性能优化是个十分广泛的话题,它涉及 CPU、内存、磁盘、网络等方面。MegEngine 作为一个训推一体的深度学习框架,也在持续不断探索性能优化的最优解。
本篇整理了 Bot 过往发布的相关文章,希望能帮助大家更好的理解和掌握 MegEngine 使用技巧。
工欲善其事必先利其器
学会使用性能评测工具
提到性能优化,笔者认为性能优化人员的技术水平大概可被分为以下三类:
- “瞎着写“。这类技术水平的人员一般不会在意其他,遇事先上”三板斧“,如循环展开,向量化,指令重排。性能好往往也不知其所以然,性能不好也没有什么后续的优化思路。
- ”摸着写”。这类技术水平的人员与第一类的一个显著的分水岭是学会使用性能评测工具,通过工具能够摸到程序的瓶颈在何处,然后进行对应的优化。
- ”瞄着写“。这类人员有了量化分析程序性能的能力。当面临同一个程序的多种写法时,能够做到即使不真实实现程序,也能较为精准的算出来哪种写法性能更好。
需要注意的是以上三类人员所用的技术是逐级包含的关系,例如第三类人员同样掌握性能评测工具的使用方法和”三板斧“式的优化方法。正所谓工欲善其事必先利其器,其实只有达到第二类的水平,性能优化人员才初步具有独立优化能力,所以性能评测工具的掌握至关重要。如果你对性能优化中一些基本概念还不够了解,且对以下问题也有相同的疑问:
- Python 及 C/C++ 拓展程序的常见的优化目标有哪些;
- 常见工具的能力范围和局限是什么,给定一个优化目标我们应该如何选择工具;
- 各种工具的使用方法和结果的可视化方法;
《profiling 与性能优化总结》将会是一个很好的总结性材料。
学会基本的性能优化方法论
学会了使用性能评测工具之后,还需要了解基本的性能优化方法论,然后就基本具有独立优化能力了。性能优化很多时候就是不断迭代的过程:
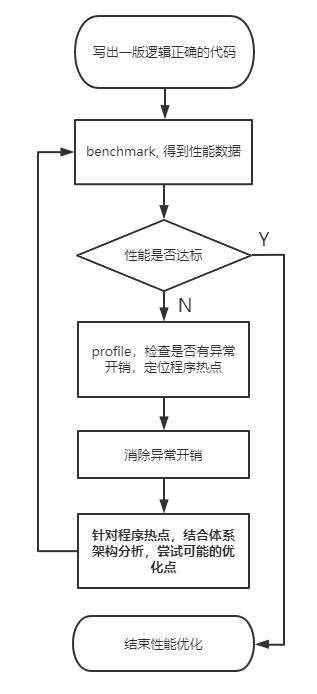
以 ARM Cortex a55 上的 GaussianBlur 优化为例,一起看《ARM 算子性能优化上手指南》
作为深度学习框架,模型训练速度很重要
解决零碎算子时间占比高的问题
众所周知,很多深度学习模型中都有类似 element-wise 的散碎操作。例如加减乘除算术运算和神经网络中的激活函数,以及 BatchNormalization 在模型推理的时候一般也被优化成一系列的 element-wise 操作。
这些散碎的操作具有计算访存比低的特点,即其计算量较低但是访存量较高,是一种典型的内存受限(memory bound)的操作。算子融合(kernel fusion)是针对内存受限的算子的常见优化手段。但是这些散碎算子的计算模式众多,这些计算模式相互组合将会是指数级别的,依靠手工写代码进行针对性优化是不现实的。MegEngine 通过引入 JIT 和自动代码生成技术解决计算模式组合爆炸的问题,从而享受到 kernel fusion 带来的性能收益,详见《JIT in MegEngine》。
提升多机多卡训练效率
从 2080Ti 这一代显卡开始,所有的民用游戏卡都取消了 P2P copy,导致训练速度显著的变慢。针对这种情况下的单机多卡训练,MegEngine 《利用共享内存实现比 NCCL 更快的集合通信 》算法,对多个不同的网络训练相对于 NCCL 有 3% 到 10% 的加速效果。
MegEngine v1.5 版本,可以手动切换集合通信后端为 shm(默认是 nccl),只需要改一个参数。
gm = GradManager()
gm.attach(model.parameters(), callbacks=[dist.make_allreduce_cb("sum", backend="shm")])
# 目前只实现了单机版本,多机暂不支持作为一个训推一体的框架,推理速度同样重要
云侧
GPU CUDA 矩阵乘法
单精度矩阵乘法(SGEMM)几乎是每一位学习 CUDA 的同学绕不开的案例,这个经典的计算密集型案例可以很好地展示 GPU 编程中常用的优化技巧,而能否写出高效率的 SGEMM Kernel,也是反映一位 CUDA 程序员对 GPU 体系结构的理解程度的优秀考题。
在《CUDA 矩阵乘法终极优化指南》一文中,详细介绍了 CUDA SGEMM 的优化手段,适合认真阅读过 《CUDA C++ Programming Guide》 、具备一定 CUDA 编程基础的同学阅读。
TensorCore 卷积算子实现
2020 年 5 月 Nvidia 发布了新一代的 GPU 架构安培(Ampere)。其中和深度学习关系最密切的莫过于性能强劲的第三代的 TensorCore ,新一代的 TensorCore 支持了更为丰富的 DL(Deep Learning)数据类型,包括了新的 TesorFloat-32(TF32),Bfloat16(BF16)计算单元以及 INT8, INT4 和 INT1 的计算单元,这些计算单元为 DL 推理提供了全面的支持。为了发挥这些计算单元的能力,以往会由资深的 HPC 工程师手写 GPU 汇编实现的卷积、矩阵乘算子来挖掘硬件的能力。然而凭借人力手工优化算子的方式已经没有办法应对如此多的数据类型,因此对于 DL 应用的优化渐渐地越来越依赖一些自动化的工具,例如面向深度学习领域的编译器。在这样的趋势下,Nvidia 开发了线性代数模板库 CUTLASS ,抽象了一系列高性能的基本组件,可以用于生成各种数据类型,各种计算单元的卷积、矩阵乘算子。
MegEngine 在 CUTLASS 的基础上进行了二次开发,可以高效地开发新的高性能的算子,快速地迁移到新的 GPU 架构。一文看懂 《MegEngine CUDA 平台的底层卷积算子的实现原理》。文中还有对 Nvidia CUTLASS 的 Implicit GEMM 卷积文档进行解读和补充。
端 & 芯侧
CPU 卷积常见优化手段
卷积计算优化作为 CV 模型推理性能优化中最重要的一项工作,CPU 上 Inference 中有关卷积的优化有很多的途径。
MegEngine 通过实现 Im2col+matmul 卷积以及 Winograd 卷积中的一些进一步优化的技术手段,进一步加速了卷积计算的性能,从而加速整个模型的 Inference 性能。
如在 Float32 的经典网络开启相关优化后,在骁龙 855 上的测试速度为:
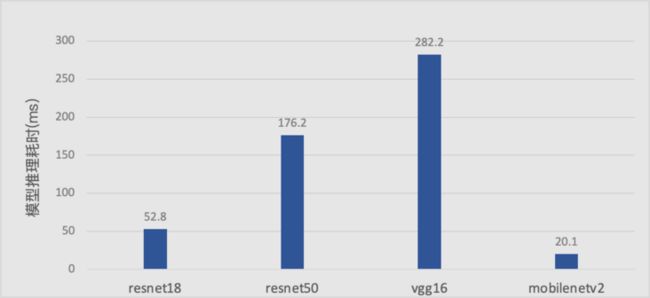
有关 Im2col 和 Winograd 算法的实现以及优化方法,见《MegEngine Inference 卷积优化之 Im2col 和 winograd 优化》
从数字信号领域获得的启发
在数字信号和数字图像领域, 对频域的研究是一个重要分支。 我们日常“加工”的图像都是像素级,被称为是图像的空域数据。空域数据表征我们“可读”的细节。如果我们将同一张图像视为信号,进行频谱分析,可以得到图像的频域数据。实现图像空域和频域转换的工具,就是傅立叶变换。由于图像数据在空间上是离散的,我们使用傅立叶变换的离散形式 DFT(Discrete Fourier Transform)及其逆变换 IDFT(Inverse Discrete Fourier Transform)。Cooley-Tuckey 在 DFT 的基础上,开发了更快的算法 FFT(Fast Fourier Transform)。
DFT/FFT 在深度学习领域也有延伸应用。 比如利用 FFT 可以降低卷积计算量的特点,FFT_Conv 算法也成为常见的深度学习卷积算法。
适配移动端 CPU 的场景
理论优化时,我们总会选择更好的设备去计算理论上限。但在实际应用时,算力较弱的移动设备,如何承载模型推理的运算?
一般认为,让模型运行于 GPU 上会比运行于 CPU 上具有较大的优势,取得可观的性能提升。这通常是真实情况,但是,在工程实践中我们也发现,对于某些模型维度较小的模型,在移动设备上,GPU 运行并没有带来性能的提升,而且还额外引入了兼容性的问题。所以,在某些应用场景下,我们需要以 CPU 为运行载体,尝试各种方法,以提升模型推理性能。
在《基于 MegEngine 移动端 CPU 的深度学习模型推理性能优化》一文中,作者总结了自己在工程实践中,基于 MegEngine 推理引擎,发现的 2 有效的优化方法“NCHW44 和 Record”的原理及使用方法做了详细说明。
如果你在 MegEngine 的使用过程中也有自己独特的技巧,欢迎联系 Bot(微信号:megengine-bot)投稿,还有多种社区周边相送哦~
相比于性能,易用性也不可或缺
Fast-Run 算子自动选择框架
为解决实际生产条件下,用户的 NN 网络千差万别的情况。在同一类数学计算中,开发者们会开发多种高效的算法,分别适用于不同的参数,以保证网络的性能。接下来开发者们需要解决一个新问题,当计算参数确定以后,如何让最快的算法执行该计算。
大部分框架靠先验的经验选择算法,MegEngine 亦总结有优秀的先验经验值,实现计算时自动选择算法。但是依靠经验不能保证一定选择了最快的算法。很多实际场景中,用户希望网络有最极致的性能。为此,MegEngine 设计了专门的流程 - Fast Run,可以为每个计算自动选择最快的算法,从而保证整个网络的运行时间最短。
原理及使用方法见《Fast Run:提高 MegEngine 模型推理性能的神奇功能》
全局图优化自动选择张量排布格式
为了在不同的应用场景上都能表现出不错的性能,MegEngine 中的张量(Tensor)具有不同的排布格式(Format),不同存储格式在不同的输入数据和不同硬件平台上的性能也不相同。全局图优化从整个模型的角度决策模型的哪一部分转换成哪种存储格式能使得整个模型的性能最优,避免给用户带来繁杂的选择和权衡从而导致额外的心智负担。同 Fast Run 一样,全局图优化也是可选择开启的优化选项。
在 int8 模型上,经过全局图优化和 MegEngine 原 Format 优化方法(传统图优化)的推理时间表现对比如下图:

全局图优化能解决哪些问题?如何使用?以及底层技术原理解析。可以看:《全局图优化:提升 MegEngine 模型推理性能的又一神器》
【很重要的补充说明】
在 Bot 把这篇内容给技术同学看的时候,被投诉:以偏概全!
据他们说:以上提到的技术点,绝对不是开源至今所有的重点工作;还有更多性能优化工作,只是没有被整理成文章而已。
所以,欢迎大家留言自己感兴趣的内容方向,在线催更~~
附
GitHub:MegEngine 旷视天元 (欢迎 star~
Gitee:MegEngine/MegEngine
MegEngine 官网:MegEngine-深度学习,简单开发
欢迎加入 MegEngine 技术交流 QQ 群:1029741705