深度学习中的优化函数optimizer SGD Adam AdaGrad RMSProp
当前深度学习中使用到的主流的优化函数有:
1. BGD(Batch Gradient Descent),SGD(Stochastic Gradient Descent)和MBGD(Mini-Batch Gradient Descent)
2. Momentum & Nesterov Momentum
3. AdaGrad
4. RMSProp
5. Adam
1. BGD(Batch Gradient Descent),SGD(Stochastic Gradient Descent)和MBGD(Mini-Batch Gradient Descent)
这三类优化算法是最早的优化算法,它们之前的不同之处是训练时输入图片数量不同。
1.1 BGD(Batch Gradient Descent)
BGD是采用整个训练集的数据来计算损失函数对参数的梯度。计算公式如下所示:
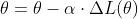
 表示当前我们需要更新的模型参数,
表示当前我们需要更新的模型参数, 表示当前的学习率,
表示当前的学习率,![]() 表示 在损失函数上的偏导数。
表示 在损失函数上的偏导数。
该算法的优缺点:每次需要计算整个数据集的梯度,计算量很大,大量的训练数据很难实现。对于损失函数是凸函数来说可以把模型优化到全局最优点的位置,对于损失函数是非凸函数来说很容易把模型优化到局部极小点。
1.2 SGD(Stochastic Gradient Descent)
SGD则是在训练过程中每次输入一张图片进行训练,这样不会像BGD一样需要大量的计算资源。计算公式如下所示:
公式和BGD一致,只是每次处理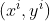 这一张图片。
这一张图片。
该算法的优缺点:优点是计算量小,计算速度快,又概率跳出BGD中提到的局部极小点。缺点是训练过程中损失函数波动很大,容易困在鞍点,对噪声特别敏感(因为每次只输入一张图片,每张图片的质量参差不齐)。
1.3 MBGD(Mini-Batch Gradient Descent)
MBGD在训练时每次输入小批量的数据进行训练。这样既可以不像BGD那样每次输入所有数据导致计算太大,又可以解决SGD每次输入一张图片导致训练损失急剧波动的问题。计算公式如下所示:
该算法的优缺点:优点是计算效率高,收敛稳定。缺点是需要不断调整学习率,也是容易被困在鞍点处。
2. Momentum & Nesterov Momentum
2.1 Momentum
Momentum动量,模拟物理中的物体运动惯性。当模型参数一直朝某个方向运动是,我们可以加快运动的步伐,当运行方向发生改变时我们就减慢朝之前运动方向的步伐。计算公式如下所示:
![]()
![]()
Momentum会观察前面的历史梯度,当前梯度如果和历史梯度一致,就会增强这个方向梯度下降的力度,如果当前梯度和历史梯度不一致,那么就会减弱当前方向梯度下降的力度。
2.2 Nesterov Momentum
在Momentum基础上做了该进,在梯度下降过程中,我们希望知道前面的梯度是否和当前的梯度一致,如果不一致那么我们可以提前进行减速操作。相当于增加了预测的功能。公式如下所示:
![]()
就表示该算法计算后面的位置的梯度,做了一个位置的展望梯度计算。
3. AdaGrad
前面的优化算法都是使用固定的学习率进行梯度优化,AdaGrad则是在训练中对学习率进行自动调整,对于出现频率较高的参数使用较低的学习率,出现频率较少的参数使用较高的学习率。计算公式如下所示:
上面公式是AdaGrad的整体算法。G表示对角矩阵,每个对角线的数据对应参数从第一次到第N次的训练梯度值, 是一个平滑项,防止分母为0。
是一个平滑项,防止分母为0。
该算法的优缺点:优点是自动调整学习率,非常适合处理稀疏的数据(训练样本数量不均)。缺点是G的数值会随着迭代的次数不断得增加,从而造成梯度消失的问题,使得训练提前结束。
4. RMSProp
RMSProp是对AdaGrad的算法改进,Adagrad是累加之前所有的梯度平方,RMSProp增加计算对应的平均值,缓解学习率飞速下降的问题。
![]()
![]()
![]()
 函数表示求当前累加梯度的平均值。第二个公式表示之前的累加梯度平均值加上当前梯度就是当前梯度的衰减平均值。
函数表示求当前累加梯度的平均值。第二个公式表示之前的累加梯度平均值加上当前梯度就是当前梯度的衰减平均值。
5. Adam
Adam是对前面算法的一个结合,既存储了过去梯度的平方指数衰减平均值,也保存了过去梯度的指数衰减平均值。公式如下所示:
![]()
![]()
如果m和v被初始化为0,会向0进行偏置,最后对m和v做了偏差矫正。偏差矫正公式为:
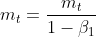

最后Adam的梯度更新公式如下所示:
![]()
综上就是Adam的整体算法公式,结合了上面优化算法的优点,可以有效处理稀疏数据。