端对端的机器学习项目
机器学习实战
- 机器学习的基础知识(已完成)
- 端对端的机器学习项目(已完成)
- 训练深度神经网络
- 使用TensorFlow自定义模型和训练
- 使用TensorFlow加载和预处理数据
- 使用卷积神经网络的深度计算机视觉
- 使用RNN和CNN处理序列
- 使用RNN和注意力机制进行自然语言处理
- 使用自动编码器和GAN的表征学习和生成学习
- 强化学习
- 大规模训练和部署TensorFlow模型
文章目录
- 机器学习实战
- 前言
- 一、真实的数据来源
- 二、观察大局
-
- 1.框架问题
- 2.选择性能指标
- 3.检查假设
- 三、获取数据
-
- 1.创建工作区
- 2.下载数据
- 3.快速查看数据结构
- 4.创建测试集
- 四、数据探索和可视化
-
- 1.将地理数据可视化
- 2.寻找相关性
- 3.试验不同属性的组合
- 五、机器学习算法的数据准备
-
- 1.数据清理
- 2.处理文本和分类属性
- 3.自定义转换器
- 4.特征缩放
- 5.转换流水线
- 六、选择和训练模型
-
- 1.训练和评估数据集
- 2.使用交叉验证来更好地进行评估
- 七、微调模型
-
- 1、网格搜索
- 2、随机搜索
- 3、集成方法
- 4、分析最佳模型机器误差
- 5、通过测试集评估系统
- 八. 启动、监控和维护你的系统
- 练习题
前言
这一章的背景是基于房地产公司的数据,主要步骤:
- 观察大局
- 获得数据
- 从数据探索和可视化中获得洞见
- 机器学习算法的数据准备
- 选择并训练模型
- 微调模型
- 展示解决方案
- 启动、监控和维护系统
一、真实的数据来源
流行的开放数据存储库:
UC Irvine Machine Learning Repository
Kaggle datasets
Amazon’s AWS datasets
元门户站点(它们会列出开放的数据存储库):
Data Portals
OpenDataMonitor
Quandl
其他一些列出许多流行的开放数据存储库的页面:
Wikipedia’s list of Machine Learning datasets
Quora.com
The datasets subreddit
从StaLib库中选择了加州住房的数据集。
二、观察大局
要做的第一件事是使用加州人口普查的数据建立起加州的房价模型。数据中有许多指标,诸如每个街区的人口数量、收入中位数、房价中位数等。街区是美国人口普查局发布样本数据的最小地理单位(一个街区通常人口数为600到3000人)。这里,我们将其简称为“区域”
我所建立的模型需要从这个数据中学习,从而能够根据所有其他指标,预测任意区域的房价中位数。
可以通过机器学习项目清单做一整个项目,它适合绝大多数机器学习项目。
机器学习项目清单:
- 框出问题并看整体
- 获取数据
- 研究数据以获得深刻见解
- 准备数据以便更好地将潜在地数据模式提供给机器学习算法
- 探索许多不同的模型
- 微调模型,并将它们组合成一个很好的解决方案
- 演示你的解决方案
- 启动、监视和维护你的系统
1.框架问题
需要明确业务目标是什么,因为建立模型本身可能不是最终的目标。公司期望知道如何使用这个模型,如何从中获益?这才是最重要的问题,决定了怎么设定问题、选择什么算法、使用什么测量方式来评估模型的性能,以及应该花多少精力来调整。
如果答案是,这个模型的输出(对一个区域房价中位数的预测)将会跟其他许多信号一起被传输给另一个机器学习系统。而这个下游系统将被用来决策一个给定的区域是否值得投资。因为直接影响到收益,所以正确获得这个信息至关重要。
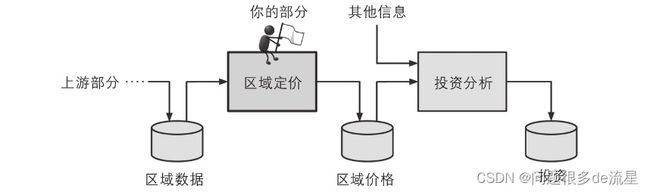
以上的图为一个机器学习流水线。一个序列的数据处理组件称为一个数据流水线。
要向老板询问的第二个问题是当前的解决方案(如果有的话)。你可以将其当作参考,也能从中获得解决问题的洞察。老板回答说,现在是由专家团队在手动估算区域的住房价格:一个团队持续收集最新的区域信息,当他们不能得到房价中位数时,便使用复杂的规则来进行估算。但这个过程的估算结果不令人满意,他们估计的房价和实际房价的偏差高达20%。这就是该公司认为给定该区域的其他数据有助于训练模型来预测该区域的房价中位数。
再解决了以上的问题后,开始设计系统。首先,先回答框架问题:是有监督学习、无监督学习还是强化学习?是分类任务、回归任务还是其他任务?应该使用批量学习还是在线学习技术?(我的回答:有监督学习、回归任务、批量学习技术)
我的回答是正确的。
2.选择性能指标
回归问题的典型性能指标是均方根误差(RMSE)。

RMSE通常是回归任务的首选性能指标。
但在某些情况下,可以考虑使用平均绝对误差(Mean Absolute Error,MAE,也称为平均绝对误差)

h是系统的预测函数,也称为假设。我感觉这都是比较好懂的。
3.检查假设
列举和验证到目前为止做出的假设。需要跟下游系统沟通证实需要的到底是分类还是回归。
三、获取数据
开始编程。
1.创建工作区
需要为机器学习的代码和数据集创建一个工作区目录。书上直接在python上建立一个工作区我用pycharm新建一个项目,安装Jupyter、NumPy、pandas、Matplotlib以及ScikitLearn。
2.下载数据
只需要下载一个压缩文件housing.tgz即可,这个文件以及包含所有的数据——一个以逗号来分隔值的CSV文档housing.csv。
①可以使用浏览器下载压缩包,运行tar xzf housing.tgz来解压缩并提取CSV文件
②创建一个小函数来实现它
这个函数非常有用:你可以编写一个小脚本,在需要获取最新数据时直接运行(或者也可以设置一个定期自动运行的计划任务)。
获取数据的函数如下:
import os
import tarfile
import urllib
import urllib.request
DOWNLOAD_ROOT = "https://raw.githubusercontent.com/ageron/handson-ml2/master/"
HOUSING_PATH = os.path.join("datasets", "housing") #把目录和文件名合成一个路径
HOUSING_URL = DOWNLOAD_ROOT + "datasets/housing/housing.tgz"
def fetch_housing_data(housing_url=HOUSING_URL,housing_path=HOUSING_PATH):
if not os.path.isdir(housing_path): #判断路径是否为目录
os.makedirs(housing_path,exist_ok=True) #创建目录
tgz_path = os.path.join(housing_path,"housing.tgz")
urllib.request.urlretrieve(housing_url,tgz_path) #将URL检索到磁盘上的临时位置
housing_tgz = tarfile.open(tgz_path) #打开
housing_tgz.extractall(path=housing_path) #解压
housing_tgz.close() #关闭
fetch_housing_data()
现在调用fetch_housing_data(),就会自动在工作区中创建一个datasets/housing目录,然后下载housing.tgz文件,并将housing.csv解压到这个目录。

现在可以用pandas加载数据。写一个小函数来加载数据,这个函数会返回一个包含所有数据的pandas DataFrame对象。
import pandas as pd
def load_housing_data(housing_path = HOUSING_PATH):
csv_path = os.path.join(housing_path,"housing.csv")
return pd.read_csv(csv_path)
housing = load_housing_data()
print(housing)
需要联网比较慢,可以输出housing的值

3.快速查看数据结构
每一行代表一个区域,总共有10个属性,调用info()函数查看具体的十个属性
print(housing.info())
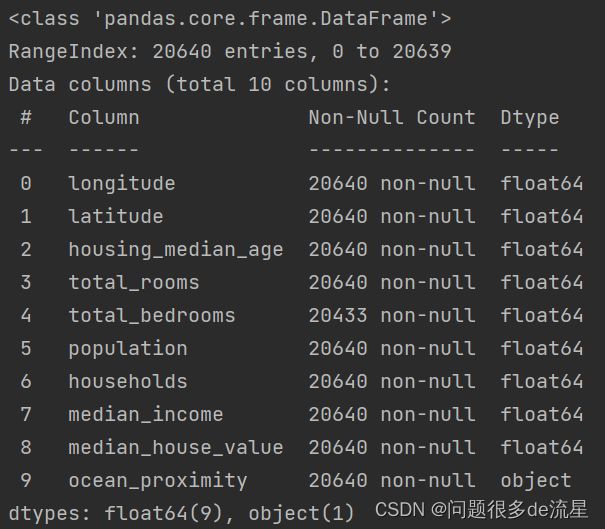
数据集中包含20640个实例,以机器学习的标准来看,这个数字非常小,但却是个完美的开始。total_bedrooms这个属性只有20433个非空值,这意味着有207个区域缺失这个特征。我们后面需要考虑这一点。
除了ocean_proximity的类型是object,其他都是数字。
通过对前面的数据进行分析,ocean_proximity似乎被分成了两种:INLAND和NEAR BY。它可能是一个分类属性。
可以通过values_count()方法查看有多少种分类存在,每种分类下分别由多少个区域:
print(housing["ocean_proximity"].value_counts())

可以分成四类:INLAND、NEAR OCEAN、NEAR BAY、ISLAND
再看看其他区域,通过describe()方法可以显示数值属性的摘要。
print(housing.describe())
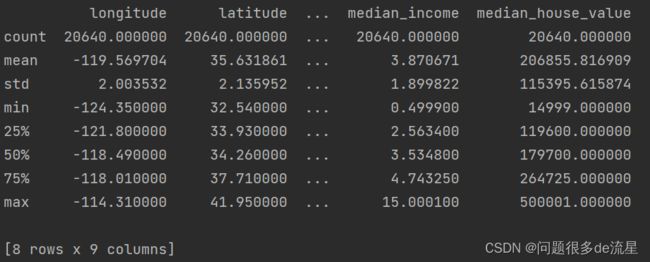
std代表标准差(用来测量数值的离散程度),25%、50%和75%行显示相应的百分位数:表示一组观测值中给定百分比的观测值都低于该值。例如,对于longitude这一个属性,25%的数据小于-121.8
另一种快速了解数据类型的方法是绘制每个数值属性的直方图。直方图用来显示给定值范围(横轴)的实例数量(纵轴)。你可以一次绘制一个属性,也可以在整个数据集上调用hist()方法,绘制每个属性的直方图
import matplotlib.pyplot as plt
housing = load_housing_data()
housing.hist(bins=50,figsize=(20,15)) #直方图
plt.show()

4.创建测试集
纯随机抽样方法:
理论上,创建测试集非常简单,只需要随机选择一些实例,通常是数据集的20%(如果数据集大,比例将更小),然后把它们放在一边。
import numpy as np
def split_train_test(data,test_ratio):
shffled_indices = np.random.permutation(len(data)) #对一个长度为len(data)的list(0,1,2,3……)随机排序
test_set_size = int(len(data)*test_ratio) #测试集的数据量
test_indices = shffled_indices[:test_set_size] #一个切片,取出随机排序后的前test_set_size(不包含)个数据
train_indices = shffled_indices[test_set_size:] #切片,从test_set_size(包含)开始
return data.iloc[train_indices],data.iloc[test_indices] #返回索引为train_indices和test_indices的数组
train_set,test_set = split_train_test(housing,0.2)
print(len(train_set))
print(len(test_set))

如果再运行一边,它又会产生一个不同的数据集!
有两种解决办法:第一个是再第一次运行程序后保存测试集,随后的运行只是加载它而已。另一种方法是调用np.random.permutation()之前设置一个随机数生成器的种子(例如,np.random.seed(42)),从而让它始终生成相同的随机索引。
eg.保存测试集
train_set, test_set = split_train_test(housing, 0.2)
train_set.to_csv("datasets/training/train_set.csv")
test_set.to_csv("datasets/training/test_set.csv")
但是这两种解决方案在下一次获取更新的数据时都会中断。为了即使在更新数据集之后也有一个稳定的训练测试分割,常见的解决方案是每个实例都使用一个标识符来决定是否进入测试集(假定每个实例都有一个唯一且不变的标识符)。如果,你可以计算每个实例标识符的哈希值,如果这个哈希值小于或等于最大哈希值的20%,则将该实例放入测试集。这样可以确保测试集在多个运行里都是一致的,即便更新数据集也仍然一致。新实例的20%将被放入新的测试集,而之前训练集中的实例也不会被放入新测试集。
实现方式如下:(说实话,我也没看懂,我觉得就会用吧。。。理解一下入口参数的含义,一个是数据,测试集比例,最后一个是标识符那一列的索引)
from zlib import crc32
def test_set_check(identifier,test_ratio):
return crc32(np.int64(identifier))&0xffffffff<test_ratio*2**32
def split_train_test_by_id(data,test_ratio,id_column):
ids = data[id_column]
in_test_set = ids.apply(lambda id_:test_set_check(id_,test_ratio))
return data.loc[~in_test_set],data.loc[in_test_set]
但是,housing数据集没有标识符列。最简单的解决方法就是使用行索引作为ID:
housing_with_id = housing.reset_index()
train_set,test_set = split_train_test_by_id(housing_with_id,0.2,"index")
如果行索引作为唯一标识符,你需要确保在数据集的末尾添加新数据,并且不会删除任何行,但如果确保不了,可以尝试用某个最稳定的特征来创建唯一标识符。
例如,一个区域的经纬度肯定几百万年都不会变,将它们组合成如下的ID
housing_with_id = housing.reset_index()
housing_with_id["id"]=housing["longitude"]*1000+housing["latitude"]
train_set,test_set = split_train_test_by_id(housing_with_id,0.2,"id")
Scikit-Learn提供了一些函数,可以通过多种方式将数据集分成多个子集。最简单的函数是train_test_split(),它与前面定义的函数split_train_test几乎相同,除了几个额外特征。首先,它也有random_state参数,让你可以像之前提过的那样设置随机生成器种子;其次,可以把行数相同的多个数据集一次性发送给它,它会根据相同的索引将其拆分。
from sklearn.model_selection import train_test_split
train_set,test_set = train_test_split(housing,test_size=0.2,random_state=42)
分层抽样
如果数据集足够庞大,纯随机抽样方法通常不错;如果不是,则有可能会导致明显的抽样偏差。如果数据集小,则要抽样确保样本能够代表全体数据。所以需要进行分层抽样:将人口划分为均匀的子集,每个子集称为一层,然后从每层抽取正确的实例数量,以确保测试集合代表了总的人口比例。
要预测房价中位数,收入中位数是一个非常重要的属性。所以希望测试集能够代表整个数据集中各种不同类型的收入。由于收入中位数是一个连续的数值属性,所以你得先创建一个收入类别的属性。
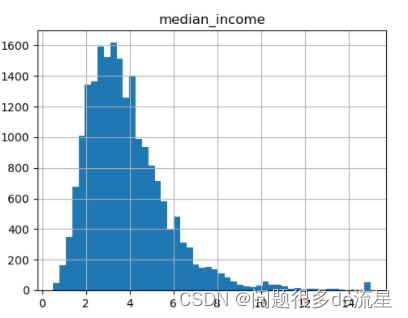
先看一下收入中位数的直方图:大多数收入中位数值聚集在(1.5~ 6)左右,但也有一部分远远超过了6万美元。在数据集中,每一层都有足够数量的实例,这一点很重要。所以,不应该把层数分得太多,每一层应该足够大。下面这段代码用np.cut()来创建5个收入类别属性的(用1~5做标签),0 ~ 1是类别1,1.5 ~ 3是类别2,以此类推
housing["income_cat"] = pd.cut(housing["median_income"],bins=[0.,1.5,3.0,4.5,6.,np.inf],labels=[1,2,3,4,5])
housing["income_cat"].hist()
plt.show()
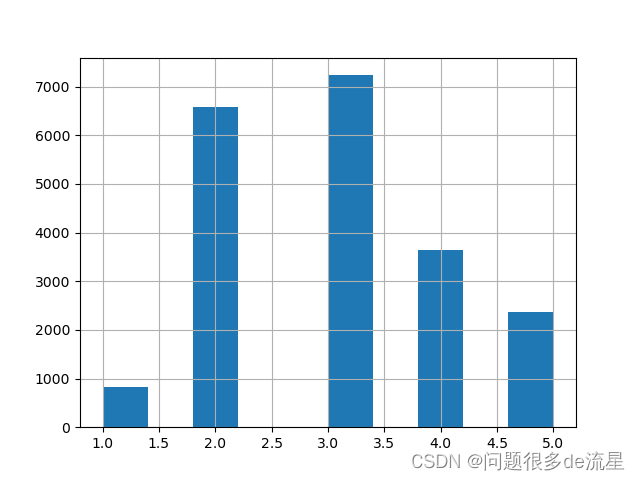
通过这个直方图可以看到我们的分类。
现在可以根据收入类别进行分层抽样。使用Scikit-learn的StratifiedShuffleSplit类:
from sklearn.model_selection import StratifiedShuffleSplit
housing["income_cat"] = pd.cut(housing["median_income"],bins=[0.,1.5,3.0,4.5,6.,np.inf],labels=[1,2,3,4,5])
housing["income_cat"].hist()
split = StratifiedShuffleSplit(n_splits=1,test_size=0.2,random_state=42)
for train_index,test_index in split.split(housing,housing["income_cat"]):
strat_train_set = housing.loc[train_index]
strat_test_set = housing.loc[test_index]
print(strat_test_set["income_cat"].value_counts()/len(strat_test_set))
通过这个代码可以看到测试集中的收入类别比例分布。
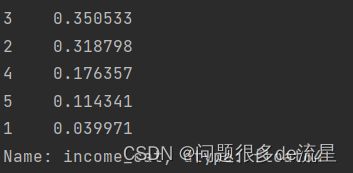
整体的收入类别比例分布:

可见,分层抽样的测试集中的比例分布与完整数据集中的分布几乎一致。
接下来可以删除income_cat属性,将数据恢复原样。
for set_ in(strat_train_set,strat_test_set):
set_.drop("income_cat",axis = 1,inplace = True)
print(strat_test_set)
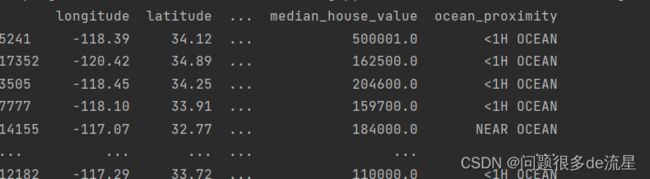
以上测试集就生成好了。
四、数据探索和可视化
这个阶段的目标就是对梳理再深入一点。首先,把测试集放在一边,你能探索的只有训练集。先创建一个副本,这样可以随便尝试而不损害训练集:
housing = strat_train_set.copy
1.将地理数据可视化
由于存在地理位置信息(经度和纬度),因此建立一个各区域的分布图以便于可视化数据
housing = strat_train_set.copy()
housing.plot(kind="scatter",x="longitude",y="latitude")
plt.show()
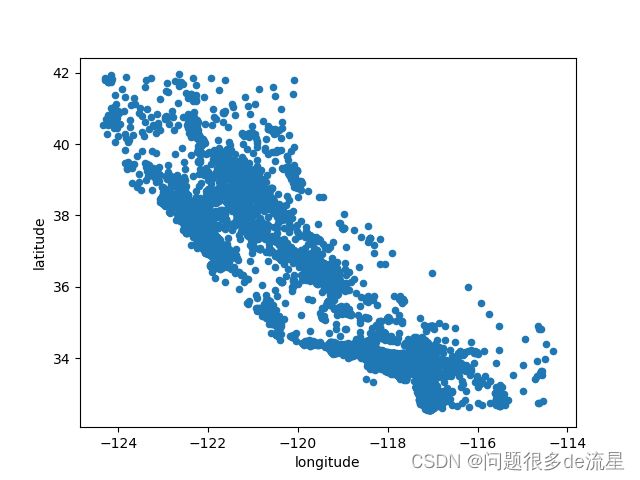
这个是数据的地理散点图,将alpha选项设置为0.1,可以更清楚地看出高密度数据点地位置
housing = strat_train_set.copy()
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.1)
plt.show()

再看房价,每个圆的半径大小代表了每个区域的人口数量(选项s),颜色代表价格(选项c)。我们使用一个名叫jet的预定义颜色表(选项cmap)来进行可视化,颜色范围从蓝(低)到红(高)。
housing.plot(kind="scatter",x="longitude",y="latitude",alpha=0.4,s=housing["population"]/100,label="population",figsize=(10,7),c="median_house_value",cmap=plt.get_cmap("jet"),colorbar=True,)
plt.legend()
plt.show()

这表明房价与地理位置和人口密度息息相关。海洋邻近度就是一个很有用的属性,不过在北加州,沿海地区的房价并不是太高,所以这个简单的规则也不是万能的。
2.寻找相关性
由于数据集不大,可以使用corr()方法轻松计算出每对属性之间的标准相关系数分别是多少:
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))

相关系数的范围从-1变化到1。越接近1,表示有越强的正相关。当系数接近于-1时,表示有较强的负相关。系数靠近0则说明二者之间没有线性相关性。
相关系数仅测量线性相关性(如果x上升,则y上升/下降)。
还有一种方法可以检测属性之间的相关性,就是使用pandas的scatter_matrix函数,它会绘制出每个数值属性相对于其他数值属性的相关性。现在我们有11个数值属性,可以得到112=121个图像,这里我们仅关注那些与房价中位数属性最相关的,可算作是最优潜力的属性(前四个)。

最优潜力能够预测房价中位数的属性是收入中位数,可以放大看看其相关性的散点图:

这说明了二者的相关性确实很强,可以清楚地看到上升的趋势,并且点也不是很分散。其次,50万美元的价格上限在图中是一条清晰的水平线,不过初次之前,还显示出几条不那么明显的直线:45万美元附近还有一条水平线,35万美元附近也有一条,28万美元附近似乎隐约也有一条,再往下可能还有一些。为了避免算法学习之后重现这些怪异数据,可以删除这些相应区域。
3.试验不同属性的组合
在准备开始给机器学习算法输入数据之前,可能识别除了一些异常的数据,需要提前清理掉;或者发现了不同属性之间的某些有趣联系,特别是跟目标属性相关的联系。再有,还可能某些属性的分布显示了明显的“重尾”分布,于是需要对它们进行转换处理(例如,计算其对数)。
因此,在准备给机器学习算法输入数据之前,要做的最后一件事应该是尝试各种属性的组合。例如,不知道一个区域有多少个家庭,那么知道一个区域的“房间总数“没有用,因为真正想知道的是一个家庭的房间数量。同样,单看”卧室总数“这个属性本身没有意义,但是,与”房间总数“对比,或者与”每个家庭的人口数“这个属性组合就会有意义。
housing["rooms_per_household"]=housing["total_rooms"]/housing["households"]
housing["bedrooms_per_home"]=housing["total_bedrooms"]/housing["total_rooms"]
housing["population_per_household"]=housing["population"]/housing["households"]
再看相关性矩阵。
corr_matrix = housing.corr()
print(corr_matrix["median_house_value"].sort_values(ascending=False))
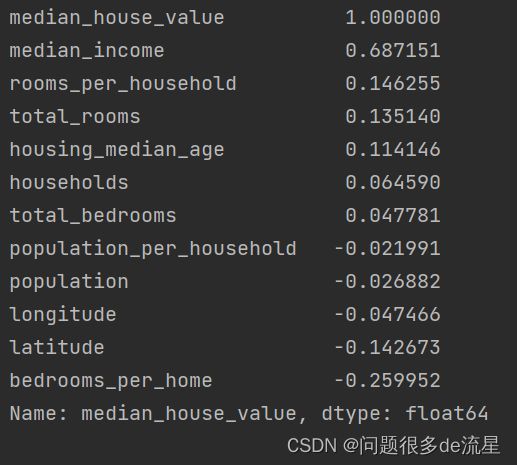
跟之前相比增加了我们添加的三项,可以看出bedrooms_per_home较”房价总数“或”卧室总数“与房价中位数的相关性都要高得多。显然,卧室/房间比例更低的房屋往往间隔更贵。同样,”每个家庭的房间数量“也比”房间总数“更具信息量——房屋越大,价格越贵。
这一轮的探索不一定很彻底,但是可以有助于获得一个比较好的第一个原型。这也是一个不断迭代的过程:一旦你的原型产生并且开始运行,可以分析它的输出以获得更多的洞见,然后在此回到这个探索步骤。
五、机器学习算法的数据准备
现在,可以给机器学习算法准备数据。这里应该编写函数来执行:可以在任何数据集上轻松重现这些转换;可以逐渐建立起一个转换函数的函数库,可以在以后的项目中重用;可以在实时系统中使用这些函数来转换新数据,再输入给算法;可以轻松尝试多种转换方法,查看哪种转换的组合效果最佳。
这个部分,先让训练集回到干净的状态。(再次复制strat_train_set),然后将预测器和标签分开,因为这里我们不一定对它们使用相同的转换方式(需要注意drop()会创建一个数据副本,但是不影响strat_train_set)
housing = strat_train_set.drop("median_house_value",axis=1)
housing_labels = strat_train_set["median_house_value"].copy()
print(housing_labels)

1.数据清理
大部分机器学习算法无法在缺失的特征上工作,所以要创建一些函数来辅助它。前面提到total_bedrooms属性有部分值缺失,所以我们要解决它。有三种选择:
①放弃这些相应的区域
②放弃整个属性
③将缺失的值设置为某个值(0、平均值或者中位数)
通过DataFrame的dropna()、drop()、fillna()方法,可以轻松完成这些操作:
housing.dropna(subset=["total_bedrooms"]) # 放弃这些区域,subset:子集,参数表示行或列的一部分,用列表表示。默认值为None
# 当total_bedrooms的这一列为空,则删除该行,axis默认为0
housing.drop("total_bedrooms", axis=1) # 删除某列
median = housing["total_bedrooms"].median() # 取中位数
housing["total_bedroom"].fillna(median, inplace=True) #填充
# True:直接修改原对象 False:创建一个副本,修改副本,原对象不变(缺省默认)
如果用第三个方法,需要计算出训练集的中位数值,再用它填充训练集中的缺失值,但是需要保存这个计算出来的中位数值。当重新评估系统时,需要更换测试集中的缺失值;或者在系统上线时,需要使用新数据替代缺失值。Scikit-Learn提供了一个非常容易上手的类来处理缺失值:SimpeImputer。
使用方法:
- 需要创建一个SimpleImputer实例,制定要用属性的中位数值替换该属性的缺失值
- 由于中位数值只能在数值属性上计算,所以需要创建一个没有文本属性ocean_proximity的数据副本
- 使用fit()方法将imputer实例适配到训练数据
- 这里imputer计算量每个属性的中位数值,并将结果存储在其实例变量statistics_中。虽然只有total_bedrooms这个属性存在缺失值,但是稳妥起见,还是将imputer应用于所有的数值属性。
- 使用imputer将缺失值替换成中位数值从而完成训练集转换
- 结果是一个Numpy数组。将其放回DataFrame格式。
imputer = SimpleImputer(strategy="median")
housing_num = housing.drop("ocean_proximity",axis=1)
imputer.fit(housing_num)
X=imputer.transform(housing_num)
housing_tr = pd.DataFrame(X,columns=housing_num.columns,index=housing_num.index)

可以看出total_bedrooms已经没有为空的数据了。
Scikit-Learn的API设计得很好,其主要得设计原则是:
- 一致性:所有对象共享一个简单一致的界面。
- 估算器:能够根据数据集对某些参数进行估算的任意对象都可以称为估算器(例如,inputer就是一个估算器)。估算由fit()方法执行,它只需要一个数据集作为参数(或者两个——对于有监督学习算法,第二个数据集包含标签)。引导估算过程的任何其他参数都视为超参数(例如imputer’s strategy=‘median’),它必须被设置为一个实例变量(一般通过构造函数参数)
- 转换器:有些估算器也可以转换数据集,这些称为转换器(imputer)。同样,API(应用程序接口)非常简单:由transform()方法和作为参数的待转换数据集一起执行转换,返回的结果就是转换后的数据集。这种转换的过程通常依赖于学习的参数。所有的转换器都可以使用一个很方便的方法,即fit_transform(),相当于先调用fit()然后再调用trandform()(但是fit_transform())
所以
imputer.fit(housing_num) #估算器--->估算中位数 X=imputer.transform(housing_num) #转换器
可以写成一句话:
X=imputer.fit_transform(housing_num) - 预测器:还有一些估算器能够基于一个给定的数据集进行预测,这称为预测器。例如LinearRegression模型就是一个预测器,它可以基于一个国家的人均GDP预测该国家的生活满意度。预测器的predict()方法接受一个新实例的数据集,然后返回一个包含相应预测的数据集。值得一提的还有一个score()方法,可以用来衡量给定测试集的预测质量(以及在有监督算法里对应的标签)
- 检查:所有估算器的超参数都可以通过公共实例变量(例如,imputer.strategy直接访问),并且所有估算器的学习参数也可以通过有下划线后缀的公共实例变量来访问(例如,Imputer.statistics_)
- 防止类扩散:数据集被表示为Numpy数组或者SciPy稀疏矩阵,而不是自定义的类型。超参数只是普通的Python字符串或者数字。
- 构成:现有的构建块尽最大可能重用。例如,任何序列的转换器最后加一个预测器就可以轻松创建一个Pipeline估算器
- 合理的默认值:Scikit-learn为大多数参数提供了合理的默认值,从而可以快速搭建起一个基本的工作系统。
2.处理文本和分类属性
到目前为止,我们只是处理了数值属性。先看一下文本属性。在此数据集中,只有一个文本属性:ocean_proximity属性。可以看看前10个实例的值:
它不是任意文本,而是有限个可能的取值,每个值代表一个类别。因此,此属性是分类属性。大多数机器学习算法更喜欢使用数字,因此将这些类别从文本转换为数字。为此,可以使用Scikit-Learn的OrdinalEncoder类:
from sklearn.preprocessing import OrdinalEncoder
ordinal_encoder = OrdinalEncoder()
housing_cat_encoded = ordinal_encoder.fit_transform(housing_cat)
可以用Categories_实例获取类别列表。这个列表包含每个类别属性的一维数组(在这个情况下,每个列表包含一个数组,因此只有一个类别属性):
print(ordinal_encoder.categories_)
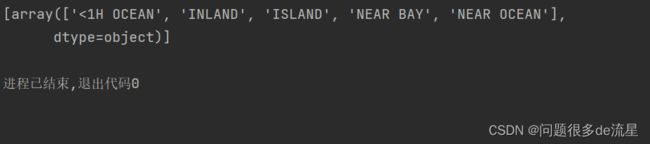
这种表示方法产生的问题就是,机器学习会认为两个相近的值比两个离得较远的值更为相似一些。在某些情况下这是对的(对一些有序类别,像”坏“”平均“”好“”优秀“),但是对于本例中的情况并非如此(例如,类别0和类别4之间就比类别0和类别1之间的相似度更高)。为了解决解决这个问题,常见的解决方案是给每个类别创建一个二进制的属性:当类别是”<1H OCEAN“时,一个属性为1(其他为0),当类别是”INLAND“时,另一个属性为1(其他是0)以此类推。这就是独热编码,因为只有一个属性为1(热),其他均为0(冷)。新的属性有时候称为哑(dummy)属性。Scikit-Learn提供了一个OneHotEncoder编码器,可以将整数类别值转换为独热向量。我们用它来将类别编码为独热向量。
from sklearn.preprocessing import OneHotEncoder
cat_encoder = OneHotEncoder()
housing_cat_1hot = cat_encoder.fit_transform(housing_cat)
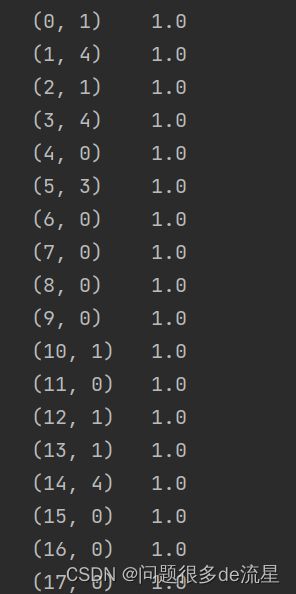
这里输出的是一个SciPy稀疏矩阵,而不是一个Numpy数组。当你有成千上万个类别属性时,这个函数会非常有用,因为在独热编码完成之后,我们会得到一个几千列的矩阵,并且全是0,每行仅有一个1。占用大量内存在存储0是一件非常浪费的事情,因此稀疏矩阵选择仅存储非零元素的位置。而你依旧可以像使用一个普通的二维数组那样来使用它,如果想转换成Numpy数组,只需要调用toarray()方法即可。
如果类别属性具有大量可能的类别(例如,国家代码、专业、物种),那么独热编码会导致大量的输入特征,这可能会减慢训练并降低性能。如果有这种情况,可以用相关的数字特征代替类别输入。例如,可以用与海洋的距离来替换ocean_proximity特征(类似地,可以用该国家的人口和人均GDP来代替国家代码)。或者,可以用可学习的低维向量(称为嵌入)来替换每个类别。每个类别的表征可以在训练期间学习。
3.自定义转换器
如果需要编写自定义清理操作或组合特定属性等转换器,并且需要让自定义的转换器与Scikit-Learn自身的功能(比如流水线)无缝衔接,而由于Scikit-Learn依赖于鸭子类型的编译,而不是继承,所以只需要创建一个类,然后应用以下三种方法:fit()(返回self)、transform()、fit_transform()。
在程序设计中,鸭子类型是动态类型的一种风格。在这种风格中,一个对象有效的语义,不是由继承自特定的类或实现特定的接口,而是由"当前方法和属性的集合"决定。在鸭子类型中,关注点在于对象的行为,能作什么;而不是关注对象所属的类型。例如,在不使用鸭子类型的语言中,我们可以编写一个函数,它接受一个类型为鸭子的对象,并调用它的 “走” 和 “叫” 方法。在使用鸭子类型的语言中,这样的一个函数可以接受一个任意类型的对象,并调用它的"走"和"叫"方法。
可以通过添加TransformerMixin作为基类,可以得到最后一种方法。同时,如果添加BaseEsitimator作为基类(并在构造函数中避免 * args 和 **kargs ),还能额外获得两种非常有用的自动调整超参数的方法(get_params和set_params())。
# *----------------------------------------------------自定义转换器-----------------------------------------*
rooms_ix, bedrooms_ix, population_ix, households_ix = 3, 4, 5, 6
class ComebinedAttributesAdder(BaseEstimator, TransformerMixin):
def __init__(self, add_bedrooms_per_room=True): # no *args or **kargs
self.add_bedrooms_per_room = add_bedrooms_per_room
def fit(self, X, y=None):
return self # nothing else to do
def transform(self, X):
rooms_per_household = X[:, rooms_ix] / X[:, households_ix]
population_per_household = X[:, population_ix] / X[:, households_ix]
if self.add_bedrooms_per_room:
bedrooms_per_rooms = X[:, bedrooms_ix] / X[:, rooms_ix]
return np.c_[X, rooms_per_household, population_per_household, bedrooms_per_rooms]
else:
return np.c_[X, rooms_per_household, population_per_household]
attr_adder = ComebinedAttributesAdder(add_bedrooms_per_room=False)
housing_extra_attribs = attr_adder.transform(housing.values)
print(housing_extra_attribs)
这个例子中,转换器有一个超参数add_bedrooms_per_room默认设置为True。这个超参数可以让你轻松知晓添加这个属性是否有助于机器学习算法。这些数据准备步骤的执行越自动化,你自动尝试的组合也就更多,从而有更大可能从中找到一个重要的组合。
4.特征缩放
最重要也最需要应用到数据上的转换就是特征缩放。如果输入的数值属性具有非常大的比例差异,往往会导致机器学习算法的性能表现不佳,当然也有极少数特例。案例中的房屋数据就是这样:房间总数的范围从5 ~ 30320,而收入中位数的范围是0 ~ 15。!!!目标值通常不需要缩放。
同比例缩放所有属性的两种常用方法:最小-最大缩放(归一化)和标准化。
归一化:将值重新缩放使其最终范围归于0~1之间。实现方法就是将值减去最小值并除以最大值和最小值的差。对此,Scikit-Learn提供了一个名叫MinMaxScaler的转换器。如果你希望范围不是0 ~ 1,那么可以通过调整超参数feature_range进行更改。
标准化:首先减去平均值(所以标准化的均值总是零),然后除以方差,从而使得结果的分布具备单位方差。不同于归一化的是,标准化不将值绑定到特定范围,对于某些算法而言,这可能是个问题(例如,神经网络期望的输入值范围通常0 ~ 1)。但是标准化的方法受异常值的影响更小。例如,假设某个地区的平均收入为100(错误数据),归一化会将所有其他值从0 ~ 15降到0 ~ 0.15,而标准化则不会受到很大影响。Scikit-Learn提供了一个标准化的转换器StandardScaler。
5.转换流水线
许多数据转换的步骤需要以正确的顺序来执行。而Scikit-learn正好提供了Pipeline类来支持这样的转换。
num_pipeline = Pipeline([('imputer',SimpleImputer(strategy="median")),('attribs_adder',ComebinedAttributesAdder()),('std_scaler',StandardScaler())])
housing_num_tr = num_pipeline.fit_transform(housing_num)
Pipeline构造函数会通过一系列名称/估算器的配对来定义步骤序列。除了最后一个是估算器之外,前面都必须是转换器(也就是说,必须要有fit_transform()方法)。至于命名可以随意,它们稍后在超参数调整中会有用。
当调用流水线的fit()方法时,会在所有转换器上按照顺序依次调用fit_transform(),将一个调用的输出作为参数传递给下一个调用方法,直到传递到最终的估算器,则只会调用fit()方法。
流水线的方法与最终的估算器的方法相同。在这个例子中,最后一个估算器是StandardScaler,这是一个转换器,因此流水线有一个transform()方法,可以按顺序将所有的转换应用到数据中(这也是我们用过的fit_transform()方法)。
以上我们分别处理了数值列和分类列。拥有一个能够处理所有列的转换器会更方便,将适当的转换应用于每个列。在0.20版中,Scikit-Learn为此引入了ColumnTransformer,好消息是它与pandas DataFrames一起使用时效果很好。用它来将所有转换应用到房屋数据:
num_attribs = list(housing_num)
cat_attribs = ["ocean_proximity"]
full_pipeline = ColumnTransformer([("num",num_pipeline,num_attribs),("cat",OneHotEncoder(),cat_attribs)])
housing_prepared = full_pipeline.fit_transform(housing)
首先导入ColunmTransformer类,接下来获得数值列名称列表和类别列名称列表,然后构造一个ColunmTransformer。构造函数需要一个元组列表,其中每个元组都包含一个名字、一个转换器、以及一个该转换器能够应用的列名字(或索引)的列表。在这个例子中,我们指定数值列使用之前定义的num_pipeline进行转换,类别列使用OneHotEncoder进行转换。最后,我们将ColunmTransformer应用到房屋数据:它将每个转换器应用于适当列,并沿第二个轴合并输出(转换器必须返回相同数量的行)。
OneHotEncoder返回一个稀疏矩阵,而num_pipeline返回一个密集矩阵。当稀疏矩阵和密集矩阵混合在一起时,ColumnTransformer会估算最终矩阵的密度(即单元格的非零比率),如果密度低于给定的阈值,则返回一个稀疏矩阵(通过默认值为sparse_threshold=0.3)。在这个例子中,它返回一个密集矩阵。我们有一个预处理流水线,该流水线可以获取全部房屋数据并对每一个列进行适当的转换
六、选择和训练模型
已经完成了自动清理和准备机器学习算法的数据,现在可以选择机器学习模型并展开训练。
1.训练和评估数据集
经过前面的步骤之后,先训练一个线性回归模型。
#*-------------------------------------------------------------------训练线性回归模型--------------------------------------*/
lin_reg = LinearRegression()
lin_reg.fit(housing_prepared,housing_labels)
some_data = housing.iloc[:5]
some_labels = housing_labels.iloc[:5]
some_data_prepared = full_pipeline.transform(some_data)
print("Predictions:",lin_reg.predict(some_data_prepared))
print("labels:",list(some_labels))
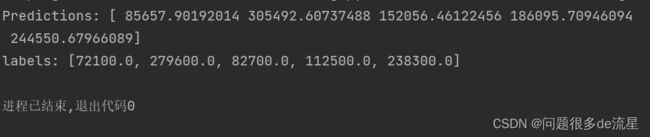
比较两者的值,发现这个模型可以工作,但是预测不是很准确。这就是一个典型的模型对训练数据欠拟合的案例,因此就尝试一个更复杂的模型 (决策树),看看它到底是怎么工作的。
# *-------------------------------------------------------------------决策树模型-------------------------------------------*/
tree_reg = DecisionTreeRegressor()
tree_reg.fit(housing_prepared, housing_labels)
housing_predictions = tree_reg.predict(housing_prepared)
tree_mse = mean_squared_error(housing_labels, housing_predictions)
tree_rmse = np.sqrt(tree_mse)
print("Predictions:", tree_reg.predict(housing_prepared)[:5])
print("labels:", list(housing_labels)[:5])
print(tree_rmse)

输出的rmse为0。有可能是这个模型对数据严重过拟合了。我们怎么确认呢?在你有信息启动模型之前,都不要触碰测试集,所以拿训练集中的一部分用于训练,另一部分用于模型验证。
2.使用交叉验证来更好地进行评估
评估决策树模型地一种方法是使用train_test_split函数将训练集分为较小的训练集和验证集,然后根据这些较小的训练集来训练模型,并对其进行评估。
另一个不错的选择是使用Scikit-Learn的K-折交叉验证功能:它将训练集随机分割成10个不同的子集,每个子集称为一个折叠,然后对决策树模型进行10次训练和评估——每次挑选1个折叠进行评估,使用另外9个折叠进行训练。产生的结果是一个包含10次评估分数的数组:
# *-------------------------------------------------------------------决策树模型评估 - ------------------------------------------ * /
scores = cross_val_score(tree_reg,housing_prepared,housing_labels,scoring = "neg_mean_squared_error",cv=10)
tree_rmse_scores = np.sqrt(-scores)
print(tree_rmse_scores)

Scikit-Learn的交叉验证功能更倾向于使用效果函数(越大越好),而不是成本函数(越小越好),所以计算分数的函数实际上是一个负的MSE(一个负值)函数,这就是为什么上面的代码会在计算平方根前计算出-scores。
看看详细结果:
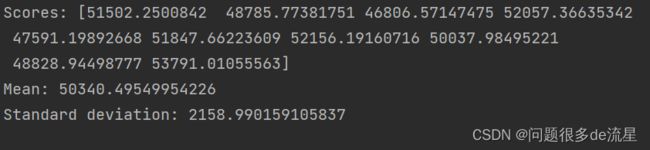
def display_scores(scores):
print("Scores:",scores)
print("Mean:",scores.mean())
print("Standard deviation:",scores.std())
display_scores(tree_rmse_scores)
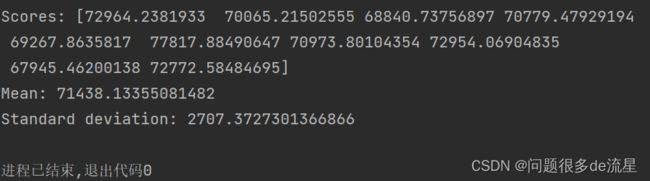
这次的决策树模型不如之前表现得好,甚至比线性回归模型还要糟糕。这里该决策树得出的评分约为71438,上下浮动2707。如果只是用一个验证集,就收不到这样的结果信息。交叉验证的代价就是要多次训练模型,因此也不是永远都行得通。保险起见,也计算一下线性回归模型的评分:
lin_scores = cross_val_score(lin_reg,housing_prepared,housing_labels,scoring="neg_mean_error",cv=10)
lin_rmse_scores = np.sqrt(-lin_scores)
display_scores(lin_rmse_scores)
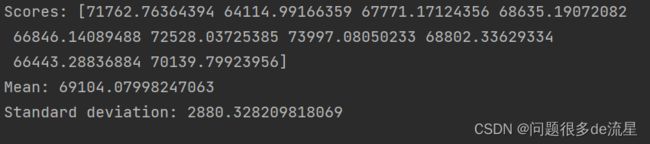
决策树模型确实是严重过拟合了,以至于表现得比线性回归模型还要糟糕。
再试试最后一个模型:RandomForestRegressor(随机森林)。
# *-------------------------------------------------------------------随机森林模型 - ------------------------------------------ * /
forest_reg = RandomForestRegressor()
forest_reg.fit(housing_prepared, housing_labels)
housing_predictions = forest_reg.predict(housing_prepared)
scores = cross_val_score(forest_reg,housing_prepared,housing_labels,scoring = "neg_mean_squared_error",cv=10)
forest_rmse_scores = np.sqrt(-scores)
display_scores(forest_rmse_scores)
这个就好多了:随机森林看起来很不错。但是训练集上得分数仍然远低于验证集,这意味着该模型仍然对训练集过拟合。过拟合的可能解决方案包括简化模型、约束模型(即使其正规化),或获得更多训练数据。我们的目的是筛选出几个(2 ~ 5个)有效的模型。
每个尝试过的模型都应该妥善保存,以便将来可以轻松回到你想要的模型当中。记得还要同时保存超参数和训练过的参数,以及交叉验证的评分和实际预测的结果。这样就可以轻松地对比不同模型类型地评分,以及不同模型造成地错误类型。通过Python的pickle模块或joblib库,你可以轻松保存Scikit-Learn模型,这样可以更有效地将大型Numpy数组序列化:
joblib.dump(forest_rmse_scores,"my_model1.pkl")
joblib.dump(tree_rmse,"my_model2.pkl")
joblib.dump(lin_rmse_scores,"my_model3.pkl")
my_model1_load = joblib.load("my_model1.pkl")
print(my_model1_load)

七、微调模型
如果现在有了一个有效模型的候选列表。现在你需要对它们进行微调。
1、网格搜索
一种微调的方法是手动调整超参数,直到找到一组很好的超参数值组合。需要耗费足够的时间。相反,可以使用Scikit-Learn的GridSearchCV来替你进行探索。你所要做的只是告诉它要进行实验的超参数是什么,以及需要尝试的值,它将会使用交叉验证来评估超参数值得所有可能组合。
例如搜索随机森林的超参数值的最佳组合:
param_grid = [{'n_estimators':[3,10,30],'max_features':[2,4,6,8]},{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]},]
forest_reg = RandomForestRegressor()
grid_search = GridSearchCV(forest_reg,param_grid,cv=5,scoring='neg_mean_squared_error',return_train_score=True)
grid_search.fit(housing_prepared,housing_labels)
n_estimators超参数代表10的连续幂次方。这个param_grid告诉Scikit-Learn,首先评估第一个dict中的n_estimator和max_features的所有3×4=12种超参数值组合;接着尝试第二个dict中超参数值的所有2×3=6种组合,但这次超参数bootstrap需要设置为False而不是True。
网格搜索将探索随机森林超参数值得18种组合,并对每个模型进行4此训练,总共会完成18×5=90次训练!完成后可以获得最佳参数组合。

如果GridSearchCV被初始化为refit=True,那么一旦通过交叉验证找到了最佳估算器,他将在整个训练集上重新训练。
print(grid_search.best_estimator_) #找最佳估算器
cvres = grid_search.cv_results_
for mean_score, params in zip(cvres["mean_test_score"],cvres["params"]):
print(np.sqrt(-mean_score),params) #评估分数
得到的最佳解决方案是将超参数max_features设置为8,将超参数n_estimators设置为30。这个组合的RMSE分数为50044,低于之前默认超参数值的分数50340。
有些数据准备的步骤也可以当作超参数来处理。例如网格搜索会自动查找是否添加你不确定的特征(比如是否使用转换器CombinedAttributesAdder的超参数add_bedrooms_per_room)。同样,还可以用它来自动寻找处理问题的最佳方法,例如处理异常值、缺失特征,以及特征选择等。
2、随机搜索
网格搜索适合探索的组合数量较少,当超参数的搜索范围较大时,通常优先选择使用RandomizedSearchCV。这个类用起来GridSearchCV类大致相同,但它不会尝试所有可能的组合,而是在每次迭代中为每个超参数选择一个随机值,然后对一定数量的随机组合进行评估。
3、集成方法
将表现最优的模型组合起来。
4、分析最佳模型机器误差
在进行准确预测时,随机森林可以指出每个属性的相对重要程度,并将重要性分数显示在对应的属性名称旁边。
feature_importances = grid_search.best_estimator_.feature_importances_
extra_attribs = ["rooms_per_hhold","pop_per_hhold","bedrooms_per_room"]
cat_encoder = full_pipeline.named_transformers_["cat"]
cat_one_hot_attribs = list(cat_encoder.categories_[0])
attributes = num_attribs+extra_attribs+cat_one_hot_attribs
print(sorted(zip(feature_importances,attributes,reverse=True)))
通过这些信息,删除一些不太有用的特征。
5、通过测试集评估系统
通过一段时间的训练,现在可以用测试集评估最终模型。这个过程只需要从测试集中获取预测器和标签,运行full_pipeline来转换数据(条用transform()而不是fit_transform()),然后在测试集上评估最终模型:
# ----------------------------------------------------------------通过测试集评估系统-----------------------------------------------
final_model = grid_search.best_estimator_
X_test = strat_test_set.drop("median_house_value",axis = 1) #原来数据不变
y_test = strat_test_set["median_house_value"].copy()
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_mse = mean_squared_error(y_test,final_predictions)
final_rmse = np.sqrt(final_mse)
print(final_mse,final_rmse)
为了能够启动生产环境,可以使用scipy.stats.t.interval()计算泛化误差的95%置信区间,以知道这个估计的精确度
#计算泛化误差95%置信区间:
confidence = 0.95
squared_errors = (final_predictions-y_test)**2
print(np.sqrt(stats.t.interval(confidence,len(squared_errors)-1,loc = squared_errors.mean(),scale=stats.sem(squared_errors))))

最后进入项目预启动阶段:你将要展示你的解决方案(强调学习了什么,什么有用,什么没有用,基于什么假设,以及系统的限制有哪些),记录所有事情,并且通过清晰的可视化的方式进行展示。
八. 启动、监控和维护你的系统
获准启动生产环境,需要准备好方案以进行上线(例如,完善代码、编写文档和测试等)。然后可以将模型部署到生产环境中。一种方法是保存训练好的模型(使用joblib),包括完整的预处理和预测流水线,然后在你的生产环境中加载经过训练的模型并通过调用prepare()方法来进行预测。例如,也许该模型在网站使用:用户将输入有关新地区的一些数据,然后单击估算价格按钮。发送一个查询,其中包含数据发送到Web服务器,然后将其转发到Web应用程序,最后,代码调用模型的predict()方法。
但是部署并不是故事的结束。还需要编写监控代码以定期检查系统的实时性能,并在系统性能降低时触发警报。
练习题
https://www.kaggle.com/competitions/titanic在这个网站选择了泰坦尼克号的数据进行练习,通过特征预测乘客是否生存。
利用支持向量机模型进行分类,最后得分:

步骤与笔记一致,先处理数据,文本数据转数字、数值数据标准化处理,缺失值利用中间值填充,对于文本值缺失,由于仅仅缺失两个值,所以删除相关行,并在经过数据探索后,删除数据中的无关特征量,最后结果不是完美的,但是我已经踏出了机器学习的第一步。
import zipfile
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from sklearn.compose import ColumnTransformer
from sklearn.ensemble import RandomForestClassifier
from sklearn.impute import SimpleImputer
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import cross_val_score, GridSearchCV
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import OrdinalEncoder, StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn import svm
from sklearn.naive_bayes import GaussianNB, MultinomialNB
from sklearn.neural_network import MLPClassifier
import joblib
# -----①下载数据-----使用浏览器下载压缩包后解压(需要运行一遍后再注释掉)
# f = zipfile.ZipFile("C:/Users/25464/Downloads/titanic.zip",'r') #压缩文件位置
# for file in f.namelist():
# f.extract(file,"D:/program/python_program/Titanic/datasets") #解压文件位置
# f.close()
# 加载数据
from sklearn.tree import DecisionTreeRegressor
titanic_training = pd.read_csv("D:/program/python_program/Titanic/datasets/train.csv")
titanic_testing = pd.read_csv("D:/program/python_program/Titanic/datasets/test.csv")
titanic_gender = pd.read_csv("D:/program/python_program/Titanic/datasets/gender_submission.csv")
# -----②快速查看数据结构-----
# print(titanic_training.info())
# 共有12个属性
# 其中Age、cabin、Embarked有缺失
# ---------------------object项-------------------
# Name、Sex、Ticket、Cabin、Embarked不是数字,其他是数字
# print(titanic_training["Sex"].value_counts())
# # 577男、314女
# print(titanic_training["Ticket"].value_counts())
# # 681个不同的值
# print(titanic_training["Cabin"].value_counts())
# # 147个不同的值
# print(titanic_training["Embarked"].value_counts())
# 应该是一个分类属性:S(644个)、C(168)个、Q(77个)
# ---------------------数值项-------------------
# 绘制每个数值属性的直方图
# titanic_training.hist(bins=50,figsize=(20,15))
# plt.show()
# 数值属性中,Survived是一个分类属性,pClass也是分类属性:(1,2,3),SibSp也是分类属性(0、1、2、3、4、5、8),Age和Fare分布不一致。
# -----③数据探索和可视化-----
# training = titanic_training.copy()
# 使用corr()方法算出属性之间的标准相关系数分别是多少:
# corr_matrix = training.corr()
# print(corr_matrix["Survived"].sort_values(ascending=False))
# 可以发现Fare、Parch正相关、SibSP负相关、Pclass负相关、Age负相关
# -----④机器学习的数据准备-----
# 对于Embarked有缺失,由于仅仅缺失2项,所以选择删除
titanic_training = titanic_training.dropna(
subset=["Embarked"]) # 放弃这些区域,subset:子集,参数表示行或列的一部分,用列表表示。默认值为None,当Embarked的这一列为空,则删除该行,axis默认为0
# 由于之前对数据的观察,Ticket和Cabin和PassengerId和Name应该是无关的量可以去掉
titanic_train_set = titanic_training.drop(["Survived", "Ticket", "Cabin", "PassengerId", "Name"], axis=1) # 剔除标签
titanic_train_labels = titanic_training["Survived"].copy() # 标签
# 对数值中位数填充
titanic_num = titanic_train_set.drop(["Sex", "Embarked"], axis=1) # 数值数据\去掉ID(有缺失)
num_attribs = list(titanic_num)
num_pipeline = Pipeline([('imputer', SimpleImputer(strategy="median")), ('std_scaler', StandardScaler())]) # 对缺失数据补充
num_prepared = num_pipeline.fit_transform(titanic_num)
# 将文本转换为数值
cat_attribs = ["Sex", "Embarked"]
full_pipeline = ColumnTransformer([("num", num_pipeline, num_attribs), ("cat", OrdinalEncoder(), cat_attribs)])
titanic_prepared = full_pipeline.fit_transform(titanic_train_set)
titanic_prepared = pd.DataFrame(titanic_prepared) # 转换为dataframe格式
# -----⑤选择和训练模型-----
# 逻辑回归
# lr_clf = LogisticRegression()
# lr_clf.fit(titanic_prepared,titanic_train_labels)
# # print(lr_rmse) # 0.446
#
# # 使用交叉验证来更好地评估模型
# scores = cross_val_score(lr_clf,titanic_prepared,titanic_train_labels,scoring="neg_mean_squared_error",cv=10)
# lr_rmse_scores = np.sqrt(-scores)
#
# # 保存模型
# joblib.dump(lr_clf,"LogisticRegression.pkl")
def display_scores(scores):
print("Scores:", scores)
print("Mean:", scores.mean())
print("Standard deviation:", scores.std())
# display_scores(lr_rmse_scores)
# 决策树
# tree_reg = DecisionTreeRegressor()
# tree_reg.fit(titanic_prepared,titanic_train_labels)
# scores = cross_val_score(tree_reg,titanic_prepared,titanic_train_labels,scoring="neg_mean_squared_error",cv=10)
# tree_rmse_scores = np.sqrt(-scores)
# # display_scores(tree_rmse_scores) # 0.466
# # 保存模型
# joblib.dump(tree_reg,"DecisionTreeRegressor.pkl")
# 支持向量机
# svm_reg = svm.SVC()
# svm_reg.fit(titanic_prepared,titanic_train_labels)
# scores = cross_val_score(svm_reg,titanic_prepared,titanic_train_labels,scoring="neg_mean_squared_error",cv=10)
# svm_rmse_scores = np.sqrt(-scores)
# display_scores(svm_rmse_scores) #0.422
# joblib.dump(svm_reg,"svm.pkl")
# 朴素贝叶斯
# gnb_reg = GaussianNB() # 高斯贝叶斯
# gnb_reg.fit(titanic_prepared,titanic_train_labels)
# scores = cross_val_score(gnb_reg,titanic_prepared,titanic_train_labels,scoring="neg_mean_squared_error",cv=10)
# gnb_rmse_scores = np.sqrt(-scores)
# display_scores(gnb_rmse_scores) #0.461
# joblib.dump(gnb_reg,"GaussianNB.pkl")
# mnb_reg = GaussianNB() # 多项式贝叶斯
# mnb_reg.fit(titanic_prepared,titanic_train_labels)
# scores = cross_val_score(mnb_reg,titanic_prepared,titanic_train_labels,scoring="neg_mean_squared_error",cv=10)
# mnb_rmse_scores = np.sqrt(-scores)
# display_scores(mnb_rmse_scores) #0.461
# 随机森林分类器
# forest_reg = RandomForestClassifier()
# forest_reg.fit(titanic_prepared, titanic_train_labels)
# scores = cross_val_score(forest_reg, titanic_prepared, titanic_train_labels, scoring="neg_mean_squared_error", cv=10)
# forest_rmse_scores = np.sqrt(-scores)
# display_scores(forest_rmse_scores) # 0.430
# joblib.dump(forest_reg,"RandomForestRegressor.pkl")
# 神经网络
# mlp_clf = MLPClassifier(max_iter=10000)
# mlp_clf.fit(titanic_prepared, titanic_train_labels)
# scores = cross_val_score(mlp_clf, titanic_prepared, titanic_train_labels, scoring="neg_mean_squared_error", cv=10)
# mlp_rmse_scores = np.sqrt(-scores)
# # display_scores(mlp_rmse_scores) # 0.438
# joblib.dump(mlp_clf,"MLPClassifier.pkl")
# 候选模型:支持向量机、随机森林,接下来对模型的超参数进行优化
# 支持向量机超参数优化
param_grid = [{'kernel':["rbf","linear"],'C':[1,5,10]}]
svm_reg = svm.SVC()
grid_search = GridSearchCV(svm_reg,param_grid,cv=5,scoring='neg_mean_squared_error',return_train_score=True)
grid_search.fit(titanic_prepared,titanic_train_labels)
#
# print(grid_search.best_estimator_) #找最佳估算器 C=5,kernel=rbf
# cvres = grid_search.cv_results_
# for mean_score, params in zip(cvres["mean_test_score"],cvres["params"]):
# print(np.sqrt(-mean_score),params) #评估分数
# 随机森林超参数优化
# param_grid = [{'n_estimators':[3,10,30],'max_features':[2,4,6]},{'bootstrap':[False],'n_estimators':[3,10],'max_features':[2,3,4]}]
# forest_reg = joblib.load("RandomForestRegressor.pkl")
# grid_search = GridSearchCV(forest_reg,param_grid,cv=5,error_score='raise',scoring='neg_mean_squared_error',return_train_score=True)
# grid_search.fit(titanic_prepared,titanic_train_labels)
# print(grid_search.best_estimator_)
# cvres = grid_search.cv_results_ #max_features=6, n_estimators=30
# for mean_score, params in zip(cvres["mean_test_score"],cvres["params"]):
# print(np.sqrt(-mean_score),params) #评估分数
# 选择支持向量机模型,利用测试集
final_model = grid_search.best_estimator_
X_test = titanic_testing.drop(["Ticket", "Cabin", "PassengerId", "Name"], axis=1) # 剔除标签
X_test_prepared = full_pipeline.transform(X_test)
final_predictions = final_model.predict(X_test_prepared)
final_predictions = pd.DataFrame({"Survived":final_predictions},index = titanic_testing["PassengerId"])
# final_predictions.to_csv("C:/Users/25464/Desktop/testing.csv")
final_mse = mean_squared_error(titanic_gender["Survived"],final_predictions["Survived"])
final_rmse = np.sqrt(final_mse)
print(final_rmse) # 0.259