Yolo系列论文解读
Table of Contents
- 前言
- 论文基本信息
- 论文出发点和思路
- 算法基本流程
- 具体实验分析
- YOLOv1个人总结
- 改进-YOLOv2
- 出发点
- 改进方案
- 改进结果
- 改进-YOLOv3
- 出发点
- 改进方案
- 改进结果
前言
YOLO作为最早的One-stage算法框架,实现了保持较好性能的前提下保证了模型较快的速度和轻便的性能。从Yolov1->Yolov3,三个版本的迭代也可以很好地观察作者进行性能提升的思路和方法。
论文基本信息
作者信息:Joseph Redmon,华盛顿大学phD,YOLOv1-v3作者,相关研究还有Xnor-net等。
YOLO官网
YOLOv1Paper
YOLOv2Paper
YOLOv3paper
论文出发点和思路
YOLOv1设计的出发点建立于人本身对图片的认知本身快速与准确的:只需要对整张图片扫描一次即可快速获取物体的类别与位置信息:You Only Look Once。其他主流物体检测算法,如DPM(defaormable parts models)通过sliding windows的方式,通过在每个spaced local位置设置分类器实现检测任务。RCNN系列通过two-stage的方式,且RCNN和Fast RCNN是无法实现端到端训练的。
YOLOv1首次通过One-Stage的方式实现Object Detection的任务,将整个任务作为bounding box的位置和类别的回归任务。下图可以简单描述YOLOv1的工作原理,YOLOV1通过直接在全图上利用卷积网络实现位置和类别的预测。这种方案的优势在于:速度快,不需要复杂的pipeline设计,标准的YOLO检测速度可以达到45FPS,Fast YOLO可以达到155FPS,当时的YOLO的检测mAP可以达到其他实时系统的两倍以上;YOLO能够更好地利用global的信息,减少背景错误;YOLO的泛化性更强。

算法基本流程
YOLOv1:
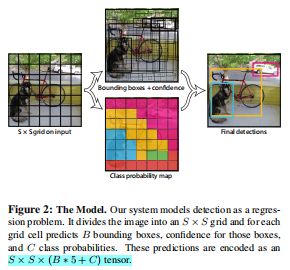
- Unified Detection:
YOLO将图片分为S*S的栅格,每个栅格对中心落在栅格内部的物体负责。每个栅格会预测B个bounding box,confidence信息和位置信息:x,y,w,h。其中confidence信息表示为条件概率的形式:confidence=Pr(Object)*IOU,即如果bounding box预测无物体,则Pr(object)=0,则confidence为0,如果预测有物体,则confidence为预测box和gt的IOU。其中,x,y表示预测的bounding box的中心与栅格边界的相对位置,w,h表示为bounding box的width,height相对于整幅图像的比例。另外每个grid cell还会预测c类的conditional confidence:Pr(Classi|Object),infer过程中通过Pr(Classi|Object)*Pr(Object)*IOU来作为bounding box的类预测confidence。注意这里的class confidence只针对c个类,而bounding box的confidence则针对每个box。
- Network Design:
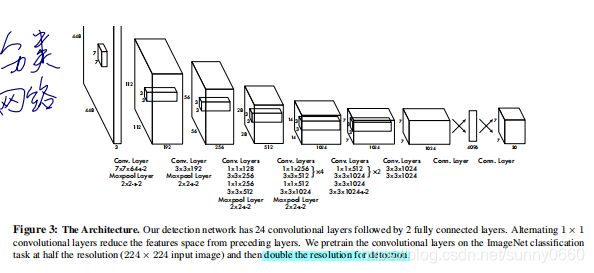
YOLO的网络借鉴了GoogleNet,通过1*1和3*3的卷积层替代了Inception结构。标准的YOLO网络有24层卷积层,后接两层全连接层,而Fast Yolo则只有9层卷积层。YOLO的输出tensor大小为7*7*30。与prediction的siz相匹配。
- Training:
先在ImageNet 1000-class分类任务上的进行网络的Pretrain,使用上述网络中的前20层卷积层, 后接一个average-pooling层和一个全连接层。将Pretrain得到的前20层全连接层作为Detection网络的前置网络,并加入后续的4层卷积层以及两个全连接层,最后层预测得到class probility以及bounding box coordinates。其中w,h,x,y需要归一化到0-1,以保证w,h小于图片尺寸,且位置在特定的grid cell边界范围内。
- Loss设计
Loss采用sum-squared error loss,但是对不同类的loss采用了不同的权重设计:- coordinates error需要有更高的权重
- no-object的栅格数目比重很大,其所占的loss很大,需要降低no-object的loss权重,降低对网络的贡献率
- 大物体小物体的误差容忍率应该是不一致的,小物体偏移对IOU影响更大,作者采用原本height和width的平方根代替原始值
训练过程中,可能存在多个box预测同一个物体,则只取IOU最大的predictor作最终的预测,最终的loss设计如下:

具体实验分析
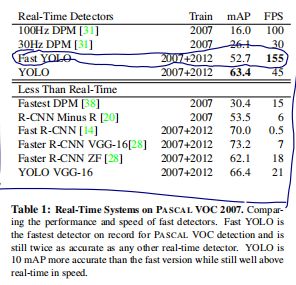
- PASCAL VOC 2007实验结果:Faster-RCNN VGG-16的mAP高于YOLO,但是速度是YOLO的6倍多,而Faster-RCNN ZF速度慢于YOLO,但是mAP也小于YOLO。
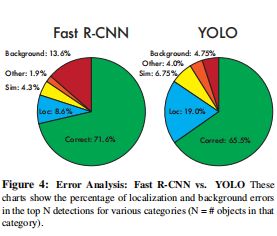
- VOC2007错误分析:与Fast RCNN进行比较,可见YOLO的位置定位误差较大,但是background的误差小。因为本身YOLO采用grid cell进行预测位置的方式,因为损失了较多的细节信息,造成了位置定位不准。
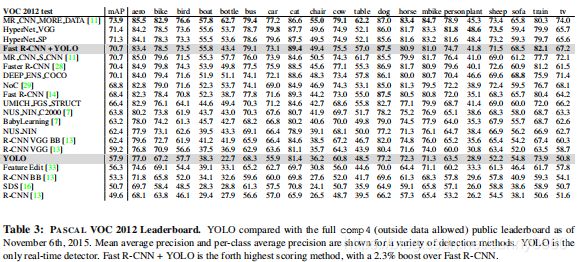
- VOC 2012:YOLOv1的性能与RCNN-VGG性能相当,主要是在小物体上的性能不如RCNN
YOLOv1个人总结
YOLOv1的缺陷也是比较明显的:
- 每个grid cell只预测2个bounding box,且不同cell之间的预测为互斥关系,所以对于相近的物体预测效果不好。
- default box的尺寸需要从训练数据中学习得到,强依赖于训练数据的物体尺寸,且没有先验的尺寸,网络学习难度变大。
- 网络最后的输出feature为7*7尺寸,小物体信息损失严重,小物体检测效果差。
改进-YOLOv2
出发点
YOLOv2(YOLO9000),从三个维度进行YOLOv1的改进:Better,Faster,Stronger。其中,Stronger主要利用分类结果进行训练,从而能够检测更多类别。本文重点关注前两项优化内容。YOLOv1的两个主要缺陷为:大量的localization error和相对proposal-based方案的较低的recall。常见的提高detector的性能的方案是采用更大,更深的网络结构,但是这会影响模型的速度。所以作者没有单纯地加宽加深网络结构,而是采取了更好的representation,而让网络更好的学习(主要是Box和对应loss的设计),同时也采用了一系列tricks以及修掉原本YOLOv1本身存在的一些问题。
改进方案
作者的改进方案如下:
- BN层:在对所有卷积层加入BN层后,提升了2%的mAP
- High Resolution Classifier:YOLOv1训练分类网络时采用的input size为224X224,但是detection网络采用的输入为448X448,意味着detection网络训练的过程中需要重新学习更大的输入尺寸。YOLOv2先将分类网络在448X448的输入下进行finetune,然后进行detection网络的finetune,提升了4%的mAP
- Convolutional With Anchor Boxes:采用anchor box的方式进行bounding box的预测。首先移除了YOLOv1的全连接层以卷积层替代,移除最后的pooling层,增大输出的size,输入的图片size由448X448->416X416,目的是为了保持输出为13X13的奇数,以保留图片正中间的grid cell位置(作者认为这对图片中间的大物体预测有帮助)。另外box的class的预测仍然沿用之前的YOLOV1的策略。该方案的收益是提高了7%的recall,但是accuracy下降:69.5mAP@81%recall->69.2mAP@88%recall。
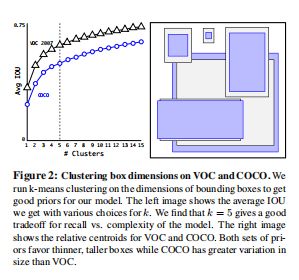
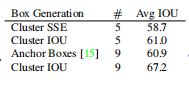
- Dimension Clusters:采用K-means进行box的聚类,相同情况下,能够比hand picked得到的box有更高的Avg IOU。
- Direct location prediction:默认的bounding box的center point的预测方案:
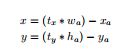
该方案的问题是偏移的最大值与anchor box的大小有关,没有其他约束,导致center点的位置有可能到图像中的任意位置,导致模型训练不稳定。所以作者沿用原先YOLO的预测位置的方式:
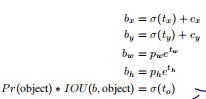
通过Dimension Clusters和Direct location prediction的方式,提高了anchor-version 5% mAP,示意图如下:

- Fine-Grained Features:通过pass-through(stacking adjacent features into diffrent channels)的方式将前置的feature层(26X26)与原先的feature map进行concat,融合多尺度性能,能够提高1% mAP。
- Multi-Scale Training:为了让YOLOv2对inputsize有更强的鲁棒性,模型训练过程中每10个batches会选择一个新的image size输入:{320,352,…,608}。
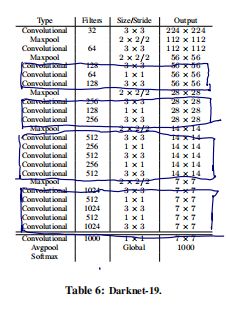
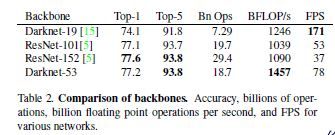
- Faster:设计了Darknet-19:5.58 billion operation,72.9% top1 accuracy, 91.2% top5 accuracy on ImageNet.:
改进结果
YOLOv1->YOLOv2改进:

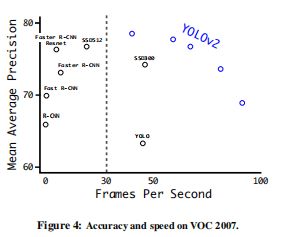
PASCALVOC2007:实现了速度和性能良好的trade-off:
PASCALVOC2012性能比较:性能基本一致,但是YOLOv2更快:
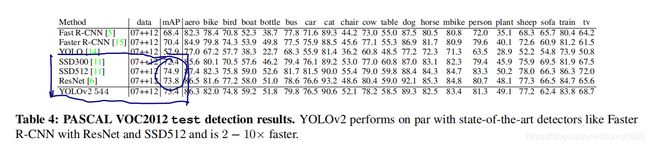
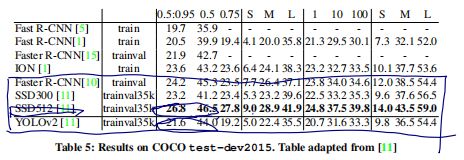
COCO性能比较:COCO小物体更多,IOU=0.5下,性能与Faster-RCNN和SSD300基本相当,但是速度更快:
改进-YOLOv3
出发点
原先YOLOv2的没有结合多尺度特征进行预测,pass-through的方案虽然实现了浅层特征的融合,但是也改变了特征的空间分布。YOLOv2的backbone-darknet19还有提升的空间。
改进方案
YOLOv3的改进更多地借鉴了诸如SSD,Faster-rcnn,FPN的优点,主要改进如下:
- Predictions Across Scales:参照FPN的设计,对原本13X13的输出feature进行上采样,分别得到26X26和52X52尺寸的feature,并与浅层的featue进行concat,最后通过卷积层进行预测。K-means采用的cluster数目为9。
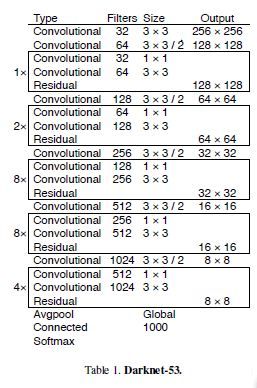
- Feature Extractor:加深了backbone的层数,并且引入Resnet的残差结构,实现了低运算量下较好的性能:
改进结果
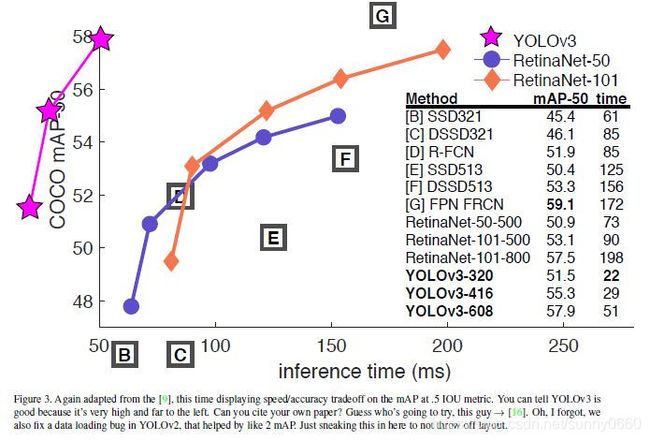
COCO数据集上的性能:可见YOLOv3的性能与SSD基本一致,但是比SSD快3倍,低于RetinaNet,但是RetinaNet的infer时间为YOLOv3的3.8倍,且0.5IOU下两者的性能比较接近。