【Transformers】第 2 章:文本分类
大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流
个人主页-Sonhhxg_柒的博客_CSDN博客
欢迎各位→点赞 + 收藏⭐️ + 留言
系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟
文章目录
数据集
拥抱人脸数据集初探
从数据集到数据帧
查看类别分布
我们的推文有多长?
从文本到标记
字符标记化
词标记化
子词标记化
标记整个数据集
训练文本分类器
变形金刚作为特征提取器
使用预训练模型
提取最后的隐藏状态
创建特征矩阵
可视化训练集
训练一个简单的分类器
微调Transformers
加载预训练模型
定义性能指标
训练模型
错误分析
保存和共享模型
编辑
结论
文本分类是 NLP 中最常见的任务之一;它可用于广泛的应用程序,例如将客户反馈标记到类别或根据他们的语言路由支持票证。您的电子邮件程序的垃圾邮件过滤器很有可能正在使用文本分类来保护您的收件箱免受大量垃圾邮件的侵害!
另一种常见的文本分类类型是情感分析,它(如我们在第 1 章中所见)旨在识别给定文本的极性。例如,像特斯拉这样的公司可能会分析图 2-1中的 Twitter 帖子,以确定人们是否喜欢它的新车顶。

图 2-1。分析 Twitter 内容可以从客户那里获得有用的反馈(由 Aditya Veluri 提供)
现在假设您是一名数据科学家,他需要构建一个系统来自动识别人们在 Twitter 上表达的关于您公司产品的情绪状态,例如“愤怒”或“快乐”。在本章中,我们将使用称为 DistilBERT 的 BERT 变体来解决此任务。1该模型的主要优势在于它实现了与 BERT 相当的性能,同时显着更小、更高效。这使我们能够在几分钟内训练一个分类器,如果你想训练一个更大的 BERT 模型,你可以简单地更改预训练模型的检查点。检查点对应于加载到给定变压器架构中的权重集。
这也将是我们第一次接触 Hugging Face 生态系统中的三个核心库: Datasets、Tokenizers 和 Transformers。如图 2-2所示 ,这些库将允许我们快速从原始文本转换为可用于推断新推文的微调模型。因此,本着 Optimus Prime 的精神,让我们潜入“转型并推出!” 2
Datasets、Tokenizers 和 Transformers。如图 2-2所示 ,这些库将允许我们快速从原始文本转换为可用于推断新推文的微调模型。因此,本着 Optimus Prime 的精神,让我们潜入“转型并推出!” 2

图 2-2。使用Datasets、Tokenizers 和Transformers 库训练 Transformer 模型的典型管道
数据集
为了构建我们的情绪检测器,我们将使用一篇文章中的一个很好的数据集,该文章探讨了情绪如何在英语 Twitter 消息中表示。3 与大多数仅涉及“正面”和“负面”极性的情绪分析数据集不同,该数据集包含六种基本情绪:愤怒、厌恶、恐惧、喜悦、悲伤和惊讶。给定一条推文,我们的任务将是训练一个可以将其分类为其中一种情绪的模型。
拥抱人脸数据集初探
我们将使用数据集从Hugging Face Hub下载数据。我们可以使用该list_datasets()函数查看 Hub 上可用的数据集:
from datasets import list_datasets
all_datasets = list_datasets()
print(f"There are {len(all_datasets)} datasets currently available on the Hub")
print(f"The first 10 are: {all_datasets[:10]}")There are 1753 datasets currently available on the Hub The first 10 are: ['acronym_identification', 'ade_corpus_v2', 'adversarial_qa', 'aeslc', 'afrikaans_ner_corpus', 'ag_news', 'ai2_arc', 'air_dialogue', 'ajgt_twitter_ar', 'allegro_reviews']
我们看到每个数据集都有一个名称,所以让我们emotion用load_dataset()函数加载数据集:
from datasets import load_dataset
emotions = load_dataset("emotion")如果我们查看emotions对象内部:
emotionsDatasetDict({
train: Dataset({
features: ['text', 'label'],
num_rows: 16000
})
validation: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
test: Dataset({
features: ['text', 'label'],
num_rows: 2000
})
})
我们看到它类似于 Python 字典,每个键对应一个不同的拆分。我们可以使用通常的字典语法来访问单个拆分:
train_ds = emotions["train"]
train_dsDataset({
features: ['text', 'label'],
num_rows: 16000
})
它返回类的一个实例Dataset。Dataset对象是数据集中的核心数据结构之一, 我们将在本书的整个过程中探索它的许多特性。对于初学者来说,它的行为就像一个普通的 Python 数组或列表,所以我们可以查询它的长度:
len(train_ds)16000
或通过索引访问单个示例:
train_ds[0]{'label': 0, 'text': 'i didnt feel humiliated'}
在这里,我们看到单行表示为字典,其中键对应于列名:
train_ds.column_names['text', 'label']
价值是推文和情感。这反映了Datasets 基于 Apache Arrow的事实,它定义了一种比原生 Python 内存效率更高的类型化列格式。features我们可以通过访问对象的属性来查看幕后使用的数据类型 Dataset:
print(train_ds.features){'text': Value(dtype='string', id=None), 'label': ClassLabel(num_classes=6,
names=['sadness', 'joy', 'love', 'anger', 'fear', 'surprise'], names_file=None,
id=None)}
在这种情况下,列的数据类型text是string,而 label列是一个特殊ClassLabel对象,其中包含有关类名及其到整数的映射的信息。我们还可以使用切片访问多行:
print(train_ds[:5]){'text': ['i didnt feel humiliated', 'i can go from feeling so hopeless to so
damned hopeful just from being around someone who cares and is awake', 'im
grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic
about the fireplace i will know that it is still on the property', 'i am feeling
grouchy'], 'label': [0, 0, 3, 2, 3]}
请注意,在这种情况下,字典值现在是列表而不是单个元素。我们还可以按名称获取完整列:
print(train_ds["text"][:5])['i didnt feel humiliated', 'i can go from feeling so hopeless to so damned hopeful just from being around someone who cares and is awake', 'im grabbing a minute to post i feel greedy wrong', 'i am ever feeling nostalgic about the fireplace i will know that it is still on the property', 'i am feeling grouchy']
现在我们已经了解了如何使用 数据集加载和检查数据,让我们对推文的内容进行一些检查。
如果我的数据集不在集线器上怎么办?
我们将使用 Hugging Face Hub 下载本书中大多数示例的数据集。但在许多情况下,您会发现自己在处理存储在笔记本电脑或组织中远程服务器上的数据。 Datasets 提供了几个加载脚本来处理本地和远程数据集。最常见的数据格式示例如表 2-1所示。
| Data format | Loading script | Example |
|---|---|---|
| CSV |
|
|
| text |
|
|
| JSON |
|
|
如您所见,对于每种数据格式,我们只需将相关的加载脚本以及指定一个或多个文件的路径或 URLload_dataset()的参数传递给函数 。data_files例如,emotion数据集的源文件实际上托管在 Dropbox 上,因此加载数据集的另一种方法是首先下载其中一个拆分:
dataset_url = "https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt"!wget {dataset_url}
如果您想知道为什么!前面的 shell 命令中有一个字符,那是因为我们在 Jupyter 笔记本中运行这些命令。如果要在终端中下载和解压缩数据集,只需删除前缀即可。现在,如果我们查看train.txt文件的第一行 :
!head -n 1 train.txti didnt feel humiliated;sadness
我们可以看到这里没有列标题,每条推文和情感都用分号分隔。尽管如此,这与 CSV 文件非常相似,因此我们可以通过使用csv脚本并将data_files参数指向train.txt文件来在本地加载数据集:
emotions_local = load_dataset("csv", data_files="train.txt", sep=";",
names=["text", "label"])在这里,我们还指定了分隔符的类型和列的名称。更简单的方法是将 data_files参数指向 URL 本身:
dataset_url = "https://www.dropbox.com/s/1pzkadrvffbqw6o/train.txt?dl=1"
emotions_remote = load_dataset("csv", data_files=dataset_url, sep=";",
names=["text", "label"])它将自动为您下载和缓存数据集。如您所见,该load_dataset()功能非常通用。我们建议查看
数据集文档以获得完整的概述。
从数据集到数据帧
尽管Datasets 提供了许多低级功能来对我们的数据进行切片和切块,但将Dataset对象转换为 Pandas通常很方便,DataFrame因此我们可以访问高级 API 以进行数据可视化。为了启用转换,Datasets 提供了一种 方法,set_format()允许我们更改. 请注意,这不会更改基础数据格式(这是一个箭头表)Dataset,如果需要,您可以稍后切换到另一种格式:
import pandas as pd
emotions.set_format(type="pandas")
df = emotions["train"][:]
df.head()| text | label | |
|---|---|---|
| 0 | i didnt feel humiliated | 0 |
| 1 | i can go from feeling so hopeless to so damned... | 0 |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 |
| 4 | i am feeling grouchy | 3 |
如您所见,列标题已被保留,前几行与我们之前的数据视图相匹配。但是,标签是用整数表示的,所以让我们使用特征的int2str()方法label在我们的新列中创建一个DataFrame具有相应标签名称的新列:
def label_int2str(row):
return emotions["train"].features["label"].int2str(row)
df["label_name"] = df["label"].apply(label_int2str)
df.head()| text | label | label_name | |
|---|---|---|---|
| 0 | i didnt feel humiliated | 0 | sadness |
| 1 | i can go from feeling so hopeless to so damned... | 0 | sadness |
| 2 | im grabbing a minute to post i feel greedy wrong | 3 | anger |
| 3 | i am ever feeling nostalgic about the fireplac... | 2 | love |
| 4 | i am feeling grouchy | 3 | anger |
在深入构建分类器之前,让我们仔细看看数据集。正如 Andrej Karpathy 在他著名的博文“训练神经网络的秘诀”中指出的那样,成为“与数据合一”是训练优秀模型的重要一步!
查看类别分布
每当您处理文本分类问题时,检查示例在类中的分布是一个好主意。具有倾斜类分布的数据集在训练损失和评估指标方面可能需要与平衡数据集不同的处理。
使用 Pandas 和 Matplotlib,我们可以快速可视化类分布,如下所示:
import matplotlib.pyplot as plt
df["label_name"].value_counts(ascending=True).plot.barh()
plt.title("Frequency of Classes")
plt.show()
在这种情况下,我们可以看到数据集严重不平衡;love和surprise 类经常出现,而joy和sadness则少 5到 10 倍。有几种方法可以处理不平衡的数据,包括:
-
随机过采样少数类。
-
随机对多数类进行欠采样。
-
从代表性不足的类别中收集更多标记数据。
为了在本章中保持简单,我们将使用原始的、不平衡的类频率。如果您想了解有关这些采样技术的更多信息,我们建议您查看 Imbalanced-learn 库。只需确保在创建训练/测试拆分之前不应用采样方法 ,否则它们之间会出现大量泄漏!
既然我们已经看过类,让我们看一下推文本身。
我们的推文有多长?
Transformer 模型有一个最大输入序列长度,称为最大上下文大小。对于使用 DistilBERT 的应用程序,最大上下文大小为 512 个标记,相当于几段文本。正如我们将在下一节中看到的,令牌是一段原子文本;现在,我们将一个标记视为一个单词。通过查看每条推文的单词分布,我们可以粗略估计每种情绪的推文长度:
df["Words Per Tweet"] = df["text"].str.split().apply(len)
df.boxplot("Words Per Tweet", by="label_name", grid=False,
showfliers=False, color="black")
plt.suptitle("")
plt.xlabel("")
plt.show()
从图中我们看到,对于每种情绪,大多数推文的长度约为 15 个单词,最长的推文远低于 DistilBERT 的最大上下文大小。长于模型上下文大小的文本需要被截断,如果截断的文本包含关键信息,可能会导致性能下降;在这种情况下,看起来这不会是一个问题。
现在让我们弄清楚如何将这些原始文本转换为适合变形金刚!当我们这样做时,让我们也重置数据集的输出格式,因为我们不再需要该DataFrame 格式:
emotions.reset_format()从文本到标记
像 DistilBERT 这样的 Transformer 模型不能接收原始字符串作为输入;相反,他们假设文本已被标记并编码为数字向量。标记化是将字符串分解为模型中使用的原子单元的步骤。可以采用多种标记化策略,通常从语料库中学习将单词优化为子单元的方法。在查看用于 DistilBERT 的分词器之前,让我们考虑两种极端情况:字符和单词分词。
字符标记化
最简单的标记化方案是将每个字符单独提供给模型。在 Python 中,str对象实际上是引擎盖下的数组,这使我们只需一行代码即可快速实现字符级标记化:
text = "Tokenizing text is a core task of NLP."
tokenized_text = list(text)
print(tokenized_text)['T','o','k','e','n','i','z','i','n','g','','t','e ', 'x', 't', ' ', 'i'、's'、''、'a'、''、'c'、'o'、'r'、'e'、''、't'、'a'、's'、' k', '', 'o', 'f'、''、'N'、'L'、'P'、'.']
这是一个好的开始,但我们还没有完成。我们的模型期望将每个字符转换为整数,这个过程有时称为 数值化。一种简单的方法是使用唯一整数对每个唯一标记(在本例中为字符)进行编码:
token2idx = {ch: idx for idx, ch in enumerate(sorted(set(tokenized_text)))}
print(token2idx){'': 0, '.': 1, 'L': 2, 'N': 3, 'P': 4, 'T': 5, 'a': 6, 'c': 7, 'e ':8,'f':9,
'g':10,'i':11,'k':12,'n':13,'o':14,'r':15,'s':16,'t':17,'x ': 18,
'z': 19}
这为我们提供了从词汇表中的每个字符到唯一整数的映射。我们现在可以使用token2idx将标记化的文本转换为整数列表:
input_ids = [token2idx[token] for token in tokenized_text]
print(input_ids)[5, 14, 12, 8, 13, 11, 19, 11, 13, 10, 0, 17, 8, 18, 17, 0, 11, 16, 0, 6, 0, 7, 14, 15, 8, 0, 17, 6, 16, 12, 0, 14, 9, 0, 3, 2, 4, 1]
现在,每个标记都已映射到一个唯一的数字标识符(因此命名为input_ids)。最后一步是转换input_ids为 one-hot 向量的 2D 张量。One-hot 向量经常在机器学习中用于对分类数据进行编码,这些数据可以是有序的也可以是名义的。例如,假设我们想要对变形金刚电视剧中的角色名称进行编码。一种方法是将每个名称映射到一个唯一的 ID,如下所示:
categorical_df = pd.DataFrame(
{"Name": ["Bumblebee", "Optimus Prime", "Megatron"], "Label ID": [0,1,2]})
categorical_df| Name | Label ID | |
|---|---|---|
| 0 | Bumblebee | 0 |
| 1 | Optimus Prime | 1 |
| 2 | Megatron | 2 |
这种方法的问题在于它在名称之间创建了一个虚构的顺序,而神经网络非常擅长学习这些类型的关系。因此,我们可以为每个类别创建一个新列,并在类别为真时分配 1,否则分配 0。在 Pandas 中,这可以通过get_dummies() 如下函数实现:
pd.get_dummies(categorical_df["Name"])| Bumblebee | Megatron | Optimus Prime | |
|---|---|---|---|
| 0 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 |
| 2 | 0 | 1 | 0 |
它的行DataFrame是 one-hot 向量,它有一个“热”条目,在其他任何地方都有一个 1 和 0。现在,看看我们的input_ids,我们有一个类似的问题:元素创建了一个序数比例。这意味着添加或减去两个 ID 是无意义的操作,因为结果是代表另一个随机令牌的新 ID。
另一方面,添加两个 one-hot 编码的结果可以很容易地解释:两个“hot”条目表示相应的标记同时出现。input_ids我们可以通过转换为张量并应用 如下函数在 PyTorch 中创建 one-hot 编码one_hot():
import torch
import torch.nn.functional as F
input_ids = torch.tensor(input_ids)
one_hot_encodings = F.one_hot(input_ids, num_classes=len(token2idx))
one_hot_encodings.shapetorch.Size([38, 20])
对于 38 个输入标记中的每一个,我们现在都有一个 20 维的 one-hot 向量,因为我们的词汇表由 20 个唯一字符组成。
警告
始终
num_classes在one_hot()函数中进行设置很重要,否则 one-hot 向量最终可能会比词汇表的长度短(并且需要手动填充零)。在 TensorFlow 中,等效函数是tf.one_hot(),其中depth参数扮演 的角色num_classes。
通过检查第一个向量,我们可以验证 1 出现在 指示的位置input_ids[0]:
print(f"Token: {tokenized_text[0]}")
print(f"Tensor index: {input_ids[0]}")
print(f"One-hot: {one_hot_encodings[0]}")Token: T Tensor index: 5 One-hot: tensor([0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
从我们的简单示例中,我们可以看到字符级标记化忽略了文本中的任何结构,并将整个字符串视为字符流。尽管这有助于处理拼写错误和稀有单词,但主要缺点是需要从数据中学习单词等语言结构。这需要大量的计算、内存和数据。出于这个原因,字符标记化在实践中很少使用。相反,在标记化步骤期间会保留文本的某些结构。词标记化是实现这一目标的一种直接方法,所以让我们来看看它是如何工作的。
词标记化
我们可以将文本拆分为单词并将每个单词映射为一个整数,而不是将文本拆分为字符。从一开始就使用单词可以使模型跳过从字符中学习单词的步骤,从而降低训练过程的复杂性。
一类简单的词标记器使用空格来标记文本。我们可以通过将 Python 的split()函数直接应用于原始文本来做到这一点(就像我们测量推文长度一样)
tokenized_text = text.split()
print(tokenized_text)['tokenizing', 'text', 'is', 'a', 'core', 'task', 'of', 'NLP.']
从这里我们可以采取与字符标记器相同的步骤将每个单词映射到一个 ID。但是,我们已经可以看到这种标记化方案的一个潜在问题:没有考虑标点符号,因此NLP.被视为单个标记。鉴于单词可能包括偏角、变位或拼写错误,词汇量很容易增长到数百万!
笔记
一些词标记器对标点符号有额外的规则。还可以应用词干或词形还原,将词规范化到词干(例如,“great”、“greater”和“greatest”都变成“great”),代价是丢失文本中的一些信息。
拥有大量词汇是一个问题,因为它需要神经网络具有大量参数。为了说明这一点,假设我们有 100 万个唯一词,并且想要在我们的神经网络的第一层中将 100 万维输入向量压缩为 1000 维向量。这是大多数 NLP 架构中的标准步骤,第一层的最终权重矩阵将包含 100 万 × 1000 = 10 亿个权重。这已经可以与最大的 GPT-2 模型相媲美了,4总共有大约 15 亿个参数!
自然地,我们希望避免在模型参数上如此浪费,因为模型的训练成本很高,而且更大的模型更难维护。一种常见的方法是通过考虑语料库中最常见的 100,000 个单词来限制词汇并丢弃稀有单词。不属于词汇表的单词被归类为“未知”并映射到共享UNK标记。这意味着我们在词标记化过程中丢失了一些潜在的重要信息,因为模型没有关于与 相关的词的信息UNK。
如果在保留所有输入信息和一些输入结构的字符和单词标记化之间进行折衷,那不是很好 吗?有:子词标记化。
子词标记化
子词标记化背后的基本思想是结合字符和词标记化的最佳方面。一方面,我们希望将稀有词拆分为更小的单元,以使模型能够处理复杂的单词和拼写错误。另一方面,我们希望将常用词保留为唯一实体,以便我们可以将输入的长度保持在可管理的大小。子词 标记化(以及词标记化)的主要区别特征是它是使用统计规则和算法的组合从预训练语料库中学习的。
NLP 中有几种常用的子词标记化算法,但让我们从BERT 和 DistilBERT 标记器使用的WordPiece 5开始。了解 WordPiece 工作原理的最简单方法是查看它的实际运行情况。
Transformers 提供了一个方便的 AutoTokenizer类,允许您快速加载与预训练模型关联的分词器——我们只需调用它的from_pretrained() 方法,提供 Hub 上模型的 ID 或本地文件路径。让我们从为 DistilBERT 加载分词器开始:
from transformers import AutoTokenizer
model_ckpt = "distilbert-base-uncased"
tokenizer = AutoTokenizer.from_pretrained(model_ckpt)该类AutoTokenizer属于一组更大的 “自动”类,其工作是从检查点的名称中自动检索模型的配置、预训练的权重或词汇表。这允许您在模型之间快速切换,但如果您希望手动加载特定类,您也可以这样做。例如,我们可以按如下方式加载 DistilBERT 分词器:
from transformers import DistilBertTokenizer
distilbert_tokenizer = DistilBertTokenizer.from_pretrained(model_ckpt)笔记
当您
AutoTokenizer.from_pretrained()第一次运行该方法时,您将看到一个进度条,显示预训练标记器的哪些参数是从 Hugging Face Hub 加载的。当你第二次运行代码时,它会从缓存中加载分词器,通常在~/.cache/huggingface。
让我们通过简单的“标记文本是 NLP 的核心任务”来检查这个标记器是如何工作的。示例文本:
encoded_text = tokenizer(text)
print(encoded_text){'input_ids': [101, 19204, 6026, 3793, 2003, 1037, 4563, 4708, 1997, 17953,
2361, 1012, 102], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
与字符标记化一样,我们可以看到单词已映射到input_ids字段中的唯一整数。attention_mask我们将在下一节讨论该字段的作用。现在我们有了input_ids,我们可以使用标记器的方法将它们转换回标记 convert_ids_to_tokens():
tokens = tokenizer.convert_ids_to_tokens(encoded_text.input_ids)
print(tokens)['[CLS]', 'token', '##izing', 'text', 'is', 'a', 'core', 'task', 'of', 'nl', '##p', '.', '[SEP]']
我们可以在这里观察到三件事。首先,在序列的开头和结尾添加了一些特殊的[CLS]和 [SEP]标记。这些标记因模型而异,但它们的主要作用是指示序列的开始和结束。其次,每个标记都被小写,这是这个特定检查点的一个特征。最后,我们可以看到“tokenizing”和“NLP”被分成了两个token,这是有道理的,因为它们不是常用词。##izing和##p中的## 前缀表示前面的字符串不是空格;当您将标记转换回字符串时,任何具有此前缀的标记都应与前一个标记合并。AutoTokenizer该类 有一个方法convert_tokens_to_string()可以做到这一点,所以让我们将它应用于我们的令牌:
print(tokenizer.convert_tokens_to_string(tokens))[CLS] tokenizing text is a core task of nlp. [SEP]
该类AutoTokenizer还具有几个提供有关标记器信息的属性。例如,我们可以检查词汇量:
tokenizer.vocab_size30522
以及相应模型的最大上下文大小:
tokenizer.model_max_length512
另一个需要了解的有趣属性是模型在其前向传递中期望的字段名称:
tokenizer.model_input_names['input_ids', 'attention_mask']
现在我们对单个字符串的标记化过程有了基本的了解,让我们看看如何标记整个数据集!
警告
使用预训练模型时,确保使用与训练模型相同的标记器非常重要。从模型的角度来看,切换分词器就像打乱词汇表一样。如果您周围的每个人都开始将 “house”之类的随机词替换为“cat”,那么您也很难理解发生了什么!
标记整个数据集
为了标记整个语料库,我们将使用对象的map()方法DatasetDict。我们将在本书中多次遇到这种方法,因为它提供了一种将处理函数应用于数据集中每个元素的便捷方法。我们很快就会看到,该map()方法也可以用来创建新的行和列。
首先,我们需要一个处理函数来标记我们的示例:
def tokenize(batch):
return tokenizer(batch["text"], padding=True, truncation=True)该函数将分词器应用于一批示例; padding=True将用零填充示例到批处理中最长示例的大小,并将truncation=True示例截断为模型的最大上下文大小。为了查看tokenize()实际效果,让我们从训练集中传递一批两个示例:
print(tokenize(emotions["train"][:2])){'input_ids': [[101, 1045, 2134, 2102, 2514, 26608, 102, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0], [101, 1045, 2064, 2175, 2013, 3110, 2061, 20625, 2000,
2061, 9636, 17772, 2074, 2013, 2108, 2105, 2619, 2040, 14977, 1998, 2003, 8300,
102]], 'attention_mask': [[1, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0], [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1,
1, 1]]}
在这里我们可以看到填充的结果: 的第一个元素input_ids 比第二个短,所以在那个元素上添加了零,使它们的长度相同。这些零在词汇表中有对应[PAD] 的记号,特殊记号的集合还包括我们之前遇到的 [CLS]和[SEP]记号:
| Special Token | [PAD] | [UNK] | [CLS] | [SEP] | [MASK] |
|---|---|---|---|---|---|
| Special Token ID | 0 | 100 | 101 | 102 | 103 |
另请注意,除了将编码的推文返回为 之外 input_ids,标记器还会返回一个attention_mask数组列表。这是因为我们不希望模型被额外的填充标记混淆:注意掩码允许模型忽略输入的填充部分。图 2-3提供了如何填充输入 ID 和注意掩码的可视化解释。
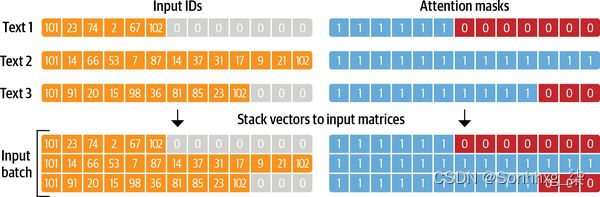
图 2-3。对于每个批次,输入序列被填充到批次中的最大序列长度;注意掩码在模型中用于忽略输入张量的填充区域
一旦我们定义了一个处理函数,我们就可以在一行代码中将它应用于语料库中的所有拆分:
emotions_encoded = emotions.map(tokenize, batched=True, batch_size=None)默认情况下,该map()方法对语料库中的每个示例单独操作,因此设置batched=True将对推文进行批量编码。因为我们已经设置batch_size=None了 ,所以我们的tokenize() 函数将作为一个批次应用于整个数据集。这确保了输入张量和注意力掩码在全局范围内具有相同的形状,我们可以看到这个操作已经向数据集添加了新的input_ids 和attention_mask列:
print(emotions_encoded["train"].column_names)['attention_mask', 'input_ids', 'label', 'text']
笔记
在后面的章节中,我们将看到如何使用数据整理器来动态填充每批中的张量。全局填充将在下一节中派上用场,我们从整个语料库中提取特征矩阵。
训练文本分类器
如第 1 章所述,像 DistilBERT 这样的模型经过预训练,可以预测文本序列中的掩码单词。但是,我们不能直接使用这些语言模型进行文本分类;我们需要稍微修改它们。为了了解哪些修改是必要的,让我们看一下基于编码器的模型(如 DistilBERT)的架构,如图 2-4 所示。
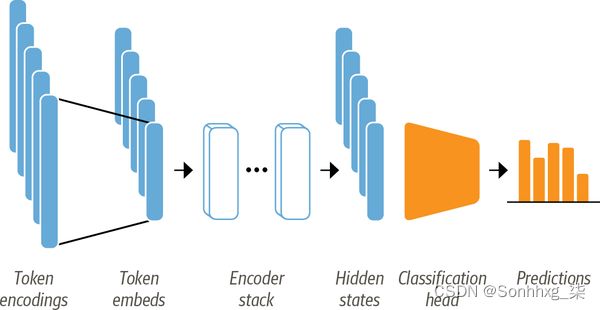
图 2-4。用于使用基于编码器的转换器进行序列分类的架构;它由模型的预训练主体和自定义分类头组成
首先,文本被标记化并表示为称为 标记编码的单热向量。标记器词汇的大小决定了标记编码的维度,它通常由 20k–200k 个唯一标记组成。接下来,这些标记编码被转换为标记嵌入,它们是生活在低维空间中的向量。然后,令牌嵌入通过编码器块层传递,以产生每个输入令牌的隐藏状态。对于语言建模的预训练目标,6每个隐藏状态都被馈送到一个预测掩码输入标记的层。对于分类任务,我们将语言建模层替换为分类层。
笔记
在实践中,PyTorch 跳过了为令牌编码创建 one-hot 向量的步骤,因为将矩阵与 one-hot 向量相乘与从矩阵中选择一列相同。这可以通过从矩阵中获取具有标记 ID 的列来直接完成。当我们使用
nn.Embedding类时,我们将在第 3 章看到这一点。
我们有两种选择可以在 Twitter 数据集上训练这样的模型:
特征提取
我们使用隐藏状态作为特征,只在它们上训练一个分类器,而不修改预训练模型。
微调
我们端到端地训练整个模型,这也更新了预训练模型的参数。
在以下部分中,我们将探讨 DistilBERT 的两个选项并检查它们的权衡。
变形金刚作为特征提取器
使用转换器作为特征提取器相当简单。如图 2-5所示 ,我们在训练过程中冻结了身体的权重,并使用隐藏状态作为分类器的特征。这种方法的优点是我们可以快速训练一个小的或浅的模型。这样的模型可以是神经分类层或不依赖梯度的方法,例如随机森林。如果 GPU 不可用,这种方法特别方便,因为隐藏状态只需要预先计算一次。
图 2-5。在基于特征的方法中,DistilBERT 模型被冻结,只为分类器提供特征
使用预训练模型
我们将使用 Transformers 中另一个方便的自动类,称为AutoModel. 与AutoTokenizer该类类似, AutoModel具有from_pretrained()加载预训练模型权重的方法。让我们使用这个方法来加载 DistilBERT 检查点
from transformers import AutoModel
model_ckpt = "distilbert-base-uncased"
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = AutoModel.from_pretrained(model_ckpt).to(device)在这里,我们使用 PyTorch 检查 GPU 是否可用,然后将 PyTorchnn.Module.to()方法链接到模型加载器。如果我们有一个,这可以确保模型将在 GPU 上运行。如果没有,模型将在 CPU 上运行,这可能会慢得多。
该类AutoModel将令牌编码转换为嵌入,然后通过编码器堆栈将它们输入以返回隐藏状态。让我们看看如何从我们的语料库中提取这些状态。
框架之间的互操作性
尽管本书中的代码大部分是用 PyTorch 编写的Transformers 提供了与 TensorFlow 和 JAX 的紧密互操作性。这意味着您只需更改几行代码即可在您喜欢的深度学习框架中加载预训练模型!例如,我们可以使用TFAutoModel如下类在 TensorFlow 中加载 DistilBERT
from transformers import TFAutoModel
tf_model = TFAutoModel.from_pretrained(model_ckpt)当模型仅在一个框架中发布但您想在另一个框架中使用它时,这种互操作性特别有用。例如, 我们将在第 4 章中遇到的XLM-RoBERTa 模型只有 PyTorch 权重,所以如果你尝试像之前一样在 TensorFlow 中加载它
tf_xlmr = TFAutoModel.from_pretrained("xlm-roberta-base")你会得到一个错误。在这些情况下,您可以为函数指定一个 from_pt=True参数TfAutoModel.from_pretrained(),该库将自动为您下载并转换 PyTorch 权重
tf_xlmr = TFAutoModel.from_pretrained("xlm-roberta-base", from_pt=True)如您所见,在 Transformers 中的框架之间切换非常简单!在大多数情况下,您只需在类中添加“TF”前缀,您将获得等效的 TensorFlow 2.0 类。当我们使用"pt"字符串时(例如,在下一节中),它是 PyTorch 的缩写,只需将其替换为 " tf",它是 TensorFlow 的缩写。
提取最后的隐藏状态
为了热身,让我们检索单个字符串的最后隐藏状态。我们需要做的第一件事是对字符串进行编码并将标记转换为 PyTorch 张量。这可以通过向 return_tensors="pt"标记器提供参数来完成,如下所示
text = "this is a test"
inputs = tokenizer(text, return_tensors="pt")
print(f"Input tensor shape: {inputs['input_ids'].size()}")Input tensor shape: torch.Size([1, 6])
如我们所见,生成的张量具有形状 [batch_size, n_tokens]。现在我们将编码作为张量,最后一步是将它们放在与模型相同的设备上,并按如下方式传递输入
inputs = {k:v.to(device) for k,v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
print(outputs)BaseModelOutput(last_hidden_state=tensor([[[-0.1565, -0.1862, 0.0528, ...,
-0.1188, 0.0662, 0.5470],
[-0.3575, -0.6484, -0.0618, ..., -0.3040, 0.3508, 0.5221],
[-0.2772, -0.4459, 0.1818, ..., -0.0948, -0.0076, 0.9958],
[-0.2841, -0.3917, 0.3753, ..., -0.2151, -0.1173, 1.0526],
[ 0.2661, -0.5094, -0.3180, ..., -0.4203, 0.0144, -0.2149],
[ 0.9441, 0.0112, -0.4714, ..., 0.1439, -0.7288, -0.1619]]],
device='cuda:0'), hidden_states=None, attentions=None)
在这里,我们使用了torch.no_grad()上下文管理器来禁用梯度的自动计算。这对于推理很有用,因为它减少了计算的内存占用。根据模型配置,输出可以包含多个对象,例如隐藏状态、损失或注意,它们排列在类似于namedtuplePython 中的 a 的类中。在我们的示例中,模型输出是 的一个实例BaseModelOutput,我们可以简单地通过名称访问其属性。当前模型只返回一个属性,也就是最后一个隐藏状态,所以让我们检查一下它的形状:
outputs.last_hidden_state.size()torch.Size([1, 6, 768])
查看隐藏状态张量,我们看到它的形状为 [batch_size, n_tokens, hidden_dim]。换句话说,为 6 个输入标记中的每一个返回一个 768 维向量。对于分类任务,通常的做法是仅使用与[CLS]令牌相关的隐藏状态作为输入特征。由于这个标记出现在每个序列的开头,我们可以通过简单的索引来提取它, outputs.last_hidden_state如下所示:
outputs.last_hidden_state[:,0].size()torch.Size([1, 768])
现在我们知道了如何获取单个字符串的最后一个隐藏状态;hidden_state让我们通过创建一个存储所有这些向量的新列来对整个数据集做同样的事情。正如我们对分词器所做的那样,我们将使用 的map()方法DatasetDict 一次性提取所有隐藏状态。我们需要做的第一件事是将前面的步骤包装在一个处理函数中
def extract_hidden_states(batch):
# Place model inputs on the GPU
inputs = {k:v.to(device) for k,v in batch.items()
if k in tokenizer.model_input_names}
# Extract last hidden states
with torch.no_grad():
last_hidden_state = model(**inputs).last_hidden_state
# Return vector for [CLS] token
return {"hidden_state": last_hidden_state[:,0].cpu().numpy()}这个函数和我们之前的逻辑的唯一区别是最后一步,我们将最终的隐藏状态作为 NumPy 数组放回 CPU。map()当我们使用批量输入时,该方法需要处理函数返回 Python 或 NumPy 对象。
由于我们的模型期望张量作为输入,接下来要做的是将input_ids和attention_mask列转换为"torch" 格式,如下所示
emotions_encoded.set_format("torch",
columns=["input_ids", "attention_mask", "label"])然后我们可以继续并一次性提取所有拆分中的隐藏状态
emotions_hidden = emotions_encoded.map(extract_hidden_states, batched=True)请注意,在这种情况下我们没有设置batch_size=None,这意味着使用默认值batch_size=1000来代替。正如预期的那样,应用该 extract_hidden_states()函数已向hidden_state我们的数据集添加了一个新列:
emotions_hidden["train"].column_names['attention_mask', 'hidden_state', 'input_ids', 'label', 'text']
现在我们已经有了与每条推文相关的隐藏状态,下一步是在它们上训练一个分类器。为此,我们需要一个特征矩阵——让我们来看看。
创建特征矩阵
预处理的数据集现在包含我们训练分类器所需的所有信息。我们将使用隐藏状态作为输入特征,使用标签作为目标。我们可以很容易地以众所周知的 Scikit-learn 格式创建相应的数组,如下所示
import numpy as np
X_train = np.array(emotions_hidden["train"]["hidden_state"])
X_valid = np.array(emotions_hidden["validation"]["hidden_state"])
y_train = np.array(emotions_hidden["train"]["label"])
y_valid = np.array(emotions_hidden["validation"]["label"])
X_train.shape, X_valid.shape((16000, 768), (2000, 768))
在我们在隐藏状态上训练模型之前,最好进行快速检查以确保它们提供了我们想要分类的情绪的有用表示。在下一节中,我们将看到可视化功能如何提供实现此目的的快速方法。
可视化训练集
由于在 768 维中可视化隐藏状态至少可以说是很棘手,我们将使用强大的 UMAP 算法将向量向下投影到 2D。7 由于当特征被缩放到位于 [0,1] 区间时 UMAP 效果最好,我们将首先应用 aMinMaxScaler然后使用umap-learn库中的 UMAP 实现来减少隐藏状态
from umap import UMAP
from sklearn.preprocessing import MinMaxScaler
# Scale features to [0,1] range
X_scaled = MinMaxScaler().fit_transform(X_train)
# Initialize and fit UMAP
mapper = UMAP(n_components=2, metric="cosine").fit(X_scaled)
# Create a DataFrame of 2D embeddings
df_emb = pd.DataFrame(mapper.embedding_, columns=["X", "Y"])
df_emb["label"] = y_train
df_emb.head()| X | Y | label | |
|---|---|---|---|
| 0 | 4.358075 | 6.140816 | 0 |
| 1 | -3.134567 | 5.329446 | 0 |
| 2 | 5.152230 | 2.732643 | 3 |
| 3 | -2.519018 | 3.067250 | 2 |
| 4 | -3.364520 | 3.356613 | 3 |
结果是一个具有相同数量训练样本的数组,但只有 2 个特征,而不是我们开始时的 768 个!让我们进一步研究压缩数据并分别绘制每个类别的点密度
fig, axes = plt.subplots(2, 3, figsize=(7,5))
axes = axes.flatten()
cmaps = ["Greys", "Blues", "Oranges", "Reds", "Purples", "Greens"]
labels = emotions["train"].features["label"].names
for i, (label, cmap) in enumerate(zip(labels, cmaps)):
df_emb_sub = df_emb.query(f"label == {i}")
axes[i].hexbin(df_emb_sub["X"], df_emb_sub["Y"], cmap=cmap,
gridsize=20, linewidths=(0,))
axes[i].set_title(label)
axes[i].set_xticks([]), axes[i].set_yticks([])
plt.tight_layout()
plt.show()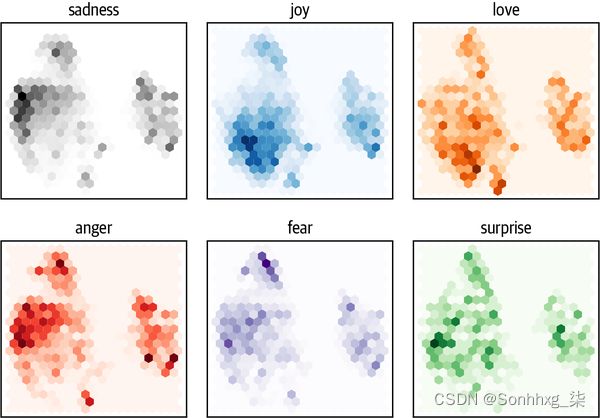
笔记
这些只是对低维空间的投影。仅仅因为某些类别重叠并不意味着它们在原始空间中不可分离。相反,如果它们在投影空间中是可分离的,那么它们在原始空间中也是可分离的。
sadness从这个图中我们可以看到一些清晰的模式: 、anger和等负面情绪fear都占据相似的区域,但分布略有不同。另一方面,joy又love与负面情绪很好地分开,也共享一个相似的空间。最后,surprise散落一地。尽管我们可能希望有一些分离,但这并不能保证,因为模型没有经过训练来了解这些情绪之间的差异。它只是通过猜测文本中的蒙面词来隐式地学习它们。
现在我们已经对数据集的特征有了一些了解,让我们最终训练一个模型吧!
训练一个简单的分类器
我们已经看到情绪之间的隐藏状态有些不同,尽管其中一些情绪没有明显的界限。让我们使用这些隐藏状态来使用 Scikit-learn 训练逻辑回归模型。训练这样一个简单的模型很快并且不需要 GPU
from sklearn.linear_model import LogisticRegression
# We increase `max_iter` to guarantee convergence
lr_clf = LogisticRegression(max_iter=3000)
lr_clf.fit(X_train, y_train)
lr_clf.score(X_valid, y_valid)0.633
从准确性来看,我们的模型似乎比随机模型好一点——但由于我们正在处理一个不平衡的多类数据集,它实际上要好得多。我们可以通过将它与一个简单的基线进行比较来检查我们的模型是否有任何好处。在 Scikit-learn 中有一个 DummyClassifier可用于构建具有简单启发式的分类器的分类器,例如始终选择多数类或始终绘制随机类。在这种情况下,表现最好的启发式方法是始终选择最频繁的类,这会产生大约 35% 的准确度
from sklearn.dummy import DummyClassifier
dummy_clf = DummyClassifier(strategy="most_frequent")
dummy_clf.fit(X_train, y_train)
dummy_clf.score(X_valid, y_valid)0.352
因此,我们带有 DistilBERT 嵌入的简单分类器明显优于我们的基线。我们可以通过查看分类器的混淆矩阵来进一步研究模型的性能,它告诉我们真实标签和预测标签之间的关系
from sklearn.metrics import ConfusionMatrixDisplay, confusion_matrix
def plot_confusion_matrix(y_preds, y_true, labels):
cm = confusion_matrix(y_true, y_preds, normalize="true")
fig, ax = plt.subplots(figsize=(6, 6))
disp = ConfusionMatrixDisplay(confusion_matrix=cm, display_labels=labels)
disp.plot(cmap="Blues", values_format=".2f", ax=ax, colorbar=False)
plt.title("Normalized confusion matrix")
plt.show()
y_preds = lr_clf.predict(X_valid)
plot_confusion_matrix(y_preds, y_valid, labels)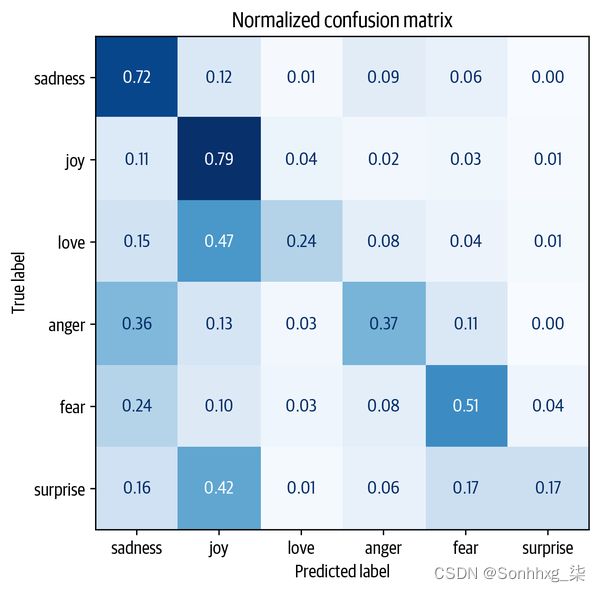
我们可以看到这一点,anger并且fear经常与 混淆 sadness,这与我们在可视化嵌入时所做的观察一致。此外,love并且surprise经常被误认为 joy.
在下一节中,我们将探讨微调方法,它可以带来出色的分类性能。但是,重要的是要注意,这样做需要更多的计算资源,例如 GPU,而这些资源在您的组织中可能不可用。在这种情况下,基于特征的方法可能是传统机器学习和深度学习之间的一个很好的折衷方案。
微调Transformers
现在让我们探索端到端微调变压器需要什么。通过微调方法,我们不使用隐藏状态作为固定特征,而是训练它们, 如图 2-6所示。这就要求分类头是可微的,这也是为什么这种方法通常使用神经网络进行分类的原因。
图 2-6。当使用微调方法时,整个 DistilBERT 模型与分类头一起训练
训练作为分类模型输入的隐藏状态将帮助我们避免处理可能不太适合分类任务的数据的问题。相反,初始隐藏状态会在训练期间适应以减少模型损失,从而提高其性能。
我们将使用 Transformers 的TrainerAP来简化训练循环。让我们看看我们需要设置的成分!
加载预训练模型
我们需要的第一件事是一个预训练的 DistilBERT 模型,就像我们在基于特征的方法中使用的模型一样。唯一的轻微修改是我们使用AutoModelForSequenceClassification模型而不是 AutoModel. 不同之处在于该 AutoModelForSequenceClassification模型在预训练模型输出之上有一个分类头,可以很容易地使用基本模型进行训练。我们只需要指定模型必须预测多少标签(在我们的例子中是六个),因为这决定了分类头的输出数量
from transformers import AutoModelForSequenceClassification
num_labels = 6
model = (AutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels)
.to(device))您将看到模型的某些部分被随机初始化的警告。这 是正常的,因为尚未训练分类头。下一步是定义我们将在 微调期间用于评估模型性能的指标。
定义性能指标
要在训练期间监控指标,我们需要 compute_metrics()为Trainer. 此函数接收一个EvalPrediction对象(它是一个具有predictions 和label_ids属性的命名元组)并需要返回一个字典,该字典将每个度量的名称映射到它的值。对于我们的应用程序,我们将计算F 1分数和模型的准确度,如下所示
from sklearn.metrics import accuracy_score, f1_score
def compute_metrics(pred):
labels = pred.label_ids
preds = pred.predictions.argmax(-1)
f1 = f1_score(labels, preds, average="weighted")
acc = accuracy_score(labels, preds)
return {"accuracy": acc, "f1": f1}准备好数据集和指标后,在定义类之前,我们只需要处理最后两件事Trainer:
-
在 Hugging Face Hub 上登录我们的帐户。这将使我们能够将微调后的模型推送到我们在 Hub 上的帐户并与社区共享。
-
定义训练运行的所有超参数。
我们将在下一节中处理这些步骤。
训练模型
如果您在 Jupyter 笔记本中运行此代码,则可以使用以下帮助函数登录到 Hub
from huggingface_hub import notebook_login
notebook_login()这将显示一个小部件,您可以在其中输入您的用户名和密码,或具有写入权限的访问令牌。您可以在Hub 文档中找到有关如何创建访问令牌的详细信息。如果您在终端中工作,则可以通过运行以下命令登录:
$ huggingface-cli login为了定义训练参数,我们使用TrainingArguments类。这个类存储了很多信息,让你可以对训练和评估进行细粒度的控制。要指定的最重要的参数是output_dir,它是所有训练工件的存储位置。这是一个TrainingArguments充满荣耀的例子:
from transformers import Trainer, TrainingArguments
batch_size = 64
logging_steps = len(emotions_encoded["train"]) // batch_size
model_name = f"{model_ckpt}-finetuned-emotion"
training_args = TrainingArguments(output_dir=model_name,
num_train_epochs=2,
learning_rate=2e-5,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
weight_decay=0.01,
evaluation_strategy="epoch",
disable_tqdm=False,
logging_steps=logging_steps,
push_to_hub=True,
log_level="error")在这里,我们还设置了批量大小、学习率和 epoch 数,并指定在训练运行结束时加载最佳模型。有了这个最终成分,我们可以使用以下方法实例化和微调我们的模型Trainer
| Epoch | Training Loss | Validation Loss | Accuracy | F1 |
|---|---|---|---|---|
| 1 | 0.840900 | 0.327445 | 0.896500 | 0.892285 |
| 2 | 0.255000 | 0.220472 | 0.922500 | 0.922550 |
查看日志,我们可以看到我们的模型在验证集上的 F 1分数约为 92%——这是对基于特征的方法的显着改进!
我们可以通过计算混淆矩阵来更详细地查看训练指标。为了可视化混淆矩阵,我们首先需要获得对验证集的预测。该类的predict()方法Trainer返回几个我们可以用于评估的有用对象
preds_output = trainer.predict(emotions_encoded["validation"])该predict()方法的输出是一个PredictionOutput对象,其中包含 和 的数组,predictions以及label_ids我们传递给训练器的指标。例如,验证集上的指标可以按如下方式访问:
preds_output.metrics{'test_loss': 0.22047173976898193,
'test_accuracy':0.9225,
'test_f1':0.9225500751072866,
'test_runtime':1.6357,
'test_samples_per_second':1222.725,
'test_steps_per_second':19.564}
它还包含每个类的原始预测。我们可以使用贪婪地解码预测np.argmax()。这会产生预测的标签,并且与 Scikit-learn 模型在基于特征的方法中返回的标签具有相同的格式
y_preds = np.argmax(preds_output.predictions, axis=1)通过预测,我们可以再次绘制混淆矩阵:
plot_confusion_matrix(y_preds, y_valid, labels)
这更接近于理想的对角混淆矩阵。该love 类别仍然经常与 混淆joy,这似乎很自然。 surprise也经常被误认为joy或混淆 fear。总体而言,该模型的性能似乎相当不错,但在我们收工之前,让我们更深入地了解一下我们的模型可能会犯的错误类型。
使用 KERAS 进行微调
如果您使用 TensorFlow,也可以使用 Keras API 微调您的模型。与 PyTorch API 的主要区别在于没有Trainer类,因为 Keras 模型已经提供了内置fit()方法。要了解它是如何工作的,我们首先将 DistilBERT 作为 TensorFlow 模型加载
from transformers import TFAutoModelForSequenceClassification
tf_model = (TFAutoModelForSequenceClassification
.from_pretrained(model_ckpt, num_labels=num_labels))接下来,我们将数据集转换为tf.data.Dataset 格式。因为我们已经填充了我们的标记化输入,所以我们可以通过将to_tf_dataset()方法应用于 emotions_encoded
# The column names to convert to TensorFlow tensors
tokenizer_columns = tokenizer.model_input_names
tf_train_dataset = emotions_encoded["train"].to_tf_dataset(
columns=tokenizer_columns, label_cols=["label"], shuffle=True,
batch_size=batch_size)
tf_eval_dataset = emotions_encoded["validation"].to_tf_dataset(
columns=tokenizer_columns, label_cols=["label"], shuffle=False,
batch_size=batch_size)在这里,我们还对训练集进行了洗牌,并为其定义了批量大小和验证集。最后要做的是编译和训练模型
import tensorflow as tf
tf_model.compile(
optimizer=tf.keras.optimizers.Adam(learning_rate=5e-5),
loss=tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True),
metrics=tf.metrics.SparseCategoricalAccuracy())
tf_model.fit(tf_train_dataset, validation_data=tf_eval_dataset, epochs=2)错误分析
在继续之前,我们应该进一步研究我们模型的预测。一种简单而强大的技术是按模型损失对验证样本进行排序。当我们在前向传递过程中传递标签时,会自动计算并返回损失。这是一个返回损失和预测标签的函数
from torch.nn.functional import cross_entropy
def forward_pass_with_label(batch):
# Place all input tensors on the same device as the model
inputs = {k:v.to(device) for k,v in batch.items()
if k in tokenizer.model_input_names}
with torch.no_grad():
output = model(**inputs)
pred_label = torch.argmax(output.logits, axis=-1)
loss = cross_entropy(output.logits, batch["label"].to(device),
reduction="none")
# Place outputs on CPU for compatibility with other dataset columns
return {"loss": loss.cpu().numpy(),
"predicted_label": pred_label.cpu().numpy()}再次使用该map()方法,我们可以应用此函数来获取所有样本的损失
# Convert our dataset back to PyTorch tensors
emotions_encoded.set_format("torch",
columns=["input_ids", "attention_mask", "label"])
# Compute loss values
emotions_encoded["validation"] = emotions_encoded["validation"].map(
forward_pass_with_label, batched=True, batch_size=16)最后,我们DataFrame使用文本、损失和预测/真实标签创建一个
emotions_encoded.set_format("pandas")
cols = ["text", "label", "predicted_label", "loss"]
df_test = emotions_encoded["validation"][:][cols]
df_test["label"] = df_test["label"].apply(label_int2str)
df_test["predicted_label"] = (df_test["predicted_label"]
.apply(label_int2str))我们现在可以轻松地emotions_encoded按升序或降序对损失进行排序。本练习的目标是检测以下情况之一:
错误的标签
每个为数据添加标签的过程都可能存在缺陷。注释者可能会犯错误或不同意,而从其他特征推断出的标签可能是错误的。如果自动注释数据很容易,那么我们就不需要模型来做到这一点。因此,有一些错误标记的示例是正常的。通过这种方法,我们可以快速找到并纠正它们。
数据集的怪癖
现实世界中的数据集总是有点混乱。处理文本时,输入中的特殊字符或字符串会对模型的预测产生重大影响。检查模型最弱的预测可以帮助识别这些特征,清理数据或注入类似的例子可以使模型更加健壮。
我们先来看看损失最高的数据样本
df_test.sort_values("loss", ascending=False).head(10)| text | label | predicted_label | loss |
|---|---|---|---|
| i feel that he was being overshadowed by the supporting characters | love | sadness | 5.704531 |
| i called myself pro life and voted for perry without knowing this information i would feel betrayed but moreover i would feel that i had betrayed god by supporting a man who mandated a barely year old vaccine for little girls putting them in danger to financially support people close to him | joy | sadness | 5.484461 |
| i guess i feel betrayed because i admired him so much and for someone to do this to his wife and kids just goes beyond the pale | joy | sadness | 5.434768 |
| i feel badly about reneging on my commitment to bring donuts to the faithful at holy family catholic church in columbus ohio | love | sadness | 5.257482 |
| i as representative of everything thats wrong with corporate america and feel that sending him to washington is a ludicrous idea | surprise | sadness | 4.827708 |
| i guess this is a memoir so it feels like that should be fine too except i dont know something about such a deep amount of self absorption made me feel uncomfortable | joy | fear | 4.713047 |
| i am going to several holiday parties and i can t wait to feel super awkward i am going to several holiday parties and i can t wait to feel super awkward a href http badplaydate | joy | sadness | 4.704955 |
| i felt ashamed of these feelings and was scared because i knew that something wrong with me and thought i might be gay | fear | sadness | 4.656096 |
| i guess we would naturally feel a sense of loneliness even the people who said unkind things to you might be missed | anger | sadness | 4.593202 |
| im lazy my characters fall into categories of smug and or blas people and their foils people who feel inconvenienced by smug and or blas people | joy | fear | 4.311287 |
我们可以清楚地看到模型错误地预测了一些标签。另一方面,似乎有相当多的例子没有明确的类别,它们可能被错误标记或完全需要一个新的类别。尤其joy是好几次似乎都被贴错了标签。有了这些信息,我们可以优化数据集,这通常可以带来与拥有更多数据或更大模型一样大的性能提升(或更多)!
sadness在查看损失最低的样本时,我们观察到模型在预测类别时似乎最有信心。深度学习模型非常擅长发现和利用捷径来进行预测。出于这个原因,还值得花时间查看模型最有信心的示例,这样我们就可以确信模型不会不恰当地利用文本的某些特征。所以,让我们也看看损失最小的预测
df_test.sort_values("loss", ascending=True).head(10)| text | label | predicted_label | loss |
|---|---|---|---|
| i feel try to tell me im ungrateful tell me im basically the worst daughter sister in the world | sadness | sadness | 0.017331 |
| im kinda relieve but at the same time i feel disheartened | sadness | sadness | 0.017392 |
| i and feel quite ungrateful for it but i m looking forward to summer and warmth and light nights | sadness | sadness | 0.017400 |
| i remember feeling disheartened one day when we were studying a poem really dissecting it verse by verse stanza by stanza | sadness | sadness | 0.017461 |
| i feel like an ungrateful asshole | sadness | sadness | 0.017485 |
| i leave the meeting feeling more than a little disheartened | sadness | sadness | 0.017670 |
| i am feeling a little disheartened | sadness | sadness | 0.017685 |
| i feel like i deserve to be broke with how frivolous i am | sadness | sadness | 0.017888 |
| i started this blog with pure intentions i must confess to starting to feel a little disheartened lately by the knowledge that there doesnt seem to be anybody reading it | sadness | sadness | 0.017899 |
| i feel so ungrateful to be wishing this pregnancy over now | sadness | sadness | 0.017913 |
我们现在知道joy有时会被错误标记,并且模型对预测标签最有信心sadness。有了这些信息,我们可以对我们的数据集进行有针对性的改进,并密切关注模型似乎非常有信心的类。
为训练好的模型提供服务之前的最后一步是将其保存以供以后使Transformers 允许我们通过几个步骤完成此操作,我们将在下一节中向您展示。
保存和共享模型
NLP 社区从共享预训练和微调模型中受益匪浅,每个人都可以通过 Hugging Face Hub 与他人共享他们的模型。任何社区生成的模型都可以从 Hub 下载,就像我们下载 DistilBERT 模型一样。使用 TrainerAPI,保存和共享模型很简单:
trainer.push_to_hub(commit_message="Training completed!")我们还可以使用微调模型对新推文进行预测。由于我们已经将模型推送到 Hub,我们现在可以将它与pipeline()函数一起使用,就像我们在 第 1 章中所做的那样。首先,让我们加载管道
from transformers import pipeline
# Change `transformersbook` to your Hub username
model_id = "transformersbook/distilbert-base-uncased-finetuned-emotion"
classifier = pipeline("text-classification", model=model_id)然后让我们使用示例推文测试管道
custom_tweet = "I saw a movie today and it was really good."
preds = classifier(custom_tweet, return_all_scores=True)最后,我们可以在条形图中绘制每个类别的概率。显然,该模型估计最有可能的类别是joy,考虑到推文,这似乎是合理的
preds_df = pd.DataFrame(preds[0])
plt.bar(labels, 100 * preds_df["score"], color='C0')
plt.title(f'"{custom_tweet}"')
plt.ylabel("Class probability (%)")
plt.show()
结论
恭喜,您现在知道如何训练 Transformer 模型对推文中的情绪进行分类!我们已经看到了两种基于特征和微调的互补方法,并研究了它们的优缺点。
然而,这只是使用 Transformer 模型构建实际应用程序的第一步,我们还有更多内容需要介绍。以下是您在 NLP 之旅中可能遇到的挑战列表:
我的老板希望我的模型昨天投入生产!
在大多数应用程序中,您的模型不只是坐在尘土飞扬的地方——您要确保它能够提供预测!将模型推送到 Hub 时,会自动创建一个推理端点,可以使用 HTTP 请求调用该端点。如果您想了解更多信息,我们建议您查看 推理 API 的文档。
我的用户想要更快的预测!
我们已经看到了解决这个问题的一种方法:使用 DistilBERT。在 第 8 章中,我们将深入探讨知识蒸馏(DistilBERT 的创建过程),以及加速 Transformer 模型的其他技巧。
你的模型也能做 X 吗?
正如我们在本章中所提到的,变压器的用途非常广泛。在本书的其余部分,我们将探索一系列任务,例如问答和命名实体识别,所有这些任务都使用相同的基本架构。
我的文章都不是英文的!
事实证明,transformer 也有多种语言,我们将在 第 4 章中使用它们同时处理多种语言。
我没有标签!
如果可用的标记数据非常少,则可能无法进行微调。在 第 9 章中,我们将探讨一些技术来处理这种情况。
现在我们已经了解了训练和共享转换器所涉及的内容,在下一章中,我们将探索从头开始实现我们自己的转换器模型。