手把手带你玩转Spark机器学习-使用Spark构建分类模型
系列文章目录
- 手把手带你玩转Spark机器学习-专栏介绍
- 手把手带你玩转Spark机器学习-问题汇总
- 手把手带你玩转Spark机器学习-Spark的安装及使用
- 手把手带你玩转Spark机器学习-使用Spark进行数据处理和数据转换
- 手把手带你玩转Spark机器学习-使用Spark构建分类模型
- 手把手带你玩转Spark机器学习-使用Spark构建回归模型
- 手把手带你玩转Spark机器学习-使用Spark构建聚类模型
- 手把手带你玩转Spark机器学习-使用Spark进行数据降维
- 手把手带你玩转Spark机器学习-使用Spark进行文本处理
- 手把手带你玩转Spark机器学习-深度学习在Spark上的应用
文章目录
- 系列文章目录
- 前言
- 一、获取数据集
- 二、数据探索
-
- 2.数据预处理
- 3.特征工程
- 4.模型构建
-
- Logistic regression
- RandomForest
- 梯度提升决策树
- 总结
前言
本文,我们将介绍如何利用Spark构建分类模型。我们会介绍分类模型【逻辑回归、随机森林、梯度决策树】的基础知识以及如何通过Spark MLib来使用这些模型。分类通常通常是指将事物分成不同的类别。在分类模型中,我们期望根据一组特征来判断类别,这些特征代表了物体、事件或上下文相关的属性(变量)。
分类是监督学习的一种形式,我们用带有类标记或者类输出的训练样本训练模型(也就是通过输出结果监督被训练过的模型)。分类模型适用于很多情形,一些常见的例子如下:
- 预测互联网用户对广告的点击率【点击or不点击,二分类】
- 检测欺诈【二分类】
- 预测拖欠贷款【二分类】
- 对图片、视频或声音分类【绝大多数为多分类】
- 对新闻、网页或者其他内容标记类别或者打标签【多分类】
- 发现垃圾邮件、垃圾页面、网络入侵和其他恶意行为【二分类或者多分类】
- 检测故障,比如计算机系统或者网络的故障检测【多分类】
- 根据顾客或者用户购买产品或者使用服务的概率对他们进行排序【多分类】
- 预测顾客或者用户中谁有可能停止使用某个产品或服务【二分类】
上面只是罗列了一些可行的用例,在实际业务场景中,分类方法是机器学习和统计领域使用最广泛的技术之一。
文章中涉及到的code可到本人github处下载:SparkML
一、获取数据集
我们在文章:Spark机器学习实战-使用Spark进行数据处理和数据转换中介绍了如何去获取一些公开数据集来支撑咱们的训练和学习。在这篇文章中我们将使用泰坦尼克号乘客数据,来预测他们是否能在泰坦尼克号沉没中幸存下来。数据集中字段定义如下:
| 变量名 | 定义 | 取值 |
|---|---|---|
| survival | 幸存 | 0=No,1=Yes |
| pclass | 船票仓位等级 | 1 = 1st, 2 = 2nd, 3 = 3rd |
| sex | 性别 | |
| Age | 年龄 | |
| sibsp | 泰坦尼克号上的兄弟姐妹/配偶 | |
| parch | 泰坦尼克号上的父母/孩子 | |
| ticket | 票号 | |
| fare | 票价 | |
| cabin | 客舱号 | |
| embarked | 登船港口 |
二、数据探索
首先创建Session,并读取泰坦尼克号的训练数据
# Firstly we create sparkSession (like a container)
spark = SparkSession.builder.appName('Play with pyspark ML on titatic_dataset').getOrCreate()
# After creating spark, we use spark.read.csv to read dataset, like pandas.read_csv
df = spark.read.csv('.c/train.csv',header = 'True',inferSchema='True')
df.limit(3).toPandas()

然后,我们使用可视化库(matplotlib、seaborn)对上述数据进行可视化分析。在这之前,我们需要将 SparkDataframe 转换为 PandasDataFrame。
pandas_df = df.toPandas()
plt.figure(figsize=(10,5))
plt.title('Age distribution among all Pasengers')
sns.distplot(pandas_df['Age']);

如上图所示,泰坦尼克号上的乘客年龄是个近似正太分布。
接下来我们利用pyspark中现有的函数来检查下数据中存在的空缺值。
isnan() 是 pysparrk.sql.function 包的一个函数,函数的入参是某列列名,isNull() 属于 pyspark.sql.Column 包,用于检查列的空状态。
from pyspark.sql.functions import isnan, when, count, col
df.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in df.columns]).show()

由上图可知,有177名乘客的年龄是缺失的,687名乘客客舱号缺失,2名乘客登船港口缺失。
2.数据预处理
由于Cabin所在列数据缺失率超过50%,所以对该列做剔除处理。
df = df.drop("Cabin")
接下来我们对年龄进行缺失值的填充,一般来说,我们可以将平均年龄填充到这些缺失值中,但是我们发现有很多不同年龄的人,但是在Name中,我们发现有Mr和Mrs这样的称呼,因此我们可以通过这样的称呼对年龄进行分组,然后将各自组的平均值分配到各自组的缺失值中。
我们利用正则表达式来提取类似上述的称呼:
df = df.withColumn("Initial",regexp_extract(col("Name"),"([A-Za-z]+)\.",1))
df.limit(3).toPandas()

通过分析Initial的结果,发现有很多拼写错误的字母,比如说Mlle或者Mme,这种我们做个替换修正的操作:
df = df.replace(['Mlle','Mme', 'Ms', 'Dr','Major','Lady','Countess','Jonkheer','Col','Rev','Capt','Sir','Don'],
['Miss','Miss','Miss','Mr','Mr', 'Mrs', 'Mrs', 'Other', 'Other','Other','Mr','Mr','Mr'])
# Checking the average age by Initials
df.groupby('Initial').avg('Age').collect()
通过对Initial进行聚合,并计算出每个分组中的平均年龄。并将平均年龄填充到对应分组中(对年龄进行四舍五入)

# Assigning missing values in age feature based on average age of Initials
df = df.withColumn("Age",when((df["Initial"] == "Miss") & (df["Age"].isNull()), 22).otherwise(df["Age"]))
df = df.withColumn("Age",when((df["Initial"] == "Other") & (df["Age"].isNull()), 46).otherwise(df["Age"]))
df = df.withColumn("Age",when((df["Initial"] == "Master") & (df["Age"].isNull()), 5).otherwise( df["Age"]))
df = df.withColumn("Age",when((df["Initial"] == "Mr") & (df["Age"].isNull()), 33).otherwise(df["Age"]))
df = df.withColumn("Age",when((df["Initial"] == "Mrs") & (df["Age"].isNull()), 36).otherwise(df["Age"]))
对于Embarked列,我们做以下探查
df.groupBy("Embarked").count().show()

Embarked列只有两项缺失,并且该列是类别类变量,因此我们利用该列的众数对该数值进行填充。
df = df.na.fill({"Embarked" : 'S'})
# Check again the missing value status
df.select([count(when(isnan(c) | col(c).isNull(), c)).alias(c) for c in df.columns]).show()

3.特征工程
在处理完缺失值后,我们开始做一些特征工程的工作,这里的话,我们会多次使用Pyspark多重条件语法:When otherwise
首先我们构造一个新的特征列"Alone",这个特征列主要是表示该乘客是否有家人
df = df.withColumn("Family_Size",col('SibSp')+col('Parch')) # Create new column: Family_size
df = df.withColumn('Alone',lit(0)) # Create new column: Alone and assign 0 default value to Alone column
df = df.withColumn("Alone",when(df["Family_Size"] == 0, 1).otherwise(df["Alone"]))
接下来对Sex、Embarked和Initial列做编码处理,将字符串转换成数字编码,这里使用StringIndexer:
indexers = [StringIndexer(inputCol=column, outputCol=column+"_index").fit(df) for column in ["Sex","Embarked","Initial"]]
pipeline = Pipeline(stages=indexers)
df = pipeline.fit(df).transform(df)
df.limit(3).toPandas()
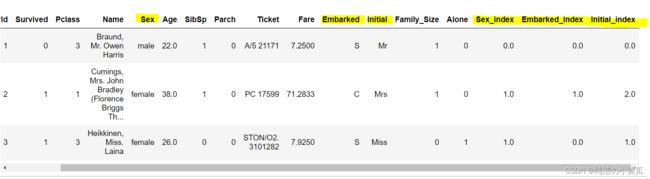
接着删除建模不需要的列,并将所有特征放入到Pyspark VectorAssembler中进行特征拼接:
# Now we drop columns that not needed for modelling
df = df.drop("PassengerId","Name","Ticket","Cabin","Embarked","Sex","Initial")
# Before modelling in Pyspark, we need to put all features to Vector using Pyspark VectorAssembler
feature = VectorAssembler(inputCols = df.columns[1:],outputCol="features")
feature_vector= feature.transform(df)
feature_vector.limit(3).toPandas()
 划分训练集和测试集
划分训练集和测试集
# for data split in pyspark, we can use df.randomSplit()
(train_df, test_df) = feature_vector.randomSplit([0.8, 0.2],seed = 11)
train_df.printSchema()

4.模型构建
这里,我们将使用三种机器学习算法:逻辑回归(LogisticRegression)、随机森林(RandomForestClassifier)、梯度提升决策树(Gradient-boosted tree classifier)。
这里,关于逻辑回归的算法介绍,大家可以看我以前写的一篇博文:CS229 Part2 分类与逻辑回归
我们选择特征列进行特征训练并选择"Survived"作为标签进行预测。
# Select features column for features training and 'Survived' as label to predict
titanic_df = feature_vector.select(['features','Survived'])
# Split the dataset to train_df and test_df
train_df,test_df = titanic_df.randomSplit([0.75,0.25])
Logistic regression
# LOAD PYSPARK LIBRARIES
from pyspark.ml.classification import LogisticRegression
from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit
from pyspark.ml import Pipeline
from pyspark.ml.evaluation import BinaryClassificationEvaluator
from pyspark.ml.tuning import CrossValidator, ParamGridBuilder
from sklearn.metrics import roc_curve,auc
# DEFINE ALGORITHM
lr = LogisticRegression(labelCol="Survived")
# DEFINE GRID PARAMETERS
paramGrid = ParamGridBuilder().addGrid(lr.regParam, (0.01, 0.1))\
.addGrid(lr.maxIter, (5, 10))\
.addGrid(lr.tol, (1e-4, 1e-5))\
.addGrid(lr.elasticNetParam, (0.25,0.75))\
.build()
# DEFINE CROSS VALIDATION WITH PARAMETERS
tvs = TrainValidationSplit( estimator=lr
,estimatorParamMaps=paramGrid
,evaluator=MulticlassClassificationEvaluator(labelCol='Survived')
,trainRatio=0.8)
model = tvs.fit(train_df)
model_predictions= model.transform(test_df)
print('Accuracy: ', MulticlassClassificationEvaluator(labelCol='Survived',metricName='accuracy').evaluate(model_predictions))
print('Precision: ',MulticlassClassificationEvaluator(labelCol='Survived',metricName='weightedPrecision').evaluate(model_predictions))

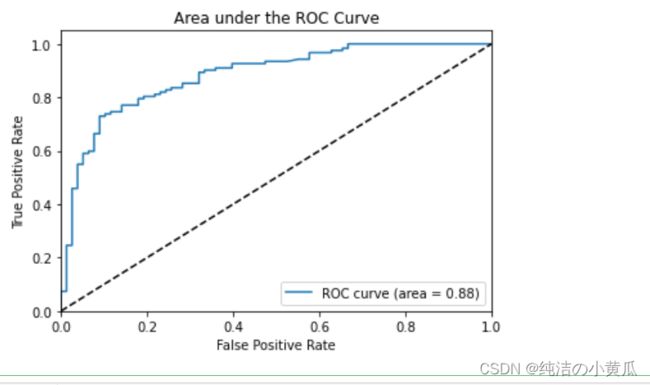
在上面的代码中,我们使用了网格参数来贪婪搜索训练模型的最佳参数,训练完成后的评估结果:Accuracy为0.8,Precision为0.8。
为了进一步刻画分类器的性能,我们来计算ROC的分值。
from pyspark.mllib.evaluation import BinaryClassificationMetrics as metric
from pyspark import SparkContext
sc =SparkContext.getOrCreate() # We need to create SparkContext
results = model_predictions.select(['probability', 'Survived'])
## prepare score-label set
results_collect = results.collect()
results_list = [(float(i[0][0]), 1.0-float(i[1])) for i in results_collect]
scoreAndLabels = sc.parallelize(results_list)
metrics = metric(scoreAndLabels)
print("The ROC score is : ", metrics.areaUnderROC)

我们将ROC曲线画出,来进一步表示分类器性能在不同决策阈值下TPR对FPR的折衷。
ROC曲线是对分类起的真阳性率-假阳性率的图形化解释。
from sklearn.metrics import roc_curve, auc
fpr = dict()
tpr = dict()
roc_auc = dict()
y_test = [i[1] for i in results_list]
y_score = [i[0] for i in results_list]
fpr, tpr, _ = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
%matplotlib inline
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Area under the ROC Curve')
plt.legend(loc="lower right")
plt.show()
RandomForest
在机器学习中,随机森林是一个包含多个决策树的分类器, 并且其输出的类别是由个别树输出的类别的众数而定。在了解随机森林前,得先了解下决策树的知识:CART分类回归树分析与python实现、ID3决策树原理分析及python实现。
构建随机森林模型
from pyspark.ml.classification import RandomForestClassifier
from pyspark.ml.tuning import ParamGridBuilder, TrainValidationSplit
rf = RandomForestClassifier(labelCol='Survived')
paramGrid = ParamGridBuilder()\
.addGrid(rf.maxDepth, [5, 10, 20]) \
.addGrid(rf.maxBins, [20, 32, 50]) \
.addGrid(rf.numTrees, [20, 40, 60 ]) \
.addGrid(rf.impurity, ["gini", "entropy"]) \
.addGrid(rf.minInstancesPerNode, [1, 5, 10]) \
.build()
tvs = TrainValidationSplit( estimator=rf
,estimatorParamMaps=paramGrid
,evaluator=MulticlassClassificationEvaluator(labelCol='Survived')
,trainRatio=0.8)
model = tvs.fit(train_df)
model_predictions= model.transform(test_df)
print('Accuracy: ', MulticlassClassificationEvaluator(labelCol='Survived',metricName='accuracy').evaluate(model_predictions))
print('Precision: ',MulticlassClassificationEvaluator(labelCol='Survived',metricName='weightedPrecision').evaluate(model_predictions))

计算ROC分数
sc =SparkContext.getOrCreate() # We need to create SparkContext
results = model_predictions.select(['probability', 'Survived'])
## prepare score-label set
results_collect = results.collect()
results_list = [(float(i[0][0]), 1.0-float(i[1])) for i in results_collect]
scoreAndLabels = sc.parallelize(results_list)
metrics = metric(scoreAndLabels)
print("The ROC score is : ", metrics.areaUnderROC)

fpr = dict()
tpr = dict()
roc_auc = dict()
y_test = [i[1] for i in results_list]
y_score = [i[0] for i in results_list]
fpr, tpr, _ = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
%matplotlib inline
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Area under the ROC Curve')
plt.legend(loc="lower right")
plt.show()

梯度提升决策树
在讲梯度提升决策树之前,先给大家讲下上面的随机森林和梯度决策树之间的区别。
随机森林和梯度提升决策树都属于集成学习算法,它们都由多棵决策树所组成,最终的结果也需要经过所有决策树共同决定。
但随机森林与梯度提升决策树在思想和算法上有所区别,随机森林采用的是机器学习中的Bagging思想,而梯度提升决策树则采用的是Boosting思想。
Bagging和Boosting都是集成学习方法,且都是通过结合多个弱学习器并提升为强学习器来完成训练任务。Bagging通过有放回均匀抽样法从训练集中抽取样本训练弱分类器,每个分类器的训练集是相互独立的,而Boosting的每个分类器的训练集不是相互独立的,每个弱分类器的训练集都是在上一个弱分类器的结果上进行取样。由于随机森林采用了Bagging思想,那么决策树训练集相互独立,组成随机森林的树相互之间可以并行生成,而梯度提升决策树采用的Boosting思想,组成的树需要按顺序串行生成。并且随机森林中的决策树对训练集进行训练时,对所有的训练集一视同仁,而梯度提升决策树对不同的决策树依据重要性赋有不同的权值。
在应用上,随机森林与梯度提升决策树都可以解决分类与回归问题,但随机森林更多地用于解决分类问题,梯度提升决策树则更多用于处理回归问题。
from pyspark.ml.classification import GBTClassifier
gbt = GBTClassifier(labelCol="Survived")
paramGrid = ParamGridBuilder()\
.addGrid(gbt.maxDepth, [5, 10, 20]) \
.addGrid(gbt.maxBins, [20, 32, 50]) \
.addGrid(gbt.maxIter, [10, 20, 30]) \
.addGrid(gbt.minInstancesPerNode, [1, 5, 10]) \
.build()
tvs = TrainValidationSplit(estimator=gbt
, estimatorParamMaps=paramGrid
,evaluator=MulticlassClassificationEvaluator(labelCol='Survived')
,trainRatio=0.8)
model = tvs.fit(train_df)
model_predictions= model.transform(test_df)
print('Accuracy: ', MulticlassClassificationEvaluator(labelCol='Survived',metricName='accuracy').evaluate(model_predictions))
print('Precision: ',MulticlassClassificationEvaluator(labelCol='Survived',metricName='weightedPrecision').evaluate(model_predictions))

计算ROC分数
sc =SparkContext.getOrCreate() # We need to create SparkContext
results = model_predictions.select(['probability', 'Survived'])
## prepare score-label set
results_collect = results.collect()
results_list = [(float(i[0][0]), 1.0-float(i[1])) for i in results_collect]
scoreAndLabels = sc.parallelize(results_list)
metrics = metric(scoreAndLabels)
print("The ROC score is: ", metrics.areaUnderROC)

画出ROC曲线
fpr = dict()
tpr = dict()
roc_auc = dict()
y_test = [i[1] for i in results_list]
y_score = [i[0] for i in results_list]
fpr, tpr, _ = roc_curve(y_test, y_score)
roc_auc = auc(fpr, tpr)
%matplotlib inline
plt.figure()
plt.plot(fpr, tpr, label='ROC curve (area = %0.2f)' % roc_auc)
plt.plot([0, 1], [0, 1], 'k--')
plt.xlim([0.0, 1.0])
plt.ylim([0.0, 1.05])
plt.xlabel('False Positive Rate')
plt.ylabel('True Positive Rate')
plt.title('Area under the ROC Curve')
plt.legend(loc="lower right")
plt.show()

总结
以上就是今天本文所要分享的内容,借助泰坦尼克号乘客数据,我们通过三个机器学习算法来预测乘客是否幸存。并详细讲解了如何通过Pyspark对数据进行分析、清洗、异常值填充、特征工程以及参数搜索模型调优,最后我们还分析比较了随机森林和梯度提升决策树的异同,以及介绍了一些性能评估指标及可视化的方法。