目标检测的Tricks | 【Trick8】数据增强——随机旋转、平移、缩放、错切、hsv增强
如有错误,恳请指出。
在之前使用opencv就介绍使用过一些常用的数据增强的实现方法,见:《数据增强 | 旋转、平移、缩放、错切、HSV增强》,当时介绍了旋转、平移、缩放、错切、HSV增强,但是只是针对了图像的数据增强,并没有涉及到label的变化。
因为,对于分类任务的数据增强来说,只需要对图像进行数据增强就可以了;但是对于目标检测任务来说,图像改变了,也以为着label的位置改变,同样需要作出变换,所以这里我介绍一下目标检测下的数据增强方法。
文章目录
- 1. 随机旋转、平移、缩放、错切
- 2. hsv增强
- 3. 随机翻转(水平与竖直)
- 4. 完整的数据增强代码展示
1. 随机旋转、平移、缩放、错切
这节来介绍其他的数据正确方式,比如仿射变换还有hsv增强,虽然之前我使用opencv进行了部分尝试,详细见:数据增强 | 旋转、平移、缩放、错切、HSV增强,不过这里还是更加yolov3-spp代码进行补充。
YOLOv3-SPP代码:
# train阶段默认为:
# img:(1472, 1472, 3), targets:(k, 5)
# 旋转角度degrees: 0.0, 平移系数translate: 0.0, 缩放因子scale=0.0, 错切角度shear:0.0
# border=-368
def random_affine(img, targets=(), degrees=10, translate=.1, scale=.1, shear=10, border=0):
"""
仿射变换 增强
torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
https://medium.com/uruvideo/dataset-augmentation-with-random-homographies-a8f4b44830d4
:param img: img4 [2 x img_size, 2 x img_size, 3]=[1472, 1472, 3] img_size为我们指定的图片大小
:param targets: labels4 [:, cls+x1y1x2y2]=[7, 5] 相对img4的 (x1,y1)左下角 (x2,y2)右上角
:param degrees: 旋转角度 0
:param translate: 水平或者垂直移动的范围 0
:param scale: 放缩尺度因子 0
:param shear: 裁剪因子 0
:param border: -368 图像每条边需要裁剪的宽度 也可以理解为裁剪后的图像与裁剪前的图像的border
:return: img: 经过仿射变换后的图像 img [img_size, img_size, 3]
targets=[3, 5] 相对仿射变换后的图像img的target 之所以这里的target少了,是因为仿射变换使得一些target消失或者变得极小了
"""
# 对图像进行仿射变换
# torchvision.transforms.RandomAffine(degrees=(-10, 10), translate=(.1, .1), scale=(.9, 1.1), shear=(-10, 10))
# targets = [cls, xyxy]
# 最终输出的图像尺寸,等于img4.shape / 2
height = img.shape[0] + border * 2
width = img.shape[1] + border * 2
# Rotation and Scale
# 生成旋转以及缩放矩阵
R = np.eye(3) # 生成对角阵
a = random.uniform(-degrees, degrees) # 随机旋转角度
s = random.uniform(1 - scale, 1 + scale) # 随机缩放因子
R[:2] = cv2.getRotationMatrix2D(angle=a, center=(img.shape[1] / 2, img.shape[0] / 2), scale=s)
# Translation
# 生成平移矩阵
T = np.eye(3)
T[0, 2] = random.uniform(-translate, translate) * img.shape[0] + border # x translation (pixels)
T[1, 2] = random.uniform(-translate, translate) * img.shape[1] + border # y translation (pixels)
# Shear
# 生成错切矩阵
S = np.eye(3)
S[0, 1] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # x shear (deg)
S[1, 0] = math.tan(random.uniform(-shear, shear) * math.pi / 180) # y shear (deg)
# Combined rotation matrix
# 将三个仿射变换矩阵相乘,即可得到最后的仿射变换矩阵
M = S @ T @ R # ORDER IS IMPORTANT HERE!!
if (border != 0) or (M != np.eye(3)).any(): # image changed
# 进行仿射变化
# 最后输出的图像大小为dsize=(width, height)
img = cv2.warpAffine(img, M[:2], dsize=(width, height), flags=cv2.INTER_LINEAR, borderValue=(114, 114, 114))
# Transform label coordinates
# 对图像的label信息进行仿射变换
n = len(targets)
if n:
# warp points
xy = np.ones((n * 4, 3))
# 求出所有目标边界框的四个顶点(x1y1, x1y2, x2y1, x2y2)
# x1:1, y1:2, x2:3, y2:4
# x1y1:(1,2), x2y2:(3,4), x1y2:(1,4), x2y1:(3,2)
xy[:, :2] = targets[:, [1, 2, 3, 4, 1, 4, 3, 2]].reshape(n * 4, 2) # x1y1, x2y2, x1y2, x2y1
# 对四个顶点坐标进行仿射变换,就是与仿射矩阵进行相乘
# 对于仿射矩阵中,最后一行是没有用的;所有对于坐标点需要增加一维,矩阵相乘后去除
# 这里算是矩阵相乘的一个小trick,比较细节
# [4*n, 3] -> [n, 8]
xy = (xy @ M.T)[:, :2].reshape(n, 8)
# create new boxes
# 再求出仿射变换后的所有x坐标与y坐标
# 对transform后的bbox进行修正(假设变换后的bbox变成了菱形,此时要修正成矩形)
x = xy[:, [0, 2, 4, 6]] # [n, 4]
y = xy[:, [1, 3, 5, 7]] # [n, 4]
# 这里取xy的最小值作为新的边界框的左上角,取xy的最大值最为新的边界框的右下角
# 因为随机变换有可能将图像进行旋转,那么边界框也会选择,所以这时候需要对选择的边界框进行修正为不旋转的矩形,而不是菱形◇
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T # [n, 4]
# reject warped points outside of image
# 对坐标进行裁剪,防止越界,最小值为0,最大值为对于的宽高
xy[:, [0, 2]] = xy[:, [0, 2]].clip(0, width)
xy[:, [1, 3]] = xy[:, [1, 3]].clip(0, height)
w = xy[:, 2] - xy[:, 0]
h = xy[:, 3] - xy[:, 1]
# 计算调整后的每个box的面积:{ndarray:(9,)}
area = w * h
# 计算调整前的每个box的面积
area0 = (targets[:, 3] - targets[:, 1]) * (targets[:, 4] - targets[:, 2])
# 计算每个box的比例
ar = np.maximum(w / (h + 1e-16), h / (w + 1e-16)) # aspect ratio
# 选取长宽大于4个像素,且调整前后面积比例大于0.2,且比例小于10的box
i = (w > 4) & (h > 4) & (area / (area0 * s + 1e-16) > 0.2) & (ar < 10)
# 筛选边界框,所以其实经过仿射变换后的有些标签信息是使用不上的,也就是被忽略掉了
targets = targets[i]
# 变换后的边界框信息重新赋值
targets[:, 1:5] = xy[i]
return img, targets
# 对图像与标签应用仿射变换
img4, labels4 = random_affine(img4, labels4, # 输入图片与边界框信息
degrees=self.hyp['degrees'], # 旋转角度
translate=self.hyp['translate'], # 平移系数
scale=self.hyp['scale'], # 缩放系数
shear=self.hyp['shear'], # 错切角度
border=-s // 2) # 这里的s是期待输出图片的大小
旋转后需要对边界框坐标进行修正:

对应代码为:
# create new boxes
# 再求出仿射变换后的所有x坐标与y坐标
# 对transform后的bbox进行修正(假设变换后的bbox变成了菱形,此时要修正成矩形)
x = xy[:, [0, 2, 4, 6]] # [n, 4]
y = xy[:, [1, 3, 5, 7]] # [n, 4]
# 这里取xy的最小值作为新的边界框的左上角,取xy的最大值最为新的边界框的右下角
# 因为随机变换有可能将图像进行旋转,那么边界框也会选择,所以这时候需要对选择的边界框进行修正为不旋转的矩形,而不是菱形◇
xy = np.concatenate((x.min(1), y.min(1), x.max(1), y.max(1))).reshape(4, n).T # [n, 4]
最后的debug结果:
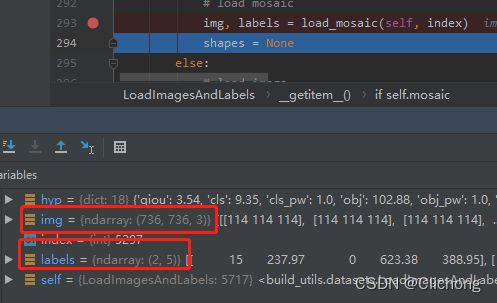
labels会丢失部分标签信息,而img的大小仍然是736x736
2. hsv增强
部分参考,见之前的笔记:数据增强 | 旋转、平移、缩放、错切、HSV增强
YOLOv3-SPP代码:
def augment_hsv(img, h_gain=0.5, s_gain=0.5, v_gain=0.5):
"""
hsv增强 处理图像hsv,不对label进行任何处理
:param img: 待处理图片 BGR [736, 736]
:param h_gain: h通道色域参数 用于生成新的h通道
:param s_gain: h通道色域参数 用于生成新的s通道
:param v_gain: h通道色域参数 用于生成新的v通道
:return: 返回hsv增强后的图片 img
"""
# 从-1~1之间随机生成3随机数与三个变量进行相乘
r = np.random.uniform(-1, 1, 3) * [h_gain, s_gain, v_gain] + 1 # random gains
hue, sat, val = cv2.split(cv2.cvtColor(img, cv2.COLOR_BGR2HSV))
dtype = img.dtype # uint8
# 分别针对hue, sat以及val生成对应的Look-Up Table(LUT)查找表
x = np.arange(0, 256, dtype=np.int16)
lut_hue = ((x * r[0]) % 180).astype(dtype)
lut_sat = np.clip(x * r[1], 0, 255).astype(dtype)
lut_val = np.clip(x * r[2], 0, 255).astype(dtype)
# 使用cv2.LUT方法利用刚刚针对hue, sat以及val生成的Look-Up Table进行变换
img_hsv = cv2.merge((cv2.LUT(hue, lut_hue), cv2.LUT(sat, lut_sat), cv2.LUT(val, lut_val))).astype(dtype)
aug_img = cv2.cvtColor(img_hsv, cv2.COLOR_HSV2BGR, dst=img) # no return needed
# 这里源码是没有进行return的,不过我还是觉得return一下比较直观了解
return aug_img
3. 随机翻转(水平与竖直)
YOLOv3-SPP代码:
# 平移增强 随机左右翻转 + 随机上下翻转
if self.augment:
# 随机左右翻转
# random left-right flip
lr_flip = True
# random.random() 生成一个[0,1]的随机数
if lr_flip and random.random() < 0.5:
img = np.fliplr(img) # np.fliplr 将数组在左右方向翻转
if nL:
labels[:, 1] = 1 - labels[:, 1] # 1 - x_center label也要映射
# 随机上下翻转
# random up-down flip
ud_flip = False
if ud_flip and random.random() < 0.5:
img = np.flipud(img) # np.flipud 将数组在上下方向翻转。
if nL:
labels[:, 2] = 1 - labels[:, 2] # 1 - y_center label也要映射
4. 完整的数据增强代码展示
这里我贴上yolov3-spp中所有的__getitem__处理过程,详情见注释。
YOLOv3-SPP代码:
# 自定义数据集
class LoadImagesAndLabels(Dataset): # for training/testing
def __init__(self,
path, # 指向data/my_train_data.txt路径或data/my_val_data.txt路径
# 这里设置的是预处理后输出的图片尺寸
# 当为训练集时,设置的是训练过程中(开启多尺度)的最大尺寸
# 当为验证集时,设置的是最终使用的网络大小
img_size=416,
batch_size=16,
augment=False, # 训练集设置为True(augment_hsv),验证集设置为False
hyp=None, # 超参数字典,其中包含图像增强会使用到的超参数
rect=False, # 是否使用rectangular training
cache_images=False, # 是否缓存图片到内存中
single_cls=False, pad=0.0, rank=-1):
...
# 注意: 开启rect后,mosaic就默认关闭
self.mosaic = self.augment and not self.rect
...
# 自定义处理格式
def __getitem__(self, index):
"""
一般一次性执行batch_size次
Args:
self: self.img_files: 存放每张照片的地址
self.label_files: 存放每张照片的label的地址
self.imgs=[None] * n cache image 恐怕没那么大的显存
self.labels: 存放每4张图片的label值 [cls+xywh] xywh都是相对值 cache label
并在cache label过程中统计nm, nf, ne, nd等4个变量
self.batch: 存放每张图片属于哪个batch self.shape: 存放每张图片原始的shape
self.n: 总的图片数量 self.hyp self.img_size
数据增强相关变量: self.augment; self.rect; self.mosaic
rect=True: 会生成self.batch_shapes 每个batch的所有图片统一输入网络的shape
index: 传入要index再从datasets中随机抽3张图片进行mosaic增强以及一系列其他的增强,且label同时也要变换
Returns:
torch.from_numpy(img): 返回一张增强后的图片(tensor格式)
labels_out: 这张图片对应的label (class, x, y, w, h) tensor格式
self.img_files[index]: 当前这张图片所在的路径地址
shapes: train=None val=(原图hw),(缩放比例),(pad wh) 计算coco map时要用
index: 当前这张图片的在self.中的index
"""
hyp = self.hyp
# 训练过程使用mosaic数据增强
if self.mosaic:
# load mosaic
img, labels = load_mosaic(self, index)
shapes = None
# 推理阶段使用rect加快推理过程
else:
# load image
img, (h0, w0), (h, w) = load_image(self, index)
# letterbox
shape = self.batch_shapes[self.batch[index]] if self.rect else self.img_size # final letterboxed shape
img, ratio, pad = letterbox(img, shape, auto=False, scale_up=self.augment)
shapes = (h0, w0), ((h / h0, w / w0), pad) # for COCO mAP rescaling
# load labels
labels = []
x = self.labels[index]
if x.size > 0:
# Normalized xywh to pixel xyxy format
labels = x.copy() # label: class, x, y, w, h
labels[:, 1] = ratio[0] * w * (x[:, 1] - x[:, 3] / 2) + pad[0] # pad width
labels[:, 2] = ratio[1] * h * (x[:, 2] - x[:, 4] / 2) + pad[1] # pad height
labels[:, 3] = ratio[0] * w * (x[:, 1] + x[:, 3] / 2) + pad[0]
labels[:, 4] = ratio[1] * h * (x[:, 2] + x[:, 4] / 2) + pad[1]
# 是否进行数据增强
if self.augment:
# 由于mosaic中已经进行了random_affine,所以不需要;没有进行mosaic才需要
if not self.mosaic:
img, labels = random_affine(img, labels,
degrees=hyp["degrees"],
translate=hyp["translate"],
scale=hyp["scale"],
shear=hyp["shear"])
# Augment colorspace: hsv数据增强, 这一部分由于没有对标签进行更改,所以不需要对边界框进行处理
img = augment_hsv(img, h_gain=hyp["hsv_h"], s_gain=hyp["hsv_s"], v_gain=hyp["hsv_v"])
# 在进行仿射变换之后会忽略一些边界框,如果没有边界框信息就可以跳过了,如果有则进行处理
nL = len(labels) # number of labels
if nL:
# convert xyxy to xywh
labels[:, 1:5] = xyxy2xywh(labels[:, 1:5])
# Normalize coordinates 0-1: 归一化处理
labels[:, [2, 4]] /= img.shape[0] # height
labels[:, [1, 3]] /= img.shape[1] # width
# 进行随机水平翻转也竖直翻转
if self.augment:
# random left-right flip
lr_flip = True # 随机水平翻转
if lr_flip and random.random() < 0.5:
img = np.fliplr(img)
if nL:
labels[:, 1] = 1 - labels[:, 1] # 1 - x_center
# random up-down flip
ud_flip = False
if ud_flip and random.random() < 0.5:
img = np.flipud(img) # 随机竖直翻转
if nL:
labels[:, 2] = 1 - labels[:, 2] # 1 - y_center
# 判断翻转后是否还有边界框信息, 并进行格式转换
labels_out = torch.zeros((nL, 6)) # nL: number of labels
if nL:
labels_out[:, 1:] = torch.from_numpy(labels)
# Convert BGR to RGB, and HWC to CHW(3x512x512)
img = img[:, :, ::-1].transpose(2, 0, 1)
img = np.ascontiguousarray(img) # 内存连续
return torch.from_numpy(img), labels_out, self.img_files[index], shapes, index
- 总结:
所以在yolov3spp中,提供的数据增强方式有mosaic,仿射变换(随机旋转、平移、缩放、错切),hsv色彩增强。但是在yolov3spp中,一般训练过程会是一个mosaic,这会包含了随机旋转、平移、缩放、错切,此时还可以设置是否使用hsv色彩增强以及上下随机翻转。而在推理过程中,就不会使用mosaic,但是可以选择是否使用除mosaic外的其他数据增强方式。
参考资料:
- https://www.bilibili.com/video/BV1t54y1C7ra?p=5
- https://blog.csdn.net/qq_38253797/article/details/117961285