论文阅读《LEAStereo:Hierarchical Neural Architecture Search for Deep Stereo Matching》
论文地址:https://arxiv.org/pdf/2010.13501.pdf
源码地址:https://github.com/XuelianCheng/LEAStereo
概述
神经网络结构搜索(NAS)方法已经在多个邻域得到了应用,其基础思想为让模型在搜索空间中(如不同卷积核大小)根据设定的搜索策略来得到最适合该任务的架构。当前的立体匹配任务都基于人工设计的复杂模型结构,NAS方法还未广泛应用到该领域中。本文提出一种端到端训练的分层 NAS 框架,将人类的模型设计知识融入神经结构搜索框架中得到针对立体匹配任务的模型架构,该模型遵循常用的立体匹配的框架(特征提取、代价体构建、稠密匹配)。使用 NAS 算法来搜索特征模型与匹配模型,能同时从不同的模型架构、不同的特征图大小、与输出的视差图范围组成的搜索空间中得到得到最优的模型结构。
模型架构
针对匹配任务的结构搜索空间
在深度学习领域,分割与立体匹配任务常用 Encoder-Decoder 结构,但基于U-Net结构的方法训练难度较大,而基于体素构建的立体匹配方法使用了较好的归纳偏置(人类设计模型结构知识),因此具有更快的收敛速度和更好的性能,该方法逐像素构建了3D代价体,然后基于3D代价体得到视差图,为此也带来了较大的计算量,这使得在NAS算法中搜索该模型结构的过程中带来挑战。
本文提出了一种基于两层的层次搜索:cell 单元级结构搜索、网络级结构搜索。在这项工作中,将立体匹配的几何知识嵌入到模型架构搜索过程中,整体模型主要包含 4 个部分:
- 用于生成2D特征图的特征网络;
- 4D 匹配代价体构建 ;
- 用于代价聚合与匹配代价计算的匹配网络;
- 将代价体回归为视差图的soft-argmax层;
由于只有特征网络与匹配网络包含可训练的参数,因此只针对这两个模块进行NAS结构搜索,主要的模型结构如图2所示;

cell 层级搜索空间
将NAS最核心的搜索单元记为 cell ,将一个 cell 定义为一个具有 N 个节点的全连通有向无环图;每个 cell 包含2个输入节点、1 个输出节点与 3 个中间节点;对于 l l l 层,输出的节点记为 C l C_l Cl ,该层的输入节点为前面两层的输出节点 ( C l − 1 、 C l − 1 C_{l-1}、C_{l-1} Cl−1、Cl−1 ),记 O O O 为搜索空间中的操作 (2D卷积、跳跃连接等);在结构搜索过程中,中间节点 s ( j ) s^{(j)} s(j) 描述为:
s ( j ) = ∑ i ∼ j o ( i , j ) ( s ( i ) ) (1) \boldsymbol{s}^{(j)}=\sum_{i \sim j} o^{(i, j)}\left(\boldsymbol{s}^{(i)}\right) \tag{1} s(j)=i∼j∑o(i,j)(s(i))(1)
其中: ∼ \sim ∼ 表示 i i i 节点与 j j j 节点相连,同时:
o ( i , j ) ( x ) = ∑ r = 1 ν exp ( α r ( i , j ) ) ∑ s = 1 ν exp ( α s ( i , j ) ) o r ( i , j ) ( x ) (2) o^{(i, j)}(\boldsymbol{x})=\sum_{r=1}^{\nu} \frac{\exp \left(\alpha_{r}^{(i, j)}\right)}{\sum_{s=1}^{\nu} \exp \left(\alpha_{s}^{(i, j)}\right)} o_{r}^{(i, j)}(\boldsymbol{x})\tag{2} o(i,j)(x)=r=1∑ν∑s=1νexp(αs(i,j))exp(αr(i,j))or(i,j)(x)(2)
其中: o r ( i , j ) o_{r}^{(i, j)} or(i,j) 为两个节点之间第 r 种候选操作;将该层搜索空间的每种操作的权重(置信度) ( α 1 ( i , j ) , α 2 ( i , j ) , ⋯ , α ν ( i , j ) ) \left(\alpha_{1}^{(i, j)}, \alpha_{2}^{(i, j)}, \cdots, \alpha_{\nu}^{(i, j)}\right) (α1(i,j),α2(i,j),⋯,αν(i,j)) 经过softmax函数后得到归一化后的权重;最后通过在所有相邻节点之间选择权重最大的操作来组成最后的结构。即 o ( i , j ) = o r ∗ ( i , j ) ; r ∗ = arg max r α r ( i , j ) o^{(i, j)}=o_{r^{*}}^{(i, j)} ; r^{*}=\arg \max _{r} \alpha_{r}^{(i, j)} o(i,j)=or∗(i,j);r∗=argmaxrαr(i,j) ;在此过程中只需要在一类 cell 中搜索特征网络和匹配网络的结构,空间分辨率的变化由网络层级的搜索来处理。由于DARTS 结构搜索方法的限制,即节点 C l − 2 , C l − 1 , C l C_{l-2},C_{l-1},C_l Cl−2,Cl−1,Cl 需要具有相同的空间和通道维度。为了处理相邻单元图像分辨率的差异,将不匹配的特征图经过上采样或下采样来调整为相同分辨率;
残差单元

以往的研究选择将所有中间节点的输出串联起来形成一个 cell 的输出,将这种设计称为直接单元。受到resNet的启发,在相邻节点之间添加跳跃连接(如图3红线所示),这允许网络在原来的结构基础上进行残差学习,实验结果表明残差结构可以得到更好的结果;
候选操作集
由于功能差异,特征网络与匹配模型的候选操作集是不同的。针对特征网络,该网络旨在提取差异化的局部特征用于逐像素代价体构建;通过经验观察到在DARTS中去除扩张的可分离卷积与池化层并不会影响模型的性能。为此,特征模型的候选操作集 O F ∈ { " 3 x 3 c o n v 2 D " , " s k i p c o n n e c t i o n " } O^F\in \{"3x3 \quad conv2D", "skip\quad connection"\} OF∈{"3x3conv2D","skipconnection"},匹配网络的候选操作集合 O M ∈ { " 3 x 3 x 3 c o n v 3 D " , " s k i p c o n n e c t i o n " } O^M\in \{"3x3x3 \quad conv3D", "skip\quad connection"\} OM∈{"3x3x3conv3D","skipconnection"}
网络层级搜索空间
文中将网络层级搜索空间定义为 cell 的排列,控制着特征维数的变化和 cell 之间的信息流动方式;如图 3 右所示,目标是在预定义的 L 层网格中找到一条最优路径;考虑到每个 cell 中的 filter 数量,将特征张量的高度和宽度减半时将通道扩充为 2 倍。
网络级搜索空间有两个超参数:最小分辨率与层数 L;文中将最小分辨率设置为 原图大小的 1 24 \frac{1}{24} 241 , 每个level的下采样率为 {3, 2, 2, 2} ,最后得到最小分辨率的特征图的尺寸为原图的 1 24 \frac{1}{24} 241 。在特征网络的初始位置拥有三层的 “茎” 结构,第一层为 stride=3 的 3x3 的 Conv2d,第二第三层为 stride=1 的 3x3 的 Conv2d。对于层数 L ,文中设定 L F = 6 , L M = 12 L^F=6 , L^M=12 LF=6,LM=12,在计算负载和网络性能之间提供了良好的平衡
类似于寻找节点之间的最佳操作,使用一组搜索参数 β \beta β 来搜索网格,以便在网格中找到最小化损失的路径。
损失函数
使用 smooth L1 loss:
L = ℓ ( d pred − d g t ) , where ℓ ( x ) = { 0.5 x 2 , ∣ x ∣ < 1 ∣ x ∣ − 0.5 , otherwise (3) \mathcal{L}=\ell\left(\mathbf{d}_{\text {pred }}-\mathbf{d}_{\mathrm{gt}}\right), \text { where } \ell(x)=\left\{\begin{array}{lc} 0.5 x^{2}, & |x|<1 \\ |x|-0.5, & \text { otherwise } \end{array}\right.\tag{3} L=ℓ(dpred −dgt), where ℓ(x)={0.5x2,∣x∣−0.5,∣x∣<1 otherwise (3)
在连续松弛后,通过双层优化来优化网络的权重 w w w 与架构参数 α , β \alpha,\beta α,β ,我们分别用 α , β \alpha,\beta α,β 来参数化 cell层级 的结构与网络层级的结构。为了加速,使用一阶近似;为了避免过拟合,使用两个不相交的数据集 t r a i n I train \text { I } train I 与 t r a i n II train \text { II } train II 交替进行 w w w 与 α , β \alpha,\beta α,β 的优化。
- 在 t r a i n I train \text { I } train I 数据集通过 ∇ w L ( w , α , β ) \nabla_{\mathbf{w}} \mathcal{L}(\mathrm{w}, \boldsymbol{\alpha}, \boldsymbol{\beta}) ∇wL(w,α,β)更新 w w w
- 在 t r a i n II train \text { II } train II 数据集通过 ∇ α , β L ( w , α , β ) \nabla_{\mathbf{\alpha, \beta}} \mathcal{L}(\mathrm{w}, \boldsymbol{\alpha}, \boldsymbol{\beta}) ∇α,βL(w,α,β)更新 α , β \alpha, \beta α,β
优化收敛时,保留从每个节点间权重最高的两个操作作为一个 cell 单元,并通过寻找具有最大概率的路径来得到网络结构。

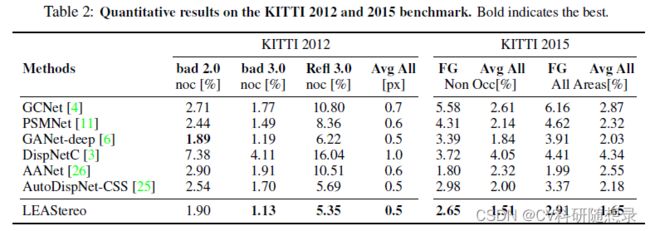
实验结果