中国大学MOOC胡浩基的机器学习第二章(支持向量机)兵王问题python版本——在python上初步使用libsvm
在中国大学MOOC上看了胡浩基的机器学习课程,完全面向入门人群感觉挺好。其中有关原理的部分讲的很细。(虽然有几个细节我还是没懂.......)其中在第二章的例题兵王问题中课程只给了MATLAB的版本。但是,我相信也有极小部分人和我一样对MATLAB不太熟悉的。所以,我自己就按照我对老师的MATLAB的代码的理解写了python版本。先放源码大多数的内容我都会写在注释(中文)上,还有几个我认为大家可能会有疑惑的地方会在之后列出。
# -*- coding: utf-8 -*-
import numpy as np
from libsvm.python.svm import *
from libsvm.python.svmutil import *
def data_read_mat(file_name):
'''
从文件中取出数据
:param file_name: 文件名称
:return: 返回一个n*7的矩阵,前6项是三个坐标,第七项是标签
'''
num_list = []
'''
一下是对数据进行读入并且处理,其中open的参数中encoding之所以设置成UTF-8-sig
是因为如果我们把这个参数设置为UTF-8或者不设置,在读入的开头多出\ufeff这么一串
东西,有时候会以中文字的形式出现。
'''
with open(file_name,"r",encoding='UTF-8-sig') as file:
for l in file:
l = l.split(',')
list_k = []
for j in range(3):
list_k.append(ord(l[j*2]) - ord('a'))
list_k.append(ord(l[j*2 + 1]) - ord('0'))
if(l[6][0] == 'd'):
list_k.append(-1)
else:
list_k.append(1)
num_list.append(list_k)
num_mat = np.array(num_list,dtype="float")
'''
在此处是以numpy的二维数据矩阵的形式存储的,本以为使用numpy的数据进行运算可以使得
训练的速度快一些。结果发现如果要往libsvm中的函数传入参数只能传入list型不能传入numpy
的数据类型。所以,后面又把数据类型转回了list型。但是,我猜应该是有方法可以把numpy
的数据类型传入使用的。于是我在读取数据后任然返回的是numpy的形式。
'''
return num_mat
def data_deal(mat,len_train,len1,len_test,len2):
'''
将数据进行处理,分出训练数据和测试数据
:param mat: 大矩阵,其中包括训练数据和测试数据
:param len_train:训练数据
:param len1: 输入坐标
:param len_test: 测试数据
:param len2: 标签
:return: 返回的依次是训练输入数据,测试输入数据,训练输入数据的标签,测试输入数据的标签
'''
np.random.shuffle(mat) #先将矩阵按行打乱。然后根据要求对矩阵进行分割,第一部分就是训练集,第二部分就是测试集
x_part1 = mat[0:len_train,0:len1]
x_part2 = mat[len_train:,0:len1]
y_part1 = mat[0:len_train,len1]
y_part2 = mat[len_train:,len1]
# 标准化
# 根据训练集求出均值和方差
avgX = np.mean(x_part1)
stdX = np.std(x_part1)
# print(avgX,stdX)
#将训练集和测试集都进行归一化处理
for data in x_part1:
for j in range(len(data)):
data[j] = (data[j] - avgX) / stdX
for data in x_part2:
for j in range(len(data)):
data[j] = (data[j] - avgX) / stdX
return x_part1,y_part1,x_part2,y_part2
def TrainModel(CScale,gammaScale,prob):
'''
:param CScale: 参数C的取值序列
:param gammaScale: 参数γ的取值序列
:param prob: 训练集合对应的标签
:return: maxACC(最高正确率),maxACC_C(最优参数C),maxACC_gamma(最优参数γ)
'''
maxACC = 0
maxACC_C = 0
maxACC_gamma = 0
for C in CScale:
C_ = pow(2, C)
for gamma in gammaScale:
gamma_ = pow(2, gamma)
# 设置训练的参数
# 其中-v 5表示的是2折交叉验证
# “-q”可以去掉这样也就可以看到训练过程
param = svm_parameter('-t 2 -c ' + str(C_) + ' -g ' + str(gamma_) + ' -v 5 -q')
ACC = svm_train(prob, param) # 进行训练,但是传回的不是训练模型而是5折交叉验证的准确率
#更新数据
if (ACC > maxACC):
maxACC = ACC
maxACC_C = C
maxACC_gamma = gamma
return maxACC,maxACC_C,maxACC_gamma
def getNewList(L,U,step):
l = []
while(L < U):
l.append(L)
L += step
return l
def TrainModelSVM(data,label,iter,model_file):
'''
模型训练并保存
:param data: 数据
:param label: 标签
:param iter:训练次数,在原先的MATLAB代码中的次数是两次
:param model_file:模型的保存位置
:return: 返回最优参数
'''
#将数据转换成list型的数据。因为,在svm的函数中好像只能传入list型的数据进行训练使用
X = data.tolist()
Y = label.tolist()
CScale = [-5, -3, -1, 1, 3, 5,7,9,11,13,15] #参数C的2^C
gammaScale = [-15,-13,-11,-9,-7,-5,-3,-1,1,3] #参数γ的取值2^γ
cnt = iter
step = 2 #用于重新生成CScale和gammaScale序列
maxACC = 0 #训练过程中的最大正确率
bestACC_C = 0 #训练过程中的最优参数C
bestACC_gamma = 0 #训练过程中的最优参数γ
prob = svm_problem(Y, X) # 传入数据
while(cnt):
#用传入的参数序列进行训练,返回的是此次训练的最高正确率,最优参数C,最优参数γ
maxACC_train,maxACC_C_train,maxACC_gamma_train = TrainModel(CScale,gammaScale,prob)
#数据更新
if(maxACC_train > maxACC):
maxACC = maxACC_train
bestACC_C = maxACC_C_train
bestACC_gamma = maxACC_gamma_train
#根据返回的参数重新生成CScale序列和gammaScale序列用于再次训练,下一次训练的C参数和γ参数的精度会比之前更高
#step就是CScale序列和gammaScale序列的相邻两个数之间的间隔
new_step = step*2/10
CScale = getNewList(maxACC_C_train - step,maxACC_C_train + step + new_step,new_step)
gammaScale = getNewList(maxACC_gamma_train - step,maxACC_gamma_train + step + new_step,new_step)
cnt -= 1
#获得最优参数后计算出对应的C和γ,并且训练获得“最优模型”
C = pow(2,bestACC_C)
gamma = pow(2,bestACC_gamma)
param = svm_parameter('-t 2 -c ' + str(C) + ' -g ' + str(gamma))
model = svm_train(prob, param) # 交叉验证准确率
svm_save_model(model_file, model) #保存模型
return model
def main():
data_file = r"E:\python_study\KingSVM\krkopt.data" #数据存放的位置(需要修改)
mode_file = r"E:\python_study\KingSVM\model_file" #训练模型保存的位置(需要修改)
data_mat = data_read_mat(data_file) #从文件中读取数据并处理
#以下是对数据训练进行分配,可以根据你的需要进行调整
train = 5000 #5000组数据作为训练数据
test = len(data_mat) - 5000 #剩下的数据作为测试数据
#————————————————————————————————————————————————————————————#
x_len = 6 #输入数据的维度是6维,即三个棋子的坐标
y_len = len(data_mat[0]) - x_len #输出的数据时1维,即两种结果
iter = 2# 训练的次数,训练的次数越多参数就调整的精度就越高
x_train,y_train,x_test,y_test = data_deal(data_mat,train,x_len,test,y_len) #对数据进行分割
if (input("是否需要进行训练?") == 'y'): #如果输入y就会进行训练,否则就可以直接使用之前训练的完成的模型
model = TrainModelSVM(x_train,y_train,iter,mode_file) #传入输入数据,标签进行模型的训练
else:
model = svm_load_model(mode_file) #直接加载现有模型
X = x_test.tolist() #将测试集的输入集转换成list
Y = y_test.tolist() #将测试集的输出集转换成list
print(Y[:10])
p_labs,p_acc,p_vals = svm_predict(Y,X,model)
if __name__ == "__main__":
main()
最后,我在尝试后预测正确率比课程视频中放出来的低0.2%。但是,总体来说应该是没有问题。接下来是列举出我认为大家可能会碰到的问题。
1.在python中怎么安装libsvm?
我用的pycharm我猜用这种方式应该是可以安装的,具体细节百度一下。(虽然我没试过)

而我使用的安装方式是参照这个博客:python libsvm安装_jessica218的博客-CSDN博客
2.大家在百度libsvm的使用时,可能会看到这个函数svm.SCV。我在刚开始的时候也碰到了不少文章中使用这个的。但是,用了这个函数死活不行。我猜可能在libsvm的老版本中使用的就是这个,对应现在这个版本中svm.svm_train。除此之外的还有svmutil.svm_read_problem在现在的版本中好像也没有了。
3.为什么libsvm中参数传入不支持numpy的一些数据类型?
在svm.py文件中我们可以看到这样一段:
class svm_problem(Structure):
_names = ["l", "y", "x"]
_types = [c_int, POINTER(c_double), POINTER(POINTER(svm_node))]
_fields_ = genFields(_names, _types)
def __init__(self, y, x, isKernel=False):
if (not isinstance(y, (list, tuple))) and (not (scipy and isinstance(y, scipy.ndarray))):
raise TypeError("type of y: {0} is not supported!".format(type(y)))
if isinstance(x, (list, tuple)):
if len(y) != len(x):
raise ValueError("len(y) != len(x)")
elif scipy != None and isinstance(x, (scipy.ndarray, sparse.spmatrix)):
if len(y) != x.shape[0]:
raise ValueError("len(y) != len(x)")
if isinstance(x, scipy.ndarray):
x = scipy.ascontiguousarray(x) # enforce row-major
if isinstance(x, sparse.spmatrix):
x = x.tocsr()
pass
else:
raise TypeError("type of x: {0} is not supported!".format(type(x)))
self.l = l = len(y)
max_idx = 0
x_space = self.x_space = []
if scipy != None and isinstance(x, sparse.csr_matrix):
csr_to_problem(x, self, isKernel)
max_idx = x.shape[1]
else:
for i, xi in enumerate(x):
tmp_xi, tmp_idx = gen_svm_nodearray(xi,isKernel=isKernel)
x_space += [tmp_xi]
max_idx = max(max_idx, tmp_idx)
self.n = max_idx
self.y = (c_double * l)()
if scipy != None and isinstance(y, scipy.ndarray):
scipy.ctypeslib.as_array(self.y, (self.l,))[:] = y
else:
for i, yi in enumerate(y): self.y[i] = yi
self.x = (POINTER(svm_node) * l)()
if scipy != None and isinstance(x, sparse.csr_matrix):
base = addressof(self.x_space.ctypes.data_as(POINTER(svm_node))[0])
x_ptr = cast(self.x, POINTER(c_uint64))
x_ptr = scipy.ctypeslib.as_array(x_ptr,(self.l,))
x_ptr[:] = self.rowptr[:-1]*sizeof(svm_node)+base
else:
for i, xi in enumerate(self.x_space): self.x[i] = xi
其中注意这部分:
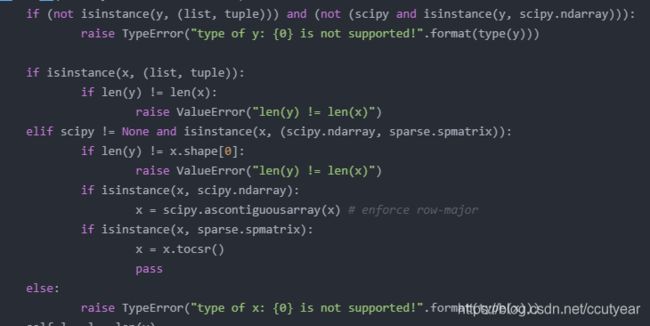
其中isinstance(a,type)是判断a是否是type类型的,我们看上图的第一行和第三行可以看到传入的参数x,y必须是list或者typle类型的,否则就会异常退出。
4.标准化这个步骤很重要法,如果没有标准化正确率就会变成大约90%。(瞎猜的正确率也是90%)
——————————————————————END————————————————————————
回答评论区river_ocean111的提问,因为来看这篇的基本上都是初学者,所以我想别人应该也会有这个问题。
在看完MOOC胡浩基的课后应该能明白下面这几点:
1.gamma是高斯核中所需要设置的超参数(在这个例子中使用的就是高斯核函数)(第二章第11个视频5:02)
至于具体细节我也不知道这个高斯核是怎么推导出来的,这个还需要看一些相关的资料。(就连李航的《统计学方法》中都没有详细阐述这个高斯核的由来,可见这个东西要么很基础要么很古老。)
2.C是SVM算法中所需要设置的一个超参数(第二章第4个视频2:50)
而这个的话直接看视频应该就能很好的理解为什么会有C这个超参数。
3.C,gamma由于人工经验所以选取的范围。C = 2^(-5)~2^(15),gamma=2^(-15)~2^(3)(第二章第12个视频6:59)
明白了之后在回到coding这,你可以这样理解。我们的目的是需要找到一个最优的C和gamma。当然在这个问题中我们都当做C和gamma都大致符合下面这个图,就只是一座山的形状,而我们要找的是那个山尖。
(没有3D的绘图工具只能画个2D的来凑合一下)
而事实是大致符合下面这个图,像一个丘陵一样。我们想要找到的是最好全局的最高点,但是这是非常困难的所以我们只需要找到一个全局的较高点即可。

如果你到此为止都看懂了,那你应该也就能理解了其实也不一定非要用pow(2,C),pow(2,gamma),完全可以把111行和112行CScale,gammaScale之后的列表改成具体的数值。这样一来直接用C和gamma就行。(我没有试过,我估计单次训练的速度会变快。但是,每次训练的效果会变差。)
回答第二个问题:我试了一下什么也不用改。至于具体原因的话,还是琢磨一下SVM的源码吧,这个我也没有仔细研究过。从SVM的原理上来看的话,咋们也可以知道SVM就是单纯的解决2分类问题与分类标签为1,0还是标签为1,-1并没有关系。