数据挖掘与分析课程笔记(Chapter 21)
数据挖掘与分析课程笔记
- 参考教材:Data Mining and Analysis : MOHAMMED J.ZAKI, WAGNER MEIRA JR.
文章目录
- 数据挖掘与分析课程笔记(目录)
- 数据挖掘与分析课程笔记(Chapter 1)
- 数据挖掘与分析课程笔记(Chapter 2)
- 数据挖掘与分析课程笔记(Chapter 5)
- 数据挖掘与分析课程笔记(Chapter 7)
- 数据挖掘与分析课程笔记(Chapter 14)
- 数据挖掘与分析课程笔记(Chapter 15)
- 数据挖掘与分析课程笔记(Chapter 20)
- 数据挖掘与分析课程笔记(Chapter 21)
笔记目录
- 数据挖掘与分析课程笔记
- 文章目录
- Chapter 21: Support Vector Machines (SVM)
-
- 21.1 支撑向量与余量
- 21.2 SVM: 线性可分情形
Chapter 21: Support Vector Machines (SVM)
21.1 支撑向量与余量
Set up: D = { ( x i , y i ) } i = 1 n , x i ∈ R d , y i ∈ { − 1 , 1 } \mathbf{D}=\{(\mathbf{x}_i,y_i) \}_{i=1}^n,\mathbf{x}_i \in \mathbb{R}^d,y_i \in \{-1,1 \} D={(xi,yi)}i=1n,xi∈Rd,yi∈{−1,1},仅两类数据。
-
超平面 (hyperplanes, d − 1 d-1 d−1 维): h ( x ) : = w T x + b = w 1 x 1 + ⋯ + w d x d + b h(\mathbf{x}):=\mathbf{w}^T\mathbf{x}+b=w_1x_1+ \cdots +w_dx_d+b h(x):=wTx+b=w1x1+⋯+wdxd+b
其中, w \mathbf{w} w 是法向量, − b w i -{b\over w_i} −wib 是 x i x_i xi 轴上的截距。
-
D \mathbf{D} D 称为是线性可分的,如果存在 h ( x ) h(\mathbf{x}) h(x) 使得对所有 y i = 1 y_i=1 yi=1 的点 x i \mathbf{x}_i xi 有 h ( x i ) > 0 h(\mathbf{x}_i)>0 h(xi)>0 ,且对所有 y i = − 1 y_i=-1 yi=−1 的点 x i \mathbf{x}_i xi 有 h ( x i ) < 0 h(\mathbf{x}_i)<0 h(xi)<0 ,并将此 h ( x ) h(\mathbf{x}) h(x) 称为分离超平面。
Remark:对于线性可分的 D \mathbf{D} D ,分离超平面有无穷多个。
-
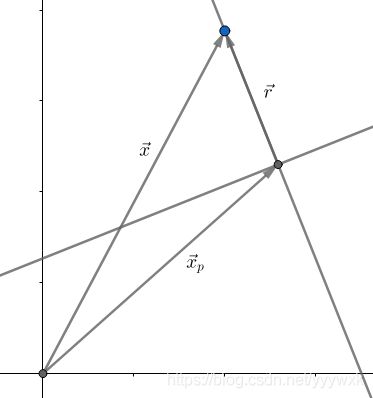
点到超平面的距离:
x = x p + x r = x p + r ⋅ w ∣ ∣ w ∣ ∣ h ( x ) = h ( x p + r w ∥ w ∥ ) = w T ( x p + r w ∥ w ∥ ) + b = w T x p + b ⏟ h ( x p ) + r w T w ∥ w ∥ = h ( x p ) ⏟ 0 + r ∥ w ∥ = r ∥ w ∥ \mathbf{x}=\mathbf{x}_p+\mathbf{x}_r=\mathbf{x}_p+r\cdot\frac{\mathbf{w}}{||\mathbf{w}||}\\ \begin{aligned} h(\mathbf{x}) &=h\left(\mathbf{x}_{p}+r \frac{\mathbf{w}}{\|\mathbf{w}\|}\right) \\ &=\mathbf{w}^{T}\left(\mathbf{x}_{p}+r \frac{\mathbf{w}}{\|\mathbf{w}\|}\right)+b \\ &=\underbrace{\mathbf{w}^{T}\mathbf{x}_{p}+b}_{h\left(\mathbf{x}_{p}\right)}+r \frac{\mathbf{w}^{T} \mathbf{w}}{\|\mathbf{w}\|}\\ &=\underbrace{h\left(\mathbf{x}_{p}\right)}_{0}+r\|\mathbf{w}\| \\ &=r\|\mathbf{w}\| \end{aligned} x=xp+xr=xp+r⋅∣∣w∣∣wh(x)=h(xp+r∥w∥w)=wT(xp+r∥w∥w)+b=h(xp) wTxp+b+r∥w∥wTw=0 h(xp)+r∥w∥=r∥w∥∴ r = h ( x ) ∥ w ∥ , ∣ r ∣ = ∣ h ( x ∣ ) ∥ w ∥ \therefore r=\frac{h(\mathbf{x})}{\|\mathbf{w}\|},|r|=\frac{|h(\mathbf{x}|)}{\|\mathbf{w}\|} ∴r=∥w∥h(x),∣r∣=∥w∥∣h(x∣)
故 ∀ x i ∈ D \forall \mathbf{x}_i \in \mathbf{D} ∀xi∈D 到 h ( x ) h(\mathbf{x}) h(x) 的距离是 y i h ( x i ) ∥ w ∥ y_i\frac{h(\mathbf{x}_i)}{\|\mathbf{w}\|} yi∥w∥h(xi)
-
给定线性可分的 D \mathbf{D} D ,及分离超平面 h ( x ) h(\mathbf{x}) h(x) ,定义余量:
δ ∗ = min x i { y i ( w T x i + b ) ∥ w ∥ } \delta^*=\min\limits_{\mathbf{x}_i}\{\frac{y_i(\mathbf{w}^T\mathbf{x}_i+b)}{\|\mathbf{w}\|} \} δ∗=ximin{∥w∥yi(wTxi+b)}
即 D \mathbf{D} D 中点到 h ( x ) h(\mathbf{x}) h(x) 距离的最小值,使得该 δ ∗ \delta^* δ∗ 取到的数据点 x i \mathbf{x}_i xi 被称为支撑向量(可能不唯一)。 -
标准超平面:对 ∀ h ( x ) = w T x + b \forall h(\mathbf{x})=\mathbf{w}^T\mathbf{x}+b ∀h(x)=wTx+b,以及任意 s ∈ R ∖ { 0 } s\in \mathbb{R}\setminus \{0\} s∈R∖{0}, s ( w T x + b ) = 0 s(\mathbf{w}^T\mathbf{x}+b)=0 s(wTx+b)=0 与 h ( x ) = 0 h(\mathbf{x})=0 h(x)=0 是同一超平面。
设 x ∗ \mathbf{x}^* x∗ 是支撑向量,若 s y ∗ ( w T x ∗ + b ) = 1 ( 1 ) sy^*(\mathbf{w}^T\mathbf{x}^*+b)=1\ (1) sy∗(wTx∗+b)=1 (1) ,则称 s h ( x ) = 0 sh(\mathbf{x})=0 sh(x)=0 是标准超平面。
由 ( 1 ) (1) (1) 可得: s = 1 y ∗ ( w T x ∗ + b ) = 1 y ∗ h ( x ∗ ) s=\frac{1}{y^*(\mathbf{w}^T\mathbf{x}^*+b)}=\frac{1}{y^*h(\mathbf{x}^*)} s=y∗(wTx∗+b)1=y∗h(x∗)1
此时,对于 s h ( x ) = 0 sh(\mathbf{x})=0 sh(x)=0 ,余量 δ ∗ = y ∗ h ( x ∗ ) ∥ w ∥ = 1 ∥ w ∥ \delta^*=\frac{y^*h(\mathbf{x}^*)}{\|\mathbf{w}\|}=\frac{1}{\|\mathbf{w}\|} δ∗=∥w∥y∗h(x∗)=∥w∥1
事实:如果 w T x + b = 0 \mathbf{w}^T\mathbf{x}+b=0 wTx+b=0 是标准超平面,对 ∀ x i \forall \mathbf{x}_i ∀xi ,一定有 y i ( w T x i + b ) ≥ 1 y_i(\mathbf{w}^T\mathbf{x}_i+b)\ge1 yi(wTxi+b)≥1
21.2 SVM: 线性可分情形
目标:寻找标准分离超平面使得其余量最大,即 h ∗ = arg max w , b { 1 w } h^*=\arg\max\limits_{\mathbf{w},b}\{\frac{1}{\mathbf{w}} \} h∗=argw,bmax{w1}
转为优化问题:
min w , b { ∥ w ∥ 2 2 } s.t. y i ( w T x i + b ) ≥ 1 , ∀ ( x i , y i ) ∈ D \begin{aligned} &\min\limits_{\mathbf{w},b}\ \{\frac{\|\mathbf{w}\|^2}{2} \}\\ &\text{s.t.} \ y_i(\mathbf{w}^T\mathbf{x}_i+b)\ge1,\forall(\mathbf{x}_i,y_i)\in \mathbf{D} \end{aligned} w,bmin {2∥w∥2}s.t. yi(wTxi+b)≥1,∀(xi,yi)∈D
引入 Lagrange 乘子 α i ≥ 0 \alpha_i\ge0 αi≥0 与 KKT 条件:
α i ( y i ( w T x i + b ) − 1 ) = 0 \alpha_i(y_i(\mathbf{w}^T\mathbf{x}_i+b)-1)=0 αi(yi(wTxi+b)−1)=0
定义:
L ( w ) = 1 2 ∥ w ∥ 2 − ∑ i = 1 n α i ( y i ( w T x i + b ) − 1 ) ( 2 ) L(\mathbf{w})=\frac{1}{2}\|\mathbf{w}\|^2-\sum\limits_{i=1}^{n}\alpha_i(y_i(\mathbf{w}^T\mathbf{x}_i+b)-1)\ (2) L(w)=21∥w∥2−i=1∑nαi(yi(wTxi+b)−1) (2)
∂ ∂ w L = w − ∑ i = 1 n α i y i x i = 0 ( 3 ) ∂ ∂ b L = ∑ i = 1 n α i y i = 0 ( 4 ) \begin{array}{l} \frac{\partial}{\partial \mathbf{w}} L=\mathbf{w}-\sum\limits_{i=1}^{n} \alpha_{i} y_{i} \mathbf{x}_{i}=\mathbf{0}\ (3) \\ \frac{\partial}{\partial b} L=\sum\limits_{i=1}^{n} \alpha_{i} y_{i}=0\ (4) \end{array} ∂w∂L=w−i=1∑nαiyixi=0 (3)∂b∂L=i=1∑nαiyi=0 (4)
将 (3)(4) 代入 (2) 得:
L d u a l = 1 2 w T w − w T ( ∑ i = 1 n α i y i x i ⏟ w ) − b ∑ i = 1 n α i y i ⏟ 0 + ∑ i = 1 n α i = − 1 2 w T w + ∑ i = 1 n α i = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j \begin{aligned} L_{d u a l} &=\frac{1}{2} \mathbf{w}^{T} \mathbf{w}-\mathbf{w}^{T}(\underbrace{\sum_{i=1}^{n} \alpha_{i} y_{i} \mathbf{x}_{i}}_{\mathbf{w}})-b\underbrace{ \sum_{i=1}^{n} \alpha_{i} y_{i}}_{0}+\sum_{i=1}^{n} \alpha_{i}\\ &=-\frac{1}{2} \mathbf{w}^{T} \mathbf{w}+\sum_{i=1}^{n} \alpha_{i}\\ &=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} \mathbf{x}_{i}^{T} \mathbf{x}_{j} \end{aligned} Ldual=21wTw−wT(w i=1∑nαiyixi)−b0 i=1∑nαiyi+i=1∑nαi=−21wTw+i=1∑nαi=i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxj
故对偶问题为:
max α L d u a l = ∑ i = 1 n α i − 1 2 ∑ i = 1 n ∑ j = 1 n α i α j y i y j x i T x j s.t. ∑ i = 1 n α i y i = 0 , α i ≥ 0 , ∀ i \begin{aligned} &\max\limits_{\alpha} L_{dual}=\sum_{i=1}^{n} \alpha_{i}-\frac{1}{2} \sum_{i=1}^{n} \sum_{j=1}^{n} \alpha_{i} \alpha_{j} y_{i} y_{j} \mathbf{x}_{i}^{T} \mathbf{x}_{j}\\ &\text{s.t.}\ \sum\limits_{i=1}^{n} \alpha_{i} y_{i}=0,\alpha_i \ge0, \forall i \end{aligned} αmaxLdual=i=1∑nαi−21i=1∑nj=1∑nαiαjyiyjxiTxjs.t. i=1∑nαiyi=0,αi≥0,∀i
利用二次规划解出 Dual: α 1 , ⋯ , α n \alpha_1,\cdots,\alpha_n α1,⋯,αn
代入 (3) 可得: w = ∑ i = 1 n α i y i x i \mathbf{w}=\sum\limits_{i=1}^{n} \alpha_{i} y_{i} \mathbf{x}_{i} w=i=1∑nαiyixi
使得 α i > 0 \alpha_i>0 αi>0 的数据 x i \mathbf{x}_i xi 给出支撑向量。
对于每一个支撑向量: y i ( w T x i + b ) − 1 ⇒ b = 1 y i − w T x i y_i(\mathbf{w}^T\mathbf{x}_i+b)-1\Rightarrow b=\frac{1}{y_i}-\mathbf{w}^T\mathbf{x}_i yi(wTxi+b)−1⇒b=yi1−wTxi
取 b = a v g α i > 0 { b i } b=\mathop{avg}_{\alpha_i>0}\{b_i\} b=avgαi>0{bi}