GrowingIO AWS 成本优化之路
作者:邢建辉 GrowingIO 运维开发工程师,主要负责平台化,自动化方向的设计与开发。
背景
营收和成本是任何一家企业都需要关注的问题。
当一家互联网公司发展到一定规模时,服务器成本会变成一项重大的开支,优化服务器成本也将变成一件提上日程的任务。GrowingIO 主要服务运行在 AWS 上,下面主要针对 GrowingIO 在 AWS 上的一些优化。
成本分析
1. 概览分析
在开始成本优化之前,需要先做规划,通过规划来确定实施方案,而不是拍脑袋直接去做,这样可能最后就是花了很大力气,成本降低的效果却不是很明显。
做规划需要通过数据做依据,通过数据分析来确定优化的优先级,例如哪些优化方案会使总体成本下降最快,哪些成本花费的并不合理。下图为 AWS 中的账单中一些概览。
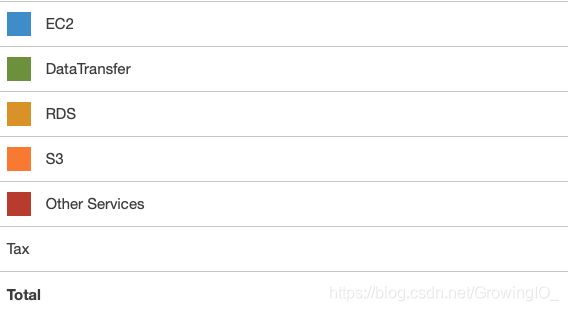
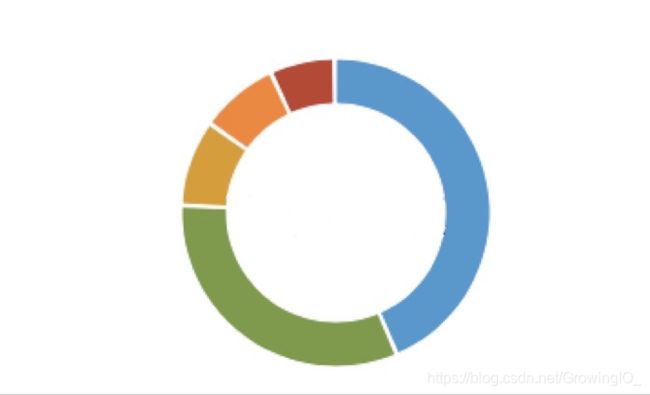
通过 AWS 的账单概览中我们可以发现费用排名依次为 EC2,DataTransfer 等,下面针对 EC2,DataTransfer 等我们需要做账单的详细分析。
2. 细节分析
数据收集
AWS 的账单中只能做到对总体的一个概览,例如只显示到 c5.xlarge 机型的 Reserved Instances 和 On Demand 的花费,而流量费用也只显示到 out of CNN1 的总数,这些信息只能让我们总体的看到费用的大致花费构成,对于庞大的资源,这些信息并不能帮助我们精准定位到优化具体资源上。
这里我们通过 Cost Management Preferences 中将详细账单文件保存到 S3 中,账单中的详细信息 https://docs.aws.amazon.com/cur/latest/userguide/detailed-billing-migrate.html
数据标签
这里需要说明的是在做详细账单时最好提前将 AWS 的所有资源打上统一 tag,我们根据自己的情况打了主要如下四个标签:
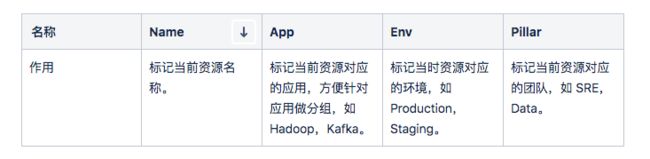
打完标签后需要将 AWS 的账单中的 tag 激活,否则生成的详细账单中不会包含 tag 信息,具体步骤为在 AWS 账单页面的 cost allocation tags 中将对应 tag active,这样在生成的账单文件中会包含 active 的 tag,如 user:App 等类似字段。
数据可视化
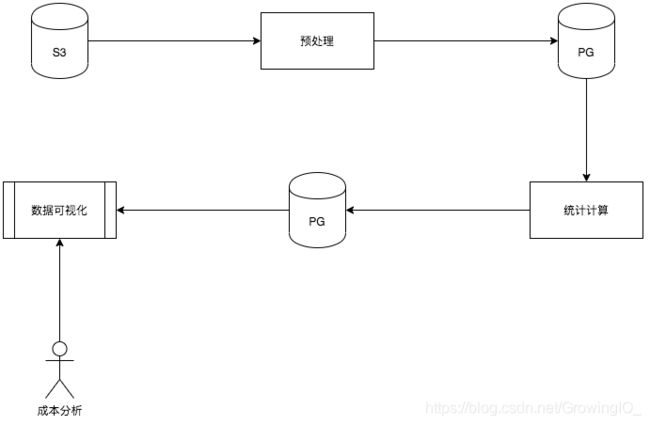
GrowingIO 通过 Azkaban 任务自动化对账单数据进行可视化,流程大致如下。
-
预处理阶段,将账单文件导出,并进行拆分与清洗后存入 PG 中。
-
统计计算阶段,对于预处理中的原始数据进行按团队,应用等维度进行聚合计算后存入到 PG 中。
-
数据可视化阶段,通过 Grafana 等图形工具对统计后的数据做图形展示。
通过数据可视化基于 App(服务类别),AWS:Usage(费用类别),Env(环境)等维度,进行费用的排序,这样可以使我们比较直观的找到费用较高的花费。
例如对于应用的维度,发现 Hadoop 的成本是最高的,而 Hadoop 的存储,计算等维度使用量也是排名靠前,那么第一优化的就是 Hadoop 的存储和计算。
下面是部分的展示图表,分别展示了 S3 的各 Bucket,各应用服务,各 ELB 的费用等部分信息(费用列由于比较敏感,已被隐藏)。


只有账单的结果还不够,我们还需要根据监控的数据来做实际使用情况的计算,例如可以导出一段时间内的 CPU,内存,磁盘的平均值,95 分位,方差等数值,并将账单和监控数据进行聚合来获取资源的真实使用情况,例如 Hadoop 的计算,内存使用率都比较高,毛峰一般出现在整点计算,Kafka,Hadoop,API 的磁盘使用量和吞吐量较大,但是 IOPS 并不高,API 的流量较高等情况。
通过这些数据,我们可以开始有针对性的做成本优化。
针对性优化
1. EC2 计算实例优化
EC2 收费模式
在开始 EC2 的优化前我们需要熟悉一下 AWS EC2 的一些收费模式。
- AWS 对于实例收费分为 Reserved Instance(RI) 和 On Demand(OD) 两种方式,其中 RI 为用户向
AWS 承诺使用某一机型一段的时间,同时 AWS 会给出相应的折扣,一般情况下 RI 相比 OD 都会节省
60%多的费用,所以对于稳定且运行时间较长的业务一定要选择 RI。 - 不同代的机型收费不一样,例如 RI 中 m5.xlarge 的 ¥516.11/月与 m4.xlarge 的
¥764.12/月对比节省了大约 32.5%,所以要关注不同代机型的价格,基本都是最新一代的比上一代的便宜,升级过程中需要注意
kernel 版本较低的需要先升级 kernel 再替换机型,否则更换机型会失败。 - t3 系列机型的计费使用积分方式,如 CPU
空闲时积分,忙时消耗积分,总的使用不到一定分数的情况则不额外收费,对于业务有峰值,但平时使用较低的推荐使用 t3 系列,t3
计费详细模式为https://aws.amazon.com/cn/about-aws/whats-new/2018/08/introducing-amazon-ec2-t3-instances/ - 对于机型的选择一定要根据服务的特性来选择,不同机型的实例价格差距比较大,下面列了一些机型的价格对比和使用场景,机型中的 a 代表
AMD。
EC2 实例费用的可优化检测
- 针对 AWS 中 RI 和 OD 的特性,并且新一代相比老一代的机型费用降低的情况,我们做了如下的功能。
- 根据 RI 的实例类型和数量对比实际使用的实例类型和数量计算得出当前需要预留的实例类型。
- 根据 RI 的过期时间计算出未来一段时间陆续到期的 RI 机型。
- 通过机型的价格对比(如 m3,m5 和 t3)和监控中的资源使用情况计算,得出实例可使用的机型,并且给出对应的费用情况。
举个例子,自动推荐计算出当前 kafka01 节点的预留实例还有 7 天时间将会到期,并且 kafka01 使用的是 m3.xlarge 机型, 同时发现 kafka01 CPU 平均使用率并不高。则发出通知,kafka01 的预留实例 m3.xlarge 7 天后将到期,当前费用 xxx/月,使用 m5.xlarge 费用 xxx/月,t3.xlarge 费用 xxx/月。
Yarn 计算资源的优化
从之前的分析来看 Hadoop 中 Yarn 的计算成本是最大的一块,针对 Yarn 我们做了如下的一些事情。
- 合并 Spark 任务,减少 driver 的数量
Spark On Yarn 分为 client 和 cluster 两种模式,cluster 模式中 driver 会跑在 yarn application master 上,目前我们在使用的大部分都是 cluster 的模式,由于现在 spark 任务较多,这样会导致同时启动大量的 driver 来进行任务的管理,由于 driver 对于资源的使用率并不高,这样就会导致一定的资源浪费,所以我们将一些资源较小的任务进行合并进而减少 driver 的数量。
- 根据实际使用量,适当降低任务请求的资源数量
- 优化数据模型,加快计算速度,降低资源使用量
- 升级 AWS 机型,降低 EC2 使用成本
通过数据上面机型的对比,我们决定将 Nodemanager 的机型从 m3 和 m4 切换到 m5,根据计算总体计算成本大概会降低 30%+,在机型变更的过程中要考虑 RI 的到期情况,否则花双份钱就得不偿失了。
资源使用不充分的实例优化
GrowingIO 是一家针对企业提供数据服务的公司,所以产品的流量也主要集中在数据采集和计算这块,面向用户这块会有部分服务的压力不是很高,但是同时又要保证服务的高可用而部署至少双节点。
针对这种情况并结合上方针对 AWS 的机型分析,我们对这部分服务采用了 t3 的机型,一方面费用较低,另一方面 t3 机型可以针对短时的业务压力可以具备一定的计算能力,没有采用 t3a 的原因是 t3a 相比 t3 的计算能力下降 20%而价格只便宜了 10%,导致我们认为 t3a 的性价比并不高。
2. EBS 存储优化
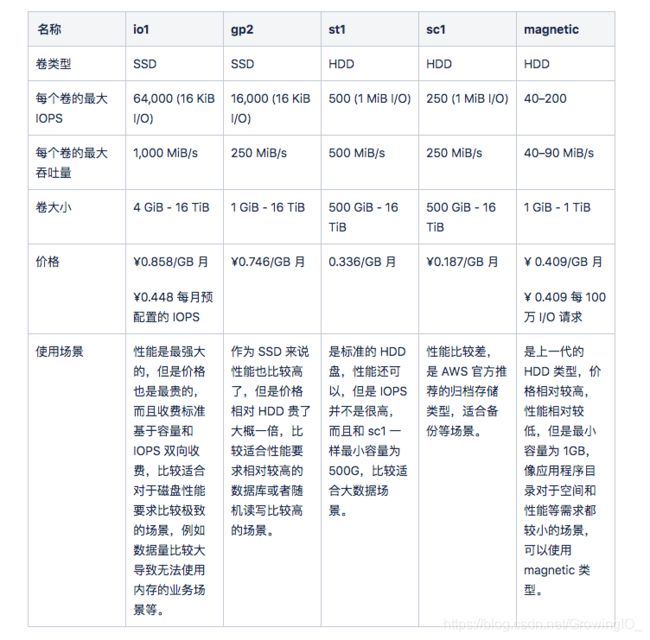
EBS 类型和收费对比
我们在来看一下 AWS 的 EBS 类型和性能,以下部分引用官方数据。
HDFS 存储优化
前面已经对 Hadoop 的计算做过了优化,HDFS 的存储也是成本的大头。
下面根据监控和数据端同事提供的数据分析可以得出一些以下结论。
- 磁盘的 IOPS 只有在小时任务运行时比较高,平时相对较低。
- 最近 XX 天的数据访问频率较高。
- 大于 XX 个月的历史数据的访问频率非常低。
根据以上现象我们可以发现 HDFS 不同的数据对磁盘的需求并不一样。
可以总结出数据类型分为 Hot,Standard 和 Archive。
分析完了 HDFS 的存储特性,这时需要引入 HDFS 的 Storage Types 的特性了,链接 https://hadoop.apache.org/docs/r2.7.2/hadoop-project-dist/hadoop-hdfs/ArchivalStorage.html
这里 HDFS 的存储类型分为 RAM_DISK,SSD,DISK 和 ARCHIVE。
RAM_DISK 使用基于特定场景,根据实际业务判断是否需要。而对于 SSD,DISK 和 ARCHIVE 则分别对应上方的 Hot,Standard 和 Archive 的不同场景。
这里我们选择了 gp2,st1 和 sc1 分别对应 Hot,Standard 和 Archive 的业务场景。
最后根据规划将 HDFS 的磁盘转成不同的磁盘类型。
这里说一下 AWS 比较强大的功能,磁盘类型的在线转换,例如 gp2 可以直接转成 st1 类型的同时提供服务,但是在类型转换时有 6 小时的冷却期。
其他方面的一些优化
- 例如 Kafka,API 等顺序读写的场景,如果之前使用的是 gp2 磁盘,那么统一替换成 st1 类型的磁盘。
- 在 EBS 的类型对比中我们发现 Magnetic
是比较适合磁盘大小和性能都要求不高的场景,例如程序放置目录,所以这一波中将这种类型的磁盘统一替换成 Magnetic 类型。
3. 流量优化
流量收费模式
- NAT 网关使用费用 ¥0.427/小时,同时数据处理费用为 ¥0.427/GB。
- 数据自 AWS 传出到 Internet 费用为 ¥0.933/GB。
- 数据自 Internet 出入到 AWS 费用为 ¥0.000/GB。
- 使用公有或弹性 IP 的费用 ¥ 0.067/GB。
- 数据跨 Region 费用为 ¥0.067/GB。
HTTP2.0 Header 压缩
在开始具体流量优化之前,我们先来简单的介绍一下 HTTP2.0 的 Header 压缩技术。
HTTP2.0 针对现在每个网页大量的 HTTP 请求而导致大部分流量都消耗在 HTTP Header 上的情况增加了 Header 压缩,具体可以参考 https://httpwg.org/specs/rfc7541.html,原理大致为服务端和客户端同时维护一份固定静态表和一份动态表,通过传输过程中只传输对应 Header 的索引来达到优化流量的目的,并且 HTTP2.0 协议向下兼容。
服务流量的优化
GrowingIO 是国内领先的数据驱动增长解决方案供应商,流量费用也十分非常庞大。
由于 GrowingIO 服务场景的特殊性,以下方法并不完全适合所有公司。
首先我们先分析一下服务流量的场景和特性。
- 大部分流量为进站请求,出站的请求携带数据量较小。
- 出站的流量大部分为 TCP 和 HTTP 的 Header 数据。
- AWS 的流量只计算出站流量费用,入站的免费。
针对以上的情况,我们对于进站的流量不需要关心,注意力主要集中在出站流量上即可。
根据上面介绍的 HTTP2.0 Header 压缩的特性,我们决定将服务切换到 HTTP2.0,经过一定测试后,我们将 AWS ELB 替换成 Application Load Balancer 模式后默认会开启 HTTP2.0,根据后期的观察出站流量也确实下降了有 30%+。
4. S3 可以优化的方面
S3 为 AWS 的对象存储,根据每个公司的业务用法并不一样,这里简单说一下 S3 使用时可能带来额外费用的地方:
- 尽量将 S3 和 EC2 放在同一 Region 中,否则 S3 和 EC2 之间的传输将产生流量费用。
- 如果将 S3 作为静态 web 服务器,并且流量较大,建议将 S3 作为 CDN 源站,S3 对于互联网的请求流量和请求次数同时收费。
- 除非明确的归档和备份文件,尽量不要选择 Glacier 类型,在访问 Glacier 对象时费用非常高昂。
- 定期清理不再需要的文件。
未来可做的事情
-
后期还可以针对 API 的 Response Header 进行一些裁剪,将 Header 进行优化,从而进一步降低出站的流量。
-
使用 Auto Scaling 功能将一些服务进行动态伸缩,从而将资源使用分配更为合理。
-
将一些服务搬到 Kubernetes 上进行更合理的资源分配。
-
根据业务团队将账单详细拆分,将账单跟监控数据关联做成自动化,定期生成报告并进行 review 从而推动整个团队的成本意识。
总结
对于成本优化,每个公司具体的优化措施需要针对具体的业务场景来制定方案,以上只是列出了一些 GrowingIO 在成本优化时一些通用的点。成本优化是一个平衡的过程,在成本,性能,稳定性,系统冗余中相互均衡后的一个结果,并且是一个长期战斗。
关于 GrowingIO
GrowingIO 是国内领先的数据驱动增长解决方案供应商。为产品、运营、市场、数据团队及管理者提供客户数据平台、获客分析、产品分析、智能运营等产品和咨询服务,帮助企业在数据化升级的路上,提升数据驱动能力,实现更好的增长。
点击「此处」获取 GrowingIO 15 天免费试用!