使用TensorRT加速Pytorch模型推理
TensorRT是NVIDIA官方推出的模型推理性能优化工具,适用于NVIDIA的GPU设备,可以实现对深度神经网络的推理加速、减少内存资源占用。TensorRT兼容TensorFlow、Pytorch等主流深度学习框架。在工业实践中能够提高基于深度学习产品的性能。本文记录使用TensorRT加速Pytorch模型推理的方法流程,包括TensorRT的安装、将Pytorch模型转换成TensorRT模型、使用TensorRT推理等内容。
首先列出主要参考链接:
(1)官方
- TensorRT主页:NVIDIA TensorRT
- TensorRT快速入门文档:TensorRT快速入门指南
- TensorRT入门示例:(Jupyter Notebook) Getting Started with TensorRT
- Pytorch2TensorRT示例:(Jupyter Notebook) Using PyTorch with TensorRT through ONNX
- TensorRT Runtime介绍及如何选择:(Jupyter Notebook) Runtimes: What are my options? How do I choose?
(2)非官方
- PyTorch模型转TensorRT是怎么实现的?
- PyTorch转TensorRT
- onnx转换tensorrt的两种方法
- TensorRT 命令行程序trtexec常用用法
如果本篇博客的内容仍无法满足您的使用需求,可以直接参考上面给出的参考链接(尤其是官方链接)。
一、安装TensorRT
关于TensorRT的安装可参考官方安装指引.
(1)从 https://developer.nvidia.com/tensorrt 下载与您的系统和CUDA版本相匹配的TensorRT安装包。下载时要求先登录NVIDIA账号并填写一个简单的调查问卷。
(2)下载完成后,在安装包路径下打开命令行,运行下面几行命令:
# 以下命令中的${os}和${tag}根据你下载的版本进行替换:
# os="ubuntuxx04"
# tag="cudax.x-trt8.x.x.x-yyyymmdd"
sudo dpkg -i nv-tensorrt-repo-${os}-${tag}_1-1_amd64.deb
sudo apt-key add /var/nv-tensorrt-repo-${os}-${tag}/7fa2af80.pub
sudo apt-get update
sudo apt-get install tensorrt
如果使用python3.x,还需要:
python3 -m pip install numpy
sudo apt-get install python3-libnvinfer-dev
如果需要ONNX graphsurgeon或使用Python模块,还需要执行以下命令:
python3 -m pip install numpy onnx
sudo apt-get install onnx-graphsurgeon
由于后面很可能需要使用TensorRT Python API,还要安装PyCUDA:
python3 -m pip install 'pycuda<2021.1'
(3)验证安装
dpkg -l | grep TensorRT
应该会看到类似下面的内容:
ii graphsurgeon-tf 8.4.0-1+cuda11.6 amd64 GraphSurgeon for TensorRT package
ii libnvinfer-bin 8.4.0-1+cuda11.6 amd64 TensorRT binaries
ii libnvinfer-dev 8.4.0-1+cuda11.6 amd64 TensorRT development libraries and headers
ii libnvinfer-doc 8.4.0-1+cuda11.6 all TensorRT documentation
ii libnvinfer-plugin-dev 8.4.0-1+cuda11.6 amd64 TensorRT plugin libraries
ii libnvinfer-plugin8 8.4.0-1+cuda11.6 amd64 TensorRT plugin libraries
ii libnvinfer-samples 8.4.0-1+cuda11.6 all TensorRT samples
ii libnvinfer8 8.4.0-1+cuda11.6 amd64 TensorRT runtime libraries
ii libnvonnxparsers-dev 8.4.0-1+cuda11.6 amd64 TensorRT ONNX libraries
ii libnvonnxparsers8 8.4.0-1+cuda11.6 amd64 TensorRT ONNX libraries
ii libnvparsers-dev 8.4.0-1+cuda11.6 amd64 TensorRT parsers libraries
ii libnvparsers8 8.4.0-1+cuda11.6 amd64 TensorRT parsers libraries
ii python3-libnvinfer 8.4.0-1+cuda11.6 amd64 Python 3 bindings for TensorRT
ii python3-libnvinfer-dev 8.4.0-1+cuda11.6 amd64 Python 3 development package for TensorRT
ii tensorrt 8.4.0.x-1+cuda11.6 amd64 Meta package of TensorRT
ii uff-converter-tf 8.4.0-1+cuda11.6 amd64 UFF converter for TensorRT package
ii onnx-graphsurgeon 8.4.0-1+cuda11.6 amd64 ONNX GraphSurgeon for TensorRT package
这样TensorRT就安装成功了,这时在/usr/src/目录下会看到tensorrt目录。
但如果在自己创建的anaconda虚拟环境下运行import tensorrt会报错:“ModuleNotFoundError: No module named ‘tensorrt’”。这就需要我们在虚拟环境下用pip安装tensorrt(个人经验:用pip安装tensorrt之前需要先完成上面的tensorrt安装流程,否则import仍然会报错,虽然官方安装指引里说pip独立安装并不依赖于前面的Tensorrt安装)。
安装前建议先确保pip和setuptools更新到最新:
python3 -m pip install --upgrade setuptools pip
然后可以开始安装nvidia-pyindex:
python3 -m pip install nvidia-pyindex
如果你的项目用到
requirement.txt文件,可以将下面这行写入requirement.txt文件来安装nvidia-pyindex。
--extra-index-url https://pypi.ngc.nvidia.com
然后安装TensorRT Python wheel:
python3 -m pip install --upgrade nvidia-tensorrt
最后验证安装的TensorRT可以在你的虚拟环境下使用:
python3
>>> import tensorrt
>>> print(tensorrt.__version__)
>>> assert tensorrt.Builder(tensorrt.Logger())
至此TensorRT已安装完毕,可以开始使用。如果安装过程中遇到问题,可以优先排查版本兼容性和 官方安装指引 中的重要提示。
二、将Pytorch模型转成TensorRT模型
TensorRT官方提供的模型转换方法共有三种:ONNX、TF-TRT、TensorRT API。
ONNX方法是最高效的方法,且不受限于深度学习框架(ONNX可使模型在不同框架之间进行转移,TensorFlow、Pytorch等框架中的模型都可以导出为onnx模型)。这里介绍的也是ONNX方法。
TF-TRT方法只适用于TensorFlow模型,TensorRT API通常用于处理有可定制化需求、复杂的问题。对于这二者,此处不作深入介绍。
Pytorch模型要转成TensorRT模型需要先转为onnx模型,下面将分两步介绍Pytorch模型——>TensorRT模型的转换步骤:
1. pytorch转为onnx
Pytorch官方教程中提供了将Pytorch模型转为onnx模型并用onnxruntime进行推理的方法 。这里我们以ResNet-50模型为例演示转换过程:
import torch
import torchvision.models as models
import torch.onnx
# 加载带有预训练权重的ResNet-50模型
resnext50_32x4d = models.resnext50_32x4d(pretrained=True)
# 将pytorch模型保存为onnx模型时需要输入一个虚拟的Batch,这里随机生成一个
BATCH_SIZE = 32
dummy_input=torch.randn(BATCH_SIZE, 3, 224, 224)
# 导出为onnx模型
torch.onnx.export(resnext50_32x4d, dummy_input,
"resnet50_onnx_model.onnx", verbose=False)
【题外话】:有时,我们并不需要从Pytorch导出模型,ONNX Model Zoo 中提供了一些带有预训练权重的onnx模型,可以直接从中下载而不需要再手动转换。当然,大多数情况下还是需要我们在pytorch中训练自己的模型,再用上面的方法从pytorch中导出onnx模型。
2. onnx转为trt
有多种工具可帮助我们将模型从ONNX转换为TensorRT引擎,最简单常用的方法是使用TensorRT自带的命令行工具——trtexec,它位于tensorrt/bin目录下(完整的路径通常是:/usr/src/tensorrt/bin)。
至于如何使用它,只需要在trtexec所在的目录下打开命令行,或直接将它复制到你的工作目录下,在命令行中运行如下命令即可实现转换:
./trtexec --onnx=resnet50_onnx_model.onnx --saveEngine=resnet_engine.trt
这里的--onnx和--saveEngine分别代表onnx模型的路径和保存trt模型的路径。此外,再介绍两个比较常用的trtexec命令行工具参数:
--explicitBatch:告诉trtexec在优化时固定输入的 batch size(将从onnx文件中推断batch size的具体值,即与导出onnx文件时传入的batch size一致)。当确定模型的输入batch size时,推荐采用此参数,因为固定batch size大小可以使得trtexec进行额外的优化,且省去了指定“优化配置文件”这一额外步骤(采用动态batch size时需要提供“优化配置文件”来指定希望接收的可能的batch size大小的范围)。--fp16:采用FP16精度,通过牺牲部分模型准确率来简化模型(减少显存占用和加速模型推理)。TensorRT支持TF32/FP32/FP16/INT8多种精度(具体还要看GPU是否支持)。FP32是多数框架训练模型的默认精度,FP16对模型推理速度和显存占用有较大优化,且准确率损失往往可以忽略不计。INT8进一步牺牲了准确率,同时也进一步降低模型的延迟和显存要求,但需要额外的步骤来仔细校准,来使其精度损耗较小。
添加--explicitBatch和--fp16之后的命令为:
./trtexec --onnx=resnet50_onnx_model.onnx --saveEngine=resnet_engine.trt --explicitBatch --inputIOFormats=fp16:chw --outputIOFormats=fp16:chw --fp16
将onnx转为trt的另一种方法是使用onnx-tensorrt的onnx2trt(链接:https://github.com/onnx/onnx-tensorrt ),此处不做介绍,感兴趣可以自己了解。
三、使用TensorRT推理
当我们成功导出TensorRT模型后,该如何使用它进行推理呢?TensorRT将实现推理的方式叫做Runtimes(运行时),TensorRT提供的Runtime选项有:TF-TRT/Python API/C++ API/TRITON。TensorRT官方提供了一个指引笔记——Runtimes: What are my options? How do I choose? ,向我们介绍了这4种Runtime,以及如何根据自己的需求进行选择。
笔记中列出了我们选择Runtime时需要考虑的主要因素:
- Frameork(使用的框架):TF-TRT同模型转换时的TF-TRT一样,只适用于TensorFLow框架。当我们使用其它框架时首先要排除掉TF-TRT。
- Time-to-solution(可以理解为任务的紧急程度):TF-TRT可以“开箱即用”,当我们需要快速解决问题且ONNX方法失败时,可以优先选择TF-TRT。当然前提是你使用的TensorFlow框架。
- Serving needs:(这方面我不是很了解,直接把笔记中的原话放上来)“TF-TRT can use TF Serving to serve models over HTTP as a simple solution. For other frameworks (or for more advanced features) TRITON is framework agnostic, allows for concurrent model execution or multiple copies within a GPU to reduce latency, and can accept engines created through both the ONNX and TF-TRT paths”
- Performance(性能):不同的Runtime性能也不同,通常TF-TRT通常比直接使用ONNX和C++ API要慢。
根据以上这些考量,我们此处选用的Runtime是Python API,对于其它Runtime选项就不作详细介绍了。关于Python API的使用方法,TensorRT的开发者指南 中有比较详细的介绍。此外,官方提供的Pytorch经ONNX转TensorRT 示例中演示了Python API的使用。下面我们也演示一下使用Python API进行模型推理的过程:
import numpy as np
import tensorrt as trt
import pycuda.driver as cuda
import pycuda.autoinit
import time
# 1. 确定batch size大小,与导出的trt模型保持一致
BATCH_SIZE = 32
# 2. 选择是否采用FP16精度,与导出的trt模型保持一致
USE_FP16 = True
target_dtype = np.float16 if USE_FP16 else np.float32
# 3. 创建Runtime,加载TRT引擎
f = open("resnet_engine.trt", "rb") # 读取trt模型
runtime = trt.Runtime(trt.Logger(trt.Logger.WARNING)) # 创建一个Runtime(传入记录器Logger)
engine = runtime.deserialize_cuda_engine(f.read()) # 从文件中加载trt引擎
context = engine.create_execution_context() # 创建context
# 4. 分配input和output内存
input_batch = np.random.randn(BATCH_SIZE, 224, 224, 3).astype(target_dtype)
output = np.empty([BATCH_SIZE, 1000], dtype = target_dtype)
d_input = cuda.mem_alloc(1 * input_batch.nbytes)
d_output = cuda.mem_alloc(1 * output.nbytes)
bindings = [int(d_input), int(d_output)]
stream = cuda.Stream()
# 5. 创建predict函数
def predict(batch): # result gets copied into output
# transfer input data to device
cuda.memcpy_htod_async(d_input, batch, stream)
# execute model
context.execute_async_v2(bindings, stream.handle, None) # 此处采用异步推理。如果想要同步推理,需将execute_async_v2替换成execute_v2
# transfer predictions back
cuda.memcpy_dtoh_async(output, d_output, stream)
# syncronize threads
stream.synchronize()
return output
# 6. 调用predict函数进行推理,并记录推理时间
def preprocess_input(input): # input_batch无法直接传给模型,还需要做一定的预处理
# 此处可以添加一些其它的预处理操作(如标准化、归一化等)
result = torch.from_numpy(input).transpose(0,2).transpose(1,2) # 利用torch中的transpose,使(224,224,3)——>(3,224,224)
return np.array(result, dtype=target_dtype)
preprocessed_inputs = np.array([preprocess_input(input) for input in input_batch]) # (BATCH_SIZE,224,224,3)——>(BATCH_SIZE,3,224,224)
print("Warming up...")
pred = predict(preprocessed_inputs)
print("Done warming up!")
t0 = time.time()
pred = predict(preprocessed_inputs)
t = time.time() - t0
print("Prediction cost {:.4f}s".format(t))
最后,我来展示一下使用 TensorRT 对 SlowFast 行为识别模型进行推理加速的效果:
注:模型输入尺寸 (BatchSize,num_Clip,num_Channel,num_Frames,height,weight) 为 (1,1,3,32,256,256)。由于单次测试推理时间存在上下浮动,于是试验了10次取平均值。
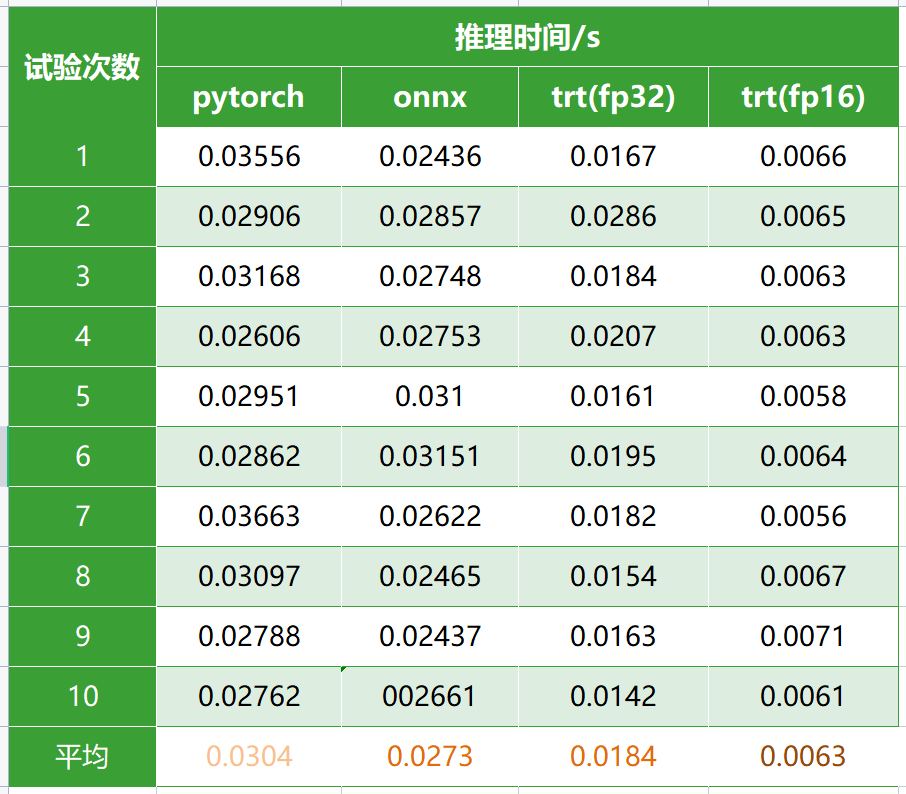
可见,使用TensorRT确实能够较大幅度地加快模型推理速度。