二叉搜索树
文章目录
- 1. 概念
- 2. 模拟实现
-
- 2.1 定义结点类
- 2.2 定义搜索二叉树类
- 2.3 构造函数
- 2.4 拷贝构造函数
- 2.3 赋值运算符重载函数
- 2.4 析构函数
- 2.5 插入函数
-
- 非递归实现
- 递归实现
- 2.6 中序遍历
- 2.7 删除函数
-
- 非递归实现
-
- 0个孩子
- 1个孩子
- 2个孩子
- 递归实现
- 2.8 查找函数
-
- 非递归实现
- 递归实现
- 3. 应用
-
- 3.1 Key模型
- 3.2 Key/Value模型
- 4. 性能
1. 概念
二叉搜索树(Binary Search Tree),也称为二叉查找树、有序二叉树(ordered binary tree)或排序二叉树(sorted binary tree),是指一棵空树或者具有下列性质的二叉树:
- 若任意节点的左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若任意节点的右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 任意节点的左、右子树也分别为二叉搜索树;

上面就是一棵二叉搜索树,每个结点的左子树的值都小于根结点的值,右子树的值都大于根结点的值。
为什么什么二叉搜索树被叫做排序二叉树?
对上图中的树进行中序遍历,得到的结果是:1、3、4、6、7、8、10、13、14。这是一个升序的数列。
本文GIF动图皆使用ScreentoGif软件在网站https://visualgo.net录制。
2. 模拟实现
2.1 定义结点类
根据二叉搜索树的定义,用二叉链表示结点的左右子树,用_key表示结点储存的值。除此之外,在类中定义一个结点的构造函数,以便new出来干净的结点是干净的。
将模板参数设置为K,意为key。
// 定义结点类
template<class K>
struct BSTreeNode
{
K _key; // 值
BSTreeNode* _left; // 左孩子结点
BSTreeNode* _right; // 右孩子结点
BSTreeNode(const K& key) // 构造函数
:_key(key)
, _left(nullptr)
, _right(nullptr)
{}
};
2.2 定义搜索二叉树类
把二叉树类把根结点私有,将各种功能函数公有。需要注意的是,像构造、析构和其他递归实现的功能函数,可以用一个子函数(用下划线标识)封装,并将子函数私有。
用typedef定义模板结点类为Node,以方便操作节点。
// 定义二叉搜索树类
template<class K>
class BSTree
{
typedef BSTreeNode<K> Node;
public:
// 构造函数
BSTree();
// 拷贝构造函数
BSTree(const BSTree<K>& t);
// 析构函数
~BSTree();
// operator= 重载
BSTree<K>& operator=(BSTree<K>& t);
// 删除函数
bool Erase(const K& key);
// 递归删除函数
bool EraseR(const K& key);
// 插入函数
bool Insert(const K& key);
// 递归插入函数
bool InsertR(const K& key);
// 查找函数
Node* Find(const K& key);
// 递归查找函数
Node* FindR(const K& key);
// 中序遍历
void InOrder();
private:
// 拷贝构造子函数
Node* _Copy(Node* root);
// 递归删除子函数
bool _EraseR(const K& key, Node* root);
// 递归插入子函数
bool _InsertR(const K& key, Node*& root);
// 递归查找子函数
Node* _FindR(const K& key, Node* root);
// 递归中序遍历子函数
void _InOrder(const Node* root);
// 析构子函数
void _Destory(Node* root);
private:
// 定义根结点
Node* _root = nullptr;
};
2.3 构造函数
对于树而言,从有到无构造一棵树只要创建一个根结点即可,即空树。
// 构造函数
BSTree()
:_root(nullptr)
{}
2.4 拷贝构造函数
拷贝构造的思路和之前一样,直接拷贝一棵一模一样的树即可。
// 拷贝构造函数
BSTree(const BSTree<K>& t)
{
_root = _Copy(t._root);
}
// 拷贝构造子函数
Node* _Copy(Node* root)
{
if(root == nullptr)
return nullptr;
Node* newnode = new Node(root->_key);
newnode->_left = _Copy(root->_left);
newnode->_right = _Copy(root->_right);
return newnode;
}
不过,如果只拷贝根结点,这相当于浅拷贝,可能会引起同一块空间二次析构的情况。所以最好实现深拷贝,也就是拷贝每一个结点的值和它的左右子树。
2.3 赋值运算符重载函数
赋值运算符重载采用主流写法,即参数不用引用接收,而利用形参是实参的一份临时拷贝而让函数自己调用拷贝构造函数。将传入的根结点的地址作为函数创建的根结点的值。由于它的定义域只在函数内,所以当函数被调用完毕以后,会调用析构函数清理创建的临时树。
// operator= 重载
BSTree<K>& operator=(BSTree<K>& t) // 调用构造函数
{
swap(t._root, _root);
return *this; // 调用析构函数
}
2.4 析构函数
因为我们都是深拷贝实现的构造函数,所以析构函数也要对应。每个结点都是new申请空间的,所以每个对象都要delete。对于二叉树,最常用的还是递归地构造和析构。
// 析构函数
~BSTree()
{
_Destory(_root);
_root = nullptr;
}
// 析构子函数
void _Destory(Node* root)
{
if(root == nullptr)
return;
_Destory(root->_left);
_Destory(root->_right);
delete root;
}
2.5 插入函数
非递归实现
根据二叉搜索树的特性,插入的新结点的值要和根结点比较,如果它更小,走当前结点的左子树,否则走左子树。当往下走到空的时候就插入。
需要注意的是,插入的地方既然是空,那么对于叶节点,它的空位置可能是左右孩子中的一个。如下图,插入结点的值为2。
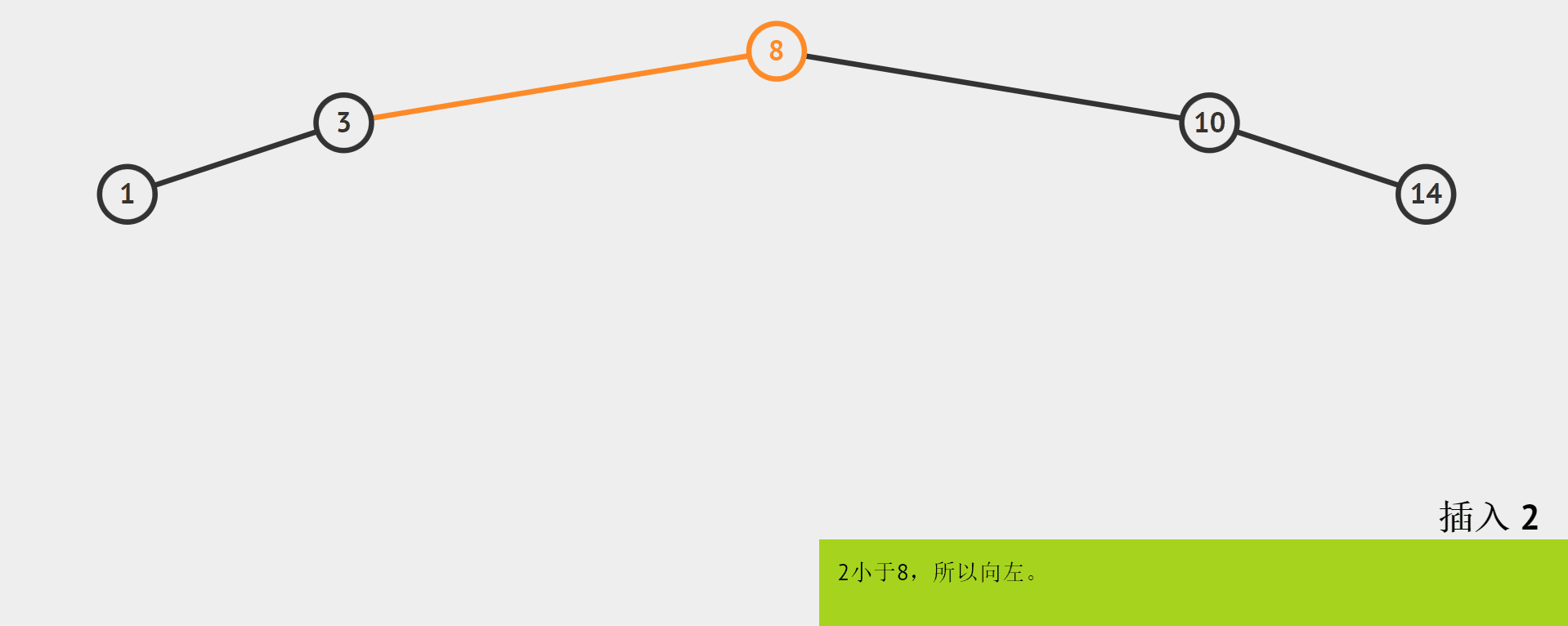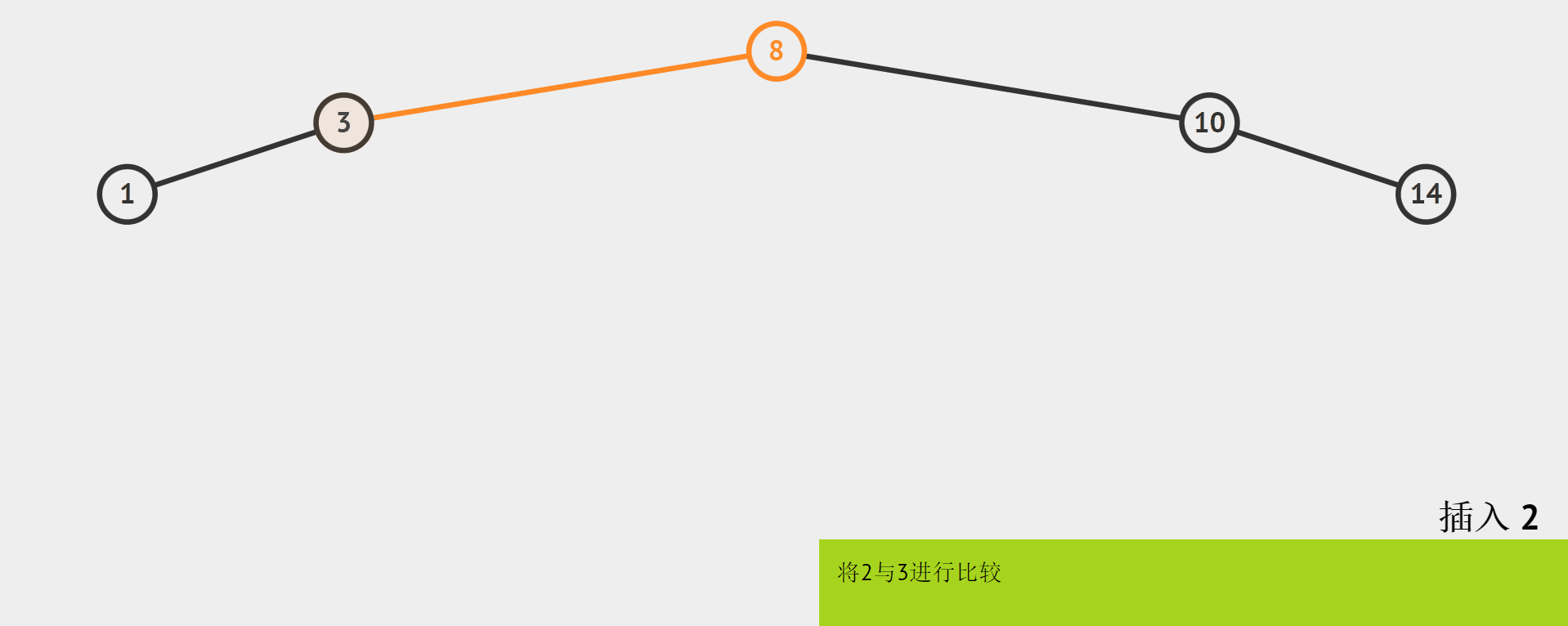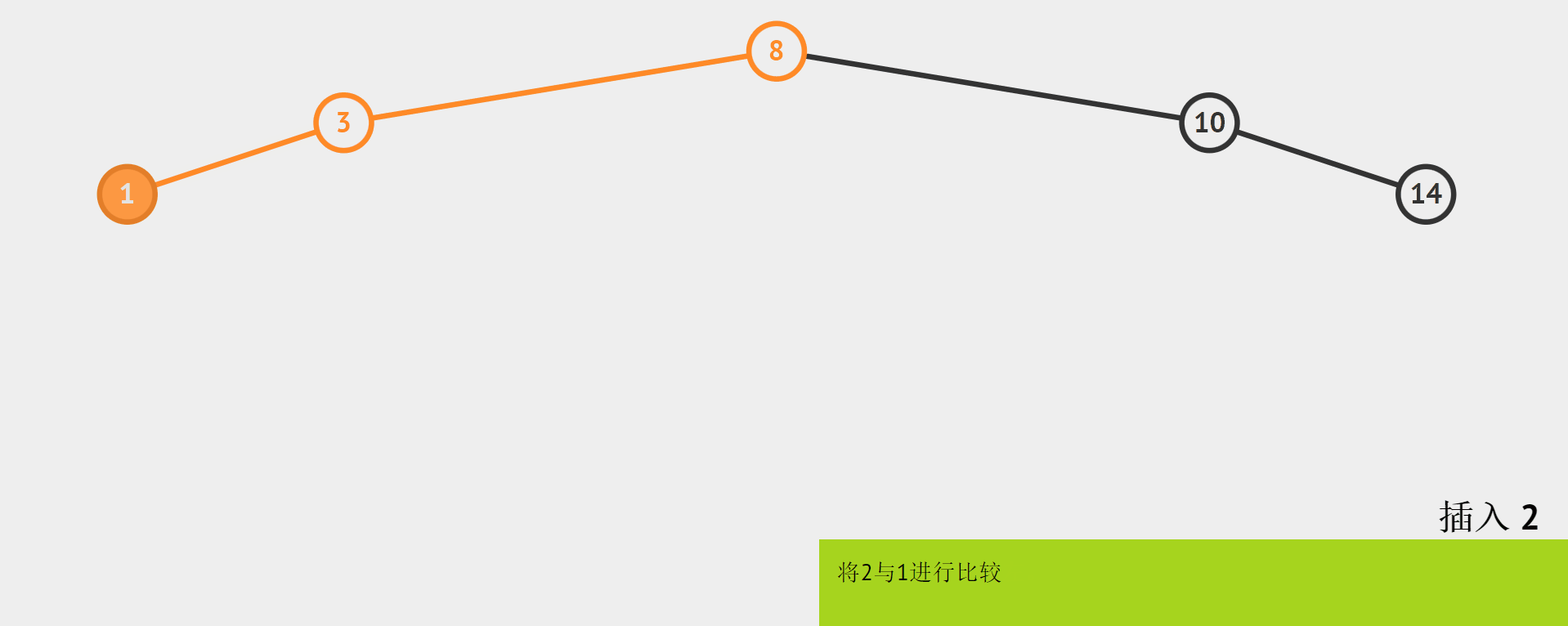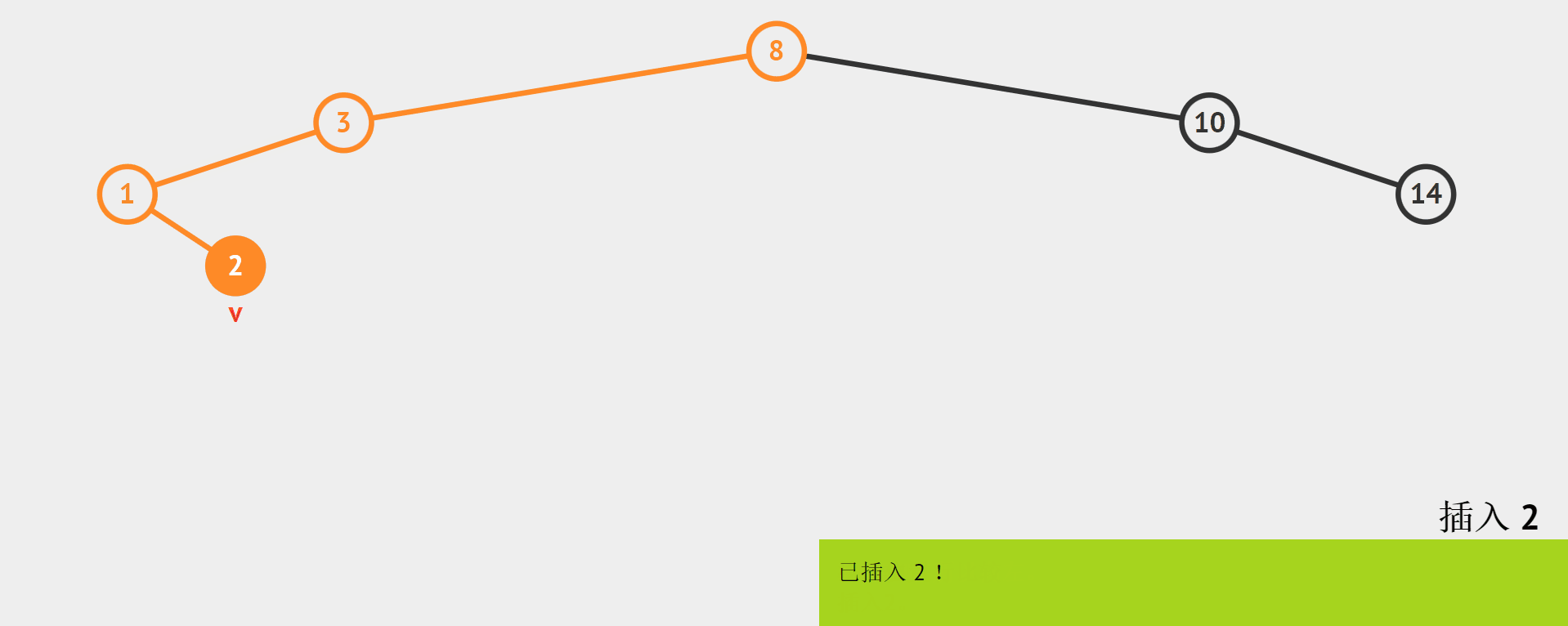
如上图,我们知道2比1大,应该把2链接到1的边,但是如何链接呢?
我们用cur表示当前处理的结点,那么当要插入之前,cur应该是走到某个叶子的左右孩子的位置。那么我们需要用一个变量parent保存cur的父结点。

插入规则符合二叉搜索树的性质:
首先必须判空:
- 空树:将新结点当做新树的根结点,返回true;
- 非空:按照下面的规则插入。
规则:
- 新结点的值小于根结点的值,将结点插入到左子树当中;
- 新结点的值大于根结点的值,将结点插入到右子树当中;
- 新结点的值等于根结点的值,插入结点失败。
// 插入函数
bool Insert(const K& key)
{
if(_root == nullptr) // 插入一个空树
{ // 插入的数作为根结点的值
_root = new Node(key);
return true;
}
// 树不为空
Node* parent = nullptr;
Node* cur = _root;
while(cur) // 迭代,让cur找nullptr
{
if(key == cur->_key) //插入结点和当前结点的值相同
{
return false;
}
else if(key < cur->_key) // 插入结点的值小于当前结点的值
{
parent = cur; // 保存父结点
cur = cur->_left; // 更新cur
}
else if(key > cur->_key) // 插入结点的值大于当前结点的值
{
parent = cur; // 保存父结点
cur = cur->_right; // 更新cur
}
}
// 此时,cur已经走到空结点,parent是它的父结点
// 链接新结点和父结点
cur = new Node(key); // 创建新结点,放在cur的位置
if(key > parent->_key) // 插入结点的值大于父结点的值
{
parent->_right = cur;
}
else if(key < parent->_key) // 插入结点的值大于父结点的值
{
parent->_left = cur;
}
return true;
}
递归实现
规则相同,但是因为是递归实现。所以终止条件就是结点为空的时候,这时候就可以插入了,插入结点以后返回true;其他情况说明还没有递归到空结点,则往左右子树递归地插入,插入失败则返回false。
值得注意的是,递归的子函数的参数类型必须是指针的引用类型,否则无法正常链接。因为局部变量的生命周期在函数内部。
// 递归插入函数
bool InsertR(const K& key)
{
return _InsertR(key, _root);
}
// 递归插入子函数
bool _InsertR(const K& key, Node*& root) // 注意这里必须传引用,否则最后链接不上
{
if(root == nullptr)
{
root = new Node(key); // 插入的树为空
return true;
}
// 插入的树不为空
if(key < root->_key)
return _InsertR(key, root->_left);
else if(key < root->_key)
return _InsertR(key, root->_right);
else
return false;
}
2.6 中序遍历
插入功能是BFSTree中最重要的功能之一,所以实现完insert接口以后,就可以进行测试了。可以用中序遍历测试结构是否是有序的。
为了结构清晰,仍然将子函数作为私有成员函数,用公有成员调用子函数。
// 中序遍历
void InOrder()
{
_InOrder(_root);
cout << endl;
}
// 递归中序遍历子函数
void _InOrder(const Node* root)
{
if(root == nullptr)
return;
_InOrder(root->_left);
cout << root->_key << " ";
_InOrder(root->_right);
}
2.7 删除函数
非递归实现
同样地,用cur表示当前处理的结点,如果找到了要删除的结点,那么cur就是待删除结点,用parent表示cur的父结点。
删除结点,根据删除结点的孩子个数,有三种情况:
0个孩子
-
0个孩子,即叶节点:
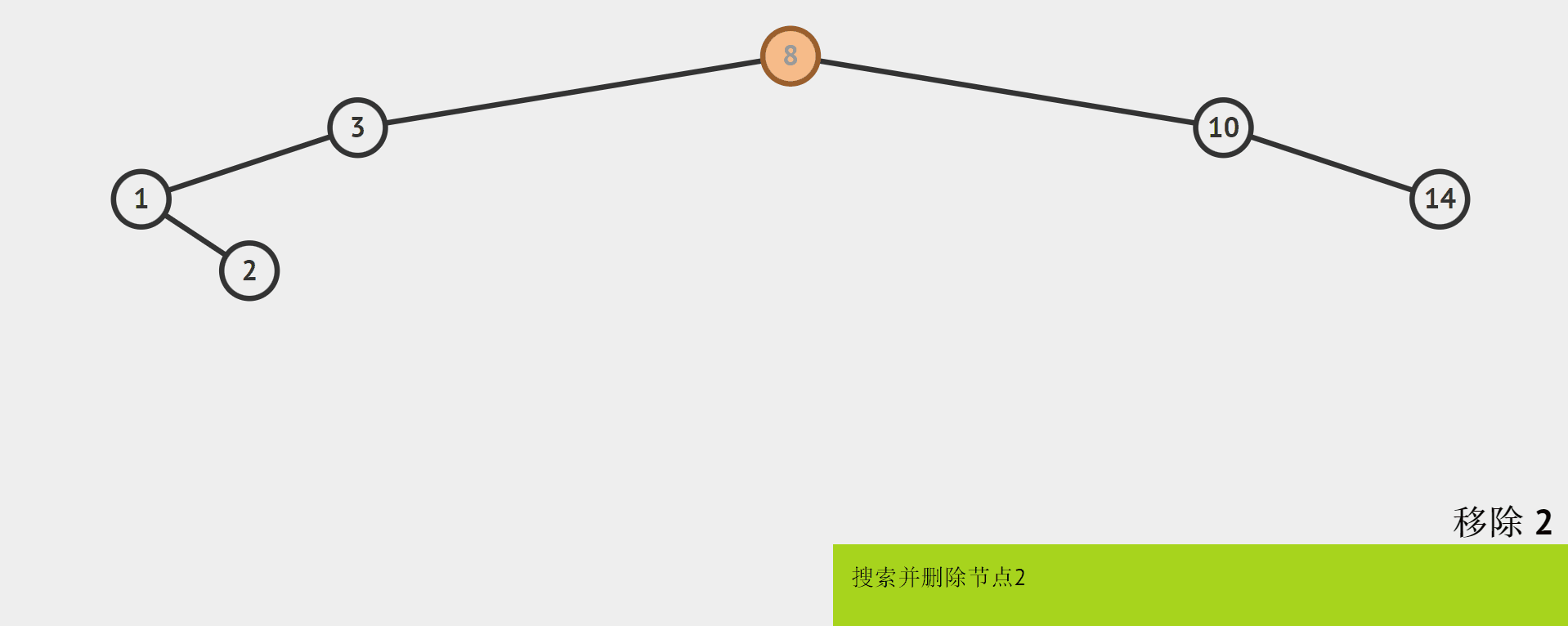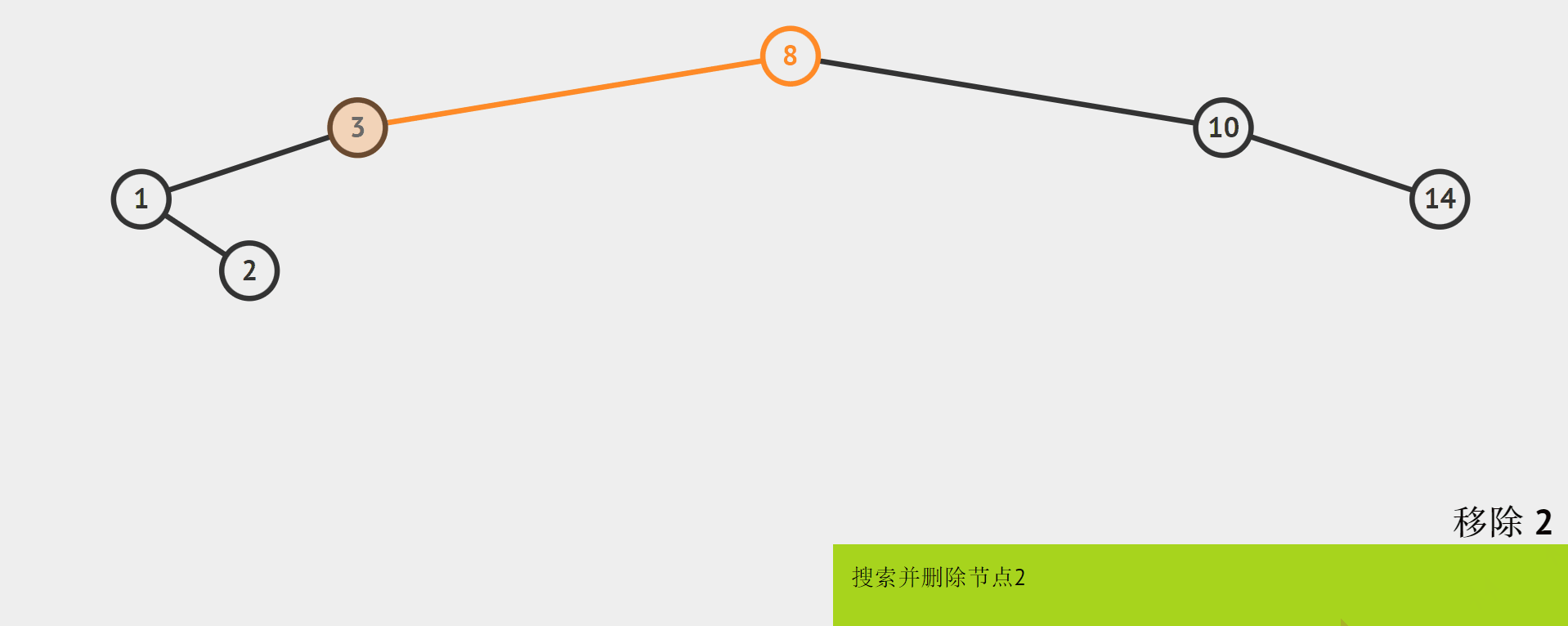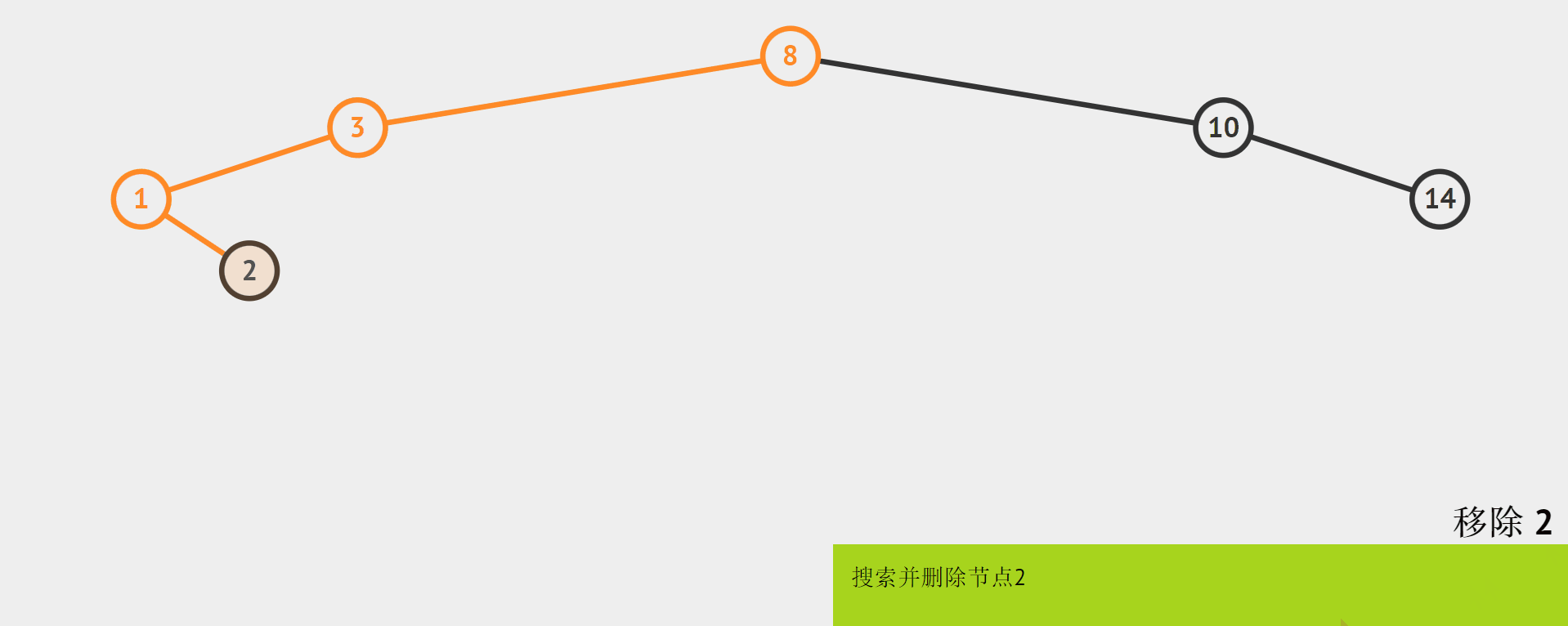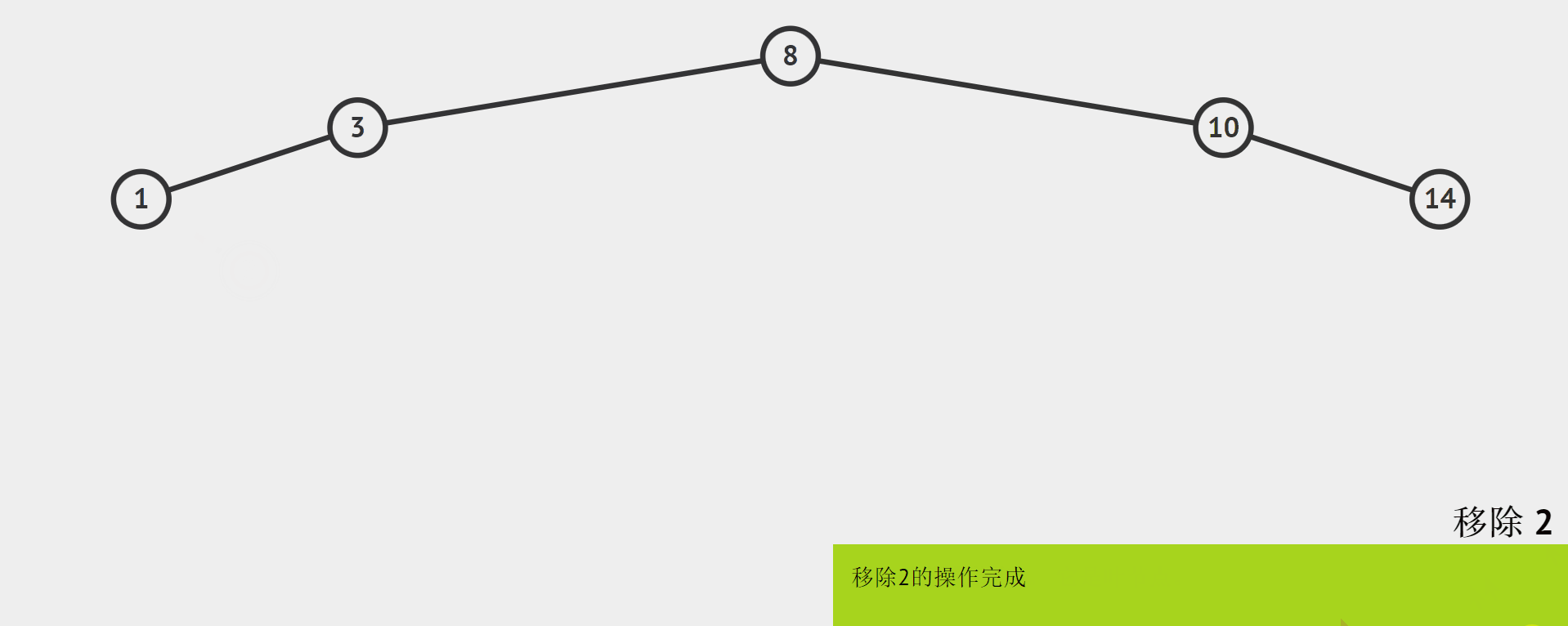
直接删除。
1个孩子
-
1个孩子:
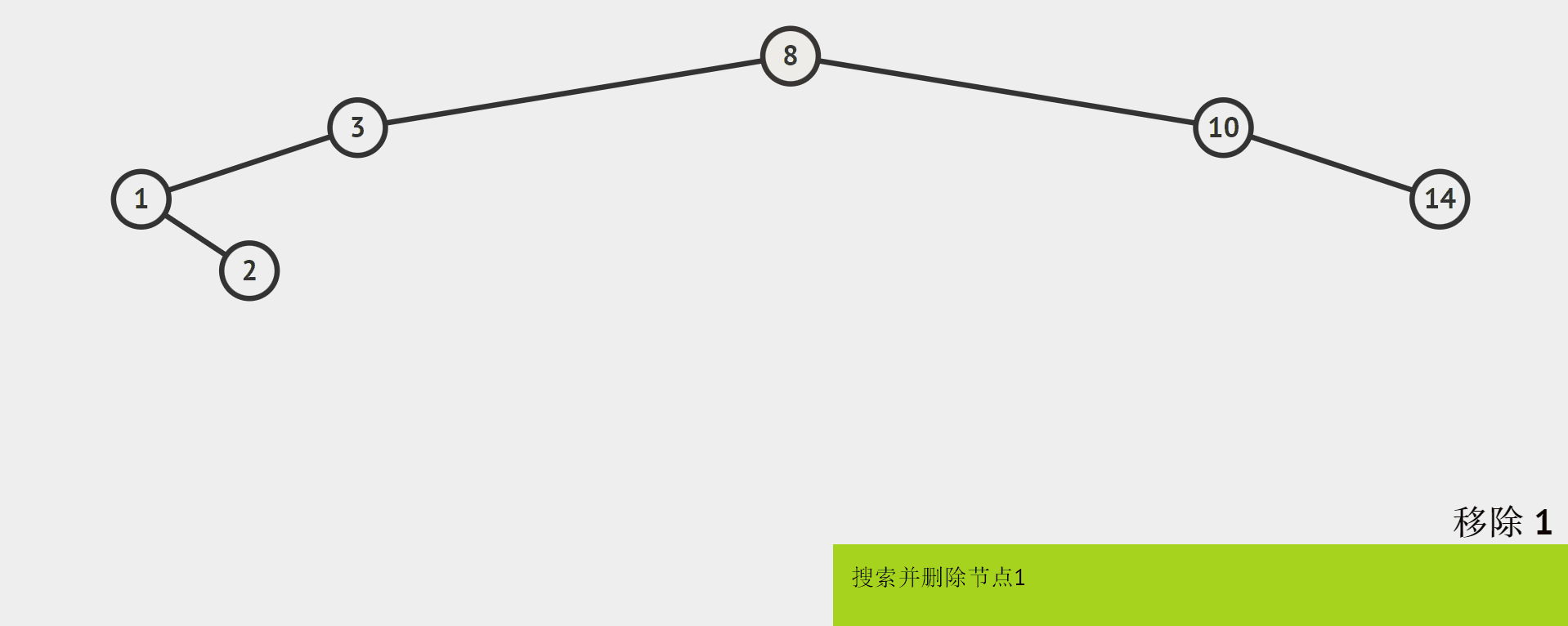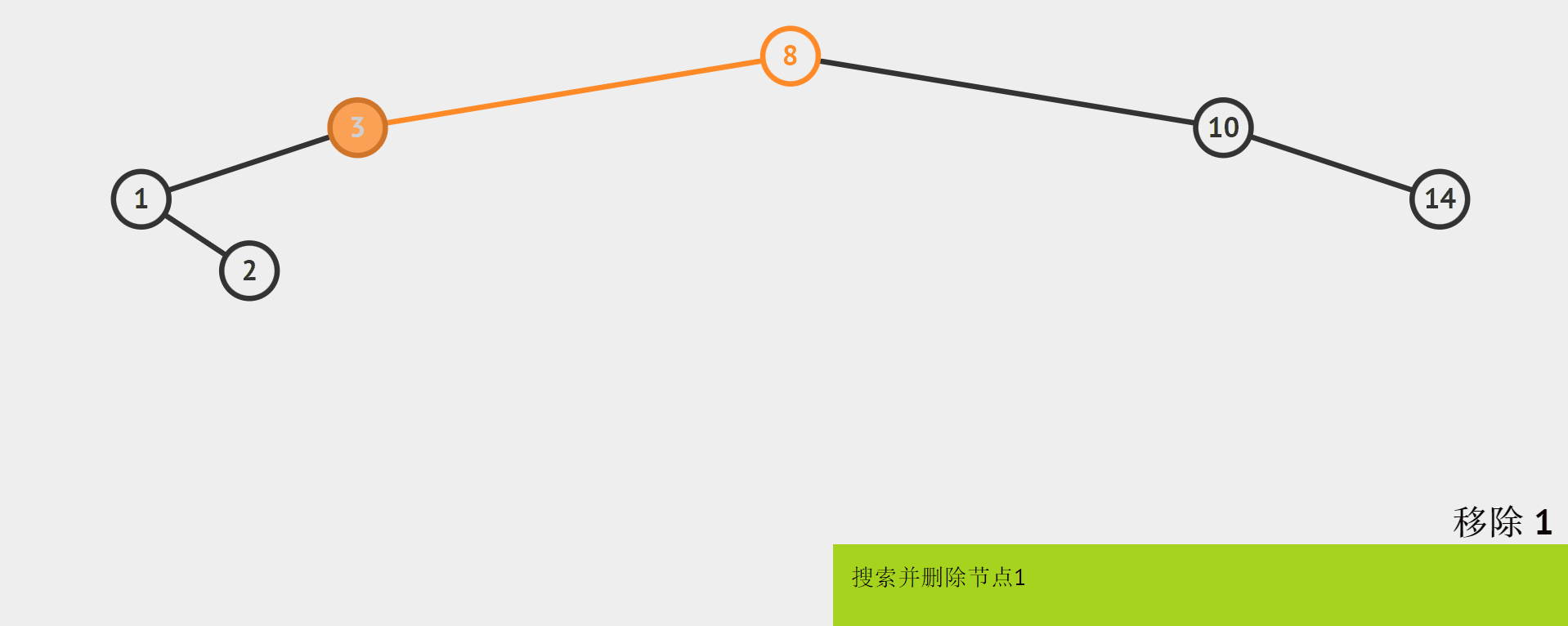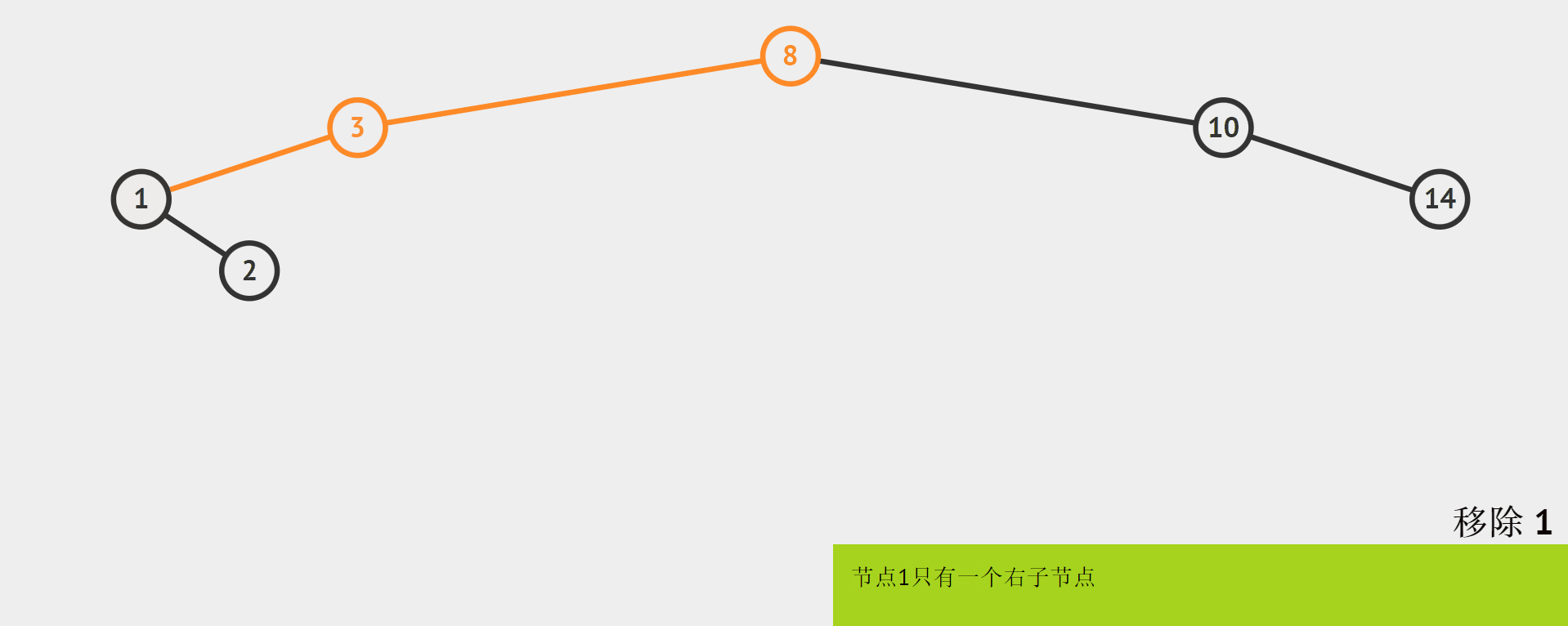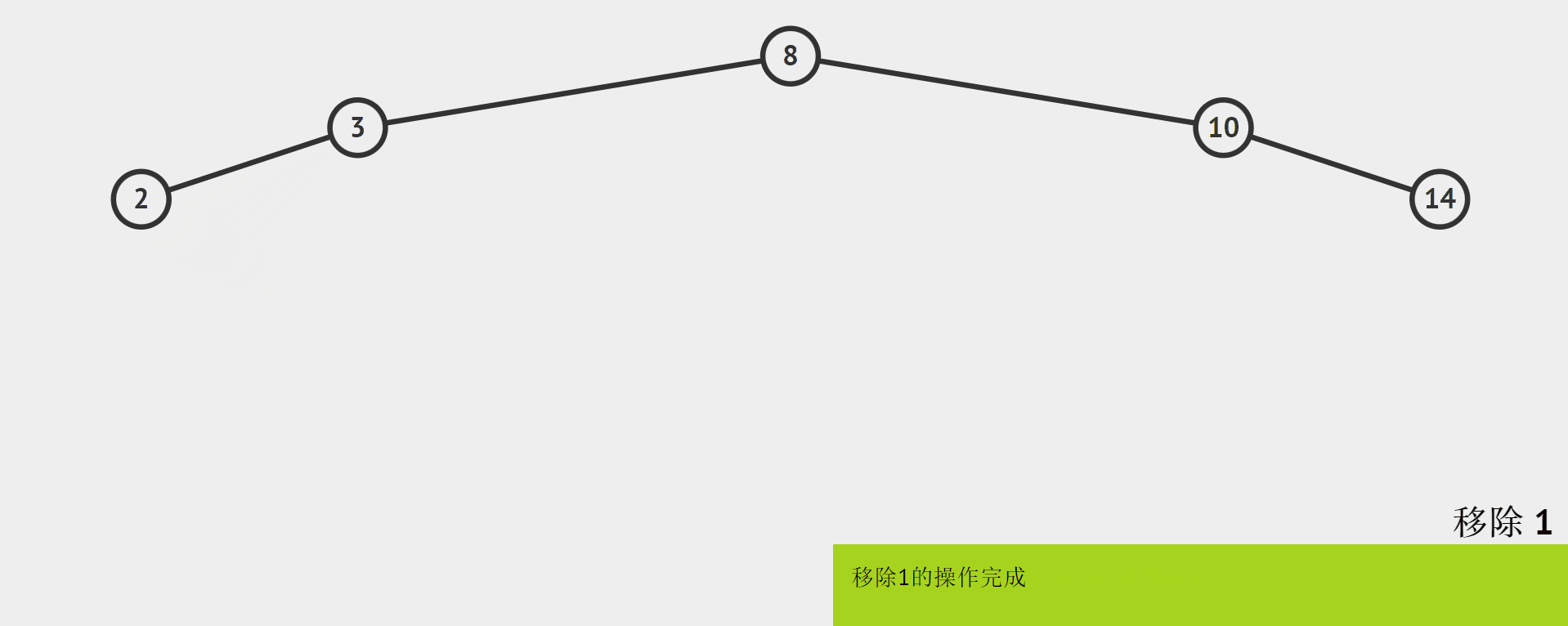
就图例而言,把删除的结点和它的这个孩子看作一个整体,它们都比待删除结点的值要小,删除1以后,而原来的1是3的左孩子。所以直接将1的孩子2作为1的父结点(3)的左孩子即可。如何判断只有一个孩子的结点?
其实可以把前两种情况合并为1种:只要cur的左右子树的其中一个子树是空,就可以把cur的另一个非空子树给parent。因为cur的左右空树有三种(左空或右空或左空+右空),而cur作为parent的孩子也有两种情况(左或右),下面给出6种情况中的2种:
-
如果cur的左树是空,而且cur(待删除结点)是parent的左子树,那么就将cur的右子树给parent的左子树,最后delete掉cur。
-
如果是cur的右子树为空,cur(待删除结点)是parent的右子树,那么就将cur的左子树给parent的右子树,最后delete掉cur。
-
如果cur的左右子树都是空树,那么只要进入上面语句的判断,不论怎样,cur的另一个子树nullptr会被链到parent上。
注意:
当找到待删除结点以后,必须判断cur是否为根结点。如果是根结点,则让另外一个不为空的子树的根结点作为整棵树的根结点。
2个孩子
- 两个孩子
根据二叉搜索树的特点,对于任意一个结点,它的左子树的所有值都比它的值小,右子树的都比它的大。那么可以有这样的结论,以cur为根结点的子树:
- 子树的最左边的值一定是最小的;
- 子树的最右边的值一定是最大的。
通过图示理解:

这棵二叉搜索树中,最大值是14,它在最右边;最小值是1,它在最左边。这对每个子树都是成立的。
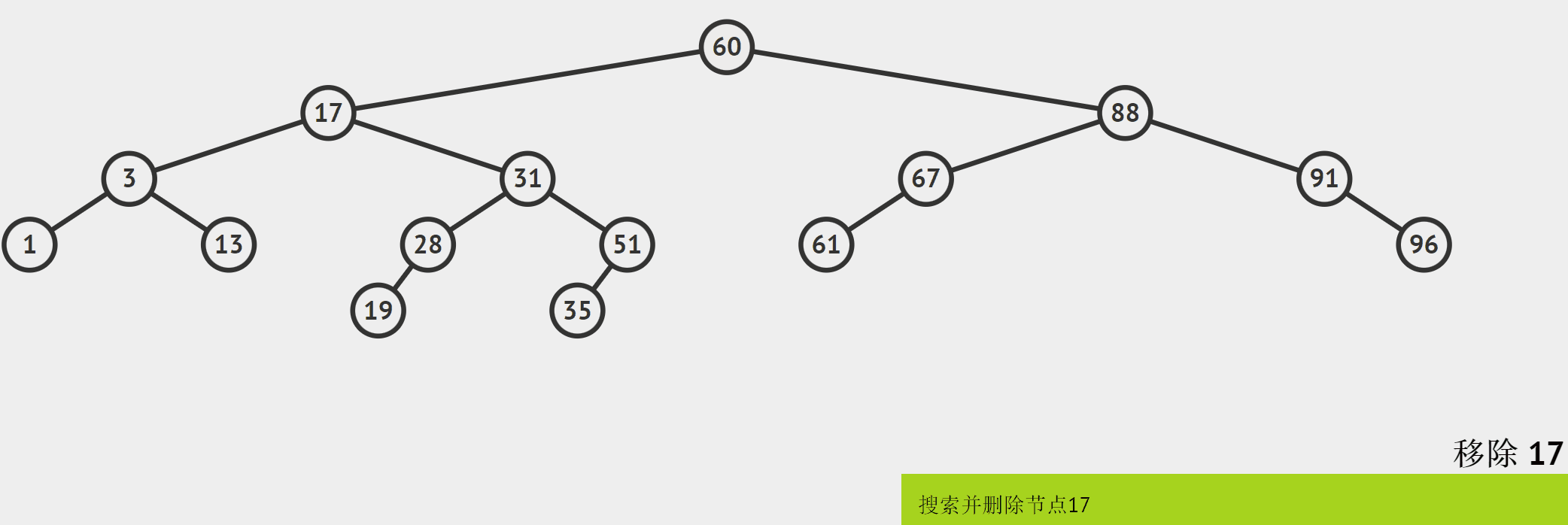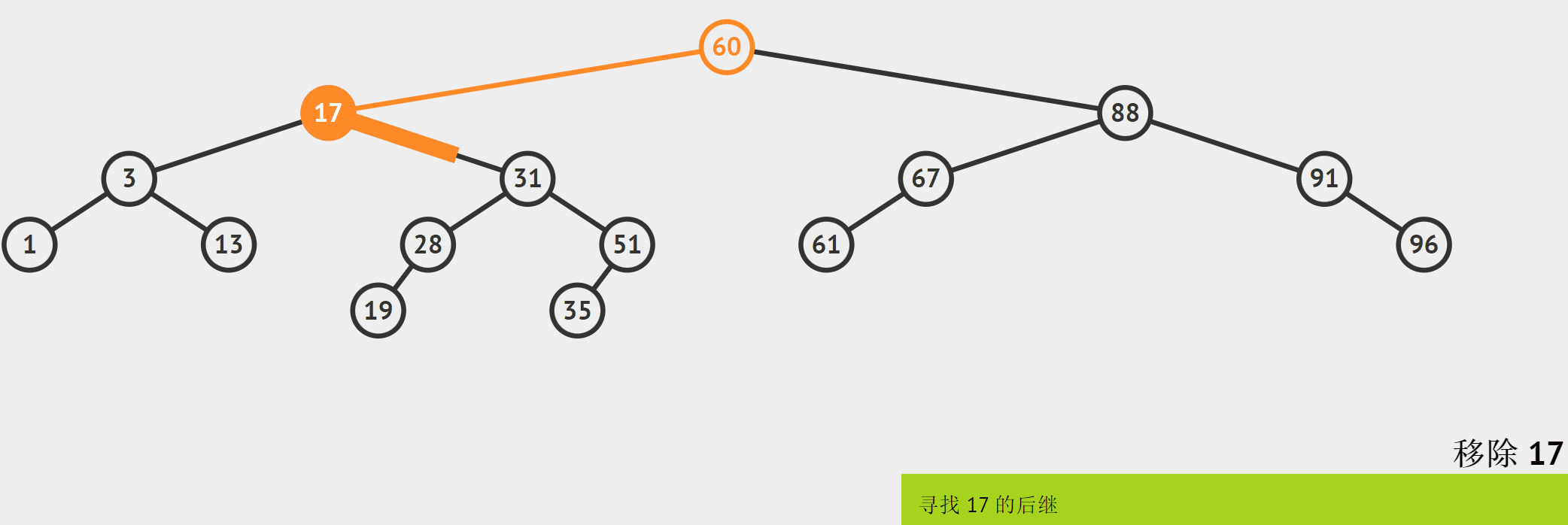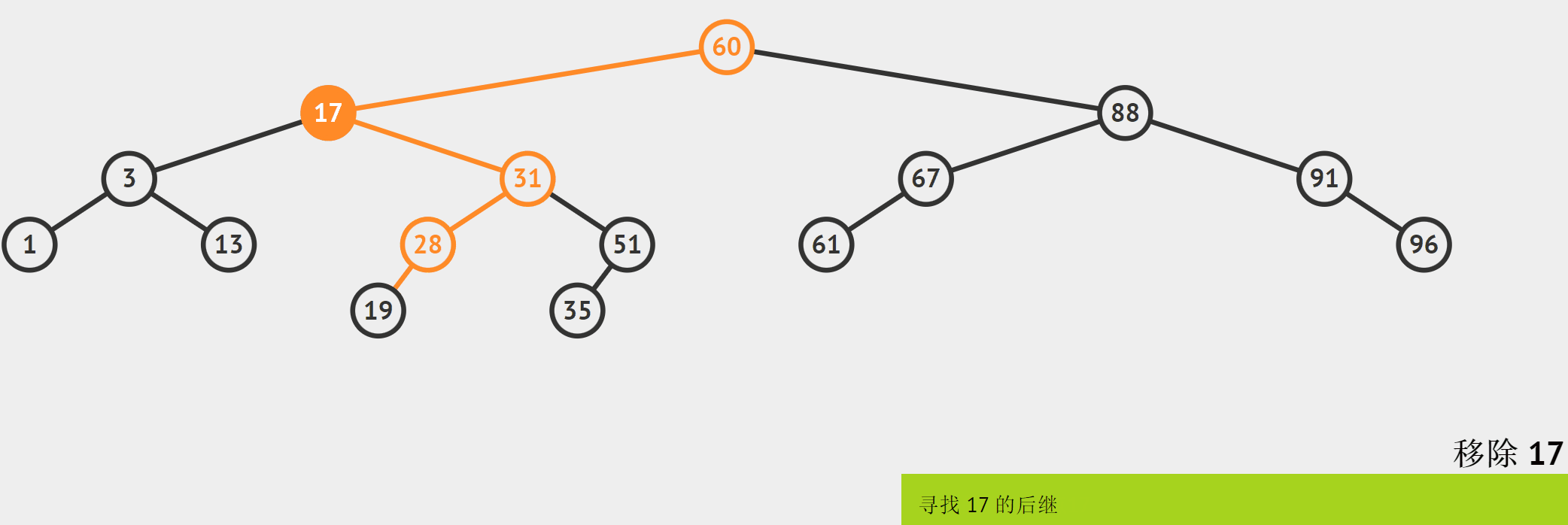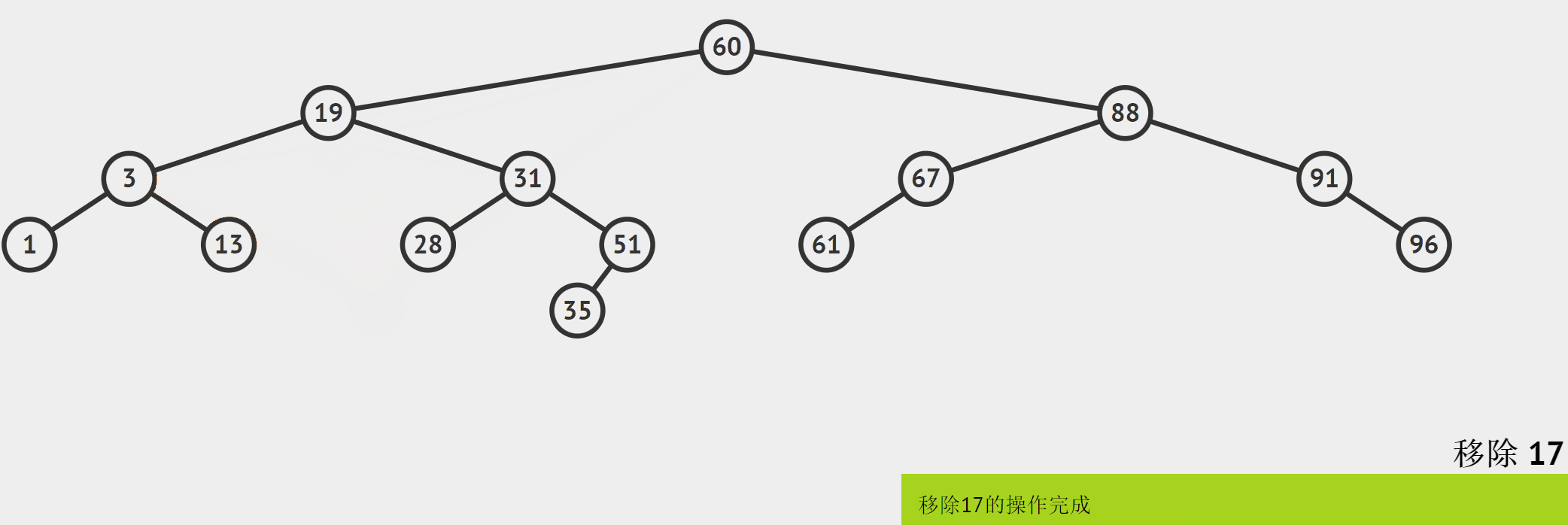
要删除2个孩子的结点,需要使用“替换法”,以上面的图为例:
对于待删除结点17而言,它的右子树的每个结点的值都比它大,取右子树中最小的结点的值作为17的替换值,然后将被替换的结点删除。
如何理解“替换法”的思想:删除结点,不论使用什么办法,都不能破坏二叉搜索树的结构,即节点的值满足左右两边的关系。那么对于待删除结点而言,它的值和左子树中最大的值最接近(左子树的值都比根结点的值小);和右子树中最小的值最接近(右子树的值都比根结点的值大),所以不破坏结构的最好办法就是任取这两个和待删除结点最接近的值作为待删除结点的替换值。
如何知道结点的两个孩子都不为空?
- 只要被第二点中只有1个孩子的情况过滤以后的所有情况都是两个孩子。
由于最接近cur的值的结点有两个,下面只以替换左子树的最右结点为例。
如何找到左子树的最右结点?因为左右节点是左子树中值最大的,所以定义为Max,让它从待删除结点的左子树中开始cur->\_left,一直往右边走while(Max->_right) (这也是利用了BFSTree的特性)。当跳出这个循环,则说明Max已经找到了。
其实,替换法的操作和动图里直接删除cur是不一样的。替换法是将Max的值替换cur结点的值,然后删除Max结点。
// 删除函数
bool Erase(const K& key)
{
Node* parent = nullptr; // 由于需要链接,所以要保存父结点的位置
Node* cur = _root; // 当前结点
while(cur)
{
if(cur->_key > key) // 要删除的结点的值小于当前结点的值
{ // 说明要删除的结点在当前结点的左子树
parent = cur; // 更新父结点
cur = cur->_left; // 更新cur
}
else if(cur->_key < key) // 要删除的结点的值大于当前结点的值
{ // 说明要删除的结点在当前结点的右子树
parent = cur;
cur = cur->_right;
}
else // 此时找到了要删除的结点
{
if(cur->_left == nullptr) // 1. 待删除结点的左子树为空
{
if(cur == _root) // 待删除结点为根结点
_root = cur->_right; // 将右子树作为新树
else // 待删除结点不为根结点,将待删除结点的父结点更新到当前结点
{
if(cur == parent->_left)// 待删除结点为父结点的左孩子
parent->_left = cur->_right;// 将左孩子的右子树链接到父结点的左孩子上
else if(cur == parent->_right)// 待删除结点为父结点的右孩子
parent->_right = cur->_right;// 将左孩子的右子树链接到父结点的右孩子上
}
delete cur; // 释放结点资源
return true; // 表示删除成功
}
else if(cur->_right == nullptr) // 2. 待删除结点的右子树为空,步骤相同
{
if(cur == _root)
_root = cur->_left;
else
{
if(cur == parent->_left)
parent->_left = cur->_left;
else if(cur == parent->_right)
parent->_right = cur->_left;
}
delete cur; // 释放结点资源
return true; // 表示删除成功
}
else // 3. 待删除结点左右子树均不为空,使用替换法
{
Node* Max = cur->_left; // 记录待删除结点左子树的最右边的结点,也就是最大结点
Node* MaxParent = cur; // 记录最大结点的父结点
while(Max->_right)
{
MaxParent = Max;
Max = Max->_right;
}
// 找到待删除结点的左子树的最右节点
// 将最右结点的值替换给待删除的结点的值
cur->_key = Max->_key;
// 替换结点可能有一个或没有孩子,有也只可能是右孩子
// 替换以后,待删除结点变为替换结点
if(Max == MaxParent->_right)// 待删除结点(替换结点)是父结点的左孩子
MaxParent->_right = Max->_left;
else if(Max == MaxParent->_left)
MaxParent->_left = Max->_right;
delete Max; // 清理替换结点
}
return true;
}
}
return false; // 上面的循环中没有找到
}
递归实现
大多数情况下,递归实现起来都要比非递归来的简单,Insert也不例外。思路还是类似地,空树返回false;cur值比根节点值小,往左递归,否则往右递归。而且同样要用到替换法。
所以erase最重要的方法就是替换法。同样,下面的替换法依然使用了cur的左子树的最右结点替换。
// 递归删除函数
bool EraseR(const K& key)
{
return _EraseR(key, _root);
}
// 递归删除子函数
bool _EraseR(const K& key, Node* root)
{
if(root == nullptr) // 空树
return false;
Node* cur = root;
if(key < cur->_key) // 待删除结点的值小于当前结点的值
return _EraseR(key, cur->_left);// 走左子树
else if(key > cur->_key) // 同理
return _ERaseR(key, cur->right);
else // 待删除结点的值等于当前结点的值->找到待删除结点
{
Node* Del = cur; // 保存待删除结点Del,稍后要delete
if(cur->_left == nullptr) // Del的左子树为空
cur = cur->_right;
else if(cur->_right = nullptr) // Del的右子树为空
cur = cur->_left;
else // Del的左右子树都不为空
{
Node* Max = cur->_left;
while(Max->_right) // 找左子树的最右结点,也即是左子树的最大结点
{
Max = Max->_right;
}
cur->_key = Max->_key; // 替换
return _EraseR(key, cur->_right);
}
delete Del;
return true;
}
}
2.8 查找函数
非递归实现
根据二叉搜索树的特性,定义cur为当前结点的值。当传入要查找的值为key的结点的规则:
- 空树:返回nullptr;
- key小于cur的值,在左子树中继续查找;
- key大于cur的值,在右子树中继续查找;
- key等于cur的值,返回cur节点的地址。
代码如下:
// 查找函数
Node* Find(const K& key)
{
Node* cur = _root;
while(cur)
{
if(key < cur->_key)
cur = cur->_left;
else if(key > cur->_key)
cur = cur->_right;
else
return cur;
}
return nullptr;
}
递归实现
递归实现查找功能,就像递归遍历一样。
Node* FindR(const K& key)
{
return _FindR(key, _root);
}
// 递归插入子函数
bool _InsertR(const K& key, Node*& root) // 注意这里必须传引用,否则最后链接不上
{
if(root == nullptr)
{
root = new Node(key); // 插入的树为空
return true;
}
// 插入的树不为空
if(key < root->_key)
return _InsertR(key, root->_left);
else if(key < root->_key)
return _InsertR(key, root->_right);
else
return false;
}
3. 应用
3.1 Key模型
key搜索模型:判断关键字key在不在。
例如有这样的场景:
- 刷卡、刷脸进宿舍楼;
- 检查一篇英文文档中的单词拼写是否正确。
3.2 Key/Value模型
key/value模型:通过key找value。key和value是绑定在一起的,称作键值对
例如有这样的场景:
-
简单的中译英:
以<中文,对应的英语单词>为键值对,它们都是string类型,构建二叉搜索树,需要注意的是,比较的都是key,所以是根据ASCII码排序的;
这样查询中文的英语单词时,只需要以中文词语为key,就能在树中找到对应的value。
-
统计单词出现的次数:
以<单词, 次数>为键值对,它们分别是string和int类型,构造二叉搜索树。同样地,以单词的ASCII码值排序。只要以英语单词为key,就能找到单词对应的次数。
为什么二叉搜索树能统计单词出现的次数?
- 因为二叉搜索树的Insert有去重+排序功能,只要遍历结点的值和指定的key值相同,那么树就会认为它是同一个键值对,对它自增就能统计次数。
使用Key/Value模型,能简单地解决链表相交和复杂链表复制问题。
4. 性能
通过实现二叉搜索树,可以知道二叉搜索树的插入、删除、查找等功能都是要先查找然后再操作的,所以查找的性能就能代表二叉搜索树的整体性能。
由于二叉搜索树的特性,在大多数情况下,它能让左右子树都能有一定数量的结点,使得整棵树达到接近完全二叉树的状态,不过这是不稳定的,因为还有其他极端情况。
假设二叉搜索树的结点数为N,对于以下极端情况:
-
最优:完全二叉树状态,查找的平均次数为树的高度,即 l o g 2 N log_2N log2N;

-
最劣:单支树状态,查找的平均次数为 N / 2 N/2 N/2。
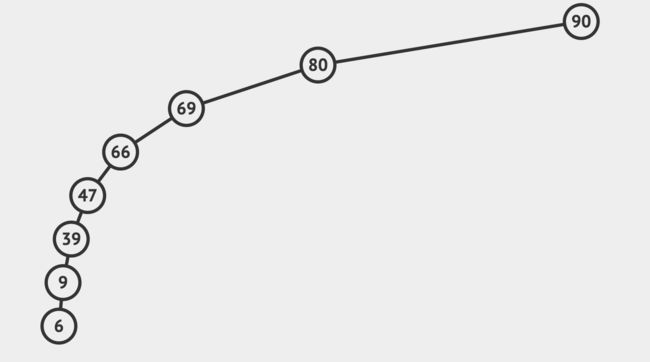
我们知道,时间复杂度是对于最差的情况而言的,所以二叉搜索树查找的时间复杂度为 O ( N ) O(N) O(N)。
即使二叉搜索树在很多时候效率都在 O ( l o g 2 N ) O(log_2N) O(log2N)和 O ( N ) O(N) O(N)之间,但是它无法保证极端情况下的效率,因为它最后的结构取决于数据。
有这样的树,它能通过改造自己的结构,使得树的结构接近完全二叉树,效率稳定在 O ( l o g 2 N ) O(log_2N) O(log2N),它们就是后续要学习的AVL树和红黑树。
源码