Res2Net: 一种新的多尺度主干体系结构(Res2Net: A New Multi-scale Backbone Architecture )
引言
如图1所示,视觉模式在自然场景中以多尺度出现。首先,对象可以在单个图像中以不同的尺寸出现,例如,沙发和杯子具有不同的尺寸。其次,对象的基本上下文信息可能比对象本身占据更大的区域。例如,我们需要依靠大桌子作为上下文,以更好地判断放置在桌子上的黑色小球是杯子还是笔筒。第三,感知来自不同尺度的信息对于理解诸如细粒度分类和语义分割之类的任务的部分和对象至关重要。因此,为视觉认知任务设计多尺度的良好特征至关重要,包括图像分类 [444] 、物体检测 [53] 、注意力预测 [55] 、目标跟踪 [76] 、动作识别 [56] 、语义分割 [6] 、显著物体检测 [2],[29],物体提议 [12],[53],骨架提取 [80],立体匹配 [52] 和边缘检测 [45],[69]。

多尺度特征已广泛用于常规特征设计 [1],[48] 和深度学习 [10],[61]。在视觉任务中获得多尺度表示需要特征提取器使用大范围的感受域来描述不同尺度的对象/部分/上下文。卷积神经网络 (CNNs) 通过一堆卷积算子自然地学习从粗到细的多尺度特征。CNNs固有的多尺度特征提取能力导致解决众多视觉任务的有效表示。如何设计更高效的网络架构是进一步提高CNNs性能的关键。
在过去的几年中,几个骨干网,例如,[10],[15],[27],[30],[31],[444],[57],[61],[68],[72],凭借最先进的性能,在众多视觉任务中取得了重大进展。早期的体系结构,如AlexNet [444] 和VGGNet [57] 堆叠卷积算子,使得多尺度特征的数据学习变得可行。随后通过使用具有不同内核大小的conv层 (例如,InceptionNets [60],[61],[62]),残差模块 (例如,ResNet [27]),快捷连接 (例如,denseNet [31]) 和分层聚合 (例如,DLA [72])。骨干CNN体系结构的进步已经证明了一种趋势,即更有效和高效的多尺度表示。
在这项工作中,我们提出了一种简单而有效的多尺度处理方法。与大多数现有方法增强cnn的逐层多尺度表示强度不同,我们在更粒度的水平上提高了多尺度表示能力。与一些并行工作 [5],[9],[11] 通过利用具有不同分辨率的特征来提高多尺度能力不同,我们提出的方法的多尺度是指在更粒度的水平上的多个可用的接受场。为了实现这一目标,我们用一组较小的滤波器组替换了n个通道的3 × 3滤波器1,每个滤波器组具有w个通道 (在不损失一般性的情况下,我们使用n = s × w)。如图2所示,这些较小的滤波器组以分层残差状样式连接,以增加输出特征可以表示的比例的数量。具体来说,我们将输入特征图分为几组。一组过滤器首先从一组输入特征图中提取特征。然后将上一组的输出特征与另一组输入特征映射一起发送到下一组过滤器。此过程重复几次,直到处理所有输入特征图。最后,将所有组的特征图串联起来,并发送到另一组1 × 1过滤器,以完全融合信息。与将输入特征转换为输出特征的任何可能路径一起,每当通过3 × 3滤波器时,等效接受场就会增加,由于组合效应,导致许多等效特征比例。
Res2Net策略公开了一个新的维度,即scale (Res2Net块中特征组的数量),作为深度 [57],宽度和基数 [68] 的现有维度之外的基本因素。
请注意,所提出的方法在更细粒度的水平上利用了多尺度潜力,这与利用逐层操作的现有方法正交。因此,所提出的构建块,即Res2Net模块,可以轻松地插入许多现有的CNN架构中。广泛的实验结果表明,Res2Net模块可以进一步提高最先进的cnn的性能,例如ResNet [27],ResNeXt [68] 和DLA [72]。
相关工作
骨干网
近年来见证了许多骨干网 [15],[27],[31],[444],[57],[61],[68],[72],具有更强的多尺度表示的各种视觉任务中实现了最先进的性能。按照设计,由于输入信息遵循从精细到粗略的方式,因此cnn配备了基本的多尺度特征表示能力。AlexNet [444] 按顺序堆叠滤波器,并且比传统的视觉识别方法具有显着的性能增益。但是,由于过滤器的网络深度和内核大小有限,AlexNet仅具有相对较小的感受野。VGGNet [57] 增加了网络深度,并使用了内核大小较小的过滤器。更深的结构可以扩展感受域,这对于从更大范围中提取特征很有用。与使用大内核相比,通过堆叠更多的层来扩大感受野更有效。因此,VGGNet提供了比AlexNet更强的多尺度表示模型,具有更少的参数。但是,AlexNet和VGGNet都直接堆叠滤波器,这意味着每个特征层都有一个相对固定的感受野。
(NIN) [38] 将多层感知器作为微网络插入到大型网络中,以增强感受野内局部补丁的模型可辨性。NIN中引入的1 × 1卷积一直是融合功能的流行模块。GoogLeNet [61] 利用具有不同内核大小的并行过滤器来增强多尺度表示能力。然而,由于其有限的参数效率,这种能力通常受到计算约束的限制。Inception Nets [60],[62] 在GoogLeNet中的并行路径的每个路径中堆叠更多的过滤器,以进一步扩展接收场。另一方面,ResNet [27] 引入了神经网络的短连接,从而缓解了梯度消失的问题,同时获得了更深层次的网络结构。在特征提取过程中,短连接允许卷积算子的不同组合,从而产生大量等效的特征尺度。同样,DenseNet [31] 中的密集连接层使网络能够在非常广泛的范围内处理对象。DPN [10] 将ResNet与DenseNet相结合,实现了ResNet的特征重用能力和DenseNet的特征探索能力。最近提出的DLA [72] 方法在树结构中结合了层。分层结构使网络能够获得更强的逐层多尺度表示能力。
视觉任务的多尺度表示
Cnn的多尺度特征表示对于许多视觉任务非常重要,包括对象检测 [53],人脸分析 [4],[51],边缘检测 [45],语义分割 [6],显着对象检测 [42],[78],和骨架检测 [80],提高了这些领域的模型性能
对象检测
有效的CNN模型需要在场景中定位不同比例的对象。早期的作品,如r-cnn [22],主要依靠骨干网,即VGGNet [57],提取多尺度的特征。他等人提出了一种SPP-Net方法 [26],该方法利用骨干网之后的空间金字塔池化来增强多尺度能力。更快的r-cnn方法 [53] 进一步提出了区域建议网络,以生成具有各种尺度的边界框。基于更快的RCNN,FPN [39] 方法引入特征金字塔,从单个图像中提取具有不同比例的特征。SSD方法 [44] 利用不同阶段的特征图来处理不同比例的视觉信息。
语义分割
提取对象的基本上下文信息需要CNN模型以各种比例处理特征,以进行有效的语义分割。Long等人 [47] 提出了一种最早的方法,该方法可以实现全卷积网络 (FCN) 的多尺度表示,用于语义分割任务。在DeepLab中,Chen等人 [6],[7] 引入了级联atrous卷积模块,以在保留空间分辨率的同时进一步扩展感受野。最近,通过PSPNet中的金字塔池方案,从基于区域的功能汇总了全局上下文信息。
显著物体检测
精确定位图像中的显著对象区域需要理解用于确定对象显著性的大规模上下文信息,以及精确定位对象边界的小规模特征 [79]。早期的方法 [3] 利用手工制作的全局对比度表示 [13] 或多尺度区域特征 [64]。Li等。[34] 提出了最早的方法之一,该方法可以实现用于显着对象检测的多尺度深度特征。后来,提出了多上下文深度学习 [81] 和多级卷积特征 [75],以改善显着对象检测。最近,Hou等人。[29] 在各个阶段之间引入密集的短连接,以在每一层提供丰富的多尺度特征图,用于显着物体检测。
同期工作
最近,有一些工作旨在通过利用多尺度特征来提高性能 [5],[9],[11],[59]。Big-Little Net [5] 是由不同计算复杂度的分支组成的多分支网络。Octave Conv [9] 将标准卷积分解为两种分辨率,以处理不同频率的特征。MSNet [11] 利用高分辨率网络通过使用低分辨率网络学习的上采样低分辨率特征来学习高频残差。除了低分辨率表示外,HRNet [58],[59] 还在网络中引入了高分辨率表示,并反复进行多尺度融合以加强高分辨率表示。[5],[9],[11],[58],[59] 中的一个常见操作是,它们都使用池化或向上采样将特征图的大小调整为原始比例的2n倍,以节省计算预算,同时保持甚至提高性能。而在Res2Net块中,单个残差块模块内的分层残差状连接使接受场的变化在更细粒度的水平,以捕获细节和全局特征。实验结果表明,Res2Net模块可以与那些新颖的网络设计集成在一起,以进一步提高单个残差块模块内的类似残差的连接性能,从而使接收场的变化更加粒度,以捕获细节和全局特征。实验结果表明,Res2Net模块可以与这些新颖的网络设计集成在一起,以进一步提高性能。
RES2NET
Res2Net模块
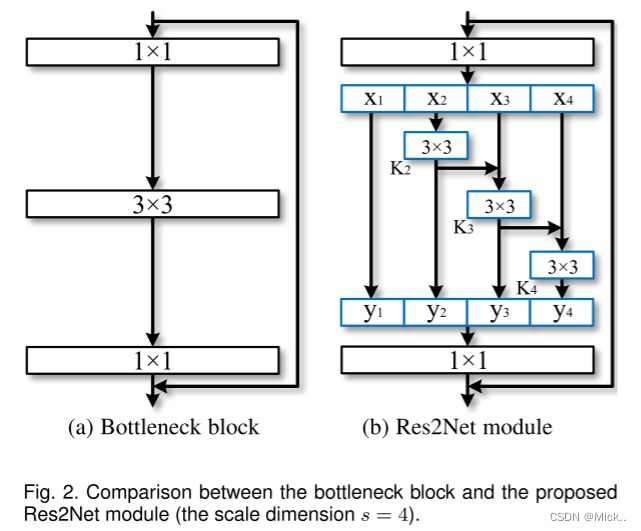
图2(a) 所示的瓶颈结构是许多现代骨干CNNs架构中的基本构建块,例如ResNet [27],ResNeXt [68] 和DLA [72]。我们没有像在瓶颈块中那样使用一组3 × 3滤波器来提取特征,而是寻求具有更强的多尺度特征提取能力的结构,同时保持相似的计算负荷。具体来说,我们用较小的过滤器组替换了一组3 × 3的过滤器,同时以分层残差状样式连接了不同的过滤器组。由于我们提出的神经网络模块涉及单个残差块内的类似残差的连接,因此我们将其命名为Res2Net。
图2显示了瓶颈块和Res2Net模块之间的差异。在1 × 1卷积之后,我们将特征图均匀地分成s个特征图子集,用xi表示,其中i ∈ {1,2,...,s}。与输入特征图相比,每个特征子集xi具有相同的空间大小,但通道数量为1/s。除x1外,每个xi都有对应的3 × 3卷积,用Ki() 表示。我们用yi表示ki () 的输出。特征子集xi与Ki − 1() 的输出相加,然后馈入Ki()。为了在增加s的同时减少参数,我们省略了x1的3 × 3卷积。因此,yi可以写成
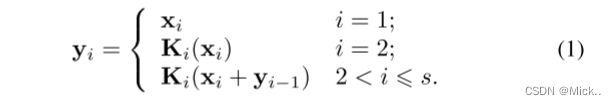
请注意,每个3 × 3卷积算子Ki() 都有可能从所有特征分割 {xj,j ≤ i} 中接收特征信息。每次特征分割xj通过3 × 3卷积算子时,输出结果可能比xj具有更大的感受野。由于组合爆炸效应,Res2Net模块的输出包含不同数量和不同组合的感受野大小/尺度。
在Res2Net模块中,以多尺度方式处理拆分,这有利于提取全局和局部信息。为了更好地融合不同规模的信息,我们将所有拆分连接起来,并通过1 × 1卷积传递。拆分和级联策略可以实施卷积,以更有效地处理特征。为了减少参数的数量,我们省略了第一次拆分的卷积,这也可以被视为特征重用的一种形式。
与现代模块的集成
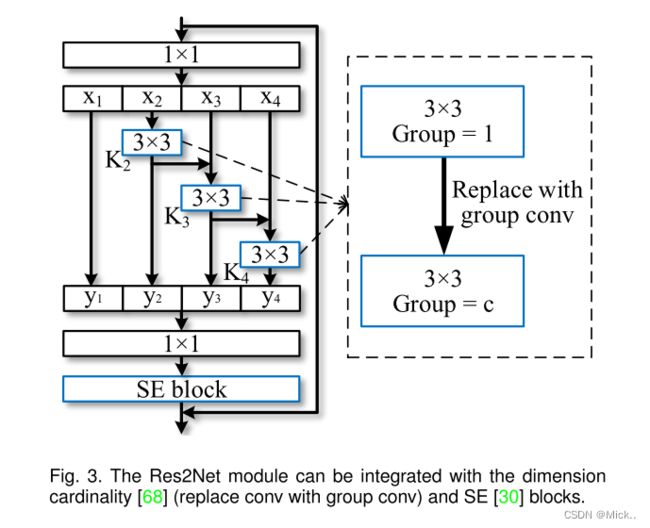 近年来已经提出了许多神经网络模块,包括谢等人 [68] 引入的基数,以及胡等人 [30] 提出的挤压和激励 (SE) 块。Res2Net模块引入了与这些改进正交的尺度。如图3所示,我们可以轻松地将基数[68] 和SE块 [30] 与建议的Res2Net模块集成在一起。
近年来已经提出了许多神经网络模块,包括谢等人 [68] 引入的基数,以及胡等人 [30] 提出的挤压和激励 (SE) 块。Res2Net模块引入了与这些改进正交的尺度。如图3所示,我们可以轻松地将基数[68] 和SE块 [30] 与建议的Res2Net模块集成在一起。
基数维度
维度基数表示滤波器内的组数 [68]。此维度将滤波器从单分支更改为多分支,并提高了CNN模型的表示能力。在我们的设计中,我们可以将3 × 3卷积替换为3 × 3组卷积,其中c表示组的数量。
SEblock
SE块通过显式建模通道之间的相互依赖性,自适应地重新校准通道上的特征响应 [30]。类似于 [30],我们在Res2Net模块的剩余连接之前添加SE块。
集成模型
由于所提出的Res2Net模块没有对整体网络结构的特定要求,并且Res2Net模块的多尺度表示能力与CNNs的逐层特征聚合模型正交,因此我们可以轻松地将所提出的Res2Net模块集成到最先进的模型中,如ResNet [27] 、ResNeXt [68] 、DLA [72] 和Big-Little Net [5]。相应的模型分别称为Res2Net、Res2NeXt、Res2Net-DLA和bLRes2Net-50。
提出的尺度与先前工作的基数 [68] 和宽度 [27] 正交。因此,在设定尺度后,我们调整基数和宽度的值,以保持总体模型复杂度与其对应的相似。在这项工作中,我们不专注于减小模型大小,因为它需要更细致的设计,例如深度可分离卷积 [49],模型修剪 [23] 和模型压缩 [14]。
代码:
import torch.nn as nn
import math
import torch.utils.model_zoo as model_zoo
import torch
import torch.nn.functional as F
__all__ = ['Res2Net', 'res2net50']
model_urls = {
'res2net50_26w_4s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_4s-06e79181.pth',
'res2net50_48w_2s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_48w_2s-afed724a.pth',
'res2net50_14w_8s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_14w_8s-6527dddc.pth',
'res2net50_26w_6s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_6s-19041792.pth',
'res2net50_26w_8s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net50_26w_8s-2c7c9f12.pth',
'res2net101_26w_4s': 'https://shanghuagao.oss-cn-beijing.aliyuncs.com/res2net/res2net101_26w_4s-02a759a1.pth',
}
class Bottle2neck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, stride=1, downsample=None, baseWidth=26, scale = 4, stype='normal'):
""" Constructor
Args:
inplanes: input channel dimensionality
planes: output channel dimensionality
stride: conv stride. Replaces pooling layer.
downsample: None when stride = 1
baseWidth: basic width of conv3x3
scale: number of scale.
type: 'normal': normal set. 'stage': first block of a new stage.
"""
super(Bottle2neck, self).__init__()
width = int(math.floor(planes * (baseWidth/64.0)))
self.conv1 = nn.Conv2d(inplanes, width*scale, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(width*scale)
if scale == 1:
self.nums = 1
else:
self.nums = scale -1
if stype == 'stage':
self.pool = nn.AvgPool2d(kernel_size=3, stride = stride, padding=1)
convs = []
bns = []
for i in range(self.nums):
convs.append(nn.Conv2d(width, width, kernel_size=3, stride = stride, padding=1, bias=False))
bns.append(nn.BatchNorm2d(width))
self.convs = nn.ModuleList(convs)
self.bns = nn.ModuleList(bns)
self.conv3 = nn.Conv2d(width*scale, planes * self.expansion, kernel_size=1, bias=False)
self.bn3 = nn.BatchNorm2d(planes * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stype = stype
self.scale = scale
self.width = width
def forward(self, x):
residual = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
spx = torch.split(out, self.width, 1)
for i in range(self.nums):
if i==0 or self.stype=='stage':
sp = spx[i]
else:
sp = sp + spx[i]
sp = self.convs[i](sp)
sp = self.relu(self.bns[i](sp))
if i==0:
out = sp
else:
out = torch.cat((out, sp), 1)
if self.scale != 1 and self.stype=='normal':
out = torch.cat((out, spx[self.nums]),1)
elif self.scale != 1 and self.stype=='stage':
out = torch.cat((out, self.pool(spx[self.nums])),1)
out = self.conv3(out)
out = self.bn3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
out = self.relu(out)
return out
class Res2Net(nn.Module):
def __init__(self, block, layers, baseWidth = 26, scale = 4, num_classes=1000):
self.inplanes = 64
super(Res2Net, self).__init__()
self.baseWidth = baseWidth
self.scale = scale
self.conv1 = nn.Conv2d(3, 64, kernel_size=7, stride=2, padding=3,
bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
self.maxpool = nn.MaxPool2d(kernel_size=3, stride=2, padding=1)
self.layer1 = self._make_layer(block, 64, layers[0])
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Linear(512 * block.expansion, num_classes)
for m in self.modules():
if isinstance(m, nn.Conv2d):
nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')
elif isinstance(m, nn.BatchNorm2d):
nn.init.constant_(m.weight, 1)
nn.init.constant_(m.bias, 0)
def _make_layer(self, block, planes, blocks, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(planes * block.expansion),
)
layers = []
layers.append(block(self.inplanes, planes, stride, downsample=downsample,
stype='stage', baseWidth = self.baseWidth, scale=self.scale))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, baseWidth = self.baseWidth, scale=self.scale))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.bn1(x)
x = self.relu(x)
x = self.maxpool(x)
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
def res2net50(pretrained=False, **kwargs):
"""Constructs a Res2Net-50 model.
Res2Net-50 refers to the Res2Net-50_26w_4s.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_4s']))
return model
def res2net50_26w_4s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_4s']))
return model
def res2net101_26w_4s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 23, 3], baseWidth = 26, scale = 4, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net101_26w_4s']))
return model
def res2net50_26w_6s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 6, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_6s']))
return model
def res2net50_26w_8s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_26w_4s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 26, scale = 8, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_26w_8s']))
return model
def res2net50_48w_2s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_48w_2s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 48, scale = 2, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_48w_2s']))
return model
def res2net50_14w_8s(pretrained=False, **kwargs):
"""Constructs a Res2Net-50_14w_8s model.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
"""
model = Res2Net(Bottle2neck, [3, 4, 6, 3], baseWidth = 14, scale = 8, **kwargs)
if pretrained:
model.load_state_dict(model_zoo.load_url(model_urls['res2net50_14w_8s']))
return model
if __name__ == '__main__':
images = torch.rand(1, 3, 224, 224).cuda(0)
model = res2net101_26w_4s(pretrained=True)
model = model.cuda(0)
print(model(images).size())简单版的resnet实现
import torch
import torch.nn as nn
import torch.nn.functional as function
class Res2NetBlock(nn.Module):
def __init__(self, inplanes, outplanes, scales=4):
super(Res2NetBlock, self).__init__()
if outplanes % scales != 0: # 输出通道数为4的倍数
raise ValueError('Planes must be divisible by scales')
self.scales = scales
# 1*1的卷积层
self.inconv = nn.Sequential(
nn.Conv2d(inplanes, 32, 1, 1, 0),
nn.BatchNorm2d(32)
)
# 3*3的卷积层,一共有3个卷积层和3个BN层
self.conv1 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
self.conv2 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
self.conv3 = nn.Sequential(
nn.Conv2d(8, 8, 3, 1, 1),
nn.BatchNorm2d(8)
)
# 1*1的卷积层
self.outconv = nn.Sequential(
nn.Conv2d(32, 32, 1, 1, 0),
nn.BatchNorm2d(32),
nn.ReLU(inplace=True)
)
def forward(self, x):
input = x
x = self.inconv(x)
# scales个部分
xs = torch.chunk(x, self.scales, 1)
ys = []
ys.append(xs[0])
ys.append(function.relu(self.conv1(xs[1])))
ys.append(function.relu(self.conv2(xs[2]) + ys[1]))
ys.append(function.relu(self.conv2(xs[3]) + ys[2]))
y = torch.cat(ys, 1)
y = self.outconv(y)
output = function.relu(y + input)
return output
参考文献
Res2Net: A New Multi-scale Backbone Architecture – 程明明个人主页 (mmcheng.net)
Res2Net Applications (github.com)