【机器学习】——梯度下降法的收敛性证明(详解)
阅读之前看这里:博主是一名正在学习数据类知识的学生,在每个领域我们都应当是学生的心态,也不应该拥有身份标签来限制自己学习的范围,所以博客记录的是在学习过程中一些总结,也希望和大家一起进步,在记录之时,未免存在很多疏漏和不全,如有问题,还请私聊博主指正。
博客地址:天阑之蓝的博客,学习过程中不免有困难和迷茫,希望大家都能在这学习的过程中肯定自己,超越自己,最终创造自己。
目录
- 1.梯度下降法的原理和作用
- 2.为什么梯度下降可以收敛?
-
- 1.泰勒级数
- 2.如何利用泰勒公式求损失函数最小值
为什么要写这篇博客呢?因为博主在面试的时候遇到了面试官问了这个问题,但是没有回答上来。而且博主也在网上去搜了很多解答,关于梯度下降法为什么收敛,很多解释都不够清晰,要么涉及到最优化或者凸优化的公式证明,确实比较复杂。博主又去看了李宏毅的2020版机器学习视频,发现在里面解释的很清楚,所以借花献佛,写一篇博客,既是解答自己的疑惑,也是解决大家的疑惑。
关于梯度下降法,博主之前已经在两篇文章中提及了,分别是:
1.数据分析面试【面试经验】-----总结和归纳
2.【机器学习】—各类梯度下降算法 简要介绍
不过上面只有基础的原理部分,大家如果只需要了解梯度下降法的作用,有兴趣可以看看这两篇博客。
1.梯度下降法的原理和作用
梯度下降法简单来说就是一种寻找目标函数最小化的方法。
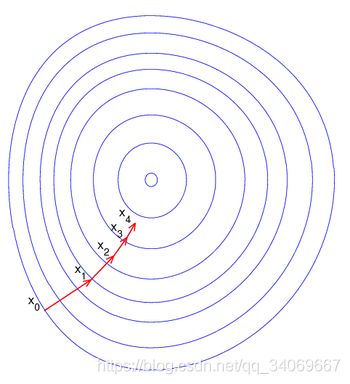
梯度下降法的优化思想是用当前位置负梯度方向作为搜索方向,因为该方向为当前位置的最快下降方向,所以也被称为是”最速下降法“。最速下降法越接近目标值,步长越小,前进越慢。梯度下降法的搜索迭代示意图如下图所示:
在机器学习中,我们需要解决的问题一般是求使得损失函数最小的参数问题:
θ ∗ = a r g m i n θ L ( θ ) L : l o s s f u n c t i o n θ : p a r a m e t e r s \theta^* = arg\mathop{min}\limits_{\theta} L(\theta) \\ L:loss function \\ \theta:parameters θ∗=argθminL(θ)L:lossfunctionθ:parameters
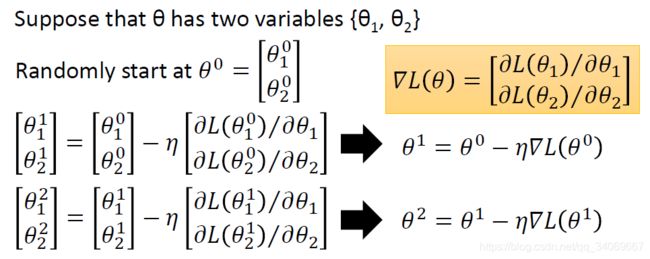
假设 θ \theta θ包含两个变量{ θ 1 , θ 2 \theta_1,\theta_2 θ1,θ2},初始值为 θ 0 \theta^0 θ0,设为 [ θ 1 0 θ 2 0 ] \begin{bmatrix} \theta_1^0 \\\theta_2^0\end{bmatrix} [θ10θ20],所以可以按照梯度下降公式得到更新的参数,然后进行不断迭代。
2.为什么梯度下降可以收敛?
通过上面的方程,或者算法,有一个疑问?就是每次梯度更新得到的新的值一定比原来的小吗?也就是梯度下降为何一定是收敛的呢?

相信很多人知道,不一定更小,在这里我没有介绍学习率步长的知识,大家可以自行查阅,这不是本文章的重点内容。若学习率设置很大,步长太大,可能导致并不能收敛,也就是会导致损失函数很大,如下图所示:
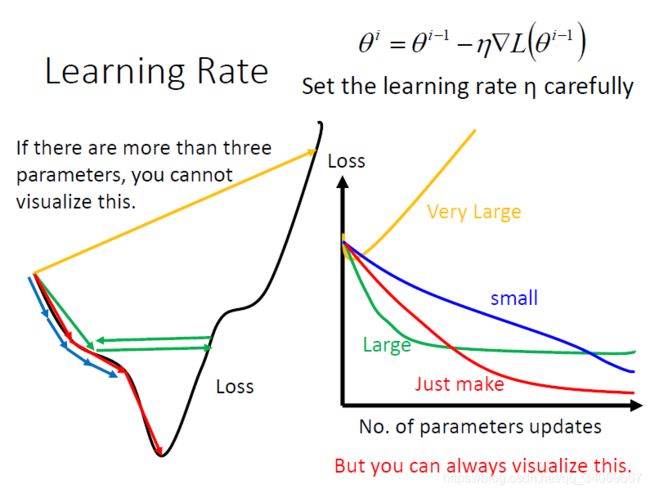
那么如何去找到收敛的最低点,也就是找到使得损失函数最小的参数的值。
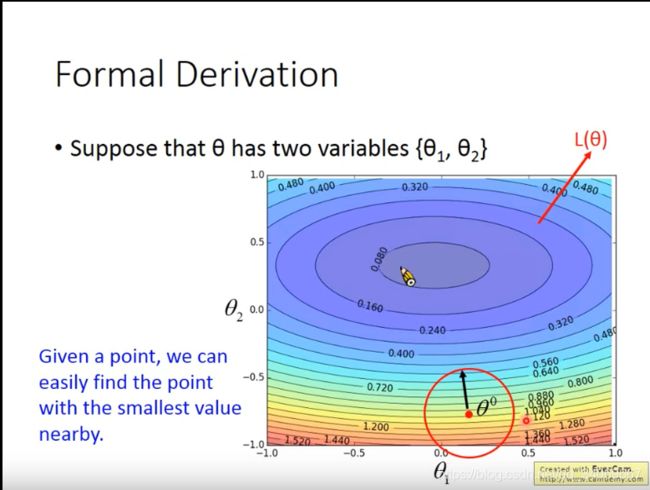
通过初始值 θ 0 \theta_0 θ0画圈,找到其中的最小值。

接下来再以 θ 1 \theta_1 θ1为中心画圈,找到最小的点,重复以上步骤,不断更新参数。
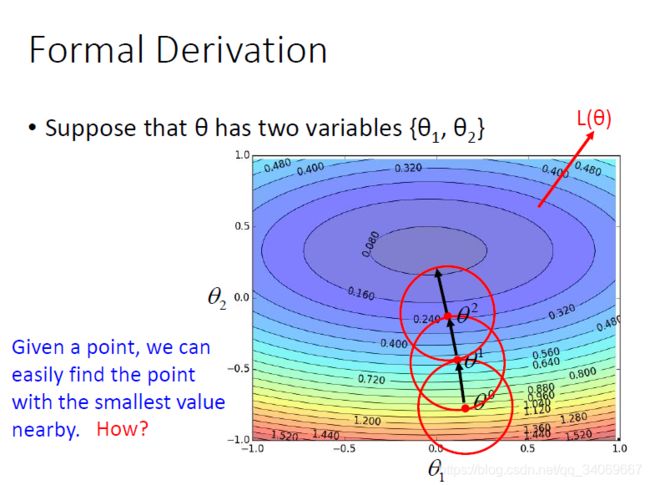
现在的问题是如何在红色的圈里找到最小的值或者最小的点呢?
要用到泰勒公式(Taylor Series)。
1.泰勒级数
泰勒公式(Taylor Series)能把大多数的函数展开成幂级数,即
f ( x ) = ∑ k = 1 N A n x n f(x)=\sum_{k=1}^N A_nx^n f(x)=k=1∑NAnxn
式子当中只有加法与乘法,容易求导,便于理解与计算。这种特性使得泰勒公式在数学推导(如:微分方程以幂级数作为解),数值逼近(如:求e、开方),函数逼近(在计算机某些计算优化时,可以把某些繁琐的式子进行泰勒展开,仅保留加法与乘法运算),复分析等多种应用中有广泛应用。

通过以上泰勒展开式,我们知道可以假设 h ( x ) h(x) h(x)在 x = x 0 x=x_0 x=x0
处是无穷可微的,即可得到其泰勒展开式为:
h ( x ) = ∑ k = 0 ∞ h k ( x 0 ) k ! ( x − x 0 ) k = h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) + h ′ ′ ( x 0 ) 2 ! ( x − x 0 ) 2 + . . . h(x)=\sum_{k=0}^\infty \frac{h^{k}(x_0)}{k!}(x-x_0)^k \\ =h(x_0)+h^\prime(x_0)(x-x_0)+\frac{h''(x_0)}{2!}(x-x_0)^2+... h(x)=k=0∑∞k!hk(x0)(x−x0)k=h(x0)+h′(x0)(x−x0)+2!h′′(x0)(x−x0)2+...
k k k:微分的次数
当 x x x很接近 x 0 x_0 x0的时候: ( x − x 0 ) ≫ ( x − x 0 ) 2 ≫ ( x − x 0 ) 3 ≫ . . . ≫ ( x − x 0 ) n (x-x_0)\gg(x-x_0)^2\gg(x-x_0)^3\gg...\gg(x-x_0)^n (x−x0)≫(x−x0)2≫(x−x0)3≫...≫(x−x0)n,所以高次项可以删掉,即:
h ( x ) ≈ h ( x 0 ) + h ′ ( x 0 ) ( x − x 0 ) h(x) \approx h(x_0)+h'(x_0)(x-x_0) h(x)≈h(x0)+h′(x0)(x−x0)
例子如下: s i n ( x ) sin(x) sin(x)的在 x 0 = π / 4 x_0=\pi/4 x0=π/4泰勒展开式
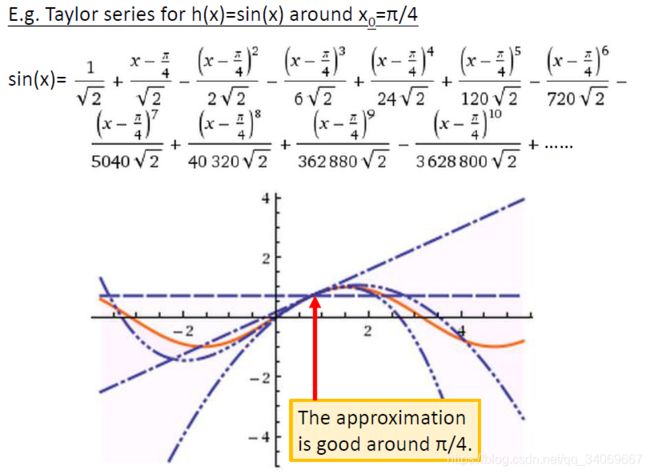
当然泰勒公式也可以有多个参数,如下:

2.如何利用泰勒公式求损失函数最小值
那我们再回到之前的问题:如何利用泰勒公式求之前红圈最小的值
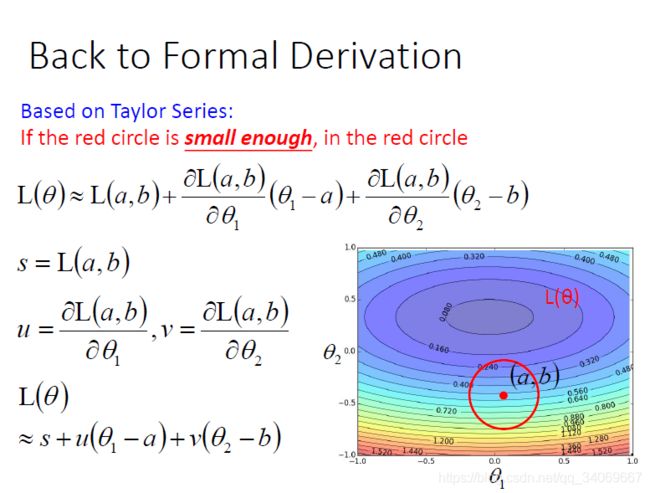
在这里,将损失函数 L ( θ ) L(\theta) L(θ)进行泰勒展开为:
L ( θ ) = L ( a , b ) + ∂ L ( a , b ) ∂ θ 1 ( θ 1 − a ) + ∂ L ( a , b ) ∂ θ 2 ( θ 2 − b ) L(\theta)=L(a,b)+\frac{\partial L(a,b)}{\partial \theta_1}(\theta_1 - a)+\frac{\partial L(a,b)}{\partial \theta_2}(\theta_2 - b) L(θ)=L(a,b)+∂θ1∂L(a,b)(θ1−a)+∂θ2∂L(a,b)(θ2−b)
然后进行替代和简化得到:
L ( θ ) ≈ s + u ( θ 1 − a ) + v ( θ 2 − b ) L(\theta) \approx s+u(\theta_1-a)+v(\theta_2 -b) L(θ)≈s+u(θ1−a)+v(θ2−b)
这个 L ( θ ) L(\theta) L(θ)即红色圈里的表达式,现在要找圈里的最小值,即 L ( θ ) L(\theta) L(θ)最小。

下图即找到最小值:不考虑 s s s的情况下,只需要招 ( u , v ) (u,v) (u,v)反方向延长到圆的边界即可

所以最小值为:
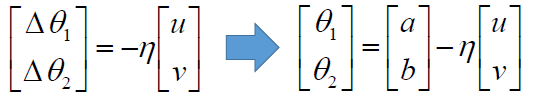
将 u , v u,v u,v的值代入方程可以得到:

所以就得到了梯度下降的公式, η \eta η代表学习率, u , v u,v u,v就是损失函数的偏导。
和之前的公式一致:
不过此方法也有一个前提: L ( θ ) ≈ s + u ( θ 1 − a ) + v ( θ 2 − b ) L(\theta) \approx s+u(\theta_1-a)+v(\theta_2 -b) L(θ)≈s+u(θ1−a)+v(θ2−b)
这个公式是成立的,意思是我们画出的红色的圈要足够小,也就是学习率不能太大,要较小才能成立。理论上就是学习率要足够小。
其它方法:牛顿迭代法,也就是进行二阶求导,或者是说二次微分,运算可能较大。
参考:李宏毅《机器学习》2020版视频
———————————————————————————————————————————————
博主码字不易,大家关注点个赞转发再走呗 ,您的三连是激发我创作的源动力^ - ^
