谢谢你能看我一本正经的胡说八道。
0) 缘由
为什么要写这么一篇博文呢?
我在很多次面试中,都被问到SVM算法。惭愧的是,我近两年一直关注深度学习算法,对SVM的理论本来就掌握得不熟,加上时间一久,被问到的时候结果可想而知。所以,思来想去,痛定思痛,还是整理一篇博文,作为自己的复习,也为可能看到这篇博文的同学带来一点启发,就更好了。
记得面试的时候,被面试官问起,我说支持向量机是通过查找一个超平面来做二分类的。然后面试官问我,“具体一点,原理是什么可以大致讲一讲么”,我就随口说了几个核函数,然后在被问到核函数原理的时候彻底懵逼。如果你也是这种情况,那么,这篇文章也是为你准备的。
其实,很多算法都是一脉相承的,只是在某些步骤采取了不同的处理方式。相信每个刚看到SVM算法的人都会跟我有相同的感觉,这玩意怎么那么像线性回归,怎么又那么像感知机呢?恭喜,如果有这种感觉的话,说明,你跟我一样,是初学者,哈哈哈。
废话不多说,下边进入正文。
1) 简介
支持向量机(Support Vector Machines, SVM)是一种二分类模型,其基本模型是定义在特征空间上的最大间隔的线性分类器,间隔最大是跟感知机区分开来的地方。
相信看到这里,你绝对是一脸懵逼,最大间隔是啥意思?没关系,我也是!但是,请接着看下去吧,让我们一起解开SVM的神秘面纱。
回归和分类的故事
在数学课上,老师教过我们一个简单的函数,$ y=f(x) = x^2 $ ,很简单,对吧,相信大家都认识这个函数。但是这个函数代表什么意思呢?我们学了那么多年数学,这个基本的函数公式,我们用在了哪里呢?
其实,我们学的很多东西,看似无用,因为很多人确实一辈子可能都用不到。但是,当你用到的时候,你会发现,哇,原来这个东西这么有用!
对的,这个函数其实很有用,当然我不会去讲这个函数多有用。在这里,这个函数仅仅可以让我们了解回归和分类是啥意思。
回归
先来看回归,我记得初中还是高中,刚学函数的时候,会有这么一道题目,给定一部分x, 也给定一部分y, 让大家根据x和y的数字,来判断x和y有什么关系。假设,我们有一批数据样本如下图所示(单变量样本):
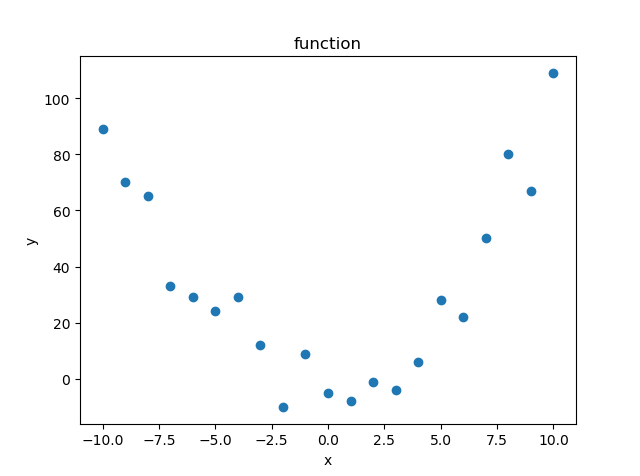
我们打眼一看,这个分布有点像我们学过的一个函数啊,什么来着?对,特别像$ y=x^2 $ !
没错,这是我故意选择的函数。我们画一下$ y=x^2 $的曲线,如下:
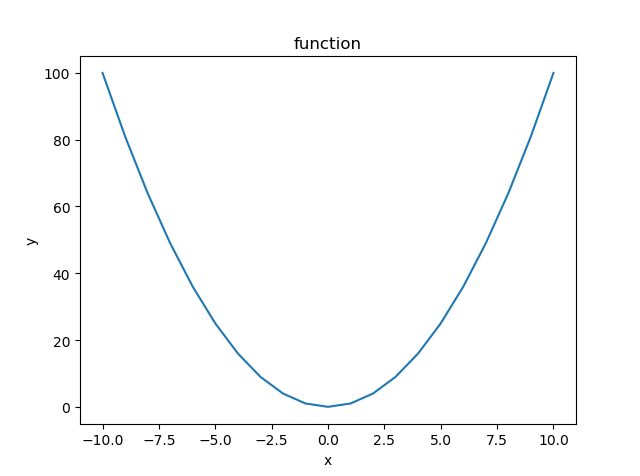
这么一看,有点不清楚,那么我们将样本点和曲线画在一个坐标里看一下:
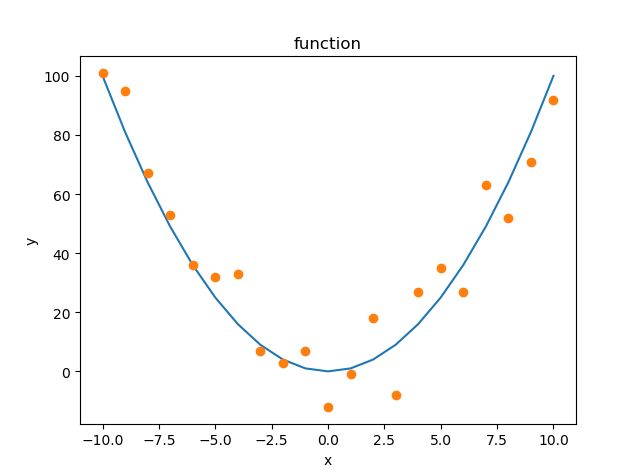
怎么样,是不是直观多了。看一下这个图,我们就可以从$ y=x^2$出发,去进一步探究样本具体符合哪个函数的分布了。
数学上是这么介绍回归的:
回归,指研究一组随机变量 $ (Y_1 ,Y_2 ,…,Y_i) $ 和另一组 $ (X_1,X_2,…,X_k) $ 变量之间关系的统计分析方法,又称多重回归分析。通常 $ Y_1,Y_2,…,Y_i $ 是因变量, $ X_1、X_2,…,X_k $ 是自变量。
这里, $ Y $ 指的就是纵坐标, $ X $ 指的是横坐标。可以看到, $ Y $ 是随着 $ X $ 的变化而变化的。
这里为了作图方便, $ X $ 只用了一个变量,但实际中,这个 $ X $ 是可以有很多个的,比如波士顿房价的例子。
分类
其实,相比回归来说,分类是比较容易被我们所理解的概念。生活中处处是分类,最近上海卯足了干劲推动的垃圾分类,就是一个典型的分类例子。再比如垃圾邮件分类,图书馆里的书籍分类,超市里的货品分类,图片分类等等。
那么,分类看起来好简单啊,人工分一下就好了,有什么好研究的?
我上边举的例子,都是比较简单的例子,特征数量很少,人工就可以轻易分出来。但是,如果待分类的数目特别大呢,或者需要考虑的特征特别多呢?
文本分类就是这样的一个难题。比如新闻分类,谷歌的新闻分类做的很不错,从互联网上抓取各种各样的新闻,然后把新闻自动分类到对应的类别去,然后不同的用户看新闻的时候,可以直接找到自己感兴趣的类别。
但是,互联网上每天的新闻何其之多,文本分类依托的特征又何其之多,只靠人工如何能处理过来。
因此,自动化分类的机器学习方法,被发明出来。
自动分类借鉴了人工分类的方式,抓取其中最能区分不同类别的特征,然后对样本进行分类。很简单对吧,SVM算法,跟其他分类算法一样,就是干的这么一回事,抓取特征,然后分类。那么,如何抓取特征,如何分类就成了不同分类算法的看家本事了,SVM算法能取得耀眼的成绩,足以说明其能力之强。那么,SVM究竟是怎么一回事?
SVM究竟是怎么一回事?
SVM要找到一个超平面来对样本进行分类,分类的原则是间隔最大化,最终转化为一个凸二次规划问题来求解。支持向量机学习方法包含由简至繁的模型:线性可分支持向量机(linear support vector machine in linearly separable acse),线性支持向量机(linear support vector machine)及非线性支持向量机(non-linear support vector machine)。
- 当训练样本线性可分时,通过硬间隔最大化,学习一个线性可分支持向量机;
- 当训练样本近似线性可分时,通过软间隔最大化,学习一个线性支持向量机;
- 当训练样本线性不可分时,通过核技巧和软间隔最大化,学习一个非线性支持向量机。
我发现书本,如李航教授的《统计学习方法》,以及很多技术博客,都会采用这种方式,来介绍SVM(其实《统计学习方法》真是很棒的一本书,推荐大家都去阅读,对机器学习的一些算法会了解得很透彻。)。这样的介绍本身没问题,用语也很精确,但是对一个初学者来说,这些语言太过生涩,比如,什么是凸二次规划?什么是间隔最大化?什么是硬间隔?什么是软间隔?
也许,这就是很多想入门机器学习的人,被吓跑的原因吧。
所以,我决定,先不讲理论了,先来看一个svm用来文本分类的例子。对,就是这么任性!
2) 例子
我们用到了scikit-learn这个机器学习工具包中的SVM算法进行文本分类。GitHub地址
文本数据哪里来?
首先,我们要找可以用来分类的数据。数据哪里来?当然是从网上。万能的互联网,包罗万象,可以找到任何你想要的东西。什么?你找不到?再找找。
IMDB数据集包含来自互联网的50000条严重两极分化的评论,该数据被分为用于训练的25000条评论和用于测试的25000条评论,训练集和测试集都包含50%的正面评价和50%的负面评价。我们将数据下载下来,合并到一起,得到数据集。
scikit-learn是神器!
这是一个很出名的机器学习包,成熟简约的调用api使得几乎人人都能迅速上手,当然,前提是你得会点python代码。只要会python的基本语法,使用scikit-learn就不在话下了。
先来感受一下使用SVM算法进行分类有多简单:
from sklearn import svm
clf_model = svm.SVC(kernel='linear', verbose=True)
clf_model.fit(x_train, y_train)
clf_model.predict(vector)怎么样,简单不?我们只要先引入svm包,然后定义一个clf_model, 调用fit方法, 就开始训练模型,等模型训练完了, 可以调用predict 对新样本进行预测.
如同SVM算法一样, 几乎所有的算法都已经有大牛写好了工具包, 只要你会调用就好了。
模型输入输出是啥?
但是,你一定在疑惑,x_train是什么?y_train又是什么?vector呢?
很显然,不论是什么算法,计算机只能处理数字,因此我们必须先将文字转变成数字。
一个直观的想法就是,给文本中的所有词,顺序建立一个编号,比如一共10万个词,分别从1-100000,代表每一个词,再将文本中出现的词用其对应的编号代替。
能这么想,说明你有这方面的天赋,从事NLP行业吧,NLP的未来是属于你的,哈哈哈。
不错,不管是什么算法处理文本,或者对文本做什么样的操作,这都是第一步。给每一个词设置一个编号,然后用编号代替词。那么,模型的输入就是替换之后的词的编号列表吗?
当然不可以了,编号怎么进行各种运算呢???
那替换成编号干啥???不干啥,纯粹是为了方便,没别的意思。
先别急,我们先来看输出是啥。
看一句文本,我看了这个电影之后,觉得这个电影真的很烂,从头到尾我都昏昏欲睡,看的想死的心都有了(这句话是从数据集中翻译出来的一句,数据集是英文,惊喜不?)。再看一句,这部电影真是太棒了,我真是太喜欢了,还想再看第二遍第三遍。
很明显,两句文本代表的是不同的两个类别,简单地给第一个文本设置标签为 $ -1 $ , 给第二个设置标签为 $ +1 $ ,OK吗?OK啊,标签只是个编号,很多分类算法就是这么干的,当然你也可以设置第一个为 $ -100 $ , 第二个为 $ +1 $ ,纯凭自愿。但是,SVM算法中,对不起,你还是乖乖的用 $ -1 $ 和 $ +1 $ 吧,因为这里的标签是参与运算的。当然,后边有机会再讲(估计没机会,哈哈)。 算法内部是这样计算的,但是,上边的y_train可以直接是字符串分类名。这再一次说明了,scikit-learn是神器般的存在。
输出定好了,输入呢?输入呢?输入呢?
急躁的朋友一定早就恨不得大喊:“TF-IDF!” 没错,就是完美而又简洁的TF-IDF值。
但是,先等等,我们还要先选择特征呢。
我们首先从所有的词中,选择靠谱的最能区分类别的词出来,作为特征词,然后只需要用特征词对文本进行分类就好了。为什么这么做?第一:大大降低了输入的维度;第二:减去了无关词的影响,降低过拟合的概率。
好了,那我们怎么选择特征呢,最简单的办法,当然是找人来选一选了,咦,“很烂”可以,哦,“太棒”也可以。。。
等你把特征全部找出来,“咦,我在哪?我是谁?今年是哪一年?”
所以,聪明的你,肯定知道,我们可以用算法大致选择靠谱的特征出来,虽然不如人工选择的那么精确,但是你还是你,时间也还是2019年,不是么。
所以,我们用什么样的特征选择算法呢?
这个例子里,我选择卡方检验作为特征选择方式。
卡方检验
相信只要上过学的朋友,都听说过卡方检验这个名词,那时候可能还不知道用来干嘛,现在总该知道了。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
#选择K个最好的特征,返回选择特征后的数据
chi_features = SelectKBest(chi2, k=10000).fit_transform(tf_vectors, target)再一次,神器就是神器,根本不需要你去费力气嘛。
等等,tf_vectors是啥?
就是用tf-idf计算的值组成的文本表示啊。所以,卡方检验其实也要做数字计算才能得到,所以要先一步计算所有词在某文本中的tf-idf值:
tf_idf_model = TfidfVectorizer(ngram_range=(1, 1),
binary=True,
sublinear_tf=True)
tf_vectors = tf_idf_model.fit_transform(dataset)tf-idf计算出之后,用卡方检验选择特征,最后得到选择了特征之后的文本表示,也就是chi_features。
现在,就可以把chi_features作为x_train,输入模型进行训练了,训练好模型后,就可以对新样本进行预测类别了。
当然,在计算tf-idf值之前,还需要把一些明显不需要的停用词去掉,网上有很多停用词表,直接判断存在然后删除即可。
事情得到完美解决。再回顾一遍流程:
文本->去停用词->计算tf-idf值->特征选择->训练svm模型->预测
这就是svm文本分类的大致流程,是不是超简单?一些代码细节请到github上查看。
就这么一个简单的分类,随便训练的模型,在imdb数据集上的测试准确率已经达到了90%以上。
接下来,在下一篇,详细整理介绍一下SVM的原理,尽量通俗易懂。
参考文献
[1]. 李航. 统计学习方法[M]. 清华大学出版社, 2012.