Unity热更新技术学习——Lua,Luajit
文章目录
-
- Lua
-
-
- 预编译资源
- 使用 Lua
- luajit
-
- 其他语言
- 关于JIT
-
-
- IOS 和 JIT
- IOS 和 jit 的后话
-
Lua
Lua是一门轻量级的脚本语言,使用C语言编写,编译器和解释器也是C语言编写。
下载资源:
- 源码 http://www.lua.org/ftp/
- 预编译好的Lua库和编译器 http://luabinaries.sourceforge.net/
预编译资源
下载第二个预编译好的lua资源(windows平台),包含如下文件:
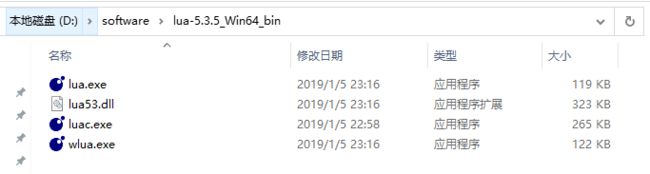
| 文件 | 描述 |
|---|---|
| lua.exe | lua脚本的编译器 |
| lua53.dll | lua5.3的库 |
| luac.exe | 它将lua脚本翻译成字节码并输出到文本,而不会去执行。 |
| wlua.exe | windows下的lua.exe |
使用 Lua
将上面lua.exe所在的目录加入环境变量。新建一个lua脚本:test.lua。循环执行一段包含取余,乘法和加法的运算。然后测量其执行时间。
st = os.clock()
a = 1
for i = 1, 100000000 do
b = i % 1000
a = b * b + 1
end
et = os.clock()
print(string.format("cost time: %.2f s", (et - st)))
在命令行中敲入:
lua test.lua
结果:

luajit
luajit是Lua的另一款编译器,采用了JIT —— Just In Time技术。从 luajit 官网 扒下来一张图它与普通的lua的编译器的速度区别(Arm 架构):
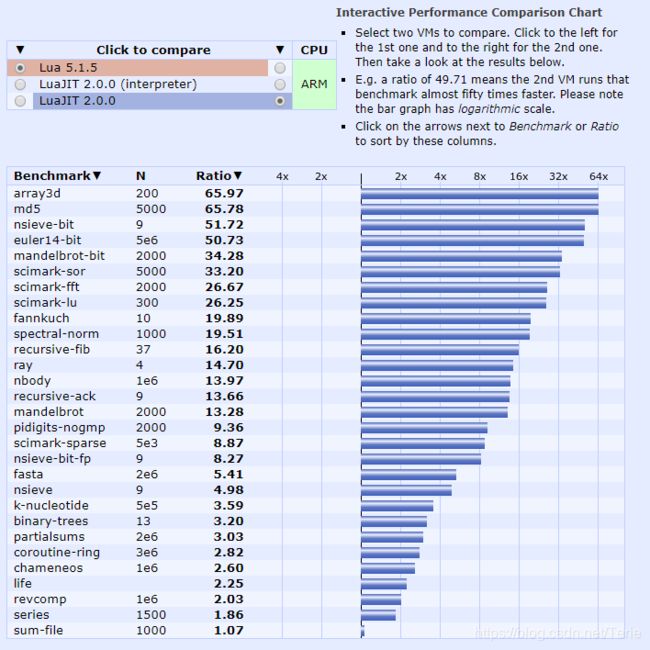
图中显示,在多种基准测试中,luajit最快可以达到普通lua编译器的64倍。
我没找到它提供的预编译的版本,所以就先在 这里 下载luajit的源码。选择最新的stable版本即可。
在编译之前,你需要在电脑中安装好gcc和make工具,windows下推荐使用Cygwin工具下载,并使用阿里的Cygwin镜像。
解压源码,可以看到如下文件:
将命令行定位到当前目录,执行:
make
之后你就可以在 src 目录下找到 luajit.exe 了。
然后将src目录加入环境变量,并用luajit编译上面的lua脚本:
luajit test.lua
结果:
![]()
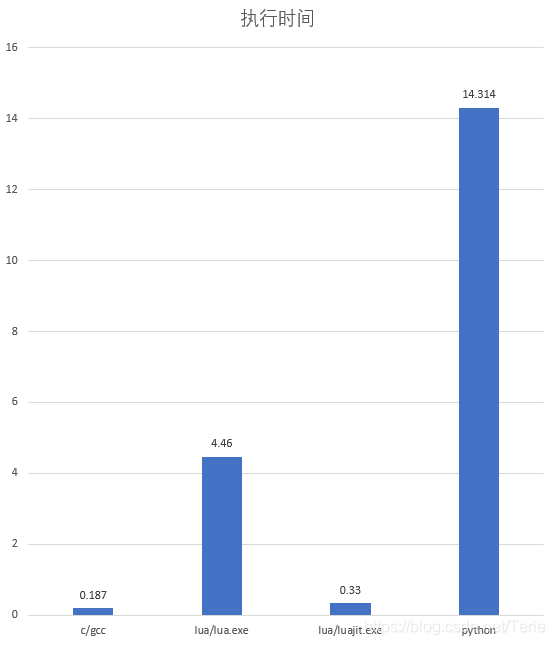
快了13倍!
其他语言
同样可以编写类似的C语言程序和python程序:
#include import time
st = time.time()
a = 1
for i in range(100000000):
b = i % 1000
a = b * b + 1
et = time.time()
print(f"cost time: {et - st} s")
C语言的结果:

Python的结果:
![]()
关于JIT
一般来说,将我们书写的源代码转化成目标机器CPU能够识别的机器指令有两种方法:
- 直接将源代码转化成机器码,然后执行程序;
- 实现一个解释器,然后使用解释器一句一句地将源码翻译成机器码并执行。
Lua就是第二种方式。lua.exe中的编译程序将lua源代码转化成平台无关的伪代码——字节码,然后再由解释程序将字节码一句句解释成机器码并执行。字节码的出现让语言能够很轻松地移植到多平台运行,而你只需要实现不同平台下的解释器即可。
Pascal是最早使用中间伪代码的一种语言,那时候,这种中间伪代码还叫(P-Code,即Pascal Code),后来被这个名称渐渐被字节码所取代,因为大多数的语言的中间伪代码都是一个字节的长度。
跨平台的问题解决了,却产生了性能问题。将字节码解释成机器码再执行肯定不如直接执行机器码来得快。而JIT的出现就是为了尝试结合两者的优点。它会在运行时将一部分经常执行的字节码转化成机器码,然后之后都会直接执行机器码。
理论上如果程序运行的时间足够长,那JIT的性能应当和静态编译的程序性能很相近。
一些采用JIT技术的例子:
- Java:JVM(Java Virtual Machine)
- C#:CLR(Common Language Runtime)
- Android:DVM(Dalvik Virtual Machine),ART(Android RunTime)
在Java的例子中,JVM会追踪每个函数的执行计数,如果执行计数超过某个阈值,JVM会将该函数的字节码转化成机器码,之后执行到该函数的时候就直接执行机器码,而不是重复逐行解释逐行运行。
IOS 和 JIT
假如有这么一段代码:
int a = 1;
int b = a * 3 + 2;
然后虚拟机将它翻译成如下的字节码(下面用伪代码代替):
asg a 1 // 赋值
asg temp [a] // 赋值
mul temp 3 // 乘
add temp 2 // 加
asg b [temp] // 赋值
上面有三种不同的字节码,即赋值(asg),乘法(mul),加法(add),虚拟机进一步解释字节码可以这么写:
void exec_bytecode(bytecode){
string code_name = bytecode[0]; // 字节码的第一部分,表示操作
val code_val_1 = bytecode[1]; // 字节码的第二部分,第一个操作数
val code_val_2 = bytecode[2]; // 字节码的第三部分,第二个操作数
switch(code_name){
case "asg":
set_register_val(code_val_1, code_val_2); // 为一个与 code_val_1 关联的寄存器赋值
break;
case "mul":
mul_register_val(code_val_1, code_val_2); // 将 code_val_1 关联的寄存器中的值乘以 code_val_2 然后放回 code_val_1 关联的寄存器中。
break;
case "add":
add_register_val(code_val_1, code_val_2); // 将 code_val_1 关联的寄存器中的值加上 code_val_2 然后放回 code_val_1 关联的寄存器中。
break;
default:
// do something...
}
}
某个实现了JIT的虚拟机需要将某一段字节码转化成机器码,为此它需要做这么几件事情:
- 申请一个可执行内存,将翻译后的机器码放入内存中
- 每当CPU执行到该函数的时候,虚拟机将CPU的指令寄存器修改到机器码所在的地址
然而在IOS中,第一步的申请可执行内存就是被禁止的行为。
每当提交一个应用程序给Apple时,它会对你的代码做审核和代码签名,标识你的程序所在的地址空间是可执行的。但它不允许你的程序新申请别的可执行内存,因为它绕过了Apple的代码验证。
更详细地说,无论从你的源码所生成的字节码是什么,字节码都不是可执行的。
- 如果你不采用JIT,最终执行的就是虚拟机中的代码,因为虚拟机已经写好了如何“解释”字节码的程序,你只需要运行这部分程序就可以了,而这部分代码在应用程序提交给Apple的时候就已经做过代码签名验证了。
- 相反,如果你采用JIT,你为字节码新生成的机器码是新的可执行代码,这在Apple看来是不被允许的。
这也就是为什么Lua的JIT在IOS平台上是不可用的原因,不过这也是后话了。
IOS 和 jit 的后话
IOS禁止jit已经是众所周知了,但是macOS是可以使用JIT的。只需要在申请内存的时候,给系统传递个 MAP_JIT 即可。请参考:
Allow Execution of JIT-compiled Code Entitlement
2020-10-12 补充:上面测试速度的代码例子可能不太准确,但是不同解释器/编译器的速度排序是对的。因为C的编译器在实际使用的时候往往会至少开启-O2级别的优化,做了优化之后,上面for循环中,实际只做了1000遍运算(因为往后,b和a都是重复赋值),所以C的运算结果耗时打印为0。
另外,尽管luajit无法在IOS上使用,但是luajit提供了解释器模式来兼容IOS平台。在windows/linux上,我们可以给luajit加上-joff参数来使用解释器模式而不是JIT模式。这个测试下来会发现,luajit的解释器依然比lua原生的解释器要快上一倍左右。