[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution
论文: https://arxiv.org/pdf/2111.09883.pdf
代码: GitHub - microsoft/Swin-Transformer: This is an official implementation for "Swin Transformer: Hierarchical Vision Transformer using Shifted Windows".
1 Introduction
在Swin Transformer的基础上,提出了以下的改进措施:
1)post normalization technique and scaled cosine attention提升大型视觉模型的稳定性;
2)log-spaced continuous position bias 进行低分辨率预训练模型向高分辨率模型迁移。
3)implementation details 大幅节省GPU显存占用以使得大视觉模型训练变得可行。
基于上述技术与自监督预训练,训练了一个包含 3 billion 参数量的SwinTransformer模型并将其迁移到不同的高分辨率输入的下游任务上,取得了SOTA性能。
Swin Transformer V2 在四个具有代表性的基准上刷新纪录:在 ImageNet-V2 图像分类任务上 top-1 准确率为 84.0%,COCO 目标检测任务为 63.1 / 54.4 box / mask mAP,ADE20K 语义分割为 59.9 mIoU,Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。
2 A Brief Review of Swin Transformer
Swin Transformer是一种通用的视觉骨干模型,在不同的视觉任务(包含图像分类、目标检测以及语义分割)上均取得了极强性能。Swin Transformer的主要思想:为常规Transformer Encoder架构引入了几个重要的视觉信号先验信息 ,包含分层、局部以及平移不变形。基础Transformer单元提供了强建模能力,视觉先验信息使其可以处理不同视觉任务。
2.1 Normalization Configuration
原始的SwinTransformer采用了常规的预归一化技术
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第1张图片](http://img.e-com-net.com/image/info8/a8aa1d24018a4468a67e8689a8725ee9.jpg)
2.2 Relative position bias
原始Swin Transformer引入了一个额外参数偏置,公式如下:

其中,B是每个head的相对位置偏置,对于dense recognition任务非常重要。当进行不同分辨率模型迁移时,常规方案是对该偏置矩阵进行双三次插值。
2.3 Issues in scaling up model capacity and window resolution
在对SwinTransformer进行容量与窗口分辨率的scaling过程中,我们发现以下两个问题:
- 扩大模型容量过程中的不稳定问题,见下图。
在大型模型中,跨层激活函数输出的幅值的差异变得更大。激活值是逐层累积的,因此深层的幅值明显大于浅层的幅值。当我们将原来的 Swin Transformer 模型从小模型放大到大模型时,深层的 activation 值急剧增加。最高和最低幅值之间的差异达到了10^4。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第2张图片](http://img.e-com-net.com/image/info8/8828fcb1eb18479ea60f9fc69664a0c3.jpg)
当我们进一步扩展到一个巨大的规模 (658M 参数) 时,它不能完成训练,如下图所示。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第3张图片](http://img.e-com-net.com/image/info8/86949a60ea204a86a42668b0d1307b55.jpg)
- 跨窗口分辨率迁移模型时的性能退化问题,见下表。
许多下游视觉任务需要高分辨率的图像或窗口,预训练模型时是在低分辨率下进行的,而 fine-tuning 是在高分辨率下进行的。针对分辨率不同的问题传统的做法是把位置编码进行双线性插值 ,这种做法是次优的。如下图3所示是不同位置编码方式性能的比较,当我们直接在较大的图像分辨率和窗口大小测试预训练的 Imagenet-1k 模型 (分辨率256×256,window siez=8×8) 时,发现精度显著下降。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第4张图片](http://img.e-com-net.com/image/info8/d42ecca7d8c947ebb56c5e13ab955518.jpg)
使用post normalization technique and scaled cosine attention解决不稳定问题;
使用log-spaced continuous position bias解决跨窗口分辨率迁移问题。
3 Method
3.1 Scaling up Model Capacity
3.1.1.Post Normalization
原始SwinTransformer的预归一化配置下,每个残差模块的输出激活值与主分支直接合并,导致主分支在更深层的幅值越来越大,进而导致训练不稳定。
为缓解该问题,我们提出了Post Normalization:每个残差模块的输出先进行归一化再与主分支进行合并,因此主分支的幅值不会逐层累积。从上面的Figure2可以看到:使用Post Normalization的模型激活幅值更温和。
在最大的模型中,我们每6个Transformer模块额外引入一个LN单元以进一步稳定训练。
3.1.2 Scaled Cosine Attention
在原始自注意力计算过程中,像素对的相似性通过query与key的点积计算。我们发现:在大模型中,某些模块与head的注意力图会被少量像素对主导 。为缓解该问题,我们提出了Scaled Cosine Attention(SCA),公式如下:

3.2 Scaling Up Window Resolution
3.2.1 Continuous Relative Position Bias
不同于直接对偏置参数直接优化,连续位置偏置方法不是直接优化参数偏差,而是在相对坐标上引入一个小的元(meta)网络:
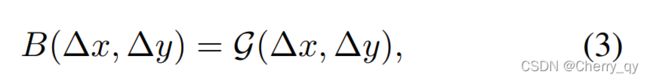
注:g是一个很小的网络,比如2层MLP中间加一个ReLU。元网络对任意相对坐标生成偏置参数,因而可以自然地进行任意窗口尺寸的迁移。在推理阶段,每个相对位置的偏置可以预先计算并保存,按照原始方式进行推理。
3.2.2 Log-space Coordinates
当变化很大的窗口大小之间迁移时,有较大比例的相对坐标范围需要外插。为缓解该问题,我们采用了log-spaced坐标:
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第5张图片](http://img.e-com-net.com/image/info8/ff3d52832cfd4dd49ef144f597ff657a.jpg)
△x和△y是线性空间的坐标
通过对数空间坐标,在进行块分辨率迁移时,所需的外插比例会更小。比如,将8*8 window预训练模型向16*16 window 迁移时,输入坐标范围从[-7,7]*[-7,7]调整为[-15,15]*[-15,15],外插比例为8/7=1.14倍。而采用对数空间坐标,输入坐标范围从[-2.079,2.079]*[-2.079,2.079]调整为[-2.773,2.773]*[-2.773,2.773],外插比例0.33倍。表1 给出了不同位置偏置下的迁移性能对比,可以看到:当向更大窗口尺寸迁移时,对数空间连续位置偏置性能最佳 。
3.3 Other Implementation
3.3.1 Implementation to save GPU memory
大分辨率输入与大容量模型存在的另一个问题是GPU显存占用不可接受问题 。我们采用了以下实现改善该问题:
- Zero-Redundancy Optimizer(ZeRO): 传统的数据并行训练方法 (如 DDP) 会把模型 broadcast 到每个 GPU 里面,这对于大型模型来讲非常不友好,比如参数量为 3,000M=3B 的大模型来讲,若使用 AdamW optimizer,32为的浮点数,就会占用 48G 的 GPU memory。通过零优化器,模型参数和相应的优化状态将被划分并分布到多个GPU,从而显著降低内存消耗,对整体训练速度影响极小;
(来自论文:Zero: Memory optimizations toward training trillion parameter models)
- Activation check-pointing:Transformer 层中的特征映射也消耗了大量的 GPU 内存,在 image 和 window 分辨率较高的情况下会成为一个瓶颈。采用checkpoint技术节省GPU占用,但会降低30%训练速度;
(来自论文:Training deep nets with sublinear memory cost)
- Sequential Self-attention computation:在非常大的分辨率下训练大模型时,如分辨率为1535×1536,window size=32×32时,在使用了上述两种优化策略之后,对于常规的 GPU (40GB 的内存)来说,仍然是无法承受的。作者发现在这种情况下,self-attention 模块构成了瓶颈。为了解决这个问题,作者实现了一个 sequential 的 self-attention 计算,而不是使用以前的批处理计算方法。这种优化在前两个阶段应用于各层,并且对整体的训练速度有一定的提升。
3.3.2 Joining with a self-supervised approach
更大的模型需要更多的数据(data hungry)。为解决该问题,之前的大模型训练通过采用额外的数据或者自监督预训练。我们对这两种策略进行了组合。
- 对ImageNet-22K进行扩大五倍达到了70M数量;
- 采用自监督训练以更好的进行数据挖掘。
通过上述训练方案,训练了一个具有3 B参数量的SwinTransformer模型并在多个基准数据集上取得了SOTA性能。
3.4 Model Configurations
我们保持与SwinTransformer相同的stage、block以及通道配置得到了四个版本的SwinTransformerV2:
- SwinV2-T: C96, layer number= {2,2,6,2}
- SwinV2-S: C96, layer number= {2,2,18,2}
- SwinV2-B: C128, layer number= {2,2,18,2}
- SwinV2-L: C192, layer number= {2,2,18,2}
我们进一步对SwinV2进行更大尺寸缩放得到了658M与3B参数模型:(每6层额外增加一个LN)
- SwinV2-H: C=352, layer number={2,2,18,2}
- SwinV2-G: C=512, layer number={2,2,42,2}
4 Experiments
Swin Transformer V2 在四个具有代表性的基准上刷新纪录:在 ImageNet-V2 图像分类任务上 top-1 准确率为 84.0%,COCO 目标检测任务为 63.1 / 54.4 box / mask mAP,ADE20K 语义分割为 59.9 mIoU,Kinetics-400 视频动作分类的 top-1 准确率为 86.8%。
SwinV2-G 实验设置:预训练采用 192×192 图像分辨率,以节省训练成本,实验采用 2-step 预训练方法:首先,在 ImageNet-22K-ext 数据集上使用自监督方法对模型进行 20epoch 的预训练。其次,在 ImageNet-1K V1 和 V2 分类任务上,继续将模型进行 30epoch 预训练。
4.1 ImageNet-1K 图像分类结果
表 2 将 SwinV2-G 模型与之前在 ImageNet-1K V1 和 V2 分类任务上的最大 / 最佳视觉模型进行了比较。SwinV2-G 是之前所有密集(dense)视觉模型中最大的。它在 ImageNet V2 基准测试中达到了 84.0% 的 top-1 准确率,比之前最好的 ViT-G (83.3%) 高 0.7%。但是,SwinV2-G 在 ImageNet-1K V1 上的准确率比 CoAtNet-7 略低(90.17% 比 90.88%)。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第6张图片](http://img.e-com-net.com/image/info8/0a9595c5a894407a9fce2bef57c8e8aa.jpg)
4.2 COCO 目标检测结果
表 3 将 SwinV2-G 模型与之前在 COCO 目标检测和实例分割任务上取得最佳性能模型进行了比较。SwinV2-G 在 COCO test-dev 上实现了 63.1/54.4 box/max AP,比 SoftTeacher(61.3/53.0) 提高了 + 1.8/1.4。这表明扩展视觉模型有利于目标检测任务中的密集视觉识别任务。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第7张图片](http://img.e-com-net.com/image/info8/e3b12d5302144a3cafc17284060b61f3.jpg)
4.3 ADE20K 语义分割结果
下表 4 将 SwinV2-G 模型与之前在 ADE20K 语义分割基准上的 SOTA 结果进行了比较。Swin-V2-G 在 ADE20K val 集上实现了 59.9 mIoU,比之前的 SOTA 结果(BEiT)58.4 高了 1.5。这表明扩展视觉模型有益于像素级视觉识别任务。在测试时使用更大的窗口大小还可以带来 +0.2 的增益,这可能归功于有效的 Log-spaced CPB 方法。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第8张图片](http://img.e-com-net.com/image/info8/d35aae8136c0438da8fce71a72ebeaad.jpg)
4.4 Kinetics-400 视频动作分类结果
下表 5 将 SwinV2-G 模型与之前在 Kinetics-400 动作分类基准上的 SOTA 结果进行了比较。可以看到,Video-SwinV2-G 实现了 86.8% 的 top-1 准确率,比之前的 SOTA (TokenLearner)85.4% 高出 +1.4%。这表明扩展视觉模型也有益于视频识别任务。在这种场景下,在测试时使用更大的窗口大小也可以带来额外增益 ( +0.2% ),这也要归功于有效的 Log-spaced CPB 方法。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第9张图片](http://img.e-com-net.com/image/info8/7a9f1d85be3a4b0f8580dfa2f7f30820.jpg)
5 Ablations
post-norm 和缩放余弦注意力的消融实验:下表 6 展示了 post-norm 和缩放余弦注意力方法应用于原始 Swin Transformer 方法的性能表现。可以看到,这两种方法都提高了 Swin-Tiny、Swin-Small 和 Swin-Base size 的准确率,整体提升分别为 +0.2%、+0.4% 和 +0.5%,表明它们对更大的模型更有益。
![[Transformer] Swin Transformer V2: Scaling Up Capacity and Resolution_第10张图片](http://img.e-com-net.com/image/info8/0509b16149854d2e96d36bfa761eeee6.jpg)