机器学习实践——人员越界识别(基于Aidlux+Yolov5实现)
一、人员越界识别背景描述
实际生活中某些场景下需要配合摄像头自动识别危险区域,并在发现有人员闯入危险区域(禁止进入区域)时进行报警,确保员工的人身安全。
二、算法目标
识别指定区域是否有有人越过改区域,并进行生成相应报警逻辑。
三、Aidlux与yolov5简介
3.1 Aidlux平台——一个跨平台应用的系统
Aidlux是基于ARM架构的跨生态(Android/鸿蒙+Linux)一站式AIoT应用开发和部署平台。
Aidlux可以进行Python版本的AI模型开发和移植,使得开发者可以基于一台安卓手机或者基于一台AidBox边缘设备进行开发,并且无缝衔接,在此基础上同时带来原生Android和原生Linux使用体验。

即Linux上开发的Python代码,可以在安卓手机、边缘设备上转换后使用。
一定程度上说,Aidlux简化了Android系统设备上的算法应用开发。
常规的方式,应用在手机Android时,需要将PC上编写的代码,封装成Android SO库(C++)。经过测试后,封装JNI调用SO库,最终在Android上使用Java调用JNI,最终再进行测试发布。可以看到,这样的流程需要一系列的工作人员参与,比如C++、Java、Python的工程师。但是大多数算法人员可能会用Python更多一些,比如上面编写的整套算法。而Aidlux将其中的整个开发流程,全部打通,通过Aidlux平台,可以将PC端编写的代码,快速应用到Android系统上。

Aidlux内部一方面内置了多种深度学习框架,便于快速开发。另外还对于多种算子进行了优化加速,很多算法的性能,也都能达到实时使用。
目前使用Aidlux主要有两种方式:
(1)边缘设备的方式:阿加犀用高通芯片的S855,和S865制作了两款边缘设备,一款提供7T算力,一款提供15T算力。
(2)手机设备的方式:没有边缘设备的情况下,可以使用手机版本的Aidlux,尝试边缘设备的所有功能。
这里使用的是手机设备的方式,通过下载安装手机Aidlux的APP软件即可。然后将开发的算法通过Aidlux即可部署到手机段。(因为直接在手机上操作编程,较为麻烦,,因此可以通过IP的方式,直接映射到电脑上操作。具体操作方式将在后面文章另做详述,在此不做赘述)。

3.2 yolov5
关于yolov5方面,江大白老师有做过yolo系列的相关内容,强烈推荐参考:
深入浅出Yolo系列之Yolov3&Yolov4&Yolov5&Yolox核心基础知识完整讲解
深入浅出Yolo系列之Yolov5核心基础知识完整讲解
四、业务逻辑分析及算法实现
越界识别的功能实现,主要包括人体目标检测、人体追踪及越界识别判断三部分
4.1 行人目标检测
这一部分主要利用YOLOv5算法实现。
首先基于YOLOv5目标检测算法训练一个检测行人(person)的权重person.pt。
训练得到的pt权重可用于在PC端进行推理测试,但是要是在边缘端Aidlux上进行使用,需要将pt模型转为tflite模型,再将tflite模型移植到Aidlux上使用,并适当修改对应推理代码,实现在Aidlux的推理。
(1)利用export.py文件实现模型转化,主要修改其中的三个地方,如下所示:

(2)Aidlux视频推理代码
要将PC段yolov5的推理代码应用到Aidlux上,需要结合Aidlux平台自身的一些专属函数接口对代码做适当调整,主要包括三个部分:
a、加载相关的函数库
# aidlux相关
from cvs import *
import aidlite_gpu
from utils import detect_postprocess, preprocess_img, draw_detect_res
import time
import cv2
b、模型初始化及加载
# AidLite初始化:调用AidLite进行AI模型的加载与推理,需导入aidlite
aidlite = aidlite_gpu.aidlite()
# Aidlite模型路径
model_path = '/home/aidlux/person.tflite'
# 定义输入输出shape
in_shape = [1 * 640 * 640 * 3 * 4]
out_shape = [1 * 25200 * 6 * 4]
# 加载Aidlite检测模型:支持tflite, tnn, mnn, ms, nb格式的模型加载
aidlite.ANNModel(model_path, in_shape, out_shape, 4, 0)
其中主要用到两个函数接口,一个是aidlite_gpu.aidlite()和aidlite.ANNMode()。
c、视频读取&模型推理代码
# 读取视频进行推理
cap = cvs.VideoCapture("/home/aidlux/person.mp4")
frame_id = 0
while True:
frame = cap.read()
if frame is None:
continue
frame_id += 1
if not int(frame_id) % 5 == 0: continue
# 预处理
img = preprocess_img(frame, target_shape=(640, 640), div_num=255, means=None, stds=None)
# 数据转换
aidlite.setInput_Float32(img, 640, 640)
# 模型推理API
aidlite.invoke()
# 读取返回的结果
pred = aidlite.getOutput_Float32(0)
# 数据维度转换
pred = pred.reshape(1, 25200, 6)[0]
# 模型推理后处理
pred = detect_postprocess(pred, frame.shape, [640, 640, 3], conf_thres=0.5, iou_thres=0.45)
# 绘制推理结果
res_img = draw_detect_res(frame, pred)
cvs.imshow(res_img)
效果图示:

4.2 目标追踪
目标追踪的实现主要是在实现目标检测的前提下,补充目标追踪功能,即通过追踪并绘制每个目标的track_id信息实现。
主要实现代码部分如下:
# 目标追踪相关功能
det = []
# Process predictions
for box in pred[0]: # per image
box[2] += box[0]
box[3] += box[1]
det.append(box)
if len(det):
# Rescale boxes from img_size to im0 size
online_targets = tracker.update(det, [frame.shape[0], frame.shape[1]])
online_tlwhs = []
online_ids = []
online_scores = []
# 取出每个目标的追踪信息
for t in online_targets:
# 目标的检测框信息
tlwh = t.tlwh
# 目标的track_id信息
tid = t.track_id
online_tlwhs.append(tlwh)
online_ids.append(tid)
online_scores.append(t.score)
# 针对目标绘制追踪相关信息
res_img = plot_tracking(res_img, online_tlwhs, online_ids, 0,0)
4.3 越界识别判断
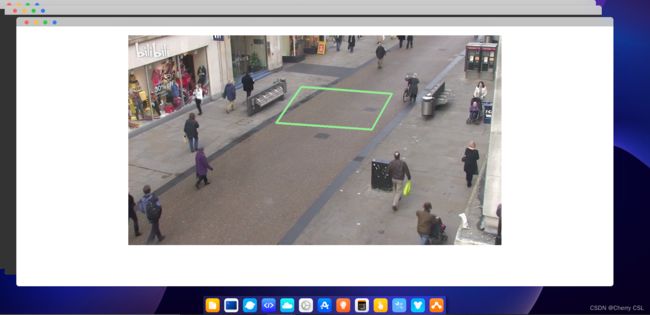
(1)越界监测区域绘制
实现越界识别,即检测某个感兴趣区域,是否有人违规进入。所以首先需要设置一个感兴趣区域(监测区域),然后结合目标追踪判断是否有人员闯入检测区域内。
代码如下:

(2) 人体检测监测点调整
绘制好监测区域后,结合前面目标检测追踪部分,便可进行越界识别判断。
这里需要注意的是在实际业务场景中,通常判断人体越界的点,主要用的是人体脚部的点。使用yolov5算法得到的是人物检测框的四个点信息[x,y,w,h],即目标框的左上角点的x,y坐标和宽w、高h,因此需要通过代码,转换成人体下方的点,即[左上角点x+1/2*宽w,左上角点y+高h]。
转换代码如下:
# 2.计算得到人体下方中心点的位置(人体检测监测点调整)
pt = [tlwh[0]+1/2*tlwh[2],tlwh[1]+tlwh[3]]
(3) 人体状态追踪判断
获取了人体的坐标信息,需要结合绘制的检测区坐标,判断人体是否在监测区域内,并将将人体的状态进行区分。比如将人体在监测区域内设置为1,不在监测区域内设置为-1。
所以代码中需要判断每个人的运动状态,将每个人运动轨迹中,每一帧在图片上的状态统计下来。
# 3. 人体和违规区域的判断(人体状态追踪判断)
track_info = is_in_poly(pt, points)
if tid not in track_id_status.keys():
track_id_status.update( {tid:[track_info]})
else:
if track_info != track_id_status[tid][-1]:
track_id_status[tid].append(track_info)
(4)越界行为判断
基于上面对行人在视频中每一帧的移动轨迹中状态的记录,便可进一步判断行人是否越界。比如某个人当前一帧的状态是-1,后一帧的状态变成1时,说明刚刚进入越界区域,此时就将当前的图片进行保存,留作告警记录。
代码如下:
# 4. 判断是否有track_id越界,有的话保存成图片
# 当某个track_id的状态,上一帧是-1,但是这一帧是1时,说明越界了
if track_id_status[tid][-1] == 1 and len(track_id_status[tid]) >1:
# 判断上一个状态是否是-1,是否的话说明越界,为了防止继续判别,随机的赋了一个3的值
if track_id_status[tid][-2] == -1:
track_id_status[tid].append(3)
cv2.imwrite("overstep.jpg",res_img)
4.4 越界识别&系统告警
一般在实际应用的项目业务系统中,需要对最后检测的报警信息进行通知警告,因此可进一步将记录的报警信息进行相应处理。
