Transformer:SegFormer个人总结
文章目录
- 前言
- 一、创新点
- 二、算法原理
-
- 2.1 总体框架
- 2.2 分层的Transformer结构
-
- 2.2.1 Hierarchical Feature Representation
- 2.2.2 Overlapped Patch Merging.
- 2.2.3 Efficient Self-Attention
- 2.2.4 Mix-FFN
- 2.3. 轻量级MLP解码器
- 2.4. Effective Receptive Field Analysis
- 2.5 网络整体框架
- 2.6 消融实验
-
- 2.6.1 模型尺度的影响:
- 2.6.2 MLP中间层的维数影响:
- 2.6.3 Mix-FFN和位置编码的对比实验:
- 2.6.4 ERF的评估
- 三、mmseg代码
-
- 3.1 定义编码器 mit_b5代码
- 3.2 MixVisionTransformer模块代码
- 3.3 OverlapPatchEmbed代码
- 3.4 block代码
- 3.5 Attention模块代码
- 3.6 MLP模块代码(用在MixFFN)
- 4.7 MLP解码器
- 3.8 输出结果
前言
本篇文章仅是个人经过阅读原文和相关博客后的简单总结,其中的理解可能有误,望各位大佬批评指导。
参考资料如下:
论文:
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
EnzeXie 的知乎解读
作者:Enze Xie
参考博客:
SegFormer论文记录(详细翻译)
SegFormer中位置编码position encoding的问题记录
作者:Z_at_here
参考博客:论文阅读|Non-local Neural Networks非局部操作self-attention
作者:可爱甜妹
一、创新点
在本篇文章中主要提出了两个创新点,分别是
- 提出了一种分层的Transformer结构。
1.1 可以产生高分辨率的浅特征和低分辨率的精细特征。
1.2 剔除了位置编码模块,采用3x3的卷积来表示位置信息。 - 提出一个轻量级的MLP解码模块。
二、算法原理
2.1 总体框架
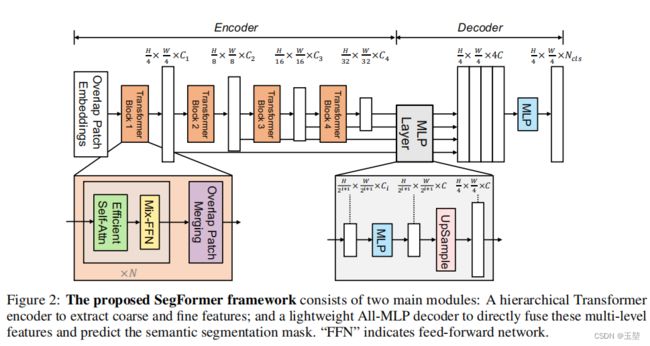
网络模型总体由编码器和解码器两部分组成。其中编码器是论文作者提出的分层Transformer模块组成,用于提取高分辨率浅层特征和低分辨率精细特征。解码器则是使用MLP组成。
2.2 分层的Transformer结构
相比于SETR,Swin等其他Transformer架构的网络,Segformer更强调鲁棒性,有效性。即可以对抗图像干扰,又可以速度快,精度高。由于SETR只能产生单尺度的特征图,这样无法有效的联系上下文信息,对于语义分割任务十分不利,因此,Segformer针对语义分割任务,专门设计出一系列MixTransformer(B0-B5)的主干网络,用于提取多尺度特征。
2.2.1 Hierarchical Feature Representation
为了获取类似CNN的多尺度特征,论文作者基于ViT论文中划分Patch的方法来进行Patch merging(即将 N x N x 3的patch,转化为1 x 1 x c的向量)。通过把 2 x 2 x Ci的特征向量,转化为1 x 1 x Ci+1的特征向量,可以获取分层的特征表示。其实可以理解为kernel为2,stride为2, padding为0的卷积。h x w->h/2 x w/2。
原文:

2.2.2 Overlapped Patch Merging.
根据ViT的划分方式,patch和patch之间是不重叠的,这样无法获得patch之间的局部连续性。因此,论文作者分别通过设置K,S,P为(7,4,3)(3,2,1)的卷积来进行重叠的Patch merging。其中,K为kernel,S为Stride,P为padding。
原文:

2.2.3 Efficient Self-Attention
论文作者认为,网络的计算量主要体现在自注意力机制层上。为了降低网路整体的计算复杂度,论文作者在自注意力机制的基础上,添加的缩放因子R,来降低每一个自注意力机制模块的计算复杂度。
[此处的操作,我没有理解其具体原因,只知道是这么做]
传统的自注意力机制原理,如下公式所示:
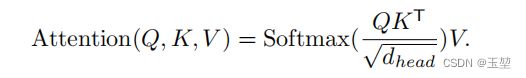
此时,自注意力的计算复杂为O(N^2)。论文作者在此的基础上,添加缩放因子R。具体操作为:
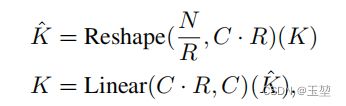
可以看出,论文作者的改进主要有两个步骤,第一个是reshape操作。原始的自注意力机制中的Q,K,V都是NxC的特征图,其中N是所有Patch的数量,C是每个Patch对应的维度。论文作者通过reshape操作把NxC的特征图,转化为(N/R x C·R)的特征图,然后在经过一个全连接层,把(N/R x C·R)转化为(N/R x C)。 从Transformer Block1到Transformer Block4中,Transformer Block的缩放因子分别为【64,16,4,1】。
原文:

2.2.4 Mix-FFN
ViT中使用位置编码来确定每个Patch的位置,但是位置编码从开始训练后,其编码就已经固定。这就导致,如果测试的时候,给出一个不同分辨率的图片,位置编码就会做插值处理,导致精度下降。对此,论文作者在文中分析的出,语义分割任务对于位置编码是不必要的,仅仅通过3x3的卷积就足以动态表达patch间的位置关系。论文作者考虑到0填充对位置的影响【此处我不太理解】,直接将3x3的卷积放入前馈网络中,组成Mix-FFN(mix feed-forward network)。
原文:

具体公式如下:

注:语义分割任务不需要位置编码的理解可以参考博客Z_at_here的SegFormer中位置编码position encoding的问题记录,我觉得挺有道理的。简单总结就是:语义分割任务是像素级别的分类,而位置编码对于像素级别的分类影响可以忽略不记。并且,语义分割任务对于分类和检测任务具有平移不变性,即图像的尺度、角度变化对于不影响输出结果。
2.3. 轻量级MLP解码器
论文作者提出轻量级MLP解码器,避免了冗余的计算。仅仅通过少量的计算就能达到很好的效果。实现这样一个简单的解码器的关键是,分层Transformer编码器比传统的CNN编码器具有更大的有效接受域(ERF)。
MLP解码器,主要分为4步。
-
将输出的4个特征图统一到维数C。
【h/4 x w/4 x c1,h/8 x w/8 x c2,h/16 x w/16 x c3,h/32 x w/32 x c4 ==> h/4 x w/4 x C,h/8 x w/8 x C,h/16 x w/16 x C,h/32 x w/32 x C】
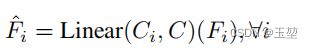
-
将4个特征图统一上采样到H/4 x W/4 x C,并cat到一起变成H/4 x W/4 x 4C。

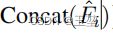
-
将H/4 x W/4 x 4C通过MLP层转化为H/4 x W/4 x C
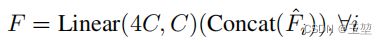
-
使用MLP层进行分类。
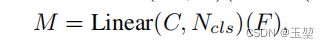
原文:

2.4. Effective Receptive Field Analysis
保持较大的感受野以获取更多的上下文信息一直是语义分割的核心问题。论文作者使用有效感受野ERF作为一个可视化和解决的工具来说明为什么MLPdecoder优异。结果图如下:

论文作者,在文中指出MLP效果很好的原因是:
- CNN中有限的感受野需要借助context模块,如ASPP。这些模块扩大了感受野,但不可避免地使模型变得复杂。Segformer的解码器设计受益于Transformer的非局部注意,可以产生一个更大的感受野而不复杂。同样的解码器设计并不能很好地适用于CNN主干,因为在stage4中,CNN的感受野远小于Transformer的感受野。
- 更重要的是,Segformer的解码器设计本质上利用了Transformer的induced feature,同时产生局部和非局部的注意特征。通过统一它们,编码器在增加少量参数的情况下来实现互补和强大的表现。
原文:

2.5 网络整体框架

K使kernel
S是Stride
P是Padding
C是维数
R是每个自注意力机制的缩放因子
N是自注意力机制的head数量
E是前馈层的膨胀率(mlp中间层维数的缩放系数,后面代码的mlp_ratios参数,中间层的维数大小为mlp_ratios * embed_dims)
L是每个Transformer Block中encoder(ESA+MixFFN)数量。
原文:

2.6 消融实验
2.6.1 模型尺度的影响:
Segformer的解码器的参数量很小,但效果表现很强。
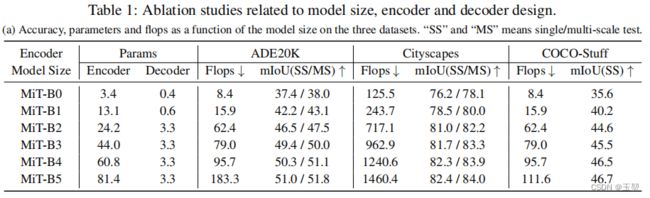

2.6.2 MLP中间层的维数影响:
对于B0而言C=256效果最好,B1-B5,C=768效果最优
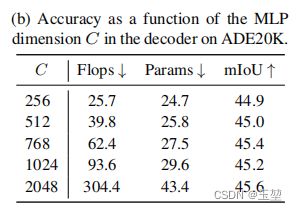
原文:

2.6.3 Mix-FFN和位置编码的对比实验:
训练阶段的cityscapes的分辨率为1024x1024。下图表示在测试图片分辨率于训练图片不一致的情况下,Mix-FFN和位置编码的影响。可以看出,在测试图片分辨率改变的情况下,明显Mix-FFN的适应性更优于位置编码(PE)。并且,在分辨率改变的情况下,Mix-FFN对于mIOU的衰减低于PE。

原文:

2.6.4 ERF的评估
MLP-decoder受益于transformer的原因,相较于CNN有更大的感受野。对此,论文作者做出了如下实验,分别在CNN主干网络后加MLP解码器和Transformer主干网络后加MLP解码器。从实验结果可以看出,相比较于使用CNN的backbone来说,本文提出的Transformer Encoder的精度更高。体现出CNN有较小的感受野,而Transformer拥有较大的感受野。

原文:


三、mmseg代码
简单记录下,我查看mmseg中的代码。仅记录,不做过多解释,因为还没看懂(捂脸)
mmseg中的代码:
3.1 定义编码器 mit_b5代码
@BACKBONES.register_module()
class mit_b5(MixVisionTransformer):
def __init__(self, **kwargs):
super(mit_b5, self).__init__(
# 划分patch的大小
patch_size=4,
# 4个stage中输出的维数Channel。
embed_dims=[64, 128, 320, 512],
# 4个stage的head数量。
num_heads=[1, 2, 5, 8],
# mlp中间层维数的缩放系数。[=mlp_ratios * embed_dims]
mlp_ratios=[4, 4, 4, 4],
# 全连接层的bias
qkv_bias=True,
# 设置LN层的参数
norm_layer=partial(nn.LayerNorm, eps=1e-6),
# 4个stage中encoder的数量。
depths=[3, 6, 40, 3],
# 4个stage的缩放因子。
sr_ratios=[8, 4, 2, 1],
# Dropout层的参数。
drop_rate=0.0,
# DropPath层的参数。
drop_path_rate=0.1,
# 输入图像维数。【这个是我自己加的,为了输入4通道数据】
in_chans=kwargs['in_chans'])
3.2 MixVisionTransformer模块代码
OverlapPatchEmbed 是用来做PatchMerging的
block 是用来做Transformer_block的。
class MixVisionTransformer(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_chans=3, num_classes=1000, embed_dims=[64, 128, 256, 512],
num_heads=[1, 2, 4, 8], mlp_ratios=[4, 4, 4, 4], qkv_bias=False, qk_scale=None, drop_rate=0.,
attn_drop_rate=0., drop_path_rate=0., norm_layer=nn.LayerNorm,
depths=[3, 4, 6, 3], sr_ratios=[8, 4, 2, 1]):
super().__init__()
self.num_classes = num_classes
self.depths = depths
# ------------------------------------------------------------------------
# patch_embed
# ------------------------------------------------------------------------
self.patch_embed1 = OverlapPatchEmbed(img_size=img_size, patch_size=7, stride=4, in_chans=in_chans,
embed_dim=embed_dims[0])
self.patch_embed2 = OverlapPatchEmbed(img_size=img_size // 4, patch_size=3, stride=2, in_chans=embed_dims[0],
embed_dim=embed_dims[1])
# ------patch_embed3,patch_embed4 同上---------
# ------------------------------------------------------------------------
# transformer encoder block
# ------------------------------------------------------------------------
dpr = [x.item() for x in torch.linspace(0, drop_path_rate, sum(depths))] # stochastic depth decay rule
cur = 0
self.block1 = nn.ModuleList([Block(
dim=embed_dims[0], num_heads=num_heads[0], mlp_ratio=mlp_ratios[0], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[0])
for i in range(depths[0])])
self.norm1 = norm_layer(embed_dims[0])
cur += depths[0]
self.block2 = nn.ModuleList([Block(
dim=embed_dims[1], num_heads=num_heads[1], mlp_ratio=mlp_ratios[1], qkv_bias=qkv_bias, qk_scale=qk_scale,
drop=drop_rate, attn_drop=attn_drop_rate, drop_path=dpr[cur + i], norm_layer=norm_layer,
sr_ratio=sr_ratios[1])
for i in range(depths[1])])
self.norm2 = norm_layer(embed_dims[1])
# ---------block3, block4 同上---------
self.apply(self._init_weights)
def forward_features(self, x):
B = x.shape[0]
outs = []
# stage 1
x, H, W = self.patch_embed1(x)
for i, blk in enumerate(self.block1):
x = blk(x, H, W)
x = self.norm1(x)
x = x.reshape(B, H, W, -1).permute(0, 3, 1, 2).contiguous()
outs.append(x)
# ---------stage 2 同stage1,省略---------
# ---------stage 3 同stage1,省略---------
# ---------stage 4 同stage1,省略---------
return outs
3.3 OverlapPatchEmbed代码
其中OverlapPatchEmbed是用来设计patch merge模块的代码。具体如下:
class OverlapPatchEmbed(nn.Module):
""" Image to Patch Embedding
"""
def __init__(self, img_size=224, patch_size=7, stride=4, in_chans=3, embed_dim=768):
super().__init__()
img_size = to_2tuple(img_size)
patch_size = to_2tuple(patch_size)
self.img_size = img_size
self.patch_size = patch_size
self.H, self.W = img_size[0] // patch_size[0], img_size[1] // patch_size[1]
self.num_patches = self.H * self.W
self.proj = nn.Conv2d(in_chans, embed_dim, kernel_size=patch_size, stride=stride,
padding=(patch_size[0] // 2, patch_size[1] // 2))
# 其实就是使用k=7,s=4,p=7//2=3 的卷积完成patch merging
self.norm = nn.LayerNorm(embed_dim)
self.apply(self._init_weights)
def forward(self, x):
x = self.proj(x)
_, _, H, W = x.shape
x = x.flatten(2).transpose(1, 2)
x = self.norm(x)
return x, H, W
假设输入为64x64x4
![]()
3.4 block代码
其中block是用来设计Transformer Block模块的代码。具体如下:
class Block(nn.Module):
def __init__(self, dim, num_heads, mlp_ratio=4., qkv_bias=False, qk_scale=None, drop=0., attn_drop=0.,
drop_path=0., act_layer=nn.GELU, norm_layer=nn.LayerNorm, sr_ratio=1):
super().__init__()
self.norm1 = norm_layer(dim)
self.attn = Attention(
dim,
num_heads=num_heads, qkv_bias=qkv_bias, qk_scale=qk_scale,
attn_drop=attn_drop, proj_drop=drop, sr_ratio=sr_ratio)
# NOTE: drop path for stochastic depth, we shall see if this is better than dropout here
self.drop_path = DropPath(drop_path) if drop_path > 0. else nn.Identity()
self.norm2 = norm_layer(dim)
mlp_hidden_dim = int(dim * mlp_ratio)
self.mlp = Mlp(in_features=dim, hidden_features=mlp_hidden_dim, act_layer=act_layer, drop=drop)
self.apply(self._init_weights)
def forward(self, x, H, W):
x = x + self.drop_path(self.attn(self.norm1(x), H, W))
x = x + self.drop_path(self.mlp(self.norm2(x), H, W))
return x
一个Transformer Block包括Efficient_attention+MixFFN。
x = x + self.drop_path(self.attn(self.norm1(x), H, W)) 是实现Efficient_attention。
x = x + self.drop_path(self.mlp(self.norm2(x), H, W)) 是实现MixFFN

假设输入为64x64x4

3.5 Attention模块代码
class Attention(nn.Module):
def __init__(self, dim, num_heads=8, qkv_bias=False, qk_scale=None, attn_drop=0., proj_drop=0., sr_ratio=1):
super().__init__()
assert dim % num_heads == 0, f"dim {dim} should be divided by num_heads {num_heads}."
self.dim = dim
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = qk_scale or head_dim ** -0.5
self.q = nn.Linear(dim, dim, bias=qkv_bias)
self.kv = nn.Linear(dim, dim * 2, bias=qkv_bias)
self.attn_drop = nn.Dropout(attn_drop)
self.proj = nn.Linear(dim, dim)
self.proj_drop = nn.Dropout(proj_drop)
self.sr_ratio = sr_ratio # 缩放因子
if sr_ratio > 1:
self.sr = nn.Conv2d(dim, dim, kernel_size=sr_ratio, stride=sr_ratio)
self.norm = nn.LayerNorm(dim)
self.apply(self._init_weights)
def forward(self, x, H, W):
B, N, C = x.shape
# q是正常操作,不需要缩放,num_head是多头注意力数量。
q = self.q(x).reshape(B, N, self.num_heads, C // self.num_heads).permute(0, 2, 1, 3)
if self.sr_ratio > 1:
x_ = x.permute(0, 2, 1).reshape(B, C, H, W)
x_ = self.sr(x_).reshape(B, C, -1).permute(0, 2, 1)
x_ = self.norm(x_)
kv = self.kv(x_).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
else:
kv = self.kv(x).reshape(B, -1, 2, self.num_heads, C // self.num_heads).permute(2, 0, 3, 1, 4)
k, v = kv[0], kv[1]
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
x = (attn @ v).transpose(1, 2).reshape(B, N, C)
x = self.proj(x)
x = self.proj_drop(x)
return x
3.6 MLP模块代码(用在MixFFN)
class Mlp(nn.Module):
def __init__(self, in_features, hidden_features=None, out_features=None, act_layer=nn.GELU, drop=0.):
super().__init__()
out_features = out_features or in_features
hidden_features = hidden_features or in_features
self.fc1 = nn.Linear(in_features, hidden_features)
self.dwconv = DWConv(hidden_features)
self.act = act_layer()
self.fc2 = nn.Linear(hidden_features, out_features)
self.drop = nn.Dropout(drop)
self.apply(self._init_weights)
def forward(self, x, H, W):
x = self.fc1(x)
x = self.dwconv(x, H, W)
x = self.act(x)
x = self.drop(x)
x = self.fc2(x)
x = self.drop(x)
return x
class DWConv(nn.Module):
def __init__(self, dim=768):
super(DWConv, self).__init__()
self.dwconv = nn.Conv2d(dim, dim, 3, 1, 1, bias=True, groups=dim)
def forward(self, x, H, W):
B, N, C = x.shape
x = x.transpose(1, 2).view(B, C, H, W)
x = self.dwconv(x)
x = x.flatten(2).transpose(1, 2)
return x
4.7 MLP解码器
class MLP(nn.Module):
"""
Linear Embedding
"""
def __init__(self, input_dim=2048, embed_dim=768):
super().__init__()
self.proj = nn.Linear(input_dim, embed_dim)
def forward(self, x):
x = x.flatten(2).transpose(1, 2)
x = self.proj(x)
return x
@HEADS.register_module()
class SegFormerHead(BaseDecodeHead):
"""
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
"""
def __init__(self, feature_strides, **kwargs):
super(SegFormerHead, self).__init__(input_transform='multiple_select', **kwargs)
assert len(feature_strides) == len(self.in_channels)
assert min(feature_strides) == feature_strides[0]
self.feature_strides = feature_strides
c1_in_channels, c2_in_channels, c3_in_channels, c4_in_channels = self.in_channels
decoder_params = kwargs['decoder_params']
embedding_dim = decoder_params['embed_dim']
self.linear_c4 = MLP(input_dim=c4_in_channels, embed_dim=embedding_dim)
self.linear_c3 = MLP(input_dim=c3_in_channels, embed_dim=embedding_dim)
self.linear_c2 = MLP(input_dim=c2_in_channels, embed_dim=embedding_dim)
self.linear_c1 = MLP(input_dim=c1_in_channels, embed_dim=embedding_dim)
self.linear_fuse = ConvModule(
in_channels=embedding_dim*4,
out_channels=embedding_dim,
kernel_size=1,
# norm_cfg=dict(type='SyncBN', requires_grad=True)
norm_cfg=dict(type='BN', requires_grad=True)
)
self.linear_pred = nn.Conv2d(embedding_dim, self.num_classes, kernel_size=1)
def forward(self, inputs):
x = self._transform_inputs(inputs) # len=4, 1/4,1/8,1/16,1/32
c1, c2, c3, c4 = x
############## MLP decoder on C1-C4 ###########
n, _, h, w = c4.shape
_c4 = self.linear_c4(c4).permute(0,2,1).reshape(n, -1, c4.shape[2], c4.shape[3]) # 统一维数
_c4 = resize(_c4, size=c1.size()[2:],mode='bilinear',align_corners=False)
# 上采样
_c3 = self.linear_c3(c3).permute(0,2,1).reshape(n, -1, c3.shape[2], c3.shape[3])# 统一维数
_c3 = resize(_c3, size=c1.size()[2:],mode='bilinear',align_corners=False)
# 上采样
_c2 = self.linear_c2(c2).permute(0,2,1).reshape(n, -1, c2.shape[2], c2.shape[3])# 统一维数
_c2 = resize(_c2, size=c1.size()[2:],mode='bilinear',align_corners=False)
# 上采样
_c1 = self.linear_c1(c1).permute(0,2,1).reshape(n, -1, c1.shape[2], c1.shape[3])# 统一维数
_c = self.linear_fuse(torch.cat([_c4, _c3, _c2, _c1], dim=1))
# 先cat,再使用1x1的卷积降维
x = self.dropout(_c)
x = self.linear_pred(x) # 输出指定维度。
return x
3.8 输出结果
输入为H/4 x W/4 x Ncls,最终经过resize还原到H x W x Ncls
def encode_decode(self, img, img_metas):
"""Encode images with backbone and decode into a semantic segmentation
map of the same size as input."""
x = self.extract_feat(img)
out = self._decode_head_forward_test(x, img_metas)
out = resize(
input=out,
size=img.shape[2:],
mode='bilinear',
align_corners=self.align_corners)
return out