Five reasons to embrace Transformer in computer vision/在计算机视觉领域拥抱Transformer的5条理由
翻译自微软亚洲研究院官网文章Five reasons to embrace Transformer in computer vision 2021.12.5
人工智能的统一建模故事
“大一统模型”是许多学科的共同目标。例如,在物理学领域,科学家长期以来一直在追求大一统理论,这是一种可以用来解释不同力之间相互作用的单一理论。人工智能领域也有类似的“统一”目标。在当前的深度学习浪潮中,我们朝着实现团结的目标迈出了一大步。例如,对于新的人工智能任务,我们通常遵循相同的过程:收集数据、标记数据、定义网络架构,以及训练网络参数。然而,在不同的人工智能子领域中,基本建模方法各不相同,也不统一。在自然语言处理(NLP)中,当前占主导地位的建模网络是Transformer;在计算机视觉(CV)中,很长一段时间以来,主要的结构是卷积神经网络(CNN);在社会计算领域,占主导地位的架构是图形网络;等等
然而,自去年年底Transformer开始展示各种计算机视觉任务的革命性性能改进以来,情况发生了变化。这表明CV和NLP建模可能在Transformer架构下实现统一。这种趋势对这两个领域都非常有益:1)它可以促进视觉和文本信号的联合建模;2) 它可以在这两个领域之间更好地共享建模知识,从而加快这两个领域的进展。
Transformer在视觉任务中的出色表现
Vision Transformer的开创性工作是ViT[1],由谷歌在ICLR2021上发布。它将图像划分为块(例如,16×16像素),并在NLP中将其视为“tokens”。然后对这些“tokens”应用标准Transformer encoder,并根据“CLS”token的输出特征对图像进行分类。使用大量的预训练数据,即谷歌内部的3亿图像分类数据集JFT-300M,它在ImageNet-1K验证集上实现了最高精度88.55%,创下了该基准测试的新纪录。
VIT以简单而直接的方式在图像上应用Transformer,因为它不仔细考虑视觉信号的特性,它主要用于图像分类任务。Transformer在其他粒度级别的任务上的能力仍然未知,学术界为此开展了大量工作。在这些努力中,Swin Transformer[2]显著刷新了之前关于对象检测和语义分割基准的记录,让社区更加相信Transformer结构将成为视觉建模的新主流。具体来说,在重要的目标检测基准COCO上,Swin Transformer获得了58.7个box AP和51.1个mask AP,分别比之前的最佳单模型方法高2.7和2.6个点。几个月后,通过改进检测框架和更好地利用数据,该基准的性能精度进一步提高到61.3 box AP和53.0 mask AP。Swin Transformer在语义切分的重要评估基准ADE20K上也取得了显著的性能改进,达到了5350万,比之前的最佳方法高出320万。在几个月内,准确度进一步提高到5700万。
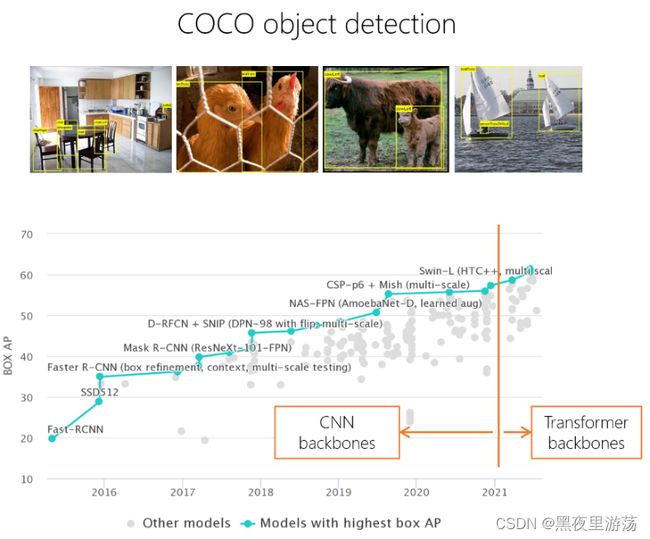
除了在目标检测和语义分割任务方面表现出色外,基于Swin Transformer的方法在许多视觉任务中也表现出了强大的性能,包括视频运动识别[3]、视觉自监督学习[4][5]、图像恢复[6]、行人识别[7]、医学图像分割[8]等。
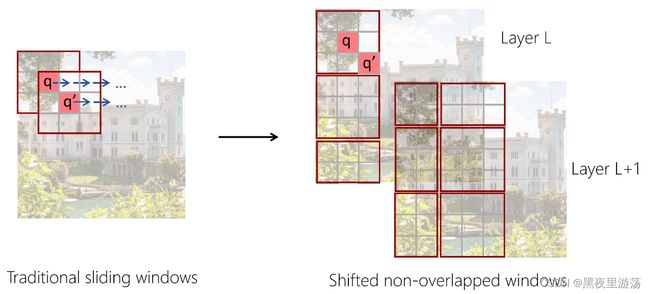
Swin Transformer的主要思想很简单:将建模功能强大的Transformer架构与几个重要的视觉信号优先级结合起来。这些先验包括层次性、局部性和平移不变性。Swin Transformer的一个重要设计是移位的非重叠窗口,与传统的滑动窗口不同,该窗口对硬件更友好,可以提高实际运行速度。如下图左侧所示,在滑动窗口设计中,不同的点使用不同的邻域窗口来计算关系,这对硬件不友好。如右图所示,在Swin Transformer使用的非重叠窗口中,同一窗口内的点是使用相同的邻域计算的,速度更友好。实际速度测试表明,非重叠窗口法的速度大约是滑动窗口法的两倍。此外,移位是在两个连续的层中进行的。在L层,窗口分割从图像的左上角开始,在L-1层,窗口分割将半个窗口向下和向右移动。这种设计确保了窗口之间不重叠的信息交换。
在过去的半年里,学术界涌现出了许多Vision Transformer的变体,包括DeiT[9]、LocalViT[10]、Twins[11]、PvT[12]、T2T ViT[13]、ViL[14]、CvT[15]、CSwin[16]、Focal Transformer[17]、Shuffle Transformer[18]等。
在计算机视觉中拥抱Transformer的五个理由
除了刷新许多视觉任务的性能记录外,与以前的CNN体系结构相比,Vision Transformer还显示了许多优点。事实上,在过去的四年里,学者们一直在利用Transformer在计算机视觉中的优势,这可以概括为五个方面,如下图所示。
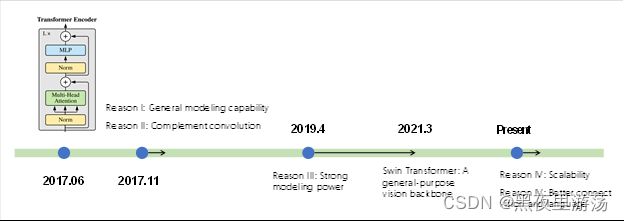
原因1:通用建模功能
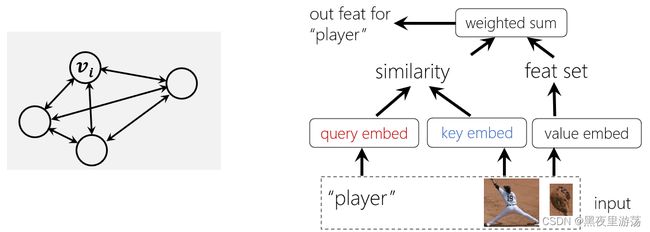
Transformer的通用建模能力来自两个方面。一方面,Transformer可以被视为在图上运行。图是完全连接的,节点之间的关系是以数据驱动的方式学习的。Transformer建模的用途非常广泛,因为任何概念,无论是具体的还是抽象的,都可以用图中的节点来表示,概念之间的关系可以用图的边来表示。
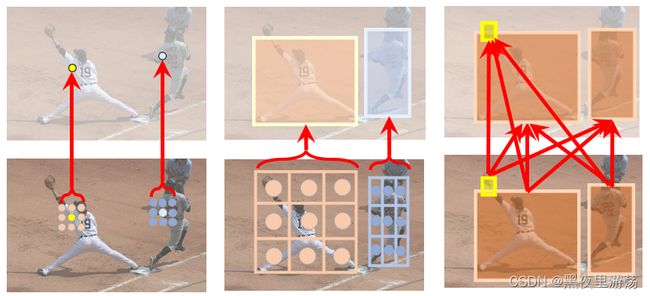
另一方面,Transformer在通过验证原理建立图节点之间的关系方面具有良好的通用性:无论节点多么异构,都可以通过将它们投影到对齐的空间来计算相似性来建立它们的关系。如下图右侧所示,图形节点可以是不同比例的图像块,也可以是“player”等文本输入,Transformer可以很好地描述这些异构节点之间的关系。
可能是因为这种多功能建模能力,Transformer及其所依赖的注意力单元可以应用于各种各样的视觉任务。具体来说,计算机视觉主要涉及两个基本的粒度元素:像素和目标,因此计算机视觉任务主要涉及这些基本元素之间的三种关系:像素到像素、目标到像素和目标到目标。以前,前两种关系类型主要分别通过卷积和ROIAllign实现,而最后一种关系在建模时往往被忽略。然而,Transformer中的注意单元可以应用于所有三种基本的关系建模类型,因为它具有通用的建模能力。近年来,在这一领域有很多代表性的工作,包括:1)非局部网络[19],其中王晓龙等人使用注意单元来建模像素到像素的关系,并证明注意单元可以帮助完成视频动作分类和目标检测等任务,袁宇辉等人将其应用于语义分割,实现显著的性能改进[20];2) 目标关系网络[21],其中注意单元被用于目标检测中的目标关系建模,该模块也被广泛用于视频目标分析[22,23,24];3) 建模目标和像素之间的关系,典型作品包括DETR[25]、Learn Region Feat[26]、RelationNet++[27]等。
原因2:卷积互补
卷积是一种局部操作,卷积层通常只模拟邻域像素之间的关系。Transformer是一个全局操作,Transformer层可以模拟所有像素之间的关系。这两个层次的类型互补性很好。非局部网络是第一个利用这种互补性的网络[19],在原始卷积网络的几个地方插入少量Transformer 自我注意单元作为补充。这在解决目标检测、语义分割和视频动作识别中的视觉问题方面已被广泛证明是有效的。
从那时起,还发现非局部网络很难真正学习计算机视觉中像素和像素之间的二阶成对关系[28]。为了解决这个问题,已经为这个模型提出了一些改进,例如分离非本地网络(DNL)[29]。
原因3:更强的建模能力
卷积可以被认为是一种模板匹配方法,在图像的不同位置使用相同的模板过滤。Transformer中的注意力单元是一个自适应滤波器,滤波器权重由两个像素的可组合性决定。这种类型的计算模块具有更强的建模能力。
本地关系网络(LR-Net)[30]和SASA[31]是将Transformer作为自适应计算模块应用于视觉骨干网的第一种方法。它们都将自我注意力计算限制在一个局部滑动窗口内,并且在使用相同的理论计算预算时比ResNet获得了更好的精度。然而,虽然计算复杂度在理论上与ResNet相同,但LR-Net在实际应用中要慢得多。主要原因之一是不同的查询使用不同的键集,这使得它对内存访问不那么友好,如图2左侧所示。
Swin Transformer提出了一种新的本地窗口设计,称为移位窗口。这种局部窗口方法将图像划分为非重叠窗口,以便在同一窗口内,不同查询使用的密钥集合相同,从而提高实际计算速度。在下一层中,窗口配置向下和向右移动半个窗口,在上一层不同窗口的像素之间建立连接。
原因4:对模型和数据大小的可扩展性
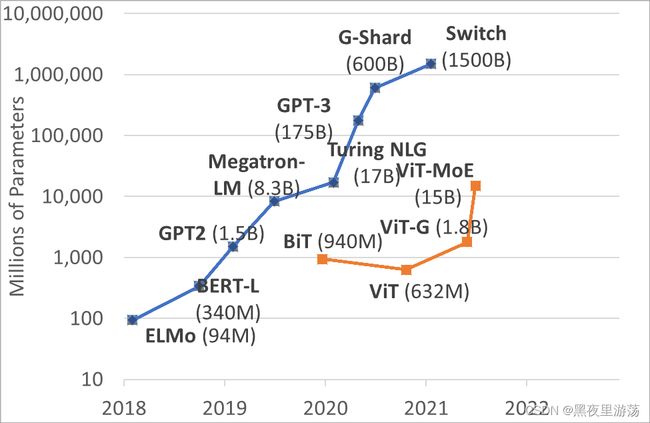
在NLP领域,Transformer模型在大模型和大数据方面表现出了极大的可扩展性。在下图中,蓝色曲线显示NLP中的模型尺寸近年来快速增长,我们都见证了大型模型的强大功能,如微软的图灵模型、谷歌的T5模型和OpenAI的GPT-3模型。
Vision Transformer的出现也为视觉模型的发展提供了重要的基础。最大的视觉模型是谷歌的ViT MoE模型,它有150亿个参数。这些大型模型在ImageNet-1K分类上创造了新记录。
理由5:视觉和语言的更好结合
在以前的视觉问题中,我们通常只处理几十个或数百个对象类别。例如,COCO对象检测任务包含80个对象类别,而ADE20K语义分割任务包含150个类别。视觉转换器模型的发明和发展使视觉和NLP领域彼此更加接近,这有助于将视觉和NLP建模联系起来,并将视觉任务与语言中涉及的所有语义联系起来。这方面的开创性工作包括OpenAI的CLIP[33]和DALL-E[34]。
考虑到上述优势,我们相信视觉转换器将开启计算机视觉建模的新时代,我们期待着与学者和行业研究人员合作,进一步探索这种新建模方法给视觉领域带来的机遇和挑战。
Reference
[1] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby. An Image is Worth 16×16 Words: Transformers for Image Recognition at Scale. ICLR 2021
[2] Ze Liu, Yutong Lin, Yue Cao, Han Hu, Yixuan Wei, Zheng Zhang, Stephen Lin, Baining Guo. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021
[3] Ze Liu, Jia Ning, Yue Cao, Yixuan Wei, Zheng Zhang, Stephen Lin, Han Hu. Video Swin Transformer. Tech report 2021
[4] Zhenda Xie, Yutong Lin, Zhuliang Yao, Zheng Zhang, Qi Dai, Yue Cao, Han Hu. Self-Supervised Learning with Swin Transformers. Tech report 2021
[5] Chunyuan Li, Jianwei Yang, Pengchuan Zhang, Mei Gao, Bin Xiao, Xiyang Dai, Lu Yuan, Jianfeng Gao. Efficient Self-supervised Vision Transformers for Representation Learning. Tech report 2021
[6] Jingyun Liang, Jiezhang Cao, Guolei Sun, Kai Zhang, Luc Van Gool, Radu Timofte. SwinIR: Image Restoration Using Swin Transformer. Tech report 2021
[7] https://github.com/layumi/Person_reID_baseline_pytorch
[8] Hu Cao, Yueyue Wang, Joy Chen, Dongsheng Jiang, Xiaopeng Zhang, Qi Tian, Manning Wang. Swin-Unet: Unet-like Pure Transformer for Medical Image Segmentation. Tech report 2021
[9] Hugo Touvron, Matthieu Cord, Matthijs Douze, Francisco Massa, Alexandre Sablayrolles, Hervé Jégou. Training data-efficient image transformers & distillation through attention. Tech report 2021
[10] Yawei Li, Kai Zhang, Jiezhang Cao, Radu Timofte, Luc Van Gool. LocalViT: Bringing Locality to Vision Transformers. Tech report 2021
[11] Xiangxiang Chu, Zhi Tian, Yuqing Wang, Bo Zhang, Haibing Ren, Xiaolin Wei, Huaxia Xia, Chunhua Shen. Twins: Revisiting the Design of Spatial Attention in Vision Transformers. Tech report 2021
[12] Wenhai Wang, Enze Xie, Xiang Li, Deng-Ping Fan, Kaitao Song, Ding Liang, Tong Lu, Ping Luo, Ling Shao. Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions. ICCV 2021
[13] Li Yuan, Yunpeng Chen, Tao Wang, Weihao Yu, Yujun Shi, Zihang Jiang, Francis EH Tay, Jiashi Feng, Shuicheng Yan. Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet. Tech report 2021
[14] Pengchuan Zhang, Xiyang Dai, Jianwei Yang, Bin Xiao, Lu Yuan, Lei Zhang, Jianfeng Gao. Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding. Tech report 2021
[15] Haiping Wu, Bin Xiao, Noel Codella, Mengchen Liu, Xiyang Dai, Lu Yuan, Lei Zhang. CvT: Introducing Convolutions to Vision Transformers. ICCV 2021
[16] Xiaoyi Dong, Jianmin Bao, Dongdong Chen, Weiming Zhang, Nenghai Yu, Lu Yuan, Dong Chen, Baining Guo. CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows. Tech report 2021
[17] Jianwei Yang, Chunyuan Li, Pengchuan Zhang, Xiyang Dai, Bin Xiao, Lu Yuan, Jianfeng Gao. Focal Self-attention for Local-Global Interactions in Vision Transformers. Tech report 2021
[18] Zilong Huang, Youcheng Ben, Guozhong Luo, Pei Cheng, Gang Yu, Bin Fu. Shuffle Transformer: Rethinking Spatial Shuffle for Vision Transformer. Tech report 2021
[19] Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He. Non-local Neural Networks. CVPR 2018
[20] Yuhui Yuan, Lang Huang, Jianyuan Guo, Chao Zhang, Xilin Chen, Jingdong Wang. OCNet: Object Context for Semantic Segmentation. IJCV 2021
[21] Han Hu, Jiayuan Gu, Zheng Zhang, Jifeng Dai, Yichen Wei. Relation Networks for Object Detection. CVPR 2018
[22] Jiarui Xu, Yue Cao, Zheng Zhang, Han Hu. Spatial-Temporal Relation Networks for Multi-Object Tracking. ICCV 2019
[23] Yihong Chen, Yue Cao, Han Hu, Liwei Wang. Memory Enhanced Global-Local Aggregation for Video Object Detection. CVPR 2020
[24] Jiajun Deng, Yingwei Pan, Ting Yao, Wengang Zhou, Houqiang Li, and Tao Mei. Relation distillation networks for video object detection. ICCV 2019
[25] Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko. End-to-End Object Detection with Transformers. ECCV 2020
[26] Jiayuan Gu, Han Hu, Liwei Wang, Yichen Wei, Jifeng Dai. Learning Region Features for Object Detection. ECCV 2018
[27] Cheng Chi, Fangyun Wei, Han Hu. RelationNet++: Bridging Visual Representations for Object Detection via Transformer Decoder. NeurIPS 2020
[28] Yue Cao, Jiarui Xu, Stephen Lin, Fangyun Wei, Han Hu. GCNet: Non-local Networks Meet Squeeze-Excitation Networks and Beyond. ICCV workshop 2019
[29] Minghao Yin, Zhuliang Yao, Yue Cao, Xiu Li, Zheng Zhang, Stephen Lin, Han Hu. Disentangled Non-Local Neural Networks. ECCV 2020
[30] Han Hu, Zheng Zhang, Zhenda Xie, Stephen Lin. Local Relation Networks for Image Recognition. ICCV 2019
[31] Prajit Ramachandran, Niki Parmar, Ashish Vaswani, Irwan Bello, Anselm Levskaya, Jonathon Shlens. Stand-Alone Self-Attention in Vision Models. NeurIPS 2019
[32] Carlos Riquelme, Joan Puigcerver, Basil Mustafa, Maxim Neumann, Rodolphe Jenatton, André Susano Pinto, Daniel Keysers, Neil Houlsby. Scaling Vision with Sparse Mixture of Experts. Tech report 2021
[33] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, Ilya Sutskever. Learning Transferable Visual Models from Natural Language Supervision. Tech report 2021
[34] Aditya Ramesh, Mikhail Pavlov, Gabriel Goh, Scott Gray, Chelsea Voss, Alec Radford, Mark Chen, Ilya Sutskever. Zero-Shot Text-to-Image Generation. Tech report 2021