CNN之手写数字识别(Handwriting Recognition)
CNN之手写数字识别(Handwriting Recognition)
目录
CNN之手写数字识别(Handwriting Recognition)
1、常用的包
2、常见概念
3、手写数字识别器实现
3.1 数据准备
3.2 构建网络
3.3 运行模型
3.4 测试模型
3.5 查看卷积核与特征图
参考文献
1、常用的包
- torchvision.datasets:数据集,对整个数据的封装,统一处理图像或张量等原始数据
- torch.utils.data.DataLoader:数据加载器,负责在程序中对数据集的使用,可实现自动化批量输出数据
- torch.utils.data.sampler:采样器,为加载器提供一个每一批抽取数据集中样本的方法,可实现顺序抽取,随机抽取或按概率分布抽取
2、常见概念
- 卷积(Convolution):在原始图像中搜索与卷积核相似的区域,即用卷积核从左到右、从上到下地进行逐个像素的扫描和匹配,并最终将匹配的结果表示成一张新的图像,通常被称为特征图(Feature Map)
- 输出特征图有多少层,这一层卷积就有多少个卷积核,每一个卷积核会完全独立地进行运算
- 锐化图像(强调细节)、模糊图像(减少细节)都可以看作某种特定权重的卷积核在原始图像上的卷积操作
- 一般情况下,底层卷积操作的特征核数量少,越往后越多
- 特征图中,一个像素就是一个神经元
- 卷积计算的两个阶段:
- 前馈运算阶段(从输入图像到输出概率分布):所有连接的权重值都不改变,系统根据输入图像计算输出分类,并根据网络的分类与数据中标签进行比较,计算出交叉熵作为损失函数
- 反馈学习阶段:根据前馈阶段的损失函数调整所有连接上的权重值,从而完成神经网络的学习过程
- 补齐(Padding):将原始图扩大,用0来填充补充的区域
- 池化(Pooling):将原始图变小,获取粗粒度信息、提炼大尺度图像信息的过程,是对原始图像的缩略和抽象
- 超参数:人为设定的参数值,决定整个网络的架构,如网络层数、神经元数量、卷积核窗口尺寸、卷积核数量、填充格点大小、池化窗口尺寸等
- 参数:不需要人为设定,在网络的训练过程中网络自动学习得到的数值
- 激活函数:提供网络的非线性建模能力
- 损失函数:度量神经网络的输出的预测值与实际值之间的差距
- dropout技术:在深度学习网络的训练过程中,根据一定的概率随机将其中的一些神经元暂时丢弃,这样在每个批的训练过程中,都是在训练不同的神经网络,最后在测试时再使用全部的神经元,这样可以增强模型的泛化能力
3、手写数字识别器实现
3.1 数据准备
import torch
import torch.nn as nn
from torch.autograd import Variable
import torch.optim as optim
import torch.nn.functional as F
import torchvision.datasets as dsets
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
%matplotlib inline
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
torch.backends.cudnn.enabled = True
# 超参数
image_size = 28 # 图像分辨率28*28
num_classes = 10
num_epochs = 60
num_workers = 2
batch_size = 128
train_dataset = dsets.MNIST(root='./data',
train=True,
transform=transforms.Compose([transforms.ToTensor(),
transforms.RandomHorizontalFlip(), # 图像的一半概率翻转,一半不翻
transforms.Normalize(mean=0.5, std=0.5)
]),
download=True)
test_dataset = dsets.MNIST(root='./data',
train=False,
transform=transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=0.5, std=0.5)
]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset=train_dataset, batch_size=batch_size, shuffle=True, num_workers=num_workers)
# 测试数据分成两部分,一部分作为校验数据,一部分作为测试数据
indices = range(len(test_dataset))
indices_val = indices[:4000] # 校验集
indices_test = indices[4000:] # 测试集
# 采样器随机从原始数据集中抽样数据,生成任意一个下标重排,从而利用下标来提取数据集中数据
sampler_val = torch.utils.data.sampler.SubsetRandomSampler(indices_val)
sampler_test = torch.utils.data.sampler.SubsetRandomSampler(indices_test)
val_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, sampler=sampler_val, num_workers=num_workers)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset, batch_size=batch_size, shuffle=False, sampler=sampler_test, num_workers=num_workers)测试其中任意批次中的数据的图像打印及标签
idx = 26
mnist_img = test_dataset[idx][0].numpy() # dataset支持下标索引,提取出来的元素为features、target格式,第25个批次,[0]表示索引features
plt.imshow(mnist_img[0,...])
print('标签是:', test_dataset[idx][1]) 任意批次中的数据的图像打印及标签
任意批次中的数据的图像打印及标签
3.2 构建网络
class ConvNet(nn.Module):
# 构造函数,每当类ConvNet被具体化一个实例时就会被调用
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(in_channels=1, out_channels=4, kernel_size=3, padding=1, stride=1, bias=True)
self.pool = nn.MaxPool2d(kernel_size=2, stride=2)
self.conv2 = nn.Conv2d(in_channels=4, out_channels=8, kernel_size=3, padding=1, stride=1, bias=True)
self.fc1 = nn.Linear(image_size // 4 * image_size // 4 * 8, 512)
self.fc2 = nn.Linear(512, num_classes)
def forward(self, x):
x = F.relu(self.conv1(x))
x = F.relu(self.conv2(self.pool(x)))
x = self.pool(x)
x = x.view(-1, image_size // 4 * image_size // 4 * 8)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training, p=0.4) # 40%的比例随机失活神经元,减少过拟合
x = F.log_softmax(self.fc2(x), dim=1)
return x
# 提取特征图,返回前两层卷积层的特征图
def retrieve_features(self, x):
feature_map1 = F.relu(self.conv1(x))
x = self.pool(feature_map1)
feature_map2 = F.relu(self.conv2(x))
return (feature_map1, feature_map2)3.3 运行模型
net = ConvNet()
# 采用多GPU训练
if torch.cuda.device_count() > 1:
net = nn.DataParallel(net, device_ids=[0, 1])
net.to(device)
print(net)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(params=net.parameters(), lr=0.0001)
record = [] # 记录准确率等数值
weights = [] # 每若干步就记录一次卷积核
def rightness(output, target):
# torch.max函数返回输入张量给定维度上每行的最大值,并同时返回每个最大值的位置索引
preds = output.data.max(dim=1, keepdim=True)[1] # keepdim保持输出的维度
return preds.eq(target.data.view_as(preds)).sum(), len(target) # 返回数值为:(正确样例数,总样本数)
best_acc = 0.0 # 最优准确率
best_epoch = 0 # 最优轮次
save_path = './ConvNet.pth'
for epoch in range(num_epochs):
# 训练
train_rights = [] # 每轮次训练得到的准确数量
net.train() # 把所有的dropout层打开
# enumerate起到枚举器的作用,在train_loader循环时,枚举器会自动输出一个数字指示循环的次数,并记录在batch_idx中
for batch_idx, (data, target) in enumerate(train_loader):
data, target = Variable(data), Variable(target) # data:手写数字图像,target:该图像对应标签
output = net(data.to(device))
loss = criterion(output, target.to(device))
optimizer.zero_grad() # 清空所有被优化变量的梯度信息
loss.backward()
optimizer.step() # 进行单次优化,更新所有的参数
train_rights.append(rightness(output, target.to(device)))
# 校验
net.eval() # 把所有的dropout层关闭
val_rights = [] # 每轮次校验得到的准确数量
with torch.no_grad():
for (data, target) in val_loader:
data, target = Variable(data), Variable(target)
output = net(data.to(device))
val_rights.append(rightness(output, target.to(device)))
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
train_acc = 1.0 * train_r[0] / train_r[1]
val_acc = 1.0 * val_r[0] / val_r[1]
if val_acc > best_acc:
best_acc = val_acc
best_epoch = epoch + 1
torch.save(net.state_dict(), save_path)
print("[epoch {}] loss:{:.6f},train_acc:{:.2f}%,val_acc:{:.2f}%".format(
epoch + 1, loss.item(),
100 * train_acc, 100 * val_acc
))
record.append((1 - train_acc, 1- val_acc))
weights.append([net.module.conv1.weight.data.clone(), net.module.conv1.bias.data.clone(),
net.module.conv2.weight.data.clone(), net.module.conv2.bias.data.clone()])
print("best epoch: %d,best val_acc: %.2f" %(best_epoch, best_acc * 100))输出结果为:
DataParallel(
(module): ConvNet(
(conv1): Conv2d(1, 4, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(4, 8, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(fc1): Linear(in_features=392, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=10, bias=True)
)
)
[epoch 1] loss:0.732432,train_acc:61.29%,val_acc:73.60%
[epoch 2] loss:0.699121,train_acc:79.38%,val_acc:78.98%
[epoch 3] loss:0.430334,train_acc:83.38%,val_acc:82.08%
[epoch 4] loss:0.310445,train_acc:85.96%,val_acc:84.68%
[epoch 5] loss:0.424920,train_acc:88.09%,val_acc:87.00%
[epoch 6] loss:0.297486,train_acc:89.76%,val_acc:88.73%
[epoch 7] loss:0.328308,train_acc:90.91%,val_acc:90.00%
[epoch 8] loss:0.198407,train_acc:92.00%,val_acc:90.85%
[epoch 9] loss:0.150639,train_acc:92.74%,val_acc:91.80%
[epoch 10] loss:0.186586,train_acc:93.15%,val_acc:92.58%
[epoch 11] loss:0.148867,train_acc:93.81%,val_acc:93.38%
[epoch 12] loss:0.161239,train_acc:94.33%,val_acc:93.50%
[epoch 13] loss:0.190747,train_acc:94.63%,val_acc:94.18%
[epoch 14] loss:0.141780,train_acc:94.93%,val_acc:94.33%
[epoch 15] loss:0.137817,train_acc:95.16%,val_acc:94.70%
[epoch 16] loss:0.092569,train_acc:95.43%,val_acc:95.00%
[epoch 17] loss:0.115552,train_acc:95.61%,val_acc:95.12%
[epoch 18] loss:0.155165,train_acc:95.85%,val_acc:95.53%
[epoch 19] loss:0.127627,train_acc:96.06%,val_acc:95.28%
[epoch 20] loss:0.053196,train_acc:96.17%,val_acc:95.85%
[epoch 21] loss:0.152282,train_acc:96.34%,val_acc:95.80%
[epoch 22] loss:0.047420,train_acc:96.44%,val_acc:95.90%
[epoch 23] loss:0.097075,train_acc:96.61%,val_acc:96.03%
[epoch 24] loss:0.209956,train_acc:96.66%,val_acc:96.25%
[epoch 25] loss:0.034327,train_acc:96.83%,val_acc:96.13%
[epoch 26] loss:0.238308,train_acc:96.90%,val_acc:96.40%
[epoch 27] loss:0.023966,train_acc:96.95%,val_acc:96.60%
[epoch 28] loss:0.161187,train_acc:97.05%,val_acc:96.18%
[epoch 29] loss:0.019604,train_acc:97.08%,val_acc:96.65%
[epoch 30] loss:0.041736,train_acc:97.20%,val_acc:96.70%
[epoch 31] loss:0.075512,train_acc:97.29%,val_acc:96.48%
[epoch 32] loss:0.103057,train_acc:97.38%,val_acc:96.45%
[epoch 33] loss:0.136958,train_acc:97.49%,val_acc:96.68%
[epoch 34] loss:0.143319,train_acc:97.41%,val_acc:96.78%
[epoch 35] loss:0.060183,train_acc:97.49%,val_acc:96.88%
[epoch 36] loss:0.032935,train_acc:97.58%,val_acc:96.93%
[epoch 37] loss:0.076284,train_acc:97.60%,val_acc:96.95%
[epoch 38] loss:0.040283,train_acc:97.65%,val_acc:96.95%
[epoch 39] loss:0.064808,train_acc:97.70%,val_acc:97.03%
[epoch 40] loss:0.231935,train_acc:97.83%,val_acc:96.85%
[epoch 41] loss:0.049855,train_acc:97.80%,val_acc:96.95%
[epoch 42] loss:0.042273,train_acc:97.84%,val_acc:97.13%
[epoch 43] loss:0.065264,train_acc:97.86%,val_acc:97.25%
[epoch 44] loss:0.147135,train_acc:97.84%,val_acc:97.23%
[epoch 45] loss:0.052399,train_acc:97.95%,val_acc:97.05%
[epoch 46] loss:0.053043,train_acc:97.90%,val_acc:97.13%
[epoch 47] loss:0.104675,train_acc:98.08%,val_acc:97.18%
[epoch 48] loss:0.042580,train_acc:98.06%,val_acc:97.20%
[epoch 49] loss:0.127764,train_acc:98.01%,val_acc:97.43%
[epoch 50] loss:0.038456,train_acc:98.10%,val_acc:97.50%
[epoch 51] loss:0.077706,train_acc:98.20%,val_acc:97.33%
[epoch 52] loss:0.072369,train_acc:98.17%,val_acc:97.40%
[epoch 53] loss:0.072277,train_acc:98.16%,val_acc:97.23%
[epoch 54] loss:0.036564,train_acc:98.22%,val_acc:97.30%
[epoch 55] loss:0.053939,train_acc:98.33%,val_acc:97.38%
[epoch 56] loss:0.103391,train_acc:98.31%,val_acc:97.38%
[epoch 57] loss:0.105614,train_acc:98.26%,val_acc:97.40%
[epoch 58] loss:0.059945,train_acc:98.26%,val_acc:97.38%
[epoch 59] loss:0.037717,train_acc:98.30%,val_acc:97.43%
[epoch 60] loss:0.024253,train_acc:98.37%,val_acc:97.45%
best epoch: 50,best val_acc: 97.503.4 测试模型
# 测试模型
net= ConvNet()
net.load_state_dict({k.replace('module.',''):v for k,v in torch.load(save_path).items()})
net.to(device)
net.eval()
test_rights = []
for data, target in test_loader:
data, target = Variable(data, requires_grad=False), Variable(target)
output = net(data.to(device))
test_rights.append(rightness(output, target.to(device)))
test_r = (sum(tup[0] for tup in test_rights), sum(tup[1] for tup in test_rights))
test_acc = 1.0 * test_r[0] / test_r[1]
print("test_acc:%.2f%%" %(test_acc * 100))输出结果为:
test_acc:98.75%绘制训练过程中对于训练数据和校验数据的误差曲线:
# 输出误差曲线
train_err_y = [y[0] for y in record]
val_err_y = [y[1] for y in record]
def Show_ErrorRate():
plt.figure(figsize = (10, 7))
x=range(1, num_epochs + 1)
plt.title("Change in Error Rate")
plt.plot(x, train_err_y, color='red', label='train_acc')
plt.plot(x, val_err_y, color='blue', label='val_acc')
plt.legend() # 显示图例
plt.xlabel('epochs')
plt.ylabel('Error rate')
Show_ErrorRate()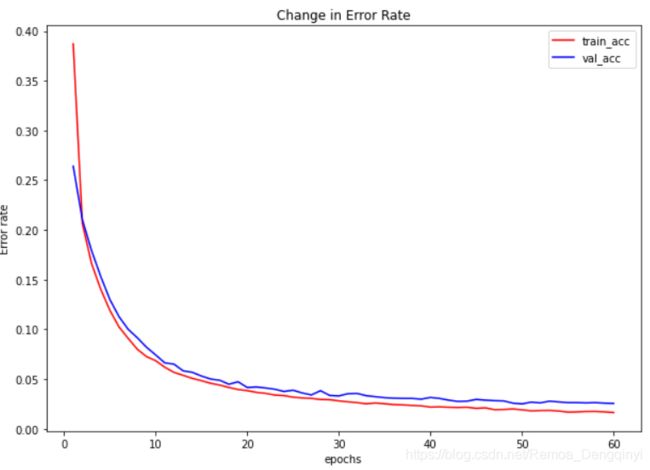 误差曲线
误差曲线
3.5 查看卷积核与特征图
(1)查看第一层4个卷积核:
# 第一层卷积核
plt.figure(figsize = (10,3))
print(net.conv1.weight.data.cpu().shape) # 4,1,3,3
for i in range(4):
plt.subplot(1, 4, i + 1) # 展示为1行4列四个子图
plt.imshow(net.conv1.weight.data.cpu().numpy()[i, 0, ...]) 第一层中4个卷积核
第一层中4个卷积核
(2)打印4个卷积核对应的4张特征图:
# 打印出第一层的四个特征图
input_x = test_dataset[idx][0].unsqueeze(0).to(device) # 让input_x是四维的,才能输入给net,补充的一维表示batch
feature_maps = net.retrieve_features(Variable(input_x))
plt.figure(figsize = (10,3))
for i in range(4):
plt.subplot(1, 4, i + 1) # 展示为1行4列四个子图
plt.imshow(feature_maps[0][0, i, ...].data.cpu().numpy())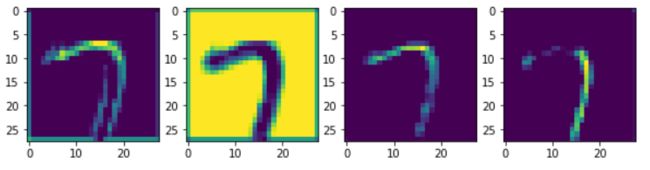 第一层中4张特征图
第一层中4张特征图
(3)查看第一层8个卷积核:
# 第二层卷积核,每一列对应一个卷积核,共8个
plt.figure(figsize = (10*2,3*4))
print(net.conv2.weight.data.cpu().shape) # 8,4,3,3
for i in range(4):
for j in range(8):
plt.subplot(4, 8, i * 8 + j + 1) # 展示为1行4列四个子图
plt.imshow(net.conv2.weight.data.cpu().numpy()[j, i, ...]) 第二层中8个卷积核
第二层中8个卷积核
(4)打印8个卷积核对应的8张特征图:
# 打印出第二层的8个特征图,可看出图像的抽象程度更高
input_x = test_dataset[idx][0].unsqueeze(0).to(device) # 让input_x是四维的,才能输入给net,补充的一维表示batch
feature_maps = net.retrieve_features(Variable(input_x))
plt.figure(figsize = (10*2,3*4))
for i in range(8):
plt.subplot(2, 4, i + 1) # 展示为2行4列,8个子图
plt.imshow(feature_maps[1][0, i, ...].data.cpu().numpy()) 第二层中8张特征图
第二层中8张特征图
参考文献
[1]集智俱乐部:深度学习原理与PyTorch实战. [M]北京:人民邮电出版社,2019.08;