机器学习入门之:不需要带脑子,全网最细,详解 Unet 代码
文章目录
- Unet
-
- 为什么 Unet 适合做医学影像处理
- Unet 结构展示
- 复现的代码
-
- 1. 主函数 main
- 2. data.py
- 3. model.py
- 一点尾巴
Unet
为什么 Unet 适合做医学影像处理
- 图像语义较为简单、结构较为固定。做脑的,就用脑CT和脑MRI,做胸片的只用胸片CT,做眼底的只用眼底OCT,都是一个固定的器官的成像,而不是全身的。由于器官本身结构固定和语义信息没有特别丰富,所以高级语义信息和低级特征都显得很重要(UNet的skip connection和U型结构就派上了用场)。
- 数据量少。医学影像的数据获取相对难一些,很多比赛只提供不到100例数据。所以我们设计的模型不宜过大,参数过多,很容易导致过拟合。
原始UNet的参数量在28M左右(上采样带转置卷积的UNet参数量在31M左右),而如果把channel数成倍缩小,模型可以更小。缩小两倍后,UNet参数量在7.75M。缩小四倍,可以把模型参数量缩小至2M以内,非常轻量。
- 多模态。相比自然影像,医疗影像比较有趣和不同的一点是,医疗影像是具有多种模态的。以ISLES脑梗竞赛为例,其官方提供了CBF,MTT,CBV,TMAX,CTP等多种模态的数据。这就需要我们更好的设计网络去提取不同模态的特征feature。这里提供两篇论文供大家参考。
Joint Sequence Learning and Cross-Modality Convolution for 3D Biomedical Segmentation(CVPR 2017) ,
Dense Multi-path U-Net for Ischemic Stroke Lesion Segmentation in Multiple Image Modalities.
- 可解释性重要。由于医疗影像最终是辅助医生的临床诊断,所以网络告诉医生一个3D的CT有没有病是远远不够的,医生还要进一步的想知道,病灶在哪一层,在哪一层的哪个位置,分割出来了吗,能求体积嘛?同时对于网络给出的分类和分割等结果,医生还想知道为什么,所以一些神经网络可解释性的trick就有用处了,比较常用的就是画activation map。看网络的哪些区域被激活了
参考文章:Unet神经网络为什么会在医学图像分割表现好?
Unet 结构展示
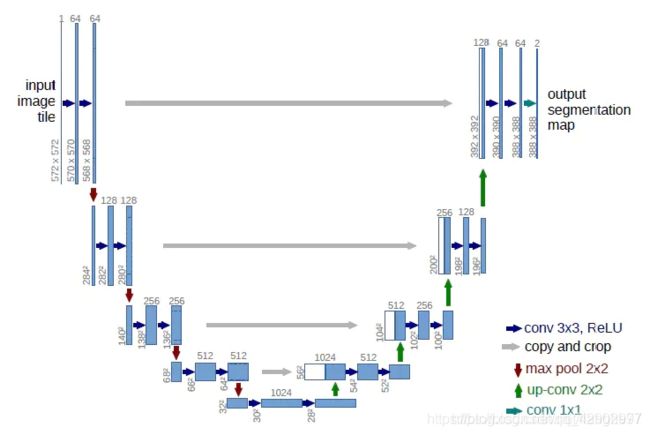
复现的代码
https://github.com/zhixuhao/unet
这是基于 Keras 结构写的,通俗易懂
1. 主函数 main
from model import *
from data import *
#os.environ["CUDA_VISIBLE_DEVICES"] = "0"
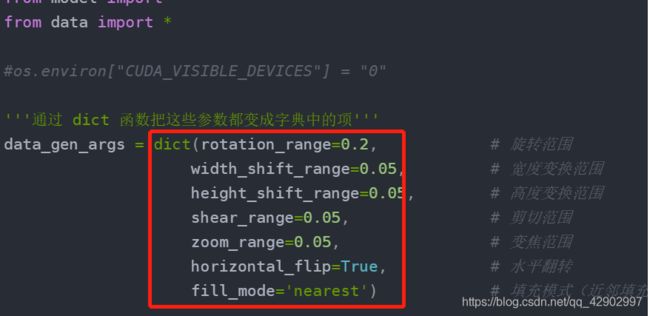
'''通过 dict 函数把这些参数都变成字典中的项'''
data_gen_args = dict(rotation_range=0.2, # 旋转范围
width_shift_range=0.05, # 宽度变换范围
height_shift_range=0.05, # 高度变换范围
shear_range=0.05, # 剪切范围
zoom_range=0.05, # 变焦范围
horizontal_flip=True, # 水平翻转
fill_mode='nearest') # 填充模式(近邻填充)
myGene = trainGenerator(2,'data/membrane/train','image','label',data_gen_args,save_to_dir = None) #产生训练数据(以生成器的方式对数据集做增广)
model = unet()
model_checkpoint = ModelCheckpoint('unet_membrane.hdf5', monitor='loss',verbose=1, save_best_only=True) # 提前设置保存模型的一些参数
model.fit_generator(myGene,steps_per_epoch=300,epochs=1,callbacks=[model_checkpoint]) # 需要设置 steps_per_epoch来适应 fit_generator
testGene = testGenerator("data/membrane/test") # 产生测试数据
results = model.predict_generator(testGene,30,verbose=1) # 对于模型输入一个生成器
saveResult("data/membrane/test",results)
2. data.py
让我们看看这个代码里是如何定义
trainGenerator的
def trainGenerator(batch_size,train_path,image_folder,mask_folder,aug_dict,image_color_mode = "grayscale",
mask_color_mode = "grayscale",image_save_prefix = "image",mask_save_prefix = "mask",
flag_multi_class = False,num_class = 2,save_to_dir = None,target_size = (256,256),seed = 1):
'''
can generate image and mask at the same time
use the same seed for image_datagen and mask_datagen to ensure the transformation for image and mask is the same
if you want to visualize the results of generator, set save_to_dir = "your path"
'''
image_datagen = ImageDataGenerator(**aug_dict)
mask_datagen = ImageDataGenerator(**aug_dict)
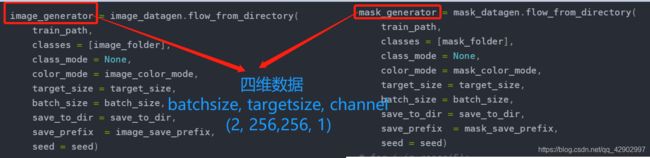
image_generator = image_datagen.flow_from_directory( # 将图片的 batch 分好
train_path,
classes = [image_folder],
class_mode = None,
color_mode = image_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = image_save_prefix,
seed = seed)
mask_generator = mask_datagen.flow_from_directory( # 将图片的 mask 都分好
train_path,
classes = [mask_folder],
class_mode = None,
color_mode = mask_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = mask_save_prefix,
seed = seed)
# for i in range(5):
# print(mask_generator.next())
# print(mask_generator.next().shape) # shape = (batch_size, 256, 256, 1)
train_generator = zip(image_generator, mask_generator)
for (img,mask) in train_generator:
img,mask = adjustData(img,mask,flag_multi_class,num_class)
yield (img,mask)
-
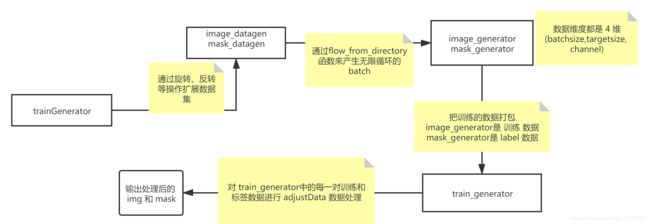
image_datagen = ImageDataGenerator(**aug_dict)根据main函数中的data_gen_args中规定的这些参数来进行数据集的扩展,把已有的数据进行:旋转(
rotation_range)、
宽度变换(width_shift_range)、
高度变换(width_shift_range)、
剪切范围(shear_range)、
变焦范围(zoom_range)、
水平翻转(horizontal_flip)、
填充方式(fill_mode);
-
同样的方式对
label数据也以同样的方式进行扩展mask_datagen = ImageDataGenerator(**aug_dict) -
扩展完数据集和标签集之后,要将这些数据进行 batch 的划分;这个步骤使用了
flow_from_directory,
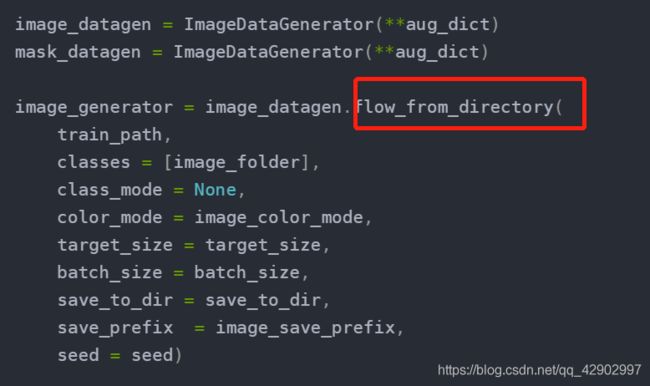
flow_from_directory():以文件夹路径(directory)为参数,将经过数据提升/归一化后的数据(文中的image_datagen和mask_datagen),在一个无限循环中无限产生batch数据;
具体的用法可以参考这篇博客:ImageDataGenerator生成器的flow,flow_from_directory用法 -
接下来,如果大家有兴趣,可以打印一下
image_generator和mask_generator中的数据的维度,你会发现,他们产生的都是4维的数据;也就是说,从这两个生成器中出来的每一个变量的维度都是 4,记住这一点,后面要用!!!
-
因为前面的代码中设定了
batch_size = 2, target_size = (256,256),


所以这个时候 image_generator 和 mask_generator 产生的数据 img 和 mask 中的数据维度就是 (2, 256, 256, 1) 四个维度分别代表了 batchsize、targetsize、图片的通道数,由于图片都是灰度图,所以最后一个通道数为 1;也就是说:
每次
image_generator和mask_generator运行一次,都会从增强和扩展后的数据集中拿出2张image图片 和 对应的2张mask标签图片;这些图片都是(256,256)的维度,并且都是单通道的灰度图
整个 trainGenerator 的流程图如下:
按照正常的思路一步步来看,接下来由于在 trainGenerator 模块中涉及到了 adjustData 这个函数,所以我们再来看一下这个函数做了什么工作:

从输入的参数上来看,除了上一部分提到的打包好的训练数据
img和 训练标签mask,还有flag_multi_class以及num_class
flag_multi_class是个多类型检测的标志,如果True那么证明一个图中有多个种类的分类目标num_class是告诉函数,一共分几类
def adjustData(img,mask,flag_multi_class,num_class):
if(flag_multi_class): # 如果一个场景里有多个识别的物体
img = img / 255 # 图片特征缩放成0-1之间
mask = mask[:,:,:,0] if(len(mask.shape) == 4) else mask[:,:,0] # 取mask颜色的值
new_mask = np.zeros(mask.shape + (num_class,)) # 变成 5 维的矩阵,(batch_size,255,255,1,num_class)
for i in range(num_class):
#for one pixel in the image, find the class in mask and convert it into one-hot vector
#index = np.where(mask == i)
#index_mask = (index[0],index[1],index[2],np.zeros(len(index[0]),dtype = np.int64) + i) if (len(mask.shape) == 4) else (index[0],index[1],np.zeros(len(index[0]),dtype = np.int64) + i)
#new_mask[index_mask] = 1
new_mask[mask == i,i] = 1 # 在 mask == i 的位置,这些值全部变成1,然后作为 new_mask 这样,new_mask就是个黑白的图像了
if flag_multi_class:
new_mask = np.reshape(new_mask,(new_mask.shape[0],new_mask.shape[1]*new_mask.shape[2],new_mask.shape[3]))
else:
new_mask = np.reshape(new_mask,(new_mask.shape[0]*new_mask.shape[1],new_mask.shape[2]))
mask = new_mask
elif(np.max(img) > 1):
img = img / 255
mask = mask /255
mask[mask > 0.5] = 1
mask[mask <= 0.5] = 0
return (img,mask)
通过
adjustData的代码,根据默认的flag_multi_class = False所以我们关注的应该是代码的elif后的部分,即:
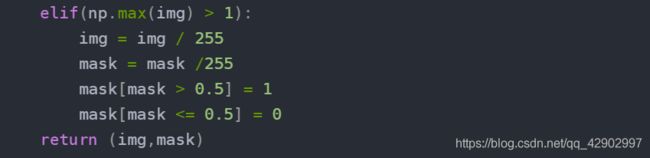
- 先判断如果整个
img (2, 256, 256, 1)变量中所有的像素点中的最大值 > 1,那就证明整个img变量中的图片都是还未进行归一化;这个时候使用/255.的方式可以把所有像素点的范围规范到0 ~ 1上,把特征进行压缩; mask[mask > 0.5] = 1就是遍历 mask 中所有的值,> 0.5的值被设置为1,<0.5的被设置成0;其实就是对标签的图片进行了二值化的处理。
到这里adjustData 的部分其实就算解析完了;但是,为了防止小伙伴们对于 flag_multi_class 的部分有疑问,我还是觉得应该解析一下:
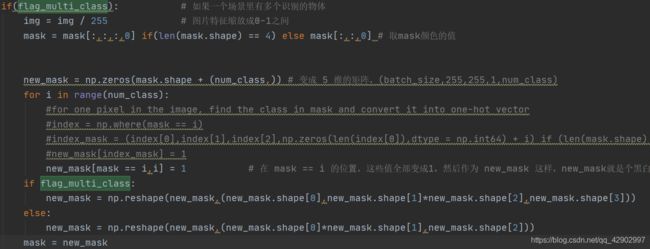
- 对于
img来说没有什么特殊,还是先把所有的像素点/255. - 对于
mask;由于flag_multi_class = True, 这个时候代表需要分类的种类变多了,这个时候num_class参数的作用就可以发挥出来;我们先一行行来看
![]()
不管怎么样都是取最后一维的像素点值;那么这样的话数据的维度也会减小
1维,从(2, 256, 256, 1)-->(2, 256, 256)
![]()
然后创建一个全零的矩阵,矩阵的维度是
(2, 256, 256) + (num_class, ) = (2, 256, 256, num_class)结合应用的场景来看,num_class一般为2,所以全零矩阵的维度应该为(2, 256, 256, 2),然后

执行
num_class次遍历操作,这里的num_class = 2所以拿 2 来举例:执行2次遍历操作,
- 第一次遍历的时候
i = 0,把mask(2,256,256)矩阵中= 0的位置的索引都找出来,然后把new_mask这个新矩阵中对应位置的值设置成1;- 同样的,第二次遍历的时候,
i = 1,把mask(2,256,256)矩阵中= 0的位置都找出来,然后对应的再new_mask的对应位置把它设置成1
这样 new_mask 中只有 0 、 1 两个值,需要被分类的目标都变成了 1 而没有用的信息都变成了 0
3. model.py
import numpy as np
import os
import skimage.io as io
import skimage.transform as trans
import numpy as np
from keras.models import *
from keras.layers import *
from keras.optimizers import *
from keras.callbacks import ModelCheckpoint, LearningRateScheduler
from keras import backend as keras
def unet(pretrained_weights = None,input_size = (256,256,1)):
inputs = Input(input_size)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(inputs)
conv1 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv1)
pool1 = MaxPooling2D(pool_size=(2, 2))(conv1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool1)
conv2 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv2)
pool2 = MaxPooling2D(pool_size=(2, 2))(conv2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool2)
conv3 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv3)
pool3 = MaxPooling2D(pool_size=(2, 2))(conv3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool3)
conv4 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv4)
drop4 = Dropout(0.5)(conv4)
pool4 = MaxPooling2D(pool_size=(2, 2))(drop4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(pool4)
conv5 = Conv2D(1024, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv5)
drop5 = Dropout(0.5)(conv5)
up6 = Conv2D(512, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(drop5))
merge6 = concatenate([drop4,up6], axis = 3)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge6)
conv6 = Conv2D(512, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv6)
up7 = Conv2D(256, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv6))
merge7 = concatenate([conv3,up7], axis = 3)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge7)
conv7 = Conv2D(256, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv7)
up8 = Conv2D(128, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv7))
merge8 = concatenate([conv2,up8], axis = 3)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge8)
conv8 = Conv2D(128, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv8)
up9 = Conv2D(64, 2, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(UpSampling2D(size = (2,2))(conv8))
merge9 = concatenate([conv1,up9], axis = 3)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(merge9)
conv9 = Conv2D(64, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv9 = Conv2D(2, 3, activation = 'relu', padding = 'same', kernel_initializer = 'he_normal')(conv9)
conv10 = Conv2D(1, 1, activation = 'sigmoid')(conv9)
model = Model(input = inputs, output = conv10)
model.compile(optimizer = Adam(lr = 1e-4), loss = 'binary_crossentropy', metrics = ['accuracy'])
#model.summary()
if(pretrained_weights):
model.load_weights(pretrained_weights)
return model
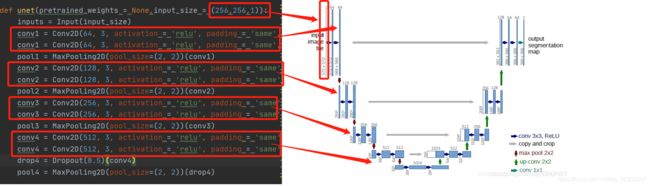
pool4 之前都是降采样的部分,但是这个代码与 unet 原文中使用的数据集不一样,原文输入的图片尺寸可以看到是
(572, 572,1)本文使用的图片尺寸一直都是(256, 256, 1)
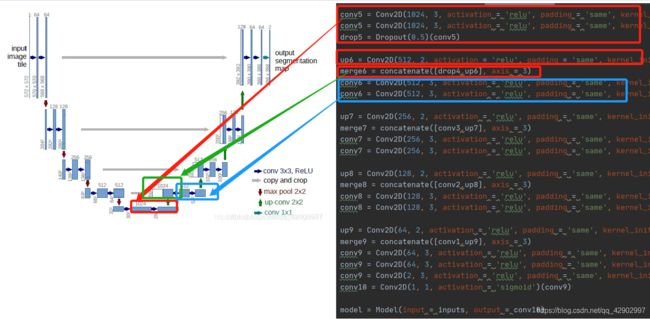
pool5层之后都是上采样的部分,并且在上采样的过程中结合了pool1-pool4提取出的浅层特征,这里使用的concatenate函数来进行矩阵的结合。
concatenate 函数 :只是简单的拼接两个矩阵,axis = 0 时,两个矩阵具有相同的列数即可;axis =1 时,需要两个被拼接的矩阵有相同的行数;对于一个二维矩阵只有两个维度,所以 axis 可以按 行(axis=0)或者列(axis=1) 来进行合并,那么当我们的矩阵维度再增多,如文中的数据,axis = 3 证明在进行运算之后,我们的数据已经变成了 4 维的数据 其中前三维是 (256,256,1) 分别代表长、宽、颜色通道,后面的维度代表 卷积层的个数,这是第四维度
也就是说,卷积操作把数据变 “厚” 了,多了一个维度,而且这个维度的数字代表的是卷积核的个数。举个例子来说
(256,256,1)的数据,经过了这一层 64 个卷积核的卷积操作,得到的结果数据的维度就是(256,256,1,64)如果卷积的过程中对边界进行填充的话;详细卷积的知识自己去上网看博客,这里不再细讲。
import numpy as np
arr = np.array([[1,2,3],[4,5,6]])
arr2 = np.array([[7,8,9],[10,11,12]])
arr3 = np.concatenate((arr,arr2))
print(arr3)

从代码上来看,整个 unet 的结构并不复杂,而且它可以全面的利用在降采样过程中提取的各种浅层的特征。
最后使用了 1*1 规模的卷积层,结合softmax函数进行分类,由于在一开始参数设置的时候 flag_multi_class=False 所以分类的时候就是 1 类,如果这个地方 flag_multi_class=True 那么 num_class 有几类,最后的 1*1 规模的卷积层的通道数就是几
一点尾巴
在 data.py 里面还有几个函数没有进行详细分析,但是都非常简单,大家可以结合这篇博客自己去看一下;希望能对大家有所帮助;如果有什么写的不对的地方,希望大家给予指正