二元逻辑回归 · 数学推导过程及代码实现完全解析
文章目录
- 概述
-
- 两个重要函数
- 预测的基本思想
- 二元逻辑回归
-
- 线性模型的简单回顾
- 从线性回归到二元逻辑回归
- 参数怎么估计
- 梯度下降
- 牛顿迭代
最近修改:2021/6/17
原文《从二元逻辑回归到多元逻辑回归 · 推导过程完全解析》经过多次修改后变得越来越长,因此笔者将其分为两部分:
第一部分:二元逻辑回归 · 数学推导过程及代码实现完全解析
第二部分:多元逻辑回归 · 数学推导过程及代码实现完全解析
概述
以下是此篇文章要用的包
# 加载包
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
sns.set_style('darkgrid')
两个重要函数
二元逻辑回归的出发点是sigmoid函数
S ( x ) = 1 1 + e − x = e x 1 + e x S(x)= \frac{1}{1+e^{-x}}= \frac{e^{x}}{1+e^{x}} S(x)=1+e−x1=1+exex
Sigmoid函数能将实数域的连续数映射到0,1区间,概率的取值范围就在0,1之间,因此可以用来做概率的预测。
以下是Sigmoid函数的代码和图像
x=np.arange(-10,10)
y=1/(1+np.exp(-x))
plt.plot(x,y)
Output:

多元逻辑回归的出发点是softmax函数
S ( x ) = e x i ∑ j = 1 k e x j S(x)=\frac{e^{x_i}}{\sum_{j=1}^{k}e^{x_j}} S(x)=∑j=1kexjexi
Softmax函数也是将实数域的连续数映射到0,1区间,进而可以理解为是概率。
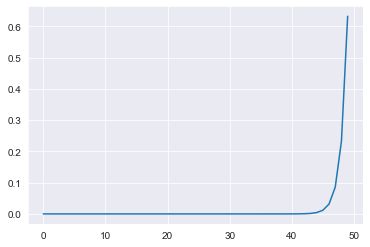
以下是softmax函数的代码和图像
图像的特点:
- 设向量x=[0,1,2,3,…,49],其输出也是一个向量y
- 这里Softmax函数会将x里的每个数映射到0,1区间
- 并且y里元素加和为一
- 数越大,其输出也越大,即概率越大。
x=np.arange(0,50)
y=np.exp(x)/np.sum(np.exp(x))
plt.plot(x,y)
print('the sum of y={}'.format(y.sum()))
Output:
the sum of y=1.0
预测的基本思想
我们想处理分类问题,最基本的统计模型便是逻辑回归,之所以使用它,最主要的原因是其输出是在0,1之间。
注意,我们并不是直接输出类别编号,而是一个概率值
然后我们会根据情况的不同来确定一个阈值,通常这个阈值定在0.5。比如,二元模型中(类别0和1),我的输出是P(Y=1)=0.75(0.75>0.5),则认为此时Y是属于类别1的。
二元逻辑回归
线性模型的简单回顾
要解释二元逻辑回归,我们得先来了解下什么是线性模型
首先这个模型建立在两个个假设上
- 假设 y y y和 X X X之间是一个线性关系
- y i ( i = 1 , 2 , 3 , . . . , n ) y_i(i=1,2,3,...,n) yi(i=1,2,3,...,n)是独立同分布
y y y和 X X X之间的线性关系
y = X β y=Xβ y=Xβ
因变量 y y y是一个nx1向量
y = [ y 1 y 2 ⋮ y n ] y= \left[ \begin{matrix} y_1 \\ y_2 \\ \vdots\\ y_n \end{matrix} \right] y=⎣⎢⎢⎢⎡y1y2⋮yn⎦⎥⎥⎥⎤
带截距项的自变量 X X X是一个nx(m+1)的矩阵
X = [ 1 x 11 x 12 . . . x 1 m 1 x 21 x 21 . . . x 2 m ⋮ ⋮ ⋮ 1 x n 1 x n 2 . . . x n m ] X= \left[ \begin{matrix} 1&x_{11}&x_{12}&...&x_{1m}\\ 1&x_{21}&x_{21}&...&x_{2m}\\ \vdots&\vdots&&\vdots\\ 1&x_{n1}&x_{n2}&...&x_{nm} \end{matrix} \right] X=⎣⎢⎢⎢⎡11⋮1x11x21⋮xn1x12x21xn2......⋮...x1mx2mxnm⎦⎥⎥⎥⎤
带截距项的参数 β β β是一个mx1向量
β = [ β 0 β 1 β 2 ⋮ β m ] β= \left[ \begin{matrix} β_0 \\ β_1 \\ β_2 \\ \vdots\\ β_m \end{matrix} \right] β=⎣⎢⎢⎢⎢⎢⎡β0β1β2⋮βm⎦⎥⎥⎥⎥⎥⎤
从线性回归到二元逻辑回归
对于二值因变量 y i y_i yi( y i = 0 y_i=0 yi=0或 y i = 1 y_i=1 yi=1),我们的假设是 y i ( i = 1 , 2 , . . . , n ) y_i(i=1,2,...,n) yi(i=1,2,...,n) 独立同分布Bernouli分布,即
y i ∼ B e r n o u l i ( P ( y i = 1 ) ) y_i\sim Bernouli (P(y_i=1)) yi∼Bernouli(P(yi=1))
首先我们想到用最基本的线性回归来估计 y i y_i yi,在Bernouli分布中, y i y_i yi的均值是 P ( y i = 1 ) P(y_i= 1) P(yi=1),因此我们的预测模型为
E ( y i ) = P ( y i = 1 ) = x i β E(y_i) = P(y_i= 1) =x_iβ E(yi)=P(yi=1)=xiβ
但这样做的缺点就是 x i β x_iβ xiβ的取值可能会落在[0,1]之外,受Sigmoid函数的启发,我们将预测模型改成
E ( y i ) = P ( y i = 1 ) = 1 1 + e − x i β E(y_i) = P(y_i = 1) =\frac{1}{1+e^{-x_iβ}} E(yi)=P(yi=1)=1+e−xiβ1
β = ( β 0 , β 1 , … β m ) ′ , 且 x i = ( 1 , x i 1 , x i 2 , … , x i m ) , 即 x i β = β 0 + x i 1 β 1 + . . . + x i m β m β = (β_0, β_1, … β_m)',且 x_i= (1, x_{i1}, x_{i2}, … ,x_{im}),即x_iβ=β_0+x_{i1}β_1+...+x_{im}β_m β=(β0,β1,…βm)′,且xi=(1,xi1,xi2,…,xim),即xiβ=β0+xi1β1+...+ximβm
参数怎么估计
前面知道 Y i Y_i Yi 服从Bernouli分布,既然分布已知了,我们自然会想到用极大似然估计的方法去估计参数,此时的似然函数是
L ( β ) = f ( y 1 , y 2 , . . , y n ) = ∏ j = 1 n p i y j ( 1 − p i ) 1 − y i = ∏ j = 1 n ( p i 1 − p i ) y i ( 1 − p i ) L(β)=f(y_1,y_2,..,y_n)=\prod_{j=1}^np_i^{y_j}(1-p_i)^{1-y_i}=\prod_{j=1}^n(\frac{p_i}{1-p_i})^{y_i}(1-p_i) L(β)=f(y1,y2,..,yn)=j=1∏npiyj(1−pi)1−yi=j=1∏n(1−pipi)yi(1−pi)
其中 p i = P ( Y i = 1 ) = 1 1 + e − x i β p_i=P(Y_i = 1)=\frac{1}{1+e^{-x_iβ}} pi=P(Yi=1)=1+e−xiβ1,又发现这样的关系 L o g p i 1 − p i = x i β Log\frac{p_i}{1-p_i}=x_iβ Log1−pipi=xiβ,为了之后计算方便,先对上式两边取对数得到
L o g L ( β ) = L o g f ( y 1 , y 2 , . . , y n ) = ∑ j = 1 n y j ( L o g p i ) + ( 1 − y j ) ( L o g ( 1 − p i ) ) (1) LogL(β)=Logf(y_1,y_2,..,y_n)=\sum_{j=1}^n y_j(Logp_i)+(1-y_j)(Log(1-p_i))\tag1 LogL(β)=Logf(y1,y2,..,yn)=j=1∑nyj(Logpi)+(1−yj)(Log(1−pi))(1) = ∑ j = 1 n y j L o g p i 1 − p i + L o g ( 1 − p i ) = ∑ j = 1 n y j x i β − L o g ( 1 + e x i β ) (2) =\sum_{j=1}^ny_jLog\frac{p_i}{1-p_i}+Log(1-p_i)=\sum_{j=1}^ny_jx_iβ-Log(1+e^{x_iβ})\tag2 =j=1∑nyjLog1−pipi+Log(1−pi)=j=1∑nyjxiβ−Log(1+exiβ)(2)
最大化这个似然函数,并取此时满足情况的 β β β作为参数的估计值 β ^ \widehat{β} β ,就能得到预测模型 E ( Y i ) = P ( Y i = 1 ) = 1 1 + e − x i β ^ E(Y_i) = P(Y_i= 1) =\frac{1}{1+e^{-x_i\widehatβ}} E(Yi)=P(Yi=1)=1+e−xiβ 1了,而为什么要最大化这个似然函数呢,也就是极大似然估计的意义在哪?
- 因为我们的假设是 Y i Y_i Yi独立同分布,这里的似然函数实质就是 Y i ( i = 1 , 2 , . . . , n ) Y_i(i=1,2,...,n) Yi(i=1,2,...,n)的联合密度函数,当联合密度函数最大的时候,也就是概率最大的时候,事件最可能发生的时候,所以我们会想去最大化似然函数。
我想大部分读者都是对机器学习感兴趣来的,那这我们用一个机器学习里的名词,代价函数(Cost function),来进行接下来的步骤,把(1)式做个小小修改就变成了,大家熟悉的代价函数
C o s t ( β ) = − 1 n ∑ j = 1 n y j ( L o g p i ) + ( 1 − y j ) ( L o g ( 1 − p i ) ) (3) Cost(β)=-\frac{1}{n}\sum_{j=1}^n y_j(Logp_i)+(1-y_j)(Log(1-p_i))\tag3 Cost(β)=−n1j=1∑nyj(Logpi)+(1−yj)(Log(1−pi))(3)
其实质就是将似然函数的对数函数做了一个平均,最大化似然函数的对数函数,也就是最小化这个代价函数
如果想要更严格地估计,我们还可以在这个基础上,再添加惩罚项(Penalty),这个步骤也叫正则化(Regularization),常见的惩罚项是一范数和二范数,也分别叫做Lasso和Ridge,叫啥都无所谓,实质都是数学。
C o s t L 1 ( β ) = C o s t ( β ) + λ n ∑ j = 1 m ∣ β j ∣ C o s t L 2 ( β ) = C o s t ( β ) + λ 2 n ∑ j = 1 m β j 2 Cost_{L_1}(β)=Cost(β)+\frac{λ}{n}\sum_{j=1}^m|β_j|\\ Cost_{L_2}(β)=Cost(β)+\frac{λ}{2n}\sum_{j=1}^mβ_j^2 CostL1(β)=Cost(β)+nλj=1∑m∣βj∣CostL2(β)=Cost(β)+2nλj=1∑mβj2
明白了这层关系后,进一步的问题就在于如何最小化代价函数,并且得到其对应的参数 β β β
求参数 β β β的方法常用的有两个,一个是梯度下降(Gradient descent),另一个是牛顿迭代(Newton’s Iteration)。
梯度下降
对(3)式里的代价函数求导,而(3)式就是把(2)式做了一个变换 − ( 2 ) n -\frac{(2)}{n} −n(2),因此
∂ C o s t ( β ) ∂ β = − 1 n ∂ ( 2 ) ∂ β = − 1 n ∑ j = 1 n x i ( y j − p i ) \frac{\partial Cost(β)}{\partial β}=-\frac{1}{n}\frac{\partial (2)}{\partial β}=-\frac{1}{n}\sum_{j=1}^nx_i(y_j-p_i) ∂β∂Cost(β)=−n1∂β∂(2)=−n1j=1∑nxi(yj−pi)
和之前一样,这里 p i = P ( Y i = 1 ) = 1 1 + e − x i β p_i=P(Y_i = 1)=\frac{1}{1+e^{-x_iβ}} pi=P(Yi=1)=1+e−xiβ1
x i x_i xi和 y j y_j yj都是已知,给定初值 β ( 0 ) = [ β 0 ( 0 ) , β 1 ( 0 ) , β 2 ( 0 ) , . . . , β m ( 0 ) ] ′ β^{(0)}=[β_0^{(0)},β_1^{(0)},β_2^{(0)},...,β_m^{(0)}]' β(0)=[β0(0),β1(0),β2(0),...,βm(0)]′后,得到 p i ( 0 ) p_i^{(0)} pi(0),因此参数 β m ( 0 ) β_m^{(0)} βm(0)的更新可以写成
β m ( t ) = β m ( t − 1 ) − l ⋅ ∂ C o s t ( β ( t − 1 ) ) ∂ β ( t − 1 ) = β m ( t − 1 ) − l ⋅ 1 n ∑ j = 1 n x i ( y j − p i ( t − 1 ) ) (4) β_m^{(t)}=β_m^{(t-1)} - l·\frac{\partial Cost(β^{(t-1)})}{\partial β^{(t-1)}}\\ =β_m^{(t-1)} - l·\frac{1}{n}\sum_{j=1}^nx_i(y_j-p_i^{(t-1)})\tag4 βm(t)=βm(t−1)−l⋅∂β(t−1)∂Cost(β(t−1))=βm(t−1)−l⋅n1j=1∑nxi(yj−pi(t−1))(4)
写成矩阵的形式
β ( t ) = β ( t − 1 ) − l ⋅ 1 n ⋅ X T ⋅ ( y − p ) β^{(t)}=β^{(t-1)}-l·\frac{1}{n}·X^T·(y-p) β(t)=β(t−1)−l⋅n1⋅XT⋅(y−p)
其中 l l l是学习速度(learning rate), X X X是nx(m+1)的矩阵, y y y是nx1的向量, p p p是nx1的向量( p = [ p 1 , p 2 , . . . , p n ] ′ p=[p_1,p_2,...,p_n]' p=[p1,p2,...,pn]′),在实际的操作中,我们会多次取不同的初值,由此希望达到全局最小值。
以下是梯度下降的简单实现,其中省略了计算 p p p的函数
def update_bata(X, y, beta, l):
'''
X: 自变量是一个(n,m+1)的矩阵
y: 因变量是一个(n,1)的向量
beta: 参数β是一个(m+1,1)的向量
l: 学习速率
'''
n = len(y)
#1 由(4)的算式得到p,设函数名为cal_p
p= cal_p(X, beta)
#2 (4)的一部分
gradient = np.dot(X.T, y-p)
#3 Take the average cost derivative for each feature
gradient /= N
#4 - Multiply the gradient by our learning rate
gradient *= l
#5 - Subtract from our weights to minimize cost
beta -= gradient
return beta
牛顿迭代
可以说这个方法是从泰勒展开得到的灵感, f ( x ) f(x) f(x)在 x k x_k xk处的展开式 f ( x ) = f ( x k ) + f ′ ( x k ) ( x − x k ) + 1 2 ! f ′ ′ ( x k ) ( x − x k ) 2 + . . . f(x)=f(x_k)+f'(x_k)(x-x_k)+\frac{1}{2!}f''(x_k)(x-x_k)^2+... f(x)=f(xk)+f′(xk)(x−xk)+2!1f′′(xk)(x−xk)2+...,我们想寻找满足 f ( x ) = 0 f(x)=0 f(x)=0的 x x x,即牛顿迭代的终点是 f ( x ) f(x) f(x)收敛到0
在这我们只取前两项, h ( x ) = f ( x k ) + f ′ ( x k ) ( x − x k ) h(x)=f(x_k)+f'(x_k)(x-x_k) h(x)=f(xk)+f′(xk)(x−xk),我们认为 h ( x ) h(x) h(x)是 f ( x ) f(x) f(x)的一个近似,那么有 f ( x ) = h ( x ) = 0 f(x)=h(x)=0 f(x)=h(x)=0,得到
x = x k − f ( x k ) f ′ ( x k ) x=x_k-\frac{f(x_k)}{f'(x_k)} x=xk−f′(xk)f(xk)
进而有迭代
x k + 1 = x k − f ( x k ) f ′ ( x k ) x_{k+1}=x_k-\frac{f(x_k)}{f'(x_k)} xk+1=xk−f′(xk)f(xk)
在我们的二元逻辑回归中,代价函数就是这里的 f ( x ) f(x) f(x),参数 β β β更新方法是
β ( k ) = β ( k − 1 ) − c o s t ( β ( k − 1 ) ) c o s t ′ ( β ( k − 1 ) ) β^{(k)}=β^{(k-1)}-\frac{cost(β^{(k-1)})}{cost'(β^{(k-1)})} β(k)=β(k−1)−cost′(β(k−1))cost(β(k−1))
直至代价函数趋近于0。这里做一个区分,梯度下降方法中的代价函数不一定趋近于0。
以上就是全部内容了,笔者从统计的角度大致解释了下机器学习中逻辑回归损失函数的来源,希望能帮助到各位读者