RCNN SPPNet Fast R-CNN Faster R-CNN Cascade R-CNN
文章目录
- 基础相关
-
- selective search算法
- 端到端=end to end=joint learning共同学习
- FPN 多尺度金字
-
- 自下而上:特征提取过程
- RPN(Region Proposal Networks):取代ss算法获取候选框(速度更快)
-
- anchors:一组矩形框,3*3卷积核滑动窗口时生成anchors,其坐标是backbone之前图像(M,N)尺寸上的坐标(x1,y1,x2,y2)
- 作用:目标定位=该区域是否非背景+该区域边界回归
- RoiPooling和RoiAlign
-
- RoiPooling/RoiAlign:收集 proposal候选框,计算出固定尺寸的proposal候选框的feature maps,送入后续网络
-
- 为什么固定尺寸
- RoiPooling
- RoiPooling优点
- RoiPooling缺点
- RoiAlign
-
- 优点
- spp:空间金字塔池化
- 特点
- RCNN:使用cnn做目标检测
-
- 步骤
- 存在的问题
- SPPNet:
-
- 改进
- 步骤
- 注意
- Fast R-CNN:以更快的速度进行分类和目标框回归的端到端
-
- 改进
- 步骤
- 存在的问题
- Faster R-CNN:不适用ss算法,以更快的速度进行特征提取、提取候选框、分类和目标框回归的总体端到端
-
- 改进
- 步骤
- Cascade R-CNN
-
- 解决faster rcnn的问题
- 如何解决
- YOLO:you only look once,看一眼就能检测到目标的类别和位置:首个单阶段检测模型
-
- 首个单阶段检测模型
- 解决的问题:
- 网络
- 步骤
- 注意点
-
- 每个网格最多只预测一个目标,一张图片最多检测S*S个目标
- bounding box 并不是 Faster RCNN 的 Anchor
- 每个网格为什么要使用B个bounding box?
-
- B个Bounding box最终结果为什么不一样
- B个Bounding box最终结果不一样体现在哪
- 训练时,每个网格 目标的C个类别的概率
- 训练时,如何设置每个网格的B个bounding box的label
- 缺陷
-
- 每个网格最多只预测出一个物体
基础相关
selective search算法
根据颜色、纹理、尺寸、形状相似性,获取Region Proposal候选区域

端到端=end to end=joint learning共同学习
end-to-end 的本质是你要解决的问题是多阶段的或多步的 (跟所谓的 raw feature 没啥关系):如目标检测,有类别和目标框两步。
如果分阶段学习的话,第一阶段的最优解不能保证第二阶段的问题达到最优。
end-to-end 把他们堆在一起来优化,确保最后阶段的解达到最优。
FPN 多尺度金字
3部分:自下而上+自上而下+横向连接
自下而上:特征提取过程
根据feature map的大小分为5个stage,
RPN(Region Proposal Networks):取代ss算法获取候选框(速度更快)

anchors:一组矩形框,3*3卷积核滑动窗口时生成anchors,其坐标是backbone之前图像(M,N)尺寸上的坐标(x1,y1,x2,y2)
(P,Q)统一尺寸为(M,N)后,经过backbone提取特征成(c,M/16,N/16)。
经过backbone提取特征feature map后,在feature map上使用33的卷积核以sliding window滑动窗口的方式划过一遍,窗口滑动时,生成anchor,anchor位于滑动窗口的中心,并与并与一个anchor_scale和一个anchor_ratio相关联。默认3个anchor_scale和3个anchor_ratio,每个滑动的窗口上有9个anchors,每个anchor都处于滑动窗口的中心【滑动时,每个点都会是一个滑动窗口的中心】,并与一个proposal关联(共9个proposals:由3个scale和3个aspect_ratio组成。ratio=w/h)。对于wh的feature map,共有whk个anchor。
base_size,anchor_scale,anchor_ratio
def generate_anchors(base_size=16, ratios=[0.5, 1, 2],
scales=2**np.arange(3, 6)):
"""
ratio=h/w
anchor的表示形式有两种,一种是记录左上角和右下角的坐标,一种是记录中心坐标和宽高
base_size为经过 backbone 网络特征提取之后图像缩小的倍数,也是feature map上每一点的感受野对应backbone之前图像(M,N)尺寸的宽、高
"""
#base_anchor为feature map上每一点感受野对应backbone之前图像的坐标范围,其area=base_size*base_size,如feature map上的第一个点在backbone之前的坐标表示为[0,0,base_size-1,base_size-1]
base_anchor = np.array([1, 1, base_size, base_size]) - 1
# 根据base_anchor和高宽比,得到面积不变的不同形状的k种anchors,其坐标为在backbone之前图像(M,N)尺寸上的坐标 (x1,y1,x2,y2)
# 保持base_size*base_size面积不变的基础上:h*w=area h=(area*ratio)^0.5 w=(area/ratio)*0.5 h/w=ratio
ratio_anchors = _ratio_enum(base_anchor, ratios)
#在anchors中心坐标不变的基础上,将高、宽分别都放大scale倍,得到新的anchors,其坐标为在backbone之前的图像(M,N)尺寸上的坐标:(x1,y1,x2,y2)
anchors = np.vstack([_scale_enum(ratio_anchors[i, :], scales)
for i in range(ratio_anchors.shape[0])])
return anchors
作用:目标定位=该区域是否非背景+该区域边界回归
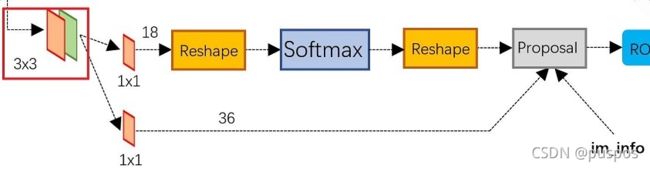
3*3卷积核以滑窗方式在backbone后的feature map上划的同时产生anchors,之后分为两条线:
1. 上面通过softmax分类anchors获得positive和negative分类。
2. 下面通过计算anchors的bounding box regression边界回归偏移量获取proposals。
3. 最后Proposal层综合positive anchors和对应的bounding box regression偏移量获得proposals,同时剔除太小和超出边界的proposals,完成目标定位:
3.0 接收输入:
positive和negative anchors分类器结果rpn_cls_prob_reshape
对应的 bbox reg结果rpn_bbox_pred=[d_x(A),d_y(A),d_w(A),d_h(A)]
im_info=(M,N,scale_factor=(P/M,Q/N)):保存缩放信息
feature_stride=backbone前img尺寸/backbone后img尺寸:用于计算 anchor 偏移量
3.1 生成anchors,对所有的anchors做边界框回归,此时anchors_num=M/16*N/16*k(=9)
3.2 对positive softmax scores由大到小排序,取前6000个positive anchors
3.3 将positive anchors映射回(M,N)尺寸,以超出图像边界的positive anchors为图像边界,防止后面RoiPooling时proposal超出图像边界
3.4 剔除尺寸很小的positive anchors
3.5 对剩下的positive anchors进行nms,得到指定数量的positive anchors(如:2000)
RoiPooling和RoiAlign
RoiPooling/RoiAlign:收集 proposal候选框,计算出固定尺寸的proposal候选框的feature maps,送入后续网络
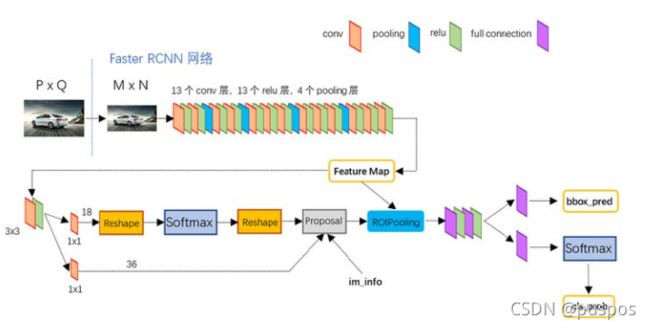
由于RPN 网络最终得到的proposal 是对应 MxN 尺度的,所以首先使用 spatial_scale参数将其映射回 backbone之后(M/16) x (N/16) 大小的 feature map 尺度;
再将每个 proposal 对应的 feature map 区域水平分为pooled_w*pooled_h 的网格;
对网格的每一份都进行 max pooling 处理,得到proposal的feature map,将其送入后续全连接和 softmax 网络作 classification。
为什么固定尺寸
Rol pooling 层有 2 个输入:
原始的 feature maps
RPN 输出的 proposal boxes(大小各不相同)
对于传统的 CNN(如 AlexNet 和 VGG),当网络训练好后输入的图像尺寸必须是固定值,同时网络输出也是固定大小的 vector or matrix。
如果输入图像大小不定,这个问题就变得比较麻烦。有 2 种解决办法:
从图像中 crop 一部分传入网络:破坏了图像的完整结构
将图像 warp 成需要的大小后传入网络:破坏了图像原始形状信息。
RoiPooling
RoiPooling有两次整数化/量化的过程:
-
由于rpn得到的proposal是相对于backbone之前图像的尺寸,首先得到proposal在backbone之后的feature map上的坐标,需要除以缩小倍数,一般是16 或者 32 ,边界【xywh】可能出现小数,为了方便操作会把它整数化(取离得最近的边界点)。

-
由于RoiPooling后面的网络需要输入特定尺寸的候选框,将整数化后的边界区域平均分割成 k x k 个单元,对每一个单元的边界进行整数化,之后得到了不同范围的池化区。
如:(5,7)->(2,2)
5/2=2.5=2,2+3
7/2=3.5=3,3+4
四块池化区长宽分别是:(2,3)(2,4)(3,3)(3,4)

RoiPooling优点
-
允许我们对 CNN 中的 feature map 进行 reuse;
-
可以显著加速 training 和 testing 速度;
-
允许 end-to-end 的形式训练目标检测系统
RoiPooling缺点
第一次量化/整数化,采用了 INTER_NEAREST(即最近邻插值) ,对于缩放proposal的坐标不能刚好为整数的情况,采用了粗暴的舍去小数,相当于选取离目标点最近的点,损失一定的空间精度。
第二次量化/整数化,不同范围的池化区,对于定位有误差。
RoiAlign
取消量化操作,proposal缩放后的坐标可以为浮点数。
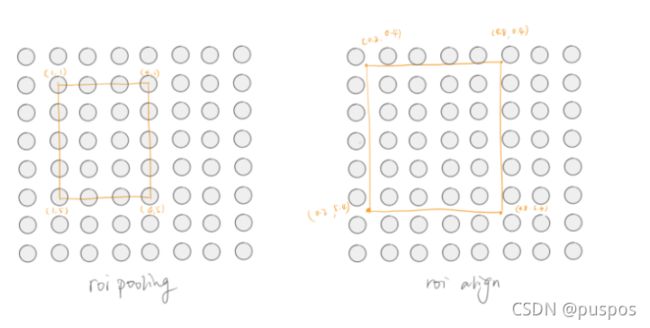
将proposal的feature map变为固定尺寸时,先划分同样范围的池化区,把每个池化区平均分为4份,每份按双线性插值求其中心的值,然后取最大值为 pooling 值。
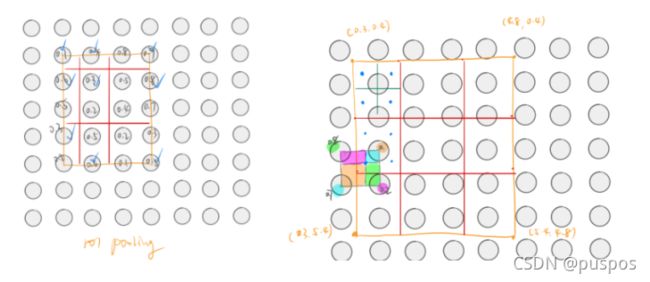
优点
解决了 ROI Pool 的量化误差问题,即浮点数坐标转换成整数坐标产生的误差,主要解决方式即不采用量化方式获取具体坐标,每个格子的值通过采样多个点获得,其中被采样点的值采用双线性插值的方式获得,不需要量化成整数坐标。
spp:空间金字塔池化
作用:将不同尺寸的特征变成固定尺寸,以满足SPPNet中fc layer的需要

将region proposals的特征分成 1x1 (金字塔底座),2x2 (金字塔中间),4x4(金字塔顶座)三张子图,分别做 max pooling 后,出来的特征就是固定(16+4+1) 维度
特点
无论输入大小如何,SPP 都能够生成固定长度的输出
多级池化已被证明对对象变形具有鲁棒性
由于输入尺度的灵活性,SPP 可以池化在可变尺度提取的特征减少过度拟合。
RCNN:使用cnn做目标检测
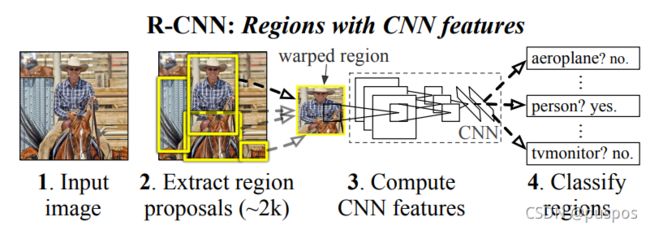

Girshick R , Donahue J , Darrell T , et al. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation[J]. IEEE Computer Society, 2013.
步骤
通过selective search算法在图片上取2000个左右Region Proposal候选区域;
通过wrap拉伸将Region Proposal统一尺寸后输入预训练分类CNN提取特征,
特征进入SVM支持向量机中分类,对分类后的Region Proposal候选区域进行box的线性回归。
存在的问题
存在的问题:
- 使用了三种模型,其结合过程繁琐,
cnn为每个Region Proposal提取特征。
每个类别对应一个SVM分类器
每个类别训练一个边界盒子回归模型
- 训练速度慢,占空间大:一张图像上有大量的重叠框,重叠部分多次重复提取特征。
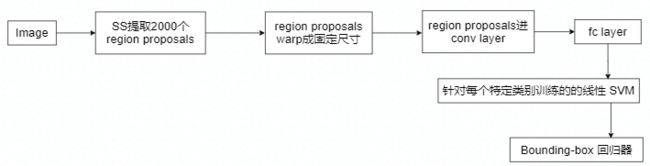
SPPNet:
改进
- 对整张图片只进行一次特征的提取,避免了RCNN的重复提取特征问题,速度快了24~102倍。
- 提出SPP,在最后一层卷积后,使用SPP,将不同维度的特征变成固定尺寸,以便喂给全连接层进行分类。
步骤
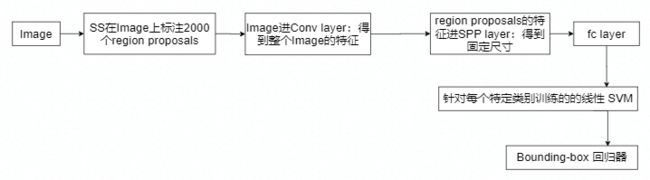
注意
cnn中fc layer才需要固定尺寸的特征:使用SPP
卷积神经网络包括卷积层和全连接层,卷积层不要求固定输入,因为卷积层的参数主要是卷积核,可以接收任意大小的输入,并产生对应大小的输出。全连接层需要固定输入,因为其参数是对所有输入的连接权重,只有输入固定了,参数个数才固定。
spp替换掉最后一个卷积层的池化层
Fast R-CNN:以更快的速度进行分类和目标框回归的端到端
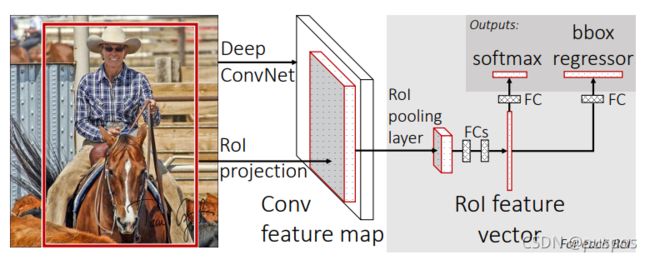
 Girshick R . Fast R-CNN[J]. Computer Science, 2015.
Girshick R . Fast R-CNN[J]. Computer Science, 2015.
改进
-
把整个图片输入CNN提取整体特征,减少计算量,更快,不像RCNN对每个Region Proposal分别提取特征,避免提取重复特征
-
引入RoiPooling:不需RCNN一样,wrap拉伸图片后再送入网络,防止图像的变形和扭曲。
-
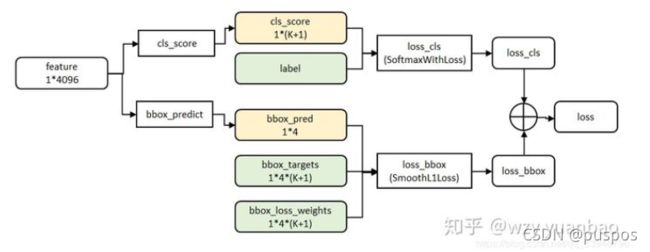
使用了multi-task loss多任务损失函数,实现分类和回归的端到端【但没有实现联合训练/总体端到端,ss算法提取候选框没有涉及】:Fast R-CNN 网络的损失函数包含了 Softmax 的损失和 Regressor 的损失,反向传播时,通过一个损失函数,即可对分类和回归的参数进行更新。
-
分类和回归都使用CNN来实现,不需要额外的分类器和回归器,不占用磁盘空间:
RCNN提取特征给SVM训练时,需磁盘空间存放特征和中间结果。
Fast RCNN所有的特征暂存显存中。
步骤
通过selective search 算法在图片上预取 2000 个左右 Region Proposal候选区域;
通过预训练分类cnn对整张图片提取特征feature map;
把Region Proposal坐标映射到feature map中得到RP_feature_map,之后用RoiPooling对每个RP_feature_map最大值池化,得到固定尺寸的Roi_RP_feature map。
将Roi_RP_feature map输入到全连接层,并定义multi-task多任务损失函数,分别与softmax 分类和bounding box regress边框回归【网络,而非线性】相连【分别使用softmax loss 和 smooth l1 loss】,分别计算类别得分和预测框 (x, y, w, h)。
存在的问题
selective search生成候选区域仍然不够快速, 消耗的时间是后面特征提取的十几倍
Faster R-CNN:不适用ss算法,以更快的速度进行特征提取、提取候选框、分类和目标框回归的总体端到端

Ren S , He K , Girshick R , et al. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks[J]. IEEE Transactions on Pattern Analysis & Machine Intelligence, 2017, 39(6):1137-1149.

改进
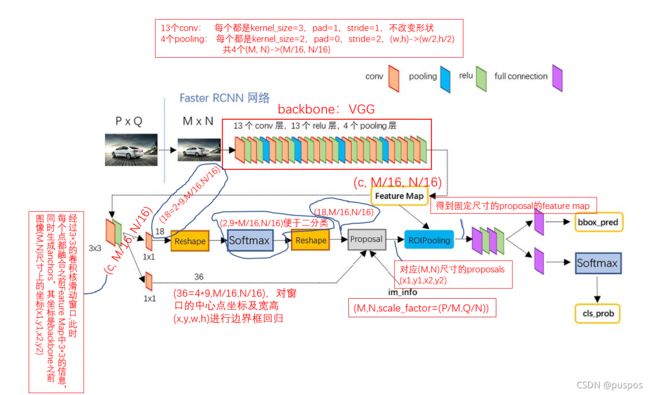
- 不再使用selective search,引入RPN(region proposal network区域推荐网络)
- 把特征提取 feature map,候选区域选取,回归和分类等操作融合在一个深层网络中,实现了联合训练,总体端到端,四个损失相加作为最后的损失,反向传播,更新参数:
(1)RPN 分类损失:anchor 是否为前景(二分类:前景or背景)
(2)RPN 位置回归损失:对候选框【此时是生成的anchor】位置微调
(3)RoI 分类损失:RoI 所属类别(21 分类,多了一个类作为背景)
(4)RoI 位置回归损失:继续对候选框位置微调
步骤
首先通过可学习的 RPN 网络获取Region Proposal 候选框
利用 Region Proposal 坐标在 CNN 的特征图上进行 RoI 特征图提取;
然后利用 RoI Pooling 层进行空间池化使其所有特征图输出尺寸相同;
最后将所有特征图输入到后续的 FC 层进行分类和回归。
Cascade R-CNN
解决faster rcnn的问题
对于faster rcnn:在训练时,IOU 阈值设的低,会引起 noisy detection;IOU 阈值设的高,满足这个阈值条件的 proposals 必然比之前少了,导致训练样本大大减少,容易过拟合。
如何解决
使用多阈值的multi-stage代替faster rcnn单阈值的two-stage,通过不断提高的阈值,在保证样本数不减少的情况下训练出高质量的检测器。
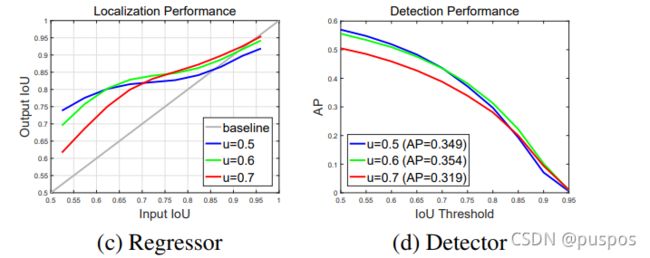
左图横轴是预测框的IOU,竖轴是预测框边框回归之后的新的IOU,通过 regressor,output IOU 会高于 input IOU,可递增使用 threshold,detector 的输出能很好地被作为下一个阶段的输入。
YOLO:you only look once,看一眼就能检测到目标的类别和位置:首个单阶段检测模型
首个单阶段检测模型
在它之前,都是两阶段检测模型,将检测问题分为求解目标类别的分类问题和求解目标位置的回归问题。
YOLO,作为端到端的单阶段检测模型,它通过单个卷积神经网络,将检测问题当成同时求解目标位置以及类别的回归问题,使用整张图片的特征直接预测所有目标的bounding box信息以及类别信息。
解决的问题:
- 速度更快
- Faster RCNN虽然基本实现了实时监测,但仍然存在训练参数过多,训练时间长的问题
网络

网络基于GoogleNet分类网络结构,使用11卷积(为了跨通道信息整合)和33卷积代替inception module,由24层卷积+2层全连接层组成。
步骤
- 将输入图像分为S*S的网格,每个网格负责预测中心落在该网格的目标。
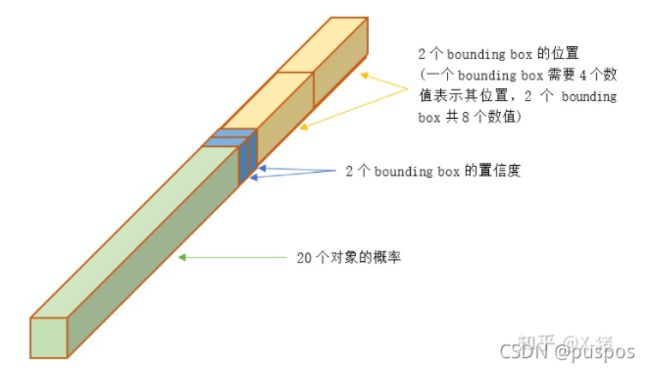
最后输出SS(B5+C)维,每个网格输出(B5+C)维:B个bounding box信息以及C(类别数)个存在目标的情况下属于某类别的条件概率P(Class_i|Object)
其中Bounding box信息包括,x,y,w,h以及置信度confidence,x,y为当前格子预测目标的中心位置,w,h为Bounding box的宽度和高度,confidence是当前Bounding box是否含有目标以及物体位置的准确性,confidence=P(object)*IOU:目标中心在网格中,P(Object)=1,否则为0。
注意点
每个网格最多只预测一个目标,一张图片最多检测S*S个目标
每个网格最终输出B*5+C维,每个网格只有一组目标分类的概率(C类)
bounding box 并不是 Faster RCNN 的 Anchor
Faster RCNN中:每个 grid 中手工设置 n 个 Anchor(先验框,预先设置好位置的 bounding box)的设计,每个 Anchor 有不同的大小和宽高比。
YOLO 的 bounding box 看起来很像一个 grid 中 2 个 Anchor,但它们不是。YOLO 并没有预先设置 2 个 bounding box 的大小和形状,也没有对每个 bounding box 分别输出一个对象的预测。它的意思仅仅是对一个对象预测出 B 个 bounding box,选择预测得相对比较准的那个。
每个网格为什么要使用B个bounding box?
B个Bounding box最终结果为什么不一样
B 个 bounding box 事先不知道会目标在哪,经过前向计算后,网络会输出 B个 bounding box,分别与实际对象的 bounding box 计算 IOU。IOU 值大的那个 bounding box,负责预测该对象。
B个Bounding box最终结果不一样体现在哪
训练开始阶段,网络预测的 bounding box 可能都是乱来的,但总是选择 IOU 相对好一些的那个,随着训练的进行,每个 bounding box 会逐渐擅长对某些情况的预测(可能是对象大小、宽高比、不同类型的对象等)
训练时,每个网格 目标的C个类别的概率
自行车的中心点落在某网格,则该网格对应的(B*5+C)维中
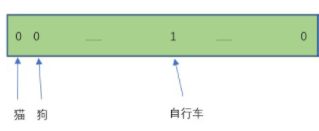
训练时,如何设置每个网格的B个bounding box的label
网格的B个Bounding box实际只有1个Bounding box负责预测目标。
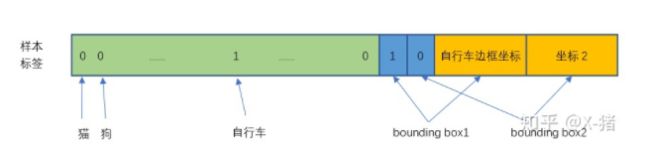
计算B个bounding box的confidence=P(Object)*IOU,谁的IOU大,该bounding box的P(Object)=1,
缺陷
每个网格最多只预测出一个物体
当物体占画面比例较小,如图像中包含畜群或鸟群时,每个格子包含多个物体,但却只能检测出其中一个。