]:
r"""
用一个大的权重参数矩阵进行线性变换
参数:
q, k, v: 对自注意来说,三者都是src;对于seq2seq模型,k和v是一致的tensor。
但它们的最后一维(num_features或者叫做embed_dim)都必须保持一致。
w: 用以线性变换的大矩阵,按照q,k,v的顺序压在一个tensor里面。
b: 用以线性变换的偏置,按照q,k,v的顺序压在一个tensor里面。
形状:
输入:
- q: shape:`(..., E)`,E是词嵌入的维度(下面出现的E均为此意)。
- k: shape:`(..., E)`
- v: shape:`(..., E)`
- w: shape:`(E * 3, E)`
- b: shape:`E * 3`
输出:
- 输出列表 :`[q', k', v']`,q,k,v经过线性变换前后的形状都一致。
"""
E = q.size(-1)
# 若为自注意,则q = k = v = src,因此它们的引用变量都是src
# 即k is v和q is k结果均为True
# 若为seq2seq,k = v,因而k is v的结果是True
if k is v:
if q is k:
return F.linear(q, w, b).chunk(3, dim=-1)
else:
# seq2seq模型
w_q, w_kv = w.split([E, E * 2])
if b is None:
b_q = b_kv = None
else:
b_q, b_kv = b.split([E, E * 2])
return (F.linear(q, w_q, b_q),) + F.linear(k, w_kv, b_kv).chunk(2, dim=-1)
else:
w_q, w_k, w_v = w.chunk(3)
if b is None:
b_q = b_k = b_v = None
else:
b_q, b_k, b_v = b.chunk(3)
return F.linear(q, w_q, b_q), F.linear(k, w_k, b_k), F.linear(v, w_v, b_v)
# q, k, v = _in_projection_packed(query, key, value, in_proj_weight, in_proj_bias)
3.2.2 遮挡机制
对于attn_mask来说,若为2D,形状如(L, S),L和S分别代表着目标语言和源语言序列长度,若为3D,形状如(N * num_heads, L, S),N代表着batch_size,num_heads代表注意力头的数目。若为attn_mask的dtype为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;若为数值,则会直接加到attn_weights。
因为在decoder解码的时候,只能看该位置和它之前的,如果看后面就犯规了,所以需要attn_mask遮挡住。
下面函数直接复制PyTorch的,意思是确保不同维度的mask形状正确以及不同类型的转换
if attn_mask is not None:
if attn_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for attn_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
attn_mask = attn_mask.to(torch.bool)
else:
assert attn_mask.is_floating_point() or attn_mask.dtype == torch.bool, \
f"Only float, byte, and bool types are supported for attn_mask, not {attn_mask.dtype}"
# 对不同维度的形状判定
if attn_mask.dim() == 2:
correct_2d_size = (tgt_len, src_len)
if attn_mask.shape != correct_2d_size:
raise RuntimeError(f"The shape of the 2D attn_mask is {attn_mask.shape}, but should be {correct_2d_size}.")
attn_mask = attn_mask.unsqueeze(0)
elif attn_mask.dim() == 3:
correct_3d_size = (bsz * num_heads, tgt_len, src_len)
if attn_mask.shape != correct_3d_size:
raise RuntimeError(f"The shape of the 3D attn_mask is {attn_mask.shape}, but should be {correct_3d_size}.")
else:
raise RuntimeError(f"attn_mask's dimension {attn_mask.dim()} is not supported")
与attn_mask不同的是,key_padding_mask是用来遮挡住key里面的值,详细来说应该是
# 将key_padding_mask值改为布尔值
if key_padding_mask is not None and key_padding_mask.dtype == torch.uint8:
warnings.warn("Byte tensor for key_padding_mask in nn.MultiheadAttention is deprecated. Use bool tensor instead.")
key_padding_mask = key_padding_mask.to(torch.bool)
先介绍两个小函数,logical_or,输入两个tensor,并对这两个tensor里的值做逻辑或运算,只有当两个值均为0的时候才为False,其他时候均为True,另一个是masked_fill,输入是一个mask,和用以填充的值。mask由1,0组成,0的位置值维持不变,1的位置用新值填充。
a = torch.tensor([0,1,10,0],dtype=torch.int8)
b = torch.tensor([4,0,1,0],dtype=torch.int8)
print(torch.logical_or(a,b))
# tensor([ True, True, True, False])
r = torch.tensor([[0,0,0,0],[0,0,0,0]])
mask = torch.tensor([[1,1,1,1],[0,0,0,0]])
print(r.masked_fill(mask,1))
# tensor([[1, 1, 1, 1],
# [0, 0, 0, 0]])
其实attn_mask和key_padding_mask有些时候对象是一致的,所以有时候可以合起来看。-inf做softmax之后值为0,即被忽略。
if key_padding_mask is not None:
assert key_padding_mask.shape == (bsz, src_len), \
f"expecting key_padding_mask shape of {(bsz, src_len)}, but got {key_padding_mask.shape}"
key_padding_mask = key_padding_mask.view(bsz, 1, 1, src_len). \
expand(-1, num_heads, -1, -1).reshape(bsz * num_heads, 1, src_len)
# 若attn_mask为空,直接用key_padding_mask
if attn_mask is None:
attn_mask = key_padding_mask
elif attn_mask.dtype == torch.bool:
attn_mask = attn_mask.logical_or(key_padding_mask)
else:
attn_mask = attn_mask.masked_fill(key_padding_mask, float("-inf"))
# 若attn_mask值是布尔值,则将mask转换为float
if attn_mask is not None and attn_mask.dtype == torch.bool:
new_attn_mask = torch.zeros_like(attn_mask, dtype=torch.float)
new_attn_mask.masked_fill_(attn_mask, float("-inf"))
attn_mask = new_attn_mask
3.2.3 点积注意力
from typing import Optional, Tuple, Any
def _scaled_dot_product_attention(
q: Tensor,
k: Tensor,
v: Tensor,
attn_mask: Optional[Tensor] = None,
dropout_p: float = 0.0,
) -> Tuple[Tensor, Tensor]:
r'''
在query, key, value上计算点积注意力,若有注意力遮盖则使用,并且应用一个概率为dropout_p的dropout
参数:
- q: shape:`(B, Nt, E)` B代表batch size, Nt是目标语言序列长度,E是嵌入后的特征维度
- key: shape:`(B, Ns, E)` Ns是源语言序列长度
- value: shape:`(B, Ns, E)`与key形状一样
- attn_mask: 要么是3D的tensor,形状为:`(B, Nt, Ns)`或者2D的tensor,形状如:`(Nt, Ns)`
- Output: attention values: shape:`(B, Nt, E)`,与q的形状一致;attention weights: shape:`(B, Nt, Ns)`
例子:
>>> q = torch.randn((2,3,6))
>>> k = torch.randn((2,4,6))
>>> v = torch.randn((2,4,6))
>>> out = scaled_dot_product_attention(q, k, v)
>>> out[0].shape, out[1].shape
>>> torch.Size([2, 3, 6]) torch.Size([2, 3, 4])
'''
B, Nt, E = q.shape
q = q / math.sqrt(E)
# (B, Nt, E) x (B, E, Ns) -> (B, Nt, Ns)
attn = torch.bmm(q, k.transpose(-2,-1))
if attn_mask is not None:
attn += attn_mask
# attn意味着目标序列的每个词对源语言序列做注意力
attn = F.softmax(attn, dim=-1)
if dropout_p:
attn = F.dropout(attn, p=dropout_p)
# (B, Nt, Ns) x (B, Ns, E) -> (B, Nt, E)
output = torch.bmm(attn, v)
return output, attn
3.3完整多头注意力机制-MultiheadAttention
点击快速回到:拆开看多头注意力机制
class MultiheadAttention(nn.Module):
r'''
参数:
embed_dim: 词嵌入的维度
num_heads: 平行头的数量
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)
例子:
>>> multihead_attn = MultiheadAttention(embed_dim, num_heads)
>>> attn_output, attn_output_weights = multihead_attn(query, key, value)
'''
def __init__(self, embed_dim, num_heads, dropout=0., bias=True,
kdim=None, vdim=None, batch_first=False) -> None:
# factory_kwargs = {'device': device, 'dtype': dtype}
super(MultiheadAttention, self).__init__()
self.embed_dim = embed_dim
self.kdim = kdim if kdim is not None else embed_dim
self.vdim = vdim if vdim is not None else embed_dim
self._qkv_same_embed_dim = self.kdim == embed_dim and self.vdim == embed_dim
self.num_heads = num_heads
self.dropout = dropout
self.batch_first = batch_first
self.head_dim = embed_dim // num_heads
assert self.head_dim * num_heads == self.embed_dim, "embed_dim must be divisible by num_heads"
if self._qkv_same_embed_dim is False:
self.q_proj_weight = Parameter(torch.empty((embed_dim, embed_dim)))
self.k_proj_weight = Parameter(torch.empty((embed_dim, self.kdim)))
self.v_proj_weight = Parameter(torch.empty((embed_dim, self.vdim)))
self.register_parameter('in_proj_weight', None)
else:
self.in_proj_weight = Parameter(torch.empty((3 * embed_dim, embed_dim)))
self.register_parameter('q_proj_weight', None)
self.register_parameter('k_proj_weight', None)
self.register_parameter('v_proj_weight', None)
if bias:
self.in_proj_bias = Parameter(torch.empty(3 * embed_dim))
else:
self.register_parameter('in_proj_bias', None)
self.out_proj = nn.Linear(embed_dim, embed_dim, bias=bias)
self._reset_parameters()
def _reset_parameters(self):
if self._qkv_same_embed_dim:
xavier_uniform_(self.in_proj_weight)
else:
xavier_uniform_(self.q_proj_weight)
xavier_uniform_(self.k_proj_weight)
xavier_uniform_(self.v_proj_weight)
if self.in_proj_bias is not None:
constant_(self.in_proj_bias, 0.)
constant_(self.out_proj.bias, 0.)
def forward(self, query: Tensor, key: Tensor, value: Tensor, key_padding_mask: Optional[Tensor] = None,
need_weights: bool = True, attn_mask: Optional[Tensor] = None) -> Tuple[Tensor, Optional[Tensor]]:
if self.batch_first:
query, key, value = [x.transpose(1, 0) for x in (query, key, value)]
if not self._qkv_same_embed_dim:
attn_output, attn_output_weights = multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask, use_separate_proj_weight=True,
q_proj_weight=self.q_proj_weight, k_proj_weight=self.k_proj_weight,
v_proj_weight=self.v_proj_weight)
else:
attn_output, attn_output_weights = multi_head_attention_forward(
query, key, value, self.num_heads,
self.in_proj_weight, self.in_proj_bias,
self.dropout, self.out_proj.weight, self.out_proj.bias,
training=self.training,
key_padding_mask=key_padding_mask, need_weights=need_weights,
attn_mask=attn_mask)
if self.batch_first:
return attn_output.transpose(1, 0), attn_output_weights
else:
return attn_output, attn_output_weights
接下来可以实践一下,并且把位置编码加起来,可以发现加入位置编码和进行多头注意力的前后形状都是不会变的
# 因为batch_first为False,所以src的shape:`(seq, batch, embed_dim)`
src = torch.randn((2,4,100))
src = positional_encoding(src,100,0.1)
print(src.shape)
multihead_attn = MultiheadAttention(100, 4, 0.1)
attn_output, attn_output_weights = multihead_attn(src,src,src)
print(attn_output.shape, attn_output_weights.shape)
# torch.Size([2, 4, 100])
# torch.Size([2, 4, 100]) torch.Size([4, 2, 2])
torch.Size([2, 4, 100])
torch.Size([2, 4, 100]) torch.Size([4, 2, 2])
4.TransformerEncoder
4.1 Encoder Layer
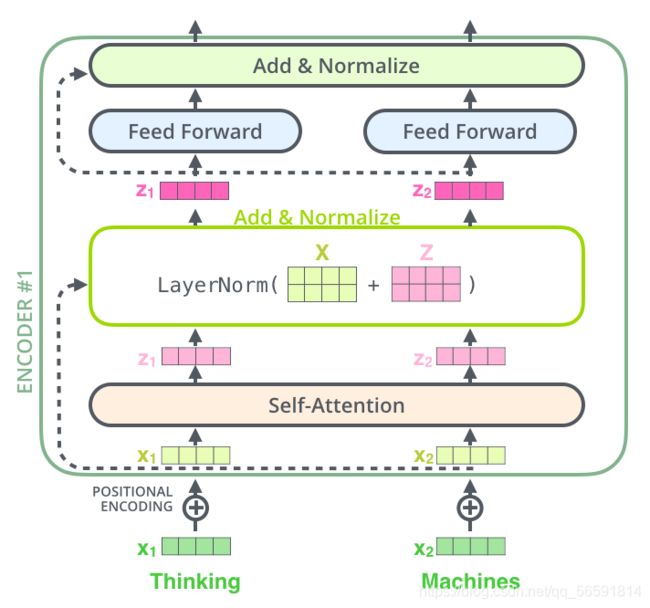
class TransformerEncoderLayer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)
nhead: 多头注意力中平行头的数目(必备)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> src = torch.randn((32, 10, 512))
>>> out = encoder_layer(src)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerEncoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.activation = activation
def forward(self, src: Tensor, src_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
src = positional_encoding(src, src.shape[-1])
src2 = self.self_attn(src, src, src, attn_mask=src_mask,
key_padding_mask=src_key_padding_mask)[0]
src = src + self.dropout1(src2)
src = self.norm1(src)
src2 = self.linear2(self.dropout(self.activation(self.linear1(src))))
src = src + self.dropout2(src2)
src = self.norm2(src)
return src
# 用小例子看一下
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
src = torch.randn((32, 10, 512))
out = encoder_layer(src)
print(out.shape)
# torch.Size([32, 10, 512])
4.2 Transformer layer组成Encoder
class TransformerEncoder(nn.Module):
r'''
参数:
encoder_layer(必备)
num_layers: encoder_layer的层数(必备)
norm: 归一化的选择(可选)
例子:
>>> encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
>>> transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
>>> src = torch.randn((10, 32, 512))
>>> out = transformer_encoder(src)
'''
def __init__(self, encoder_layer, num_layers, norm=None):
super(TransformerEncoder, self).__init__()
self.layer = encoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, src: Tensor, mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = positional_encoding(src, src.shape[-1])
for _ in range(self.num_layers):
output = self.layer(output, src_mask=mask, src_key_padding_mask=src_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 例子
encoder_layer = TransformerEncoderLayer(d_model=512, nhead=8)
transformer_encoder = TransformerEncoder(encoder_layer, num_layers=6)
src = torch.randn((10, 32, 512))
out = transformer_encoder(src)
print(out.shape)
# torch.Size([10, 32, 512])
5. Decoder Layer:
以两层encoder-decoder结构举例
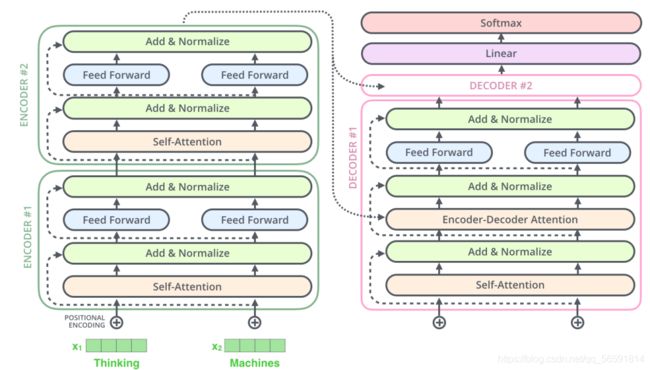
5.1 TransformerDecoderLayer
class TransformerDecoderLayer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)
nhead: 多头注意力中平行头的数目(必备)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> decoder_layer = TransformerDecoderLayer(d_model=512, nhead=8)
>>> memory = torch.randn((10, 32, 512))
>>> tgt = torch.randn((20, 32, 512))
>>> out = decoder_layer(tgt, memory)
'''
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation=F.relu,
layer_norm_eps=1e-5, batch_first=False) -> None:
super(TransformerDecoderLayer, self).__init__()
self.self_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.multihead_attn = MultiheadAttention(d_model, nhead, dropout=dropout, batch_first=batch_first)
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm2 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.norm3 = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = activation
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
tgt: 目标语言序列(必备)
memory: 从最后一个encoder_layer跑出的句子(必备)
tgt_mask: 目标语言序列的mask(可选)
memory_mask(可选)
tgt_key_padding_mask(可选)
memory_key_padding_mask(可选)
'''
tgt2 = self.self_attn(tgt, tgt, tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(tgt, memory, memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
# 可爱的小例子
decoder_layer = nn.TransformerDecoderLayer(d_model=512, nhead=8)
memory = torch.randn((10, 32, 512))
tgt = torch.randn((20, 32, 512))
out = decoder_layer(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
5.2 Transformer layer组成Decoder
class TransformerDecoder(nn.Module):
r'''
参数:
decoder_layer(必备)
num_layers: decoder_layer的层数(必备)
norm: 归一化选择
例子:
>>> decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
>>> transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
>>> memory = torch.rand(10, 32, 512)
>>> tgt = torch.rand(20, 32, 512)
>>> out = transformer_decoder(tgt, memory)
'''
def __init__(self, decoder_layer, num_layers, norm=None):
super(TransformerDecoder, self).__init__()
self.layer = decoder_layer
self.num_layers = num_layers
self.norm = norm
def forward(self, tgt: Tensor, memory: Tensor, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
output = tgt
for _ in range(self.num_layers):
output = self.layer(output, memory, tgt_mask=tgt_mask,
memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
if self.norm is not None:
output = self.norm(output)
return output
# 可爱的小例子
decoder_layer =TransformerDecoderLayer(d_model=512, nhead=8)
transformer_decoder = TransformerDecoder(decoder_layer, num_layers=6)
memory = torch.rand(10, 32, 512)
tgt = torch.rand(20, 32, 512)
out = transformer_decoder(tgt, memory)
print(out.shape)
# torch.Size([20, 32, 512])
总结一下,其实经过位置编码,多头注意力,Encoder Layer和Decoder Layer形状不会变的,而Encoder和Decoder分别与src和tgt形状一致
6. Transformer
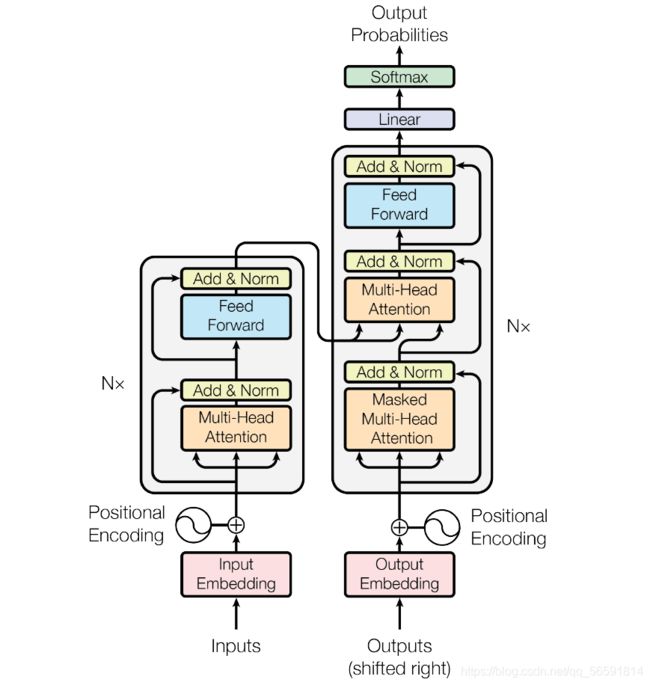
class Transformer(nn.Module):
r'''
参数:
d_model: 词嵌入的维度(必备)(Default=512)
nhead: 多头注意力中平行头的数目(必备)(Default=8)
num_encoder_layers:编码层层数(Default=8)
num_decoder_layers:解码层层数(Default=8)
dim_feedforward: 全连接层的神经元的数目,又称经过此层输入的维度(Default = 2048)
dropout: dropout的概率(Default = 0.1)
activation: 两个线性层中间的激活函数,默认relu或gelu
custom_encoder: 自定义encoder(Default=None)
custom_decoder: 自定义decoder(Default=None)
lay_norm_eps: layer normalization中的微小量,防止分母为0(Default = 1e-5)
batch_first: 若`True`,则为(batch, seq, feture),若为`False`,则为(seq, batch, feature)(Default:False)
例子:
>>> transformer_model = Transformer(nhead=16, num_encoder_layers=12)
>>> src = torch.rand((10, 32, 512))
>>> tgt = torch.rand((20, 32, 512))
>>> out = transformer_model(src, tgt)
'''
def __init__(self, d_model: int = 512, nhead: int = 8, num_encoder_layers: int = 6,
num_decoder_layers: int = 6, dim_feedforward: int = 2048, dropout: float = 0.1,
activation = F.relu, custom_encoder: Optional[Any] = None, custom_decoder: Optional[Any] = None,
layer_norm_eps: float = 1e-5, batch_first: bool = False) -> None:
super(Transformer, self).__init__()
if custom_encoder is not None:
self.encoder = custom_encoder
else:
encoder_layer = TransformerEncoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
encoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.encoder = TransformerEncoder(encoder_layer, num_encoder_layers)
if custom_decoder is not None:
self.decoder = custom_decoder
else:
decoder_layer = TransformerDecoderLayer(d_model, nhead, dim_feedforward, dropout,
activation, layer_norm_eps, batch_first)
decoder_norm = nn.LayerNorm(d_model, eps=layer_norm_eps)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
self.batch_first = batch_first
def forward(self, src: Tensor, tgt: Tensor, src_mask: Optional[Tensor] = None, tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None, src_key_padding_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None, memory_key_padding_mask: Optional[Tensor] = None) -> Tensor:
r'''
参数:
src: 源语言序列(送入Encoder)(必备)
tgt: 目标语言序列(送入Decoder)(必备)
src_mask: (可选)
tgt_mask: (可选)
memory_mask: (可选)
src_key_padding_mask: (可选)
tgt_key_padding_mask: (可选)
memory_key_padding_mask: (可选)
形状:
- src: shape:`(S, N, E)`, `(N, S, E)` if batch_first.
- tgt: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
- src_mask: shape:`(S, S)`.
- tgt_mask: shape:`(T, T)`.
- memory_mask: shape:`(T, S)`.
- src_key_padding_mask: shape:`(N, S)`.
- tgt_key_padding_mask: shape:`(N, T)`.
- memory_key_padding_mask: shape:`(N, S)`.
[src/tgt/memory]_mask确保有些位置不被看到,如做decode的时候,只能看该位置及其以前的,而不能看后面的。
若为ByteTensor,非0的位置会被忽略不做注意力;若为BoolTensor,True对应的位置会被忽略;
若为数值,则会直接加到attn_weights
[src/tgt/memory]_key_padding_mask 使得key里面的某些元素不参与attention计算,三种情况同上
- output: shape:`(T, N, E)`, `(N, T, E)` if batch_first.
注意:
src和tgt的最后一维需要等于d_model,batch的那一维需要相等
例子:
>>> output = transformer_model(src, tgt, src_mask=src_mask, tgt_mask=tgt_mask)
'''
memory = self.encoder(src, mask=src_mask, src_key_padding_mask=src_key_padding_mask)
output = self.decoder(tgt, memory, tgt_mask=tgt_mask, memory_mask=memory_mask,
tgt_key_padding_mask=tgt_key_padding_mask,
memory_key_padding_mask=memory_key_padding_mask)
return output
def generate_square_subsequent_mask(self, sz: int) -> Tensor:
r'''产生关于序列的mask,被遮住的区域赋值`-inf`,未被遮住的区域赋值为`0`'''
mask = (torch.triu(torch.ones(sz, sz)) == 1).transpose(0, 1)
mask = mask.float().masked_fill(mask == 0, float('-inf')).masked_fill(mask == 1, float(0.0))
return mask
def _reset_parameters(self):
r'''用正态分布初始化参数'''
for p in self.parameters():
if p.dim() > 1:
xavier_uniform_(p)
# 小例子
transformer_model = Transformer(nhead=16, num_encoder_layers=12)
src = torch.rand((10, 32, 512))
tgt = torch.rand((20, 32, 512))
out = transformer_model(src, tgt)
print(out.shape)
# torch.Size([20, 32, 512])
到此为止,PyTorch的Transformer库我们已经全部实现,相比于官方的版本,手写的这个少了较多的判定语句。
致谢
本文由台运鹏撰写,datawhale-learn-nlp-with-transformers项目成员重新组织和整理。最后,期待您的阅读反馈和star,谢谢。