BEVFormer 论文笔记
参考代码:BEVFormer
paper:BEVFormer: Learning Bird’s-Eye-View Representation from Multi-Camera Images via Spatiotemporal Transformers
1. 概述
导读:这篇文章介绍了一种基于transformer的bev特征提取算法,在该算法中包含了对空间域和时间域信息的融合,对应的模块便是spatial cross-attention和temporal self-attention,这样便可以高效感知车辆周围环境以及利用前后帧信息处理遮挡情况。通过建立3d bev grid在spatial和temporal维度的信息索引,文章构建了一种适合多任务的bev特征提取方法。
在文章的bev特征提取方案中需要解决的是bev grid(3D)在多视图图像中的空间索引,以及当前帧bev特征与之前帧中bev特征的关联,也就是下图中展示的spatial和temporal维度信息如何去索引:

对于spatial维度上的特征索引,可以通过3D bev grid中的点从3D到2D的投影获得reference points,之后在reference points的基础上添加具有偏移属性deformable attention操作去感知local区域的特征。对于temporal维度上的索引,可以通过类似RNN的机制实现序列关联。
2. 方法设计
2.1 整体pipeline
文章的整体pipeline见下图所示:

根据上图文章的方法可以划分为如下几个步骤:
- 1)通过CNN网络抽取多视图特征,更大的backbone带来更好的性能;
- 2)通过堆叠多层的temporal self-attention和spatial cross-attention(transformer layer)实现3d bev grid的特征索引构建对应bev特征;
- 3)在上述得到的bev特征的基础上添加多任务头,实现多任务预测;
2.2 spatial cross-attention
在进行spatial cross-attention之前需要计算预先定义好的3d bev特征在输入多视图特征的位置,这些位置被称之为reference points。其计算是根据3d空间到2d空间的投影实现的,具体的映射过程可以参考:
# projects/mmdet3d_plugin/bevformer/modules/encoder.py#L90
def point_sampling(self, reference_points, pc_range, img_metas):
...
在上述的代码中除了计算每个3d bev grid到多视图特征的投影,还会通过这些投影操作(记为 P ( p , i , j ) \mathcal{P}(p,i,j) P(p,i,j))预先计算出可能投影到的位置(文章将这些通过相机参数匹配上的点称之为 V h i t \mathcal{V}_{hit} Vhit,其可能在多个视图上),从而得到一个掩膜mask,该mask就可以在多视图特征中排除一些无关的区域,从而加快运算速度。那么对于当前3d bev grid的索引 Q p Q_p Qp其在多视图特征下的计算可以描述为:
S C A ( Q p , F t ) = 1 V h i t ∑ i ∈ V h i t ∑ j = 1 N r e f D e f o r m A t t n ( Q p , P ( p , i , j ) , F t i ) SCA(Q_p,F_t)=\frac{1}{\mathcal{V}_{hit}}\sum_{i\in \mathcal{V}_{hit}}\sum_{j=1}^{N_{ref}}DeformAttn(Q_p,\mathcal{P}(p,i,j),F_t^i) SCA(Qp,Ft)=Vhit1i∈Vhit∑j=1∑NrefDeformAttn(Qp,P(p,i,j),Fti)
其中的deformable attention的计算过程描述为:
D e f o r m A t t n ( q , p , x ) = ∑ i = 1 N h e a d W i ∑ j = 1 N k e y A i j ⋅ W i ′ x ( p + Δ p i , j ) DeformAttn(q,p,x)=\sum_{i=1}^{N_{head}}\mathcal{W}_i\sum_{j=1}^{N_{key}}\mathcal{A}_{ij}\cdot \mathcal{W}_i^{'}x(p+\Delta_{p_{i,j}}) DeformAttn(q,p,x)=i=1∑NheadWij=1∑NkeyAij⋅Wi′x(p+Δpi,j)
这里需要注意的是 Δ p i , j \Delta_{p_{i,j}} Δpi,j是通过在query的基础上预测得到的:
# projects/mmdet3d_plugin/bevformer/modules/spatial_cross_attention.py#L342
sampling_offsets = self.sampling_offsets(query).view(
bs, num_query, self.num_heads, self.num_levels, self.num_points, 2)
...
sampling_locations = reference_points + sampling_offsets
2.3 temporal self-attention
在上述的spatial cross-attention过程中解决了时空关联,而仅仅依靠时空关联是无法处理一些遮挡情况的case的,这就需要引入前后帧的信息。在这里也是通过transformer的形式进行计算得到的,其计算可以描述为:
T S A ( Q p , { Q , B t − 1 ′ } ) = ∑ V ∈ { Q , B t − 1 ′ } D e f o r m A t t n ( Q p , p , V ) TSA(Q_p,\{Q,B_{t-1}^{'}\})=\sum_{V\in\{Q,B_{t-1}^{'}\}}DeformAttn(Q_p,p,V) TSA(Qp,{Q,Bt−1′})=V∈{Q,Bt−1′}∑DeformAttn(Qp,p,V)
需要注意的是这里deformable attention的偏移是由前一帧的bev特征和当前帧的query确定的,而在初始的时候前一帧bev特征与query相等:
# projects/mmdet3d_plugin/bevformer/modules/temporal_self_attention.py#L191
query = torch.cat([value[:bs], query], -1)
...
sampling_offsets = self.sampling_offsets(query)
2.4 消融实验
上述中的attention操作都是基于deformable的local属性,该attention操作和global和point属性的attention操作在新能上的比较:

不同bev grid的参数设置和transformer layers对耗时和性能的影响:

3. 实验结果
3D检测任务的性能比较:

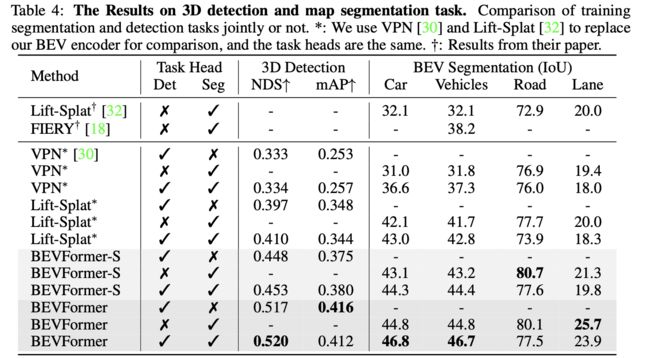
3D检测任务和map分割的性能比较: